Azure Cosmos DB 使用分区缩放数据库中的容器以满足应用程序的性能需求。 容器中的项分为不同的子集,称为逻辑分区。 逻辑分区形式基于与容器中的每个项关联的 分区键 的值。 逻辑分区中的所有项都具有相同的分区键值。
例如,某个容器保存项。 每个项具有唯一的 UserID 属性值。 如果 UserID 充当容器中的项的分区键,并且有 1,000 个唯一的 UserID 值,则会为容器创建 1,000 个逻辑分区。
容器中的每个项都有一个 分区键 ,用于确定其逻辑分区以及该分区中唯一 的项 ID 。 将分区键与项 ID 相结合可创建项的索引,用来唯一地标识该项。 分区键的选择非常重要,它会影响应用程序的性能。
注意
在某些分布式数据库系统和学习材料中,术语 分片键 用于描述用于确定数据如何在分片之间分布的属性。 在 Azure Cosmos DB 中,这一概念称为 分区键。
这两个术语都指用于分发和定位数据的值,但 分区键 是整个 Azure Cosmos DB 文档和 API 中使用的官方和正确的术语。
本文介绍逻辑分区与物理分区之间的关系,讨论分区的最佳做法,并深入地了解 Azure Cosmos DB 中的水平缩放的工作原理。 无需了解这些内部详细信息来选择分区键,但本文将介绍它们以阐明 Azure Cosmos DB 的工作原理。
逻辑分区
逻辑分区是共享同一分区键的一组项。 例如,在包含食物营养相关数据的容器中,所有项都包含 foodGroup 属性。 用作 foodGroup 容器的分区键。 具有特定 foodGroup 值(例如 Beef Products、Baked Products 和 Sausages and Luncheon Meats)的项组构成了独立的逻辑分区。
逻辑分区也定义数据库事务的范围。 可以使用支持快照隔离的事务来更新逻辑分区中的项。 当向容器中添加新项时,系统会以透明的方式创建新的逻辑分区。 无需担心在删除基础数据时是否会删除逻辑分区。
容器中的逻辑分区数没有限制。 每个逻辑分区最多可保存 20 GB 的数据。 有效的分区键具有广泛的可能值。 例如,在一个其中所有项都包含 foodGroup 属性的容器中,Beef Products 逻辑分区内的数据最多可以增长到 20 GB。
选择具有多种可能值的分区键会确保容器能够缩放。
使用 Azure Monitor 警报 来监视逻辑分区的大小是否接近 20 GB。
物理分区
容器通过跨物理分区分布数据和吞吐量进行缩放。 在内部,一个或多个逻辑分区映射到单个物理分区。 通常,较小的容器具有许多逻辑分区,但只需要单个物理分区。 与逻辑分区不同,物理分区是内部系统实现,Azure Cosmos DB 完全管理它们。
容器中的物理分区数取决于以下特征:
预配的吞吐量(每个单独的物理分区最多可以提供每秒 10,000 个请求单位的吞吐量)。 由于每个逻辑分区仅会映射到一个物理分区,若物理分区受到 10,000 RU/秒的限制,则意味着逻辑分区也会受 10,000 RU/秒的限制。
总数据存储(每个单独的物理分区最多可以存储 50 GB 的数据)。
注意
物理分区是由 Azure Cosmos DB 完全托管的内部系统实现。 开发解决方案时,请不要将重点放在物理分区上,因为你无法对其进行控制。 而是将注意力集中在分区键上。 选择跨逻辑分区均匀分配吞吐量消耗的分区键可确保在物理分区之间均衡的吞吐量消耗。
容器中物理分区总数没有限制。 随着预配的吞吐量或数据量规模的增长,Azure Cosmos DB 会拆分现有物理分区,从而自动创建新物理分区。 物理分区拆分不影响应用程序可用性。 物理分区拆分后,单个逻辑分区内的所有数据仍将存储在同一个物理分区中。 物理分区拆分只是创建逻辑分区到物理分区的新映射。
容器的预配吞吐量在物理分区之间均匀划分。 不均匀分配请求的分区键设计可能会导致定向到“热”的一小部分分区的请求过多。热分区导致预配吞吐量的使用效率低下,这可能会导致速率限制和更高的成本。
例如,假设有一个容器,其路径 /foodGroup 指定为分区键。 容器可以有任意数量的物理分区,但在此示例中,我们假定它有三个。 单个物理分区可以包含多个分区键。 例如,最大的物理分区可能包含前三个最大的逻辑分区:Beef Products、Vegetable and Vegetable Products 和 Soups, Sauces, and Gravies。
如果分配的吞吐量为每秒 18,000 个请求单位(RU/秒),则三个物理分区中的每一个都使用预配的总吞吐量的三分之一。 在选定的物理分区中,逻辑分区键 Beef Products、Vegetable and Vegetable Products 和 Soups, Sauces, and Gravies 可以共同利用为物理分区预配的每秒 6,000 个 RU。 由于预配的吞吐量是在容器的物理分区间平均分配的,因此,请务必选择平均分配吞吐量消耗的分区键。 有关详细信息,请参阅 选择正确的逻辑分区键。
管理逻辑分区
Azure Cosmos DB 自动管理逻辑分区在物理分区上的放置,以满足容器的可伸缩性和性能需求。 当应用程序的吞吐量和存储要求增加时,Azure Cosmos DB 会移动逻辑分区,以将负载分散到更多物理分区。 详细了解 物理分区。
Azure Cosmos DB 使用基于哈希的分区在物理分区之间分配逻辑分区。 Azure Cosmos DB 对项的分区键值进行哈希处理。 哈希处理结果确定了逻辑分区。 然后,Azure Cosmos DB 在物理分区之间均匀分配分区键哈希的键空间。
仅允许单个逻辑分区中的项使用存储过程或触发器中的事务。
副本集
每个物理分区由一组副本组成,也称为 副本集。 每个副本都托管数据库引擎的一个实例。 副本集使物理分区中的数据存储具有持久性、高可用性和一致性。 物理分区中的每个副本都继承分区的存储配额。 物理分区的所有副本共同支持分配给该物理分区的吞吐量。 Azure Cosmos DB 自动管理副本集。
较小的容器通常需要单个物理分区,但它们仍至少有四个副本。
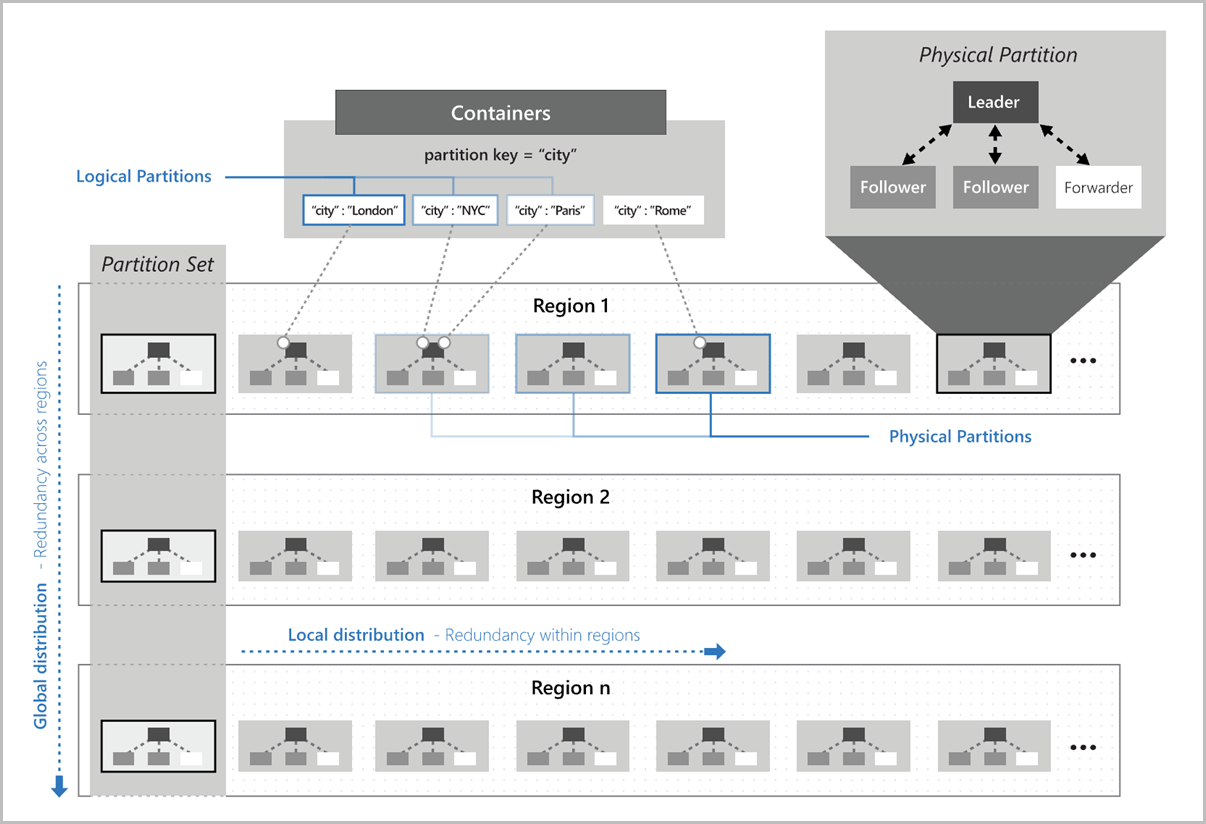
此图显示了逻辑分区如何映射到多区域分布的物理分区。 映像中的分区集是指一组物理分区,这些物理分区跨多个区域管理相同的逻辑分区键:
选择分区键
分区键具有两个组成部分:分区键路径和分区键值。 例如,如果选择“userId”作为分区键,则考虑项 { "userId" : "Andrew", "worksFor": "Microsoft" },以下是两个分区键组件:
分区键路径(例如 "/userId")。 分区键路径支持字母数字和下划线 (_) 字符。 还可以通过标准路径表示法 (/) 来使用嵌套的对象。
分区键值(例如 "Andrew")。 分区键值可以是字符串或数值类型。
了解 Azure Cosmos DB 服务配额 一文中吞吐量、存储和分区密钥长度的限制。
选择分区键是 Azure Cosmos DB 中的一个简单但重要的设计选择。 选择分区键后,无法就地更改它。 如果需要更改分区键,请将数据移动到具有所需分区键的新容器。
对于 所有 容器,分区键应:
是一个属性,并且其值不会更改。 如果某个属性是分区键,那么你不能更新该属性的值。
仅
String包含值,或根据String,将数字转换为双精度数字的边界。 Json 规范解释了为何由于互作性问题而使用此边界之外的数字是一种不良做法。 这些问题尤其与分区键列相关,因为它不可变,并且需要数据迁移才能在以后进行更改。具有较高的基数。 换言之,该属性应具有范围广泛的可能值。
将请求单位 (RU) 消耗和数据存储均匀分配到所有逻辑分区上。 这样的分散方式可确保跨物理分区均匀分配 RU 消耗和存储。
具有通常不大于 2048 字节的值,或者不大于 101 字节的值(如果未启用大分区键)。 有关详细信息,请参阅大分区键
如果在 Azure Cosmos DB 中需要多项 ACID 事务,则需要使用存储过程或触发器。 所有基于 JavaScript 的存储过程和触发器的作用域都是单个逻辑分区。
注意
如果只有一个物理分区,则分区键的值可能不相关,因为所有查询都以相同的物理分区为目标。
分区键的类型
| 分区策略 | 何时使用 | 优点 | 缺点 |
|---|---|---|---|
| 常规分区键 (例如 CustomerId、OrderId) | 当分区键具有高基数并符合查询模式(例如,按 CustomerId 进行筛选)时使用。 适用于查询主要面向单个客户数据的工作负荷(例如,检索客户的所有订单)。 | 易于管理。 当访问模式与分区键匹配时高效查询(例如,查询 CustomerId 的所有订单)。 如果访问模式一致,则防止跨分区查询。 | 如果某些值(例如,少数高流量客户)生成的数据比其他值多,则热分区的风险。 如果特定键的数据量迅速增长,则可能会达到每个逻辑分区的 20 GB 限制。 |
| 合成分区键 (例如 CustomerId + OrderDate) | 当没有单个字段具有高基数且匹配查询模式时使用。 适用于写入密集型工作负荷,其中数据需要均匀分布在物理分区(例如,许多订单都放在同一日期)。 | 帮助跨分区均匀分布数据,减少热分区(例如,按 CustomerId 和 OrderDate 分发订单)。 将写入分散到多个分区,并提高吞吐量。 | 仅按一个字段(例如 CustomerId)进行筛选的查询可能会导致跨分区查询。 跨分区查询可能会导致 RU 消耗量较高(每个物理分区的 2-3 RU/秒额外费用)并增加了延迟。 |
| 分层分区键 (HPK) (例如 CustomerId/OrderId、StoreId/ProductId) | 需要多级分区来支持大规模数据集时使用。 当查询筛选层次结构的第一个和第二个级别时,理想。 | 通过创建多个分区级别来帮助避免 20 GB 的限制。 对两个分层级别的高效查询(例如,先按 CustomerID 筛选,再按 OrderID 筛选)。 最大程度地减少针对顶级查询的跨分区查询(例如,从特定 CustomerID 检索所有数据)。 | 需要仔细规划以确保一级密钥具有较高的基数,并且包含在大多数查询中。 比常规分区键更复杂。 如果查询与层次结构不一致(例如,仅当 CustomerID 为第一级时按 OrderID 进行筛选),则查询性能可能会受到影响。 |
读取密集型容器的分区键
对于大多数容器,选择分区键时需要考虑这些条件。 但对于较大的读取密集型容器,可能需要选择在查询中经常作为筛选器出现的分区键。 在筛选器谓词中包括分区键可 有效地将查询路由到相关的物理分区。
如果大多数工作负荷的请求是查询,并且大多数查询对同一属性使用相等筛选器,则此属性是一个很好的分区键选择。 例如,如果经常运行在 UserID 上筛选的查询,则选择 UserID 作为分区键将减少跨分区查询的数目。
如果容器较小,则可能没有足够的物理分区来担心跨分区查询的性能。 Azure Cosmos DB 中的大多数小容器只需要一个或两个物理分区。
如果容器可能会增长到许多个物理分区,则应确保选择一个可以最大程度地减少跨分区查询的分区键。 如果满足以下任一情况,容器需要多个物理分区:
容器已预配超过 30,000 个请求单位
容器存储的数据超过 100 GB
使用项 ID 作为分区键
注意
本部分主要适用于 API for NoSQL。 其他 API(例如 Gremlin API)不支持唯一标识符作为分区键。
如果容器具有具有各种可能值的属性,则可能是一个很好的分区键选择。 此类属性的示例是 项 ID。 对于较小的读取密集型容器或任意大小的写入密集型容器,项 ID (/id) 自然是很好的分区键选择。
系统属性 项 ID 存在于容器中的每个项中。 可能会有其他用于表示项逻辑 ID 的属性。 在许多情况下,这些唯一标识符也是伟大的分区键选择,原因与 项 ID 相同。
项 ID 是很好的分区键选择,原因如下:
- 其可能值范围十分广泛(每个项一个唯一的项 ID)。
- 由于每个项都有一个唯一的项 ID,因此,项 ID 在均衡 RU 消耗和数据存储方面有显著作用。
- 你可以轻松执行高效的点读取,因为如果知道项的项 ID,就始终知道项的分区键。
选择 项 ID 作为分区键时,请考虑以下注意事项:
- 如果 项 ID 是分区键,则它将成为整个容器的唯一标识符。 无法创建具有重复 标识符的项目。
- 如果一个读取密集型容器有大量物理分区,则当查询具有一个包含项 ID 的等式筛选器时,查询将更高效。
- 存储过程或触发器不能以多个逻辑分区为目标。