本文介绍Azure SQL Database中数据库的不同类型的存储空间。 虽然不常见,但本文包含可在分配的文件空间需要显式管理时执行的步骤。
概述
使用Azure SQL Database时,有一些工作负荷模式,其中数据库的基础数据文件分配可能大于已使用的数据页数。 当使用的空间增加并稍后删除数据时,可能会出现这种情况。 这是因为在数据被删除时,分配的文件空间不会自动回收。
在以下情况下,可能需要监视文件空间使用量并收缩数据文件:
- 当分配给数据库的文件空间达到池的最大大小时,允许在弹性池中增大数据。
- 允许减少单一数据库或弹性池的最大大小。
- 允许将单一数据库或弹性池更改为最大大小更小的其他服务层级或性能层。
注意
收缩操作不应被视为常规维护操作。 由于常规定期业务操作而增长的数据和日志文件不需要收缩操作。
监视文件空间用量
以下 API 中显示的大多数存储空间指标仅度量已用数据页面的大小:
- 基于Azure Resource Manager的指标 API,包括 PowerShell get-metrics
但是,以下 API 还度量分配给数据库和弹性池的空间大小:
- T-SQL:sys.resource_stats
- T-SQL:sys.elastic_pool_resource_stats
了解数据库存储空间的类型
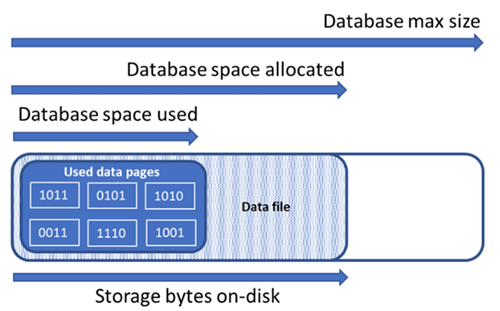
了解以下存储空间数量对于管理数据库的文件空间非常重要。
| 数据库数量 | 定义 | 注释 |
|---|---|---|
| 已用数据空间 | 用于存储数据库数据的空间量。 | 通常,已用空间会在执行插入操作时增大,在执行删除操作时减小。 在某些情况下,已用空间不会在执行插入或删除操作时发生变化,具体取决于该操作涉及的数据数量和模式,以及是否有任何碎片。 例如,从每个数据页中删除一行不一定会减小已用空间。 |
| 已分配的数据空间 | 可用于存储数据库数据的格式化文件空间量。 | 已分配的空间量会自动增长,但执行删除操作后永远不会减小。 此行为可确保将来的插入操作速度更快,因为不需要重新格式化空间。 |
| 已分配但未使用的数据空间 | 已分配的数据空间量与已使用的数据空间量之间的差值。 | 此数量表示通过收缩数据库数据文件可回收的最大可用空间量。 |
| 数据最大大小 | 可用于存储数据库数据的最大空间量。 | 已分配的数据空间量在增长后不能超过数据最大大小。 |
下图演示了数据库的不同存储空间类型之间的关系。
查询单一数据库的文件空间信息
使用以下查询 sys.database_files,返回已分配的以及已分配但未使用的数据库文件空间量。 查询结果以 MB 为单位。
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
了解弹性池存储空间的类型
了解以下存储空间数量对于管理弹性池的文件空间非常重要。
| 弹性池数量 | 定义 | 注释 |
|---|---|---|
| 已用数据空间 | 弹性池中所有数据库已使用的数据空间总和。 | |
| 已分配的数据空间 | 弹性池中所有数据库已分配的数据空间总和。 | |
| 已分配但未使用的数据空间 | 弹性池中所有数据库已分配的数据空间量与已使用的数据空间量之间的差值。 | 此数量表示弹性池通过收缩数据库数据文件可回收的最大空间量。 |
| 数据最大大小 | 弹性池对其所有数据库使用的最大数据空间量。 | 为弹性池分配的空间不应超过弹性池最大大小。 如果发生这种情况,可通过收缩数据库数据文件来回收未使用的空间。 |
注意
错误消息“弹性池已达到其存储限制”表示数据库对象占用足够的空间来满足弹性池存储限制。 请考虑增加存储限制,或作为短期解决方案,使用 回收未使用分配空间中的示例释放数据空间。 您还应注意收缩数据库文件可能对性能造成的负面影响。 请参阅收缩后的索引维护。
查询弹性池的存储空间信息
可使用以下查询确定弹性池的存储空间数量。
已用的弹性池数据空间
修改以下查询,返回已用的弹性池数据空间量。 查询结果以 MB 为单位。
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
分配的弹性池数据空间和未使用的分配空间
修改以下示例以返回一个表,其中列出了弹性池中每个数据库的总分配空间和未使用的空间。 该表将数据库按未使用空间从最多到最少进行排序。 查询结果以 MB 为单位。
为池中的每个数据库添加查询结果,以确定弹性池的总分配空间。 弹性池分配的空间不应超过弹性池的最大大小。
重要
PowerShell Azure Resource Manager(AzureRM)模块已于 2024 年 2 月 29 日弃用。 所有未来的开发都应使用 Az.Sql 模块。 建议用户从 AzureRM 迁移到 Az PowerShell 模块,以确保持续支持和更新。 不再维护或支持 AzureRM 模块。 Az PowerShell 模块和 AzureRM 模块中命令的参数基本相同。 有关兼容性的详细信息,请参阅 介绍新的 Az PowerShell 模块。
PowerShell 脚本需要SQL Server PowerShell 模块。 有关详细信息,请参阅 SQL Server PowerShell 模块。
以下 PowerShell 脚本完成以下步骤:
- 声明变量。 将这些值替换为你自己的值。
- 获取弹性池中数据库的列表。
- 对于弹性池中的每个数据库,获取总分配的空间(以 MB 为单位)和已分配但未使用的空间(以 MB 为单位)。
- 按未使用分配空间的降序显示数据库。
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get the total allocated space in MB and the allocated but unused space in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.chinacloudapi.cn,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of unused allocated space
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
以下屏幕截图显示了脚本输出的示例:

弹性池数据最大大小
修改以下 T-SQL 查询,返回上次记录的弹性池数据最大大小。 查询结果以 MB 为单位。
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
回收已分配但未使用的空间
重要
Shrink 命令在运行时可能会影响数据库的性能,请尽量在使用率较低的时候运行它。
收缩数据文件
由于数据库性能的潜在影响,Azure SQL Database不会自动收缩数据文件。 但是,客户可在他们选择的时间通过自助式操作收缩数据文件。 收缩操作不应是定期计划的,而应作为一次性事件,仅在数据文件使用空间大幅减少时进行。
提示
如果常规应用程序工作负荷导致文件再次增长到相同的分配大小,请不要浪费时间收缩数据文件。 文件增长事件可能会对应用程序性能产生负面影响。
在 Azure SQL Database 中,若要收缩文件,可以使用 DBCC SHRINKDATABASE 或 DBCC SHRINKFILE 命令:
-
DBCC SHRINKDATABASE使用单个命令收缩数据库中的所有数据和日志文件。 该命令一次收缩一个数据文件,对于较大的数据库,这可能需要很长时间。 它还收缩日志文件,这通常是不必要的,因为Azure SQL Database根据需要自动收缩日志文件。 -
DBCC SHRINKFILE命令支持更高级的方案:- 它可根据需要以单个文件为目标,而不必收缩数据库中的所有文件。
- 每个
DBCC SHRINKFILE命令可以与其他DBCC SHRINKFILE命令并行运行,以同时收缩多个文件并减少收缩的总时间,代价是资源使用率更高,且阻止用户查询的可能性更高(如果在收缩期间执行)。- 通过并发收缩多个数据文件,你可以更快地完成收缩操作。 如果使用并发数据文件收缩,可能会观察到一个收缩请求被另一个请求短暂阻塞的情况。
- 如果文件的尾部不包含数据,则通过指定
TRUNCATEONLY参数可以更快地减少分配的文件大小。TRUNCATEONLY不需要在文件中移动数据。
- 有关这些收缩命令的详细信息,请参阅 DBCC SHRINKDATABASE 和 DBCC SHRINKFILE。
在连接到目标用户数据库而不是 master 数据库时,必须执行以下示例。
若要使用 DBCC SHRINKDATABASE 收缩给定数据库中的所有数据和日志文件,请执行以下命令:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
在Azure SQL Database中,数据库可能有一个或多个数据文件,在数据增长时自动创建。 若要确定数据库的文件布局,包括每个文件的已使用和已分配的大小,请使用以下示例脚本查询 sys.database_files 目录视图:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
只能通过 DBCC SHRINKFILE 命令对一个文件执行收缩操作,例如:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
请注意收缩数据库文件的潜在负面性能影响。 有关详细信息,请参阅 收缩后的索引维护。
收缩事务日志文件
与数据文件不同,Azure SQL Database自动收缩事务日志文件,以避免过多的空间使用,从而导致空间不足错误。 在大多数情况下,无需收缩事务日志文件。
在“高级”和“业务关键”服务层中,如果事务日志变得很大,则可能会显著影响本地存储消耗,直至达到最大本地存储限制。 如果本地存储消耗接近于限制,客户可以选择使用 DBCC SHRINKFILE 命令收缩事务日志,如以下示例所示。 此命令完成后,将立即释放本地存储,而无需等待定期自动收缩操作。
在连接到目标用户数据库而不是 master 数据库时,应执行以下示例。
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
自动收缩
作为手动收缩数据文件的替代方法,可以为数据库启用自动收缩。 但是,与 DBCC SHRINKDATABASE 和 DBCC SHRINKFILE 相比,自动收缩在回收文件空间方面的效率更低。
默认情况下,自动收缩处于禁用状态,这是适用于大多数数据库的建议设置。 如果有必要启用自动收缩,建议在达到空间管理目标后将其禁用,而不是将其永久启用。 有关详细信息,请参阅 AUTO_SHRINK 注意事项。
例如,如果一个弹性池中包含多个数据库,它们的已用空间经常出现大幅增加和减少,那么自动收缩功能会很有帮助,以避免池接近其最大大小限制。 此方案并不常见。
要启用自动收缩,请在连接到数据库(而非 master 数据库)时执行以下命令。
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
有关此命令的详细信息,请参阅 DATABASE SET 选项。
收缩后的索引维护
对数据文件执行完收缩操作后,索引可能会变得碎片化。 碎片可减少某些工作负荷的读取 I/O 吞吐量,例如使用大型扫描的查询。 如果在收缩操作完成后性能下降,请考虑通过索引维护来重新生成索引。 请记住,索引重新生成需要数据库中的可用空间,因此可能会导致分配的空间增加,从而抵消收缩的影响。
有关索引维护的详细信息,请参阅优化索引维护以提高查询性能并减少资源消耗。
收缩大型数据库
当数据库已分配的空间达到数百 GB 或更高时,收缩可能需要很长时间才能完成,对于若干 TB 的数据库,通常是以小时或天为单位度量的。 可以使用进程优化和最佳做法来提高此过程的效率,并减少对应用程序工作负载的影响。
捕获空间使用情况基线
在开始收缩之前,通过执行以下空间使用情况查询来捕获每个数据库文件中当前已使用和已分配的空间:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
收缩完成后,可以再次执行此查询,并将结果与初始基线进行比较。
截断数据文件
建议首先使用 TRUNCATEONLY 参数对每个数据文件执行收缩操作。 这样,如果文件末尾有任何已分配但未使用的空间,则会快速删除它,且没有任何数据移动。 以下示例命令会截断 file_id 为 4 的数据文件:
DBCC SHRINKFILE (4, TRUNCATEONLY);
对每个数据文件执行此命令后,可以重新运行空间使用情况查询,以查看已分配空间的减少情况(如果有)。 还可以在 Azure 门户中查看数据库的已分配空间。
评估索引页密度
如果截断数据文件不会导致分配的空间减少足够,则需要收缩数据文件。 但是,作为可选但建议的步骤,应首先确定数据库中索引的平均页面密度。 对于相同的数据量,如果页面密度较高,收缩操作将更快完成,因为需要移动的页面更少。 如果某些索引的页面密度较低,请考虑对这些索引执行维护,以增加页面密度,然后再收缩数据文件。 更高的页面密度使得压缩可以更加有效地减少已分配存储空间的占用。
若要确定数据库中所有索引的页面密度,请使用以下查询。 页面密度在 avg_page_space_used_in_percent 列中报告。
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
如果存在页数较多且页密度低于 60-70% 的索引,请考虑在收缩数据文件之前重新生成或重新组织这些索引。
对于较大的数据库,用于确定页面密度的查询可能需要很长时间才能完成。 重新生成或重新组织大型索引也需要大量时间和资源使用。 但是,收缩之前的索引维护可以缩短收缩持续时间,并实现更大的空间节省。
如果有多个索引的页面密度较低,可以在多个数据库会话中并行重新生成它们,以加快该过程。 但是,请确保不要通过这样做来接近数据库资源限制。 为可能正在运行的应用程序工作负荷留出足够的资源余地。 在Azure门户中或使用 sys.dm_db_resource_stats 视图监视资源消耗(CPU、数据 IO、日志 IO)。 仅当每个维度上的资源利用率仍远远低于 100%时,才会启动额外的并行重新生成。 如果 CPU、数据 IO 或日志 IO 利用率为 100%,可以扩展数据库,以拥有更多 CPU 核心,并增加 IO 吞吐量。
示例索引重新生成命令
下面是使用 ALTER INDEX 语句重新生成索引并增加其页面密度的示例命令:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
此命令将启动联机的可恢复索引重新生成。 此操作允许并发工作负荷在重新生成过程中继续使用表,并允许在因任何原因中断时恢复重新生成。 但是,这种类型的重新生成比脱机重新生成慢,后者会阻止对表的访问。 如果在重新生成期间没有其他工作负载需要访问表,请将 ONLINE 和 RESUMABLE 选项设置为 OFF 并删除 WAIT_AT_LOW_PRIORITY 子句。
若要了解有关索引维护的详细信息,请参阅优化索引维护以提高查询性能并减少资源消耗。
在缩减之前压缩 LOB 数据
如果数据库包含以下情况,收缩可能需要更长的时间:
- LOB 数据类型,如 varchar(max)、 nvarchar(max)、 varbinary(max)、 xml 或类似存储在分配单元中的
LOB_DATA数据类型。 - 存储在中的
ROW_OVERFLOW_DATA。 - 列存储索引。
若要加快收缩运行速度并释放更多空间,请先使用 LOB 压缩完成索引重组。 对于包含 LOB 列或大型行的所有索引,建议在缩小之前先进行 LOB 压缩。 例如:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REORGANIZE WITH (LOB_COMPACTION = ON);
在收缩之前重新组织或重新生成列存储索引可以同样提高收缩速度和有效性。
收缩多个数据文件
如前所述,伴随数据移动的缩减是一个耗时的过程。 如果数据库有多个数据文件,可以通过并行收缩多个数据文件来加快该过程。 打开多个数据库会话,并在每个会话DBCC SHRINKFILE上使用不同的file_id值。 与前面重新生成索引类似,在开始每个新的并行收缩命令之前,请确保你有足够的资源空余空间(CPU、数据 IO、日志 IO)。
以下示例命令对 file_id 为 4 的数据文件进行收缩,尝试通过移动文件中的页面将其分配大小减少到 52,000 MB。
DBCC SHRINKFILE (4, 52000);
如果想将分配给文件的空间缩小到最小,请执行以下语句而不指定目标大小:
DBCC SHRINKFILE (4);
如果工作负载与收缩同时运行,它可能会在收缩完成并截断文件之前开始使用收缩释放的存储空间。 在这种情况下,系统无法将已分配的空间减少到指定的大小。
若要避免此问题,请以较小的步骤收缩每个文件。 在命令中 DBCC SHRINKFILE ,设置的目标略小于文件的当前分配空间,如 基线空间使用情况查询的结果所示。 例如,如果为 file_id 为 4 的文件分配的空间是 200,000 MB,并且要将其缩小到 100,000 MB,则可以先将目标设置为 170,000 MB:
DBCC SHRINKFILE (4, 170000);
此命令截断文件并将其分配的大小缩减为 170,000 MB。 然后,可以重复此命令,先将目标设置为 140,000 MB,再设置为 110,000 MB,依此类推,直到文件缩小到所需的大小。 如果命令完成但文件未截断,请使用较小的步幅,例如 15,000 MB(而不是 30,000 MB)。
若要监视所有并发运行的收缩会话的收缩进度,可以使用以下查询:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
注意
收缩进度可以是非线性的,并且列中的值 percent_complete 可能在很长一段时间内保持不变,即使仍在进行收缩。
当所有数据文件的收缩完成后,请重新运行 空间使用情况查询(或在 Azure 门户中查看),以确定分配的存储大小的减少情况。 如果已用空间与分配的空间之间仍有较大差异,请 重新生成索引。 索引重新生成可以暂时增加分配的空间。 重新生成索引后再次收缩数据文件,应会导致分配的空间显著减少。
收缩期间出现暂时性错误
收缩命令有时可能会失败,并导致出现各种错误,例如超时和死锁。 一般情况下,这些错误是暂时性的,如果重复相同的命令,这些错误不会再次出现。 如果收缩失败并出现错误,则会保留到目前为止所做的进度。 再次运行同一收缩命令以继续收缩文件。
以下示例脚本演示如何在重试循环中运行压缩。 当发生超时错误或死锁错误时,循环会自动重试操作,次数可配置。 此重试方法适用于收缩期间可能发生的许多其他错误。
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
除了超时和死锁之外,收缩操作可能因某些已知问题而遇到错误。
返回的错误和缓解步骤如下所示:
- 错误编号:49503,错误消息:%.*ls: 页 %d:%d 无法移动,因为该页是一个行外永久版本存储页。页暂留原因: %ls。页暂留时间戳: %I64d。
当长期运行的活动事务在持久性版本存储(PVS)中生成行版本时,会发生此错误。 收缩操作无法移动包含行版本的页面。
若要缓解问题,必须等到长时间运行的事务完成。 或者,可以识别和终止长时间运行的事务,但如果应用程序未正常处理事务故障,则可能会影响应用程序。 查找长时间运行的事务的一种方法是,在执行了收缩命令的数据库中运行以下查询:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
可以使用 KILL 命令并指定查询结果中关联的 session_id 值来终止事务:
KILL 4242; -- replace 4242 with the session_id value from query results
注意
终止事务可能会对工作负载产生负面影响。
长时间运行的事务完成后,内部后台任务将清理不再需要的行版本。 可以使用以下查询监视 PVS 大小以衡量清理进度。 在运行收缩命令的数据库中运行查询:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
一旦 persistent_version_store_size_gb 列中报告的 PVS 大小相较于初始大小大幅减少,重新运行收缩操作通常就会成功。
- 错误号:5223,错误消息:%.*ls:空页 %d:%d 无法解除分配。
如果存在正在进行的索引维护操作(例如 ALTER INDEX),则可能会发生此错误。 完成这些操作后,重试收缩命令。
如果此错误仍然存在,可能需要重新生成关联的索引。 若要查找要重新生成的索引,请在运行收缩命令的同一数据库中执行以下查询:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
在执行此查询之前,请将 <file_id> 和 <page_id> 占位符替换为收到的错误消息中的实际值。 例如,如果消息是“空页 1:62669 无法解除分配”,则 为 <file_id>,1 为 <page_id>62669。
重新生成由查询标识的索引,然后重试收缩命令。
- 错误号:5201,错误消息:DBCC SHRINKDATABASE: 已跳过数据库 ID %d 的文件 ID %d,因为该文件没有足够的可用空间可以回收。
此错误意味着无法进一步收缩数据文件。 可以转到下一个数据文件。
相关内容
有关数据库最大大小的信息,请参阅:
- Azure SQL Database基于vCore的单一数据库购买模型限制
- 使用基于 DTU 的购买模型的单一数据库的资源限制
- Azure SQL Database vCore购买模型的弹性池限制
- 使用基于 DTU 的购买模型的弹性池的资源限制