适用范围:![]() NoSQL
NoSQL
本文基于多个 Azure Cosmos DB 概念,例如数据建模、分区和预配吞吐量,演示如何完成一个真实数据设计练习。
如果你平时主要使用关系数据库,可能在设计数据模型方面已经形成了自己的习惯和直觉。 由于具体的约束,加上 Azure Cosmos DB 的独特优势,其中的大部分最佳做法不能产生很好的效果,甚至可能会生成欠佳的解决方案。 本文旨在引导你完成 Azure Cosmos DB 中的真实用例建模的整个过程,包括项的建模,以及实体共置和容器分区。
下载或查看社区生成的源代码,其中阐释了本文中的概念。 此代码示例由社区参与者贡献,Azure Cosmos DB 团队不对其维护提供支持。
方案
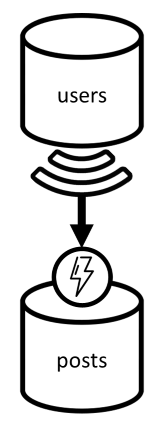
对于本练习,我们假设有一个博客平台域,用户可在其中创建帖子。 用户还可以点赞和评论这些贴子。
提示
本文以斜体突出显示了某些词语,这些词语表示我们的模型需要处理的“事情”类型。
将更多的要求添加到规范:
- 首页显示最近创建的帖子的源,
- 我们可以提取某个用户的所有帖子、对某个帖子发表的所有评论,以及某个帖子的所有点赞数,
- 帖子将连同其作者的用户名以及这些帖子获得的评论数和点赞数一起返回,
- 评论和点赞也会连同评论者和点赞者的用户名一起返回,
- 以列表形式显示时,帖子只需显示其内容的截断的摘要。
标识主要访问模式
在开始之前,让我们通过标识解决方案的访问模式,来为初始规范提供某种结构。 设计 Azure Cosmos DB 的数据模型时,必须了解模型需要为哪些请求提供服务,以确保模型能够有效地为这些请求提供服务。
为使整个过程更易于遵循,我们借用了 CQRS 中的某个词汇表,将这些不同的请求分类为命令或查询,其中,命令表示写入请求(即,更新系统的意图),查询表示只读的请求。
下面是平台必须公开的请求列表:
- [C1] 创建/编辑用户
- [Q1] 检索用户
- [C2] 创建/编辑帖子
- [Q2] 检索帖子
- [Q3] 以短格式列出用户的帖子
- [C3] 创建评论
- [Q4] 列出帖子的评论
- [C4] 为帖子点赞
- [Q5] 列出帖子的点赞数
- [Q6] 以短格式列出最近创建的 x 个帖子(源)
在此阶段,我们尚未考虑每个实体(用户、帖子等)将要包含的详细信息。 针对关系存储进行设计时,此步骤往往是要处理的最初几个步骤之一,因为我们需要确定这些实体在表、列、外键等方面如何进行转换。对于在写入时不会实施任何架构的文档数据库,基本上不必要予以考虑。
必须从一开始就标识访问模式的主要原因在于,请求列表将会成为我们的测试套件。 每当循环访问数据模型时,我们都会遍历每个请求,并检查其性能和可伸缩性。 我们计算每个模型中消耗的请求单位并对其进行优化。 所有这些模型都使用默认索引策略,你可以通过为特定属性编制索引来覆盖该策略,这可以进一步改善 RU 消耗量和延迟。
V1:第一个版本
从两个容器着手:users 和 posts。
用户容器
此容器仅存储用户项:
{
"id": "<user-id>",
"username": "<username>"
}
我们按 id 将此容器分区,这意味着,该容器中的每个逻辑分区仅包含一个项。
帖子容器
此容器包含帖子、评论和点赞数:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
我们按 postId 将此容器分区,这意味着,该容器中的每个逻辑分区包含一个帖子、对该帖子的所有评论,以及该帖子的所有点赞数。
请注意,我们在此容器存储的项中引入了一个 type 属性,以区分此容器包含的三种实体类型。
另外,我们已选择引用相关的数据而不是嵌入这些数据(有关这些概念的详细信息,请查看此部分),因为:
- 用户可以创建的帖子数没有上限;
- 帖子可以是任意长度;
- 帖子产生的评论数和点赞数没有上限;
- 我们希望能够在无需更新帖子本身的情况下,为帖子添加评论或点赞。
模型的性能如何?
现在,让我们评估第一个版本的性能和可伸缩性。 对于前面标识的每个请求,我们将测量其延迟,及其消耗的请求单位数。 这种测量是针对某个虚构数据集进行的。该数据集包含 100,000 个用户,每个用户发布了 5 到 50 个帖子,每个帖子产生了 25 条评论和 100 次点赞。
[C1] 创建/编辑用户
可以直截了当地实现此请求,因为我们只需在 users 容器中创建或更新某个项。 得益于 id 分区键,请求将合理分散在所有分区之间。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 7 毫秒 | 5.71 RU | ✅ |
[Q1] 检索用户
通过读取 users 容器中的相应项来检索用户。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 2 毫秒 | 1 RU | ✅ |
[C2] 创建/编辑帖子
类似于 [C1] ,我们只需写入到 posts 容器。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 9 毫秒 | 8.76 RU | ✅ |
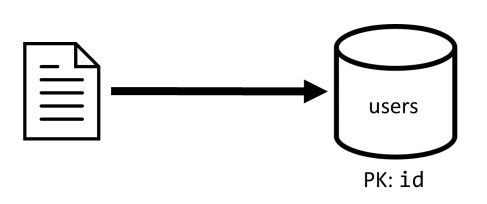
[Q2] 检索帖子
首先检索 posts 容器中的相应文档。 但这并不足够,根据规范,我们还需要聚合帖子作者的用户名以及此帖子产生的评论和点赞数,这需要发出 3 个附加的 SQL 查询。
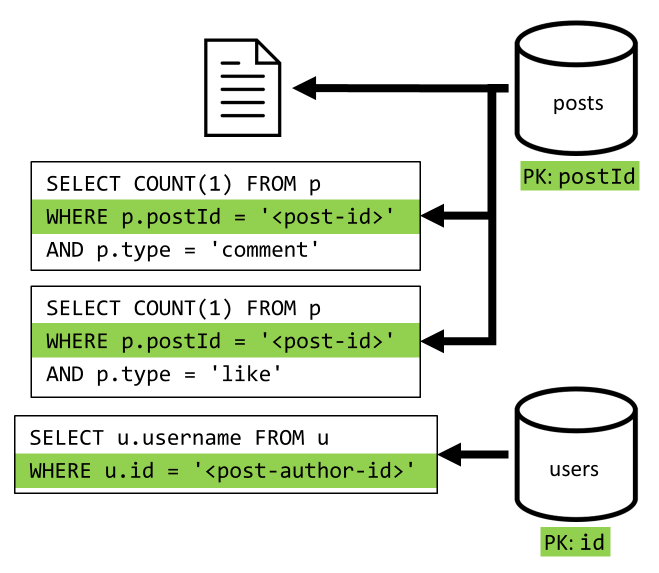
每个附加查询根据相应容器的分区键进行筛选,而我们恰好需要使用分区来最大化性能和可伸缩性。 但是,我们最终需要执行四个操作才能返回一个帖子,因此,我们将在下一次迭代中改进此方法。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 9 毫秒 | 19.54 RU | ⚠ |
[Q3] 以短格式列出用户的帖子
首先,必须使用一个 SQL 查询来检索所需的帖子。该查询会提取对应于该特定用户的帖子。 但是,我们还需要发出附加的查询来聚合作者的用户名以及评论数和点赞数。
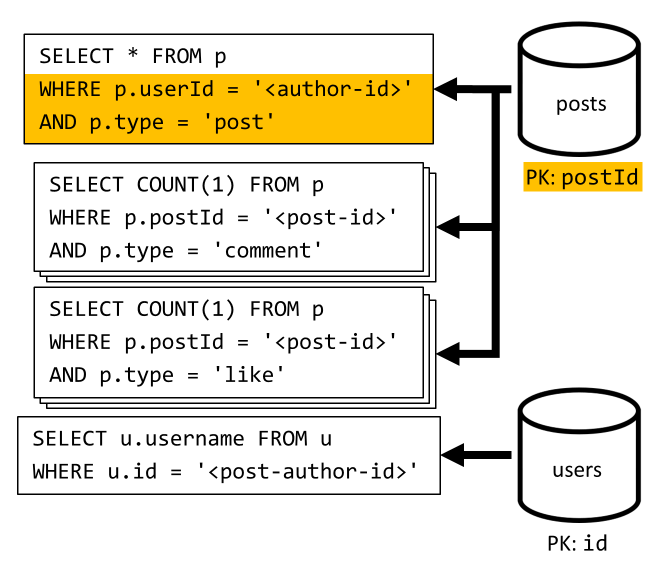
此实现存在许多缺点:
- 必须针对第一个查询返回的每个帖子,发出用于聚合评论数和点赞数的查询;
- 主查询不会根据
posts容器的分区键进行筛选,导致扇出并在整个容器中进行分区扫描。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 130 毫秒 | 619.41 RU | ⚠ |
[C3] 创建评论
通过在 posts 容器中写入相应的项来创建评论。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 7 毫秒 | 8.57 RU | ✅ |
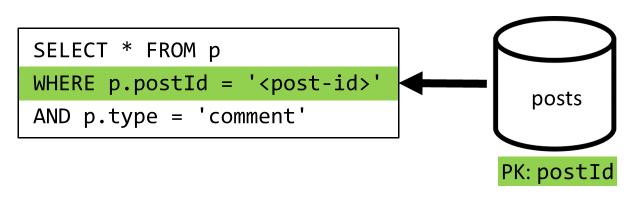
[Q4] 列出帖子的评论
首先使用一个查询提取该帖子的所有评论,同样,我们也需要单独聚合每条评论的用户名。
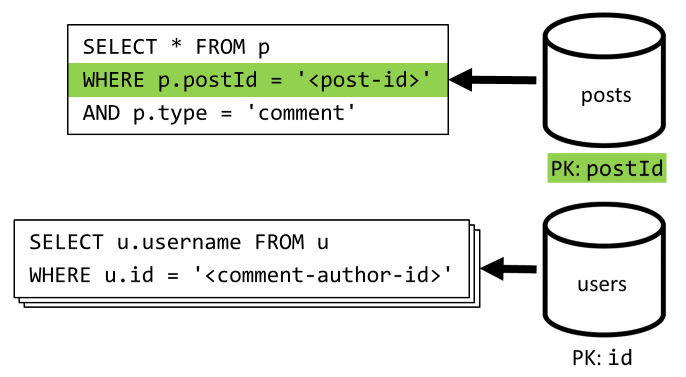
尽管主查询会根据容器的分区键进行筛选,但单独聚合用户名会降低总体性能。 稍后我们将会改进。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 23 毫秒 | 27.72 RU | ⚠ |
[C4] 为帖子点赞
类似于 [C3] ,我们将在 posts 容器中创建相应的项。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 6 毫秒 | 7.05 RU | ✅ |
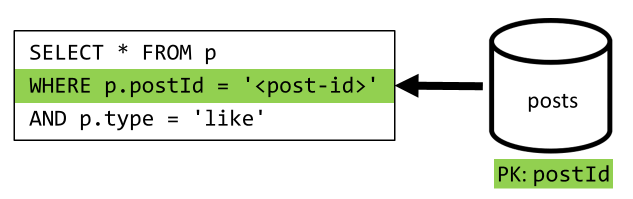
[Q5] 列出帖子的点赞数
类似于 [Q4] ,我们将查询该帖子的点赞数,然后聚合点赞者的用户名。
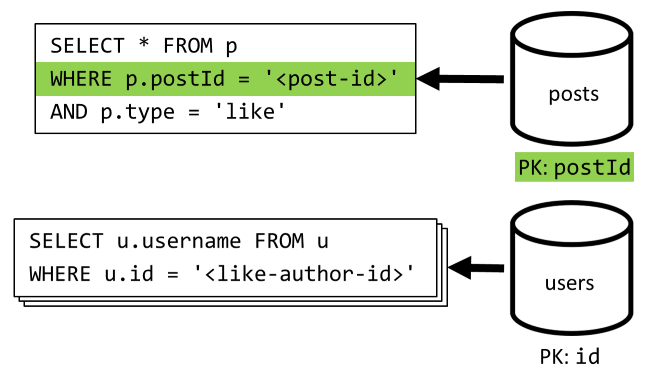
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 59 毫秒 | 58.92 RU | ⚠ |
[Q6] 以短格式列出最近创建的 x 个帖子(源)
我们通过查询 posts 容器来提取最近的帖子(按创建日期的降序排序),然后聚合每个帖子的用户名以及评论数和点赞数。
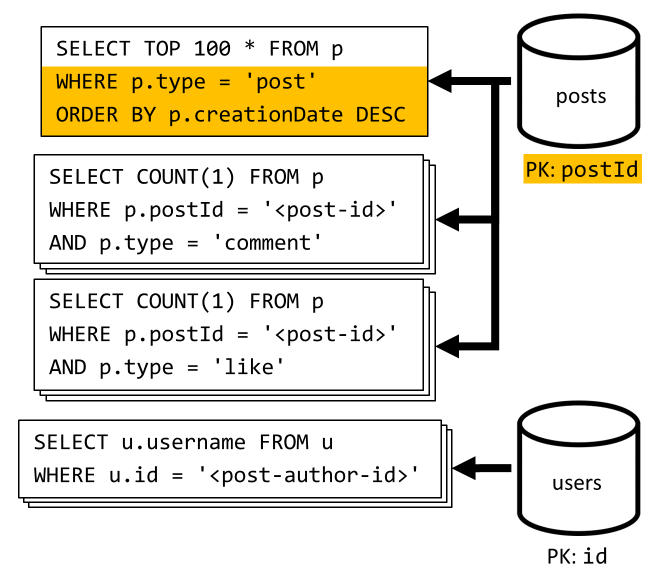
同样,我们的初始查询不会根据 posts 容器的分区键进行筛选,这会触发高开销的扇出。但这一次情况更糟,因为我们的目标是一个大得多的结果集,并要使用 ORDER BY 子句将结果排序,因此会消耗更多的请求单位。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 306 毫秒 | 2063.54 RU | ⚠ |
反映 V1 的性能
分析在上一部分遇到的性能问题,我们可以发现存在两类主要问题:
- 某些请求要求发出多个查询来收集需要返回的所有数据;
- 某些查询不会根据它们所针对的容器的分区键进行筛选,导致发生扇出,使可伸缩性受到阻碍。
让我们解决上述每个问题,从第一个问题开始。
V2:引入反规范化以优化读取查询
之所以需要在某些情况下发出附加请求,是因为初始请求的结果不包含需要返回的所有数据。 使用 Azure Cosmos DB 之类的非关系数据存储时,通常可以通过反规范化数据集中的数据来解决此类问题。
在本示例中,我们将修改帖子项,以添加帖子作者的用户名,以及评论数和点赞数:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
此外,我们将修改评论和点赞项,以添加评论者和点赞者的用户名:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
反规范化评论数和点赞数
我们要实现的目的是,每次添加评论或点赞时,都会递增相应帖子中的 commentCount 或 likeCount。 由于 posts 容器已按 postId 分区,新项(评论或点赞)及其相应帖子将位于同一个逻辑分区中。 因此,我们可以使用某个存储过程来执行该操作。
现在,在创建评论 ( [C3] ) 时,我们不仅需要在 posts 容器中添加新项,而且还要针对该容器调用以下存储过程:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
此存储过程采用帖子 ID 和新评论的正文作为参数,然后:
- 检索帖子
- 递增
commentCount - 替换帖子
- 添加新评论
由于存储过程是作为原子事务执行的,因此 commentCount 的值和实际评论数始终保持同步。
添加新的点赞来递增 likeCount 时,我们将显式调用类似的存储过程。
反规范化用户名
对于用户名,需要采用不同的方法,因为用户不仅位于不同的分区中,而且还位于不同的容器中。 如果必须反规范化不同分区和容器中的数据,可以使用源容器的更改源。
在本示例中,每当用户更新其用户名时,我们都会使用 users 容器的更改源来做出反应。 如果发生这种情况,我们会针对 posts 容器调用另一个存储过程来传播更改:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
此存储过程采用用户 ID 和用户的新用户名作为参数,然后:
- 提取与
userId匹配的所有项(可能是帖子、评论或点赞) - 对于其中的每个项
- 替换
userUsername - 替换项
- 替换
重要
此操作的开销较大,因为需要针对 posts 容器的每个分区执行此存储过程。 假设大多数用户在注册期间选择了适当的用户名,并且以后永远不会更改此用户名,因此,极少运行这种更新。
V2 有多大的性能提升?
[Q2] 检索帖子
完成反规范化后,只需提取单个项即可处理该请求。
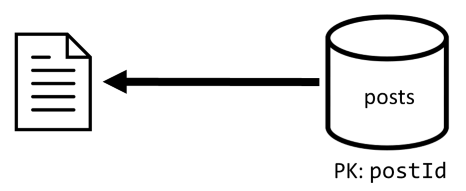
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 2 毫秒 | 1 RU | ✅ |
[Q4] 列出帖子的评论
同样,我们无需发出额外的请求来提取用户名,最终只需运行一个可以根据分区键进行筛选的查询。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 4 毫秒 | 7.72 RU | ✅ |
[Q5] 列出帖子的点赞数
列出点赞时,情况完全相同。
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 4 毫秒 | 8.92 RU | ✅ |
V3:确保所有请求都可缩放
分析我们的总体性能改进,可以发现仍有两个请求未得到完全优化: [Q3] 和 [Q6] 。 这些请求涉及到不根据其所针对的容器的分区键进行筛选的查询。
[Q3] 以短格式列出用户的帖子
此请求已受益于 V2 中引入的改进,可以免除附加的查询。

但是,剩余的查询仍不根据 posts 容器的分区键进行筛选。
查明此问题的原因其实非常简单:
- 此请求必须根据
userId进行筛选,因为我们需要提取特定用户的所有帖子 - 它的性能之所以不佳,是因为它是针对
posts容器执行的,而该容器的分区依据不是userId - 明白地讲,我们需要针对某个容器执行此请求来解决性能问题,该容器的分区依据为
userId - 正好我们已有这样一个容器:
users容器!
因此,我们通过将整个帖子复制到 users 容器,来引入第二级反规范化。 这样,我们便可以有效地获取只按一个不同维度分区的帖子副本,从而可以更有效地按帖子的 userId 来检索帖子。
users 容器现在包含 2 种类型的项:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
请注意:
- 我们在用户项中引入了
type字段,以便将用户与帖子区分开来; - 我们还在用户项中添加了
userId字段,该字段似乎是多余的,因为存在id字段。但是,该字段是必需的,因为users容器现在按userId分区(而不像以前一样按id分区)
若要实现这种反规范化,我们将再次使用更改源。 这一次,我们将对 posts 容器的更改源做出反应,以将任何新的或更新的帖子调度到 users 容器。 由于列出帖子不需要返回其完整内容,我们可以在列出过程中截断帖子。
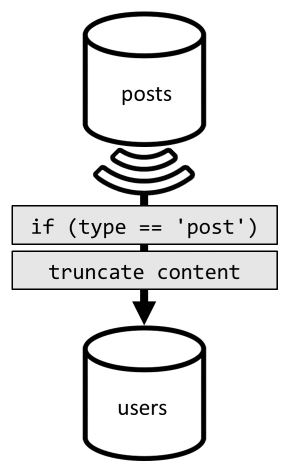
现在,可将查询路由到 users 容器,并根据该容器的分区键进行筛选。

| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 4 毫秒 | 6.46 RU | ✅ |
[Q6] 以短格式列出最近创建的 x 个帖子(源)
在此处必须处理类似的情况:尽管实现 V2 中引入的反规范化后无需运行附加的查询,但是,剩余的查询仍不会根据容器的分区键进行筛选:
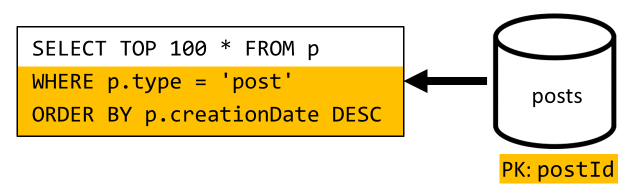
遵循相同的方法最大化此请求的性能和可伸缩性要求只命中一个分区。 这是一种可行的做法,因为我们只需返回有限数量的项;若要填充博客平台的主页,我们只需获取 100 个最近的帖子,而无需通过整个数据集分页。
为了优化这最后一个请求,我们在设计中引入了第三个容器,该容器专门为此请求提供服务。 将帖子反规范化为该新的 feed 容器:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
此容器按 type(始终为项中的 post)分区。 这可以确保此容器中的所有项位于同一个分区。
若要实现反规范化,我们只需挂接前面引入的更改源管道,以将帖子调度到该新容器。 要记住的一个要点是,需要确保只存储 100 个最近的帖子;否则,容器内容可能会增大到超过分区的最大大小。 为此,可以在每次将文档添加到容器中时,调用 post-trigger:
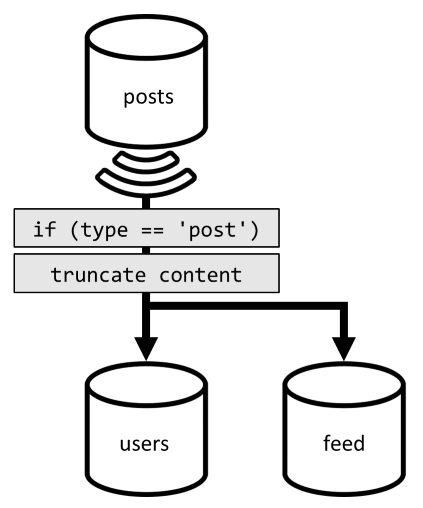
下面是用于截断集合的 post-trigger 的正文:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
最后一步是将查询重新路由到新的 feed 容器:
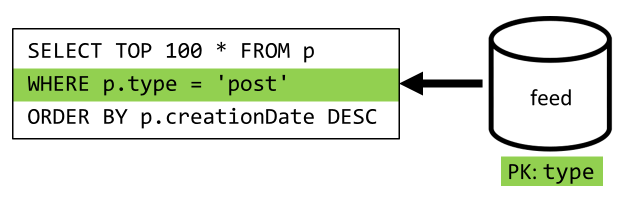
| 延迟 | RU 开销 | “性能” |
|---|---|---|
| 9 毫秒 | 16.97 RU | ✅ |
结论
让我们分析一下在不同设计版本中引入的总体性能和可伸缩性改进。
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 毫秒 / 5.71 RU | 7 毫秒 / 5.71 RU | 7 毫秒 / 5.71 RU |
| [Q1] | 2 毫秒 / 1 RU | 2 毫秒 / 1 RU | 2 毫秒 / 1 RU |
| [C2] | 9 毫秒 / 8.76 RU | 9 毫秒 / 8.76 RU | 9 毫秒 / 8.76 RU |
| [Q2] | 9 毫秒 / 19.54 RU | 2 毫秒 / 1 RU | 2 毫秒 / 1 RU |
| [Q3] | 130 毫秒 / 619.41 RU | 28 毫秒 / 201.54 RU | 4 毫秒 / 6.46 RU |
| [C3] | 7 毫秒 / 8.57 RU | 7 毫秒 / 15.27 RU | 7 毫秒 / 15.27 RU |
| [Q4] | 23 毫秒 / 27.72 RU | 4 毫秒 / 7.72 RU | 4 毫秒 / 7.72 RU |
| [C4] | 6 毫秒 / 7.05 RU | 7 毫秒 / 14.67 RU | 7 毫秒 / 14.67 RU |
| [Q5] | 59 毫秒 / 58.92 RU | 4 毫秒 / 8.92 RU | 4 毫秒 / 8.92 RU |
| [Q6] | 306 毫秒 / 2063.54 RU | 83 毫秒 / 532.33 RU | 9 毫秒 / 16.97 RU |
我们已优化一个读取密集型方案
你可能已注意到,我们在牺牲写入请求(命令)性能的情况下,集中精力改善了读取请求(查询)的性能。 在许多情况下,写入操作现在会通过更改源触发后续的反规范化,因此,其计算开销更大,且具体化的时间更长。
这种方案是合理的,因为博客平台(类似于大多数社交应用)是读取密集型的,这意味着,它需要服务的读取请求数量往往比写入请求数量要高几个数量级。 因此,提高所要执行的写入请求的开销是有利的,这可以降低读取请求的开销,并提高其性能。
执行极端优化后我们发现, [Q6] 的开销已从 2000 多个 RU 降到了 17 个 RU;这种改进是通过反规范化帖子实现的,每个项的开销大约为 10 RU。 由于我们要服务的源请求比帖子创建或更新请求要多得多,在考虑到总体节省的情况下,这种反规范化带来的开销可以忽略不计。
可以增量方式应用反规范化
本文中探讨的可伸缩性改进涉及到反规范化,以及复制整个数据集中的数据。 请注意,不一定要在第 1 天就完成这些优化。 根据分区键筛选的查询在大规模执行时的性能更佳,但是,如果极少调用跨分区查询或者针对有限的数据集调用此类查询,则其性能也完全可接受。 如果你只是要生成一个原型,或者要推出一款用户群较小并且受控的产品,则也许可以在今后再实施这些改进;重要的是监视模型的性能,以便可以确定是否以及何时将其投放生产。
用于将更新分发到其他容器的更改源会持久存储所有这些更新。 这样,便可以请求所有更新,因为即使系统已包含大量的数据,创建容器和启动反规范化的视图也是一次性的同步操作。
后续步骤
完成这篇有关数据建模和分区实践的简介文章后,建议接下来阅读以下文章,以了解本文涉及的概念:
正在尝试为迁移到 Azure Cosmos DB 进行容量计划? 可以使用有关现有数据库群集的信息进行容量规划。
- 如果只知道现有数据库群集中的 vCore 和服务器数量,请阅读使用 vCore 或 vCPU 估算请求单位
- 若知道当前数据库工作负载的典型请求速率,请阅读使用 Azure Cosmos DB 容量计划工具估算请求单位