Azure Cosmos DB 是 Azure 中的基础服务,因此它部署在所有Azure中国区域。
概括而言,Azure Cosmos DB 容器数据水平分区到多个副本集,在每个区域内复制写入。 副本集使用多数仲裁持久提交写入。
每个区域都包含 Azure Cosmos DB 容器的所有数据分区,并且可以在启用多区域写入时提供读取和写入。 如果 Azure Cosmos DB 帐户分布在 N Azure 区域中,则所有数据至少有 N x 4 个副本。
在数据中心内,我们在大规模的机器组上部署和管理 Azure Cosmos DB,每台机器都有专用的本地存储。 在数据中心内,Azure Cosmos DB 跨多个群集部署,每个群集可能运行多代硬件。 群集中的计算机通常分散在 10 到 20 个容错域之间,以便在一个区域中实现高可用性。 下图显示了 Azure Cosmos DB 多区域分发系统拓扑:
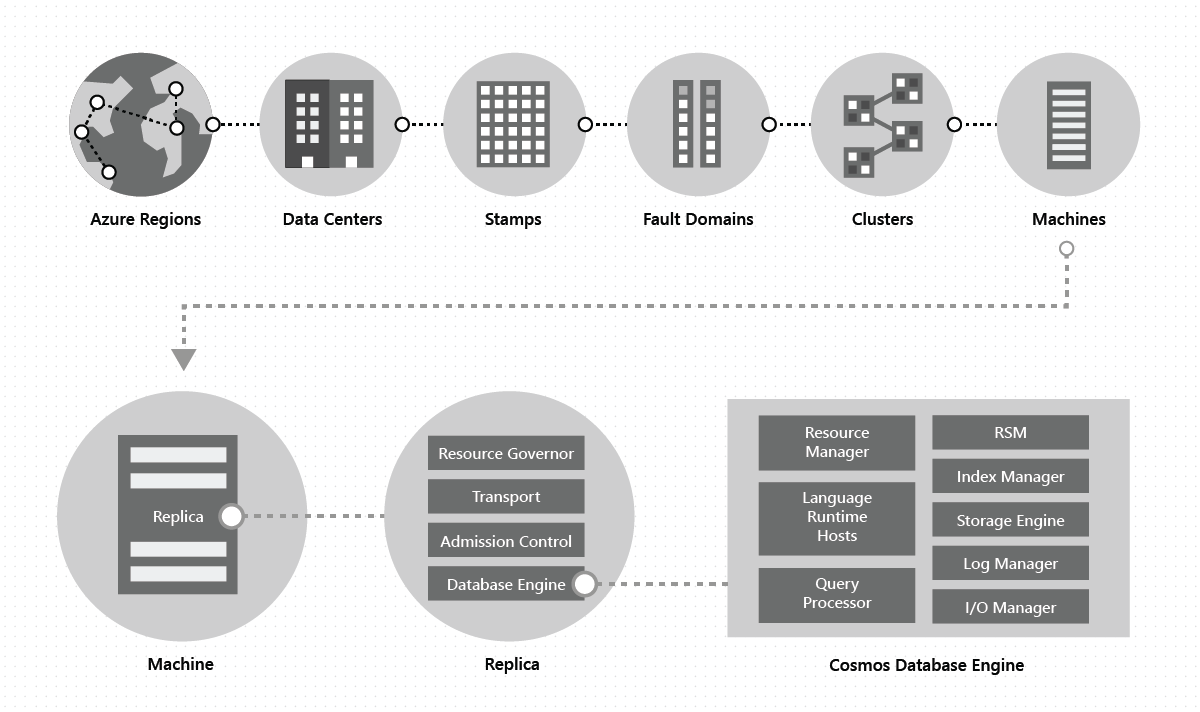
Azure Cosmos DB 中的多个区域分布是即开即用的:随时,只需单击几下鼠标,或者通过单个 API 调用以编程方式,即可添加或删除与 Azure Cosmos DB 数据库关联的区域。 Azure Cosmos DB 数据库又包含一组Azure Cosmos DB 容器。 在 Azure Cosmos DB 中,容器充当分布和可伸缩性的逻辑单元。 创建的集合、表格和图表在内部仅是 Azure Cosmos DB 容器。 容器对架构完全不可知,它提供查询范围。 Azure Cosmos DB 容器中的数据在引入时自动编制索引。 自动编制索引使用户无需进行繁琐的架构或索引管理(尤其是在多区域分布式设置中)就能查询数据。
在给定的区域中,可以使用分区键来分布容器中的数据。分区键由你提供,并由基础物理分区以透明方式进行管理(本地分布)。
每个物理分区还会跨地理区域进行复制(多区域分布)。
当使用 Azure Cosmos DB 的应用在 Azure Cosmos DB 容器上弹性缩放吞吐量或消耗更多存储时,Azure Cosmos DB 自动透明地处理分区管理作业(拆分、克隆、删除),并在所有区域跨区执行。 与规模、分布或故障无关,Azure Cosmos DB 继续提供容器中数据的单一系统视图,而这些容器在多个区域之间进行多区域分布。
如下图所示,容器中的数据沿两个维度分布 - 在某个地区内部和跨区域,整个中国境内。
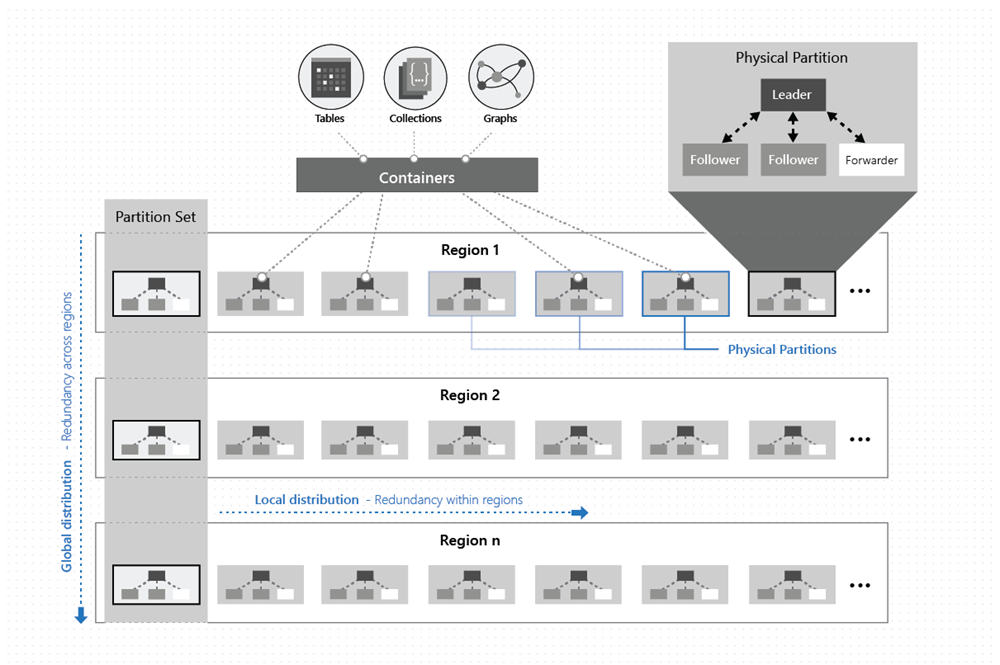
物理分区是通过一组副本(称作副本集)实现的。 每台计算机托管数百个副本,这些副本对应于一组固定进程中的各个物理分区,如上图所示。 对应于物理分区的副本在区域中群集与数据中心内的计算机之间进行动态定位和负载均衡。
副本唯一归属于 Azure Cosmos DB 租户。 每个副本托管 Azure Cosmos DB 的 database engine 实例,该实例管理资源和关联的索引。 Azure Cosmos DB 数据库引擎运行在基于原子-记录-序列(ARS)类型系统的基础上。 该引擎对架构概念不可知,并将记录的结构与实例值之间的边界模糊化。 Azure Cosmos DB 通过以高效方式自动对引入时的所有内容编制索引来实现完全的架构不可知,这样用户就无需处理架构或索引管理即可查询其多区域分布式数据。
Azure Cosmos DB数据库引擎由多个组件组成,包括多种协调基元的实现、语言运行时、查询处理器,及管理事务性存储与数据索引的存储和索引子系统。 为了提供持久性和高可用性,数据库引擎会将其数据和索引保存在 SSD 上,并在副本集中的数据库引擎实例之间分别复制这些数据和索引。 较大的租户对应于更高的吞吐量和存储规模,而且具有更大或更多的副本或两者兼有。 该系统的每个组件是完全异步的 – 永远不会出现线程阻塞,每个线程执行生存期较短的工作,可避免任何不必要的线程切换。 速率限制和反压在从许可控制到所有 I/O 路径的整个堆栈中传播。 Azure Cosmos DB数据库引擎旨在充分利用精细化的并发性,并在有限的系统资源下运行时提供高吞吐量。
Azure Cosmos DB 的多区域分布依赖于两个关键抽象 :replica-sets 和 partition-sets。 副本集是一个模块化构建基块,用于协调,分区集是一个或多个地理分布式物理分区的动态覆盖。 若要了解多区域分布的工作原理,需要了解这两个关键抽象。
副本集
物理分区具体化为一组分散在多个容错域之间的、名为“副本集”的自我托管动态负载均衡副本。 此集统一实现复制的状态机协议,使物理分区中的数据保持高度可用、持久且一致。 副本集成员身份 N 是动态的 - 它根据故障、管理操作以及重新生成/恢复有故障副本所需的时间,在 NMin 与 NMax 之间波动。 复制协议还会根据成员身份的变化来重新配置读取和写入仲裁的大小。 为了均匀分布分配给指定物理分区的吞吐量,我们采用了两种思路:
首先,处理领先者写入请求的开销高于对后继者应用更新的开销。 相应地,为领先者预算的系统资源比后继者更多。
其次,确保给定一致性级别的读取仲裁尽可能地专门由后继者副本组成。 除非有必要,否则我们会避免访问领先者来为读取提供服务。 我们采用了一些关于基于仲裁系统中负载和容量关系的研究理念,用于 Azure Cosmos DB 支持的五种一致性模型。
有关副本集及其与物理分区的关系的详细信息,请参阅 分区副本集。
分区集
一组源自每个配置了 Azure Cosmos DB 数据库区域的物理分区组成,用于管理在所有配置区域中复制的相同密钥集。 这种更高的协调基元称为分区集 - 管理给定键集的物理分区的地理分布式动态叠加层。 给定的物理分区(副本集)限定在群集范围内,而分区集可跨群集、数据中心和地理区域,如下图所示:
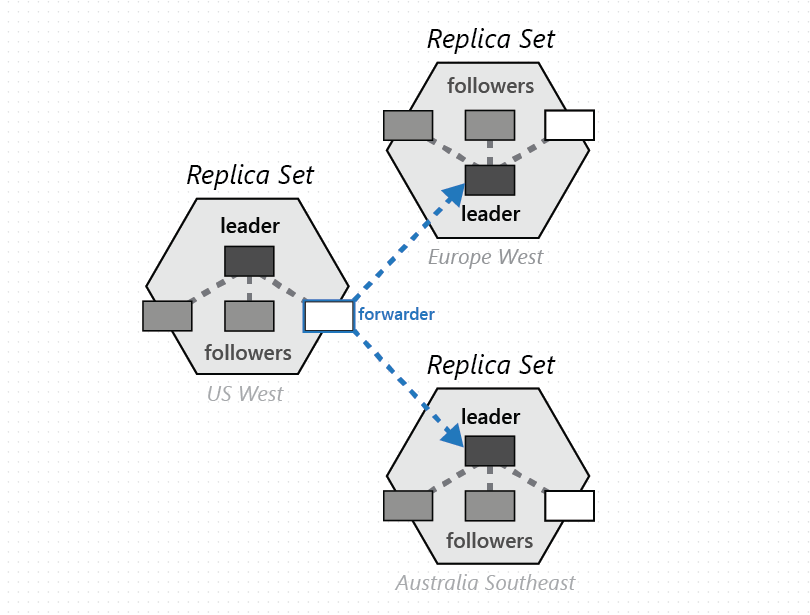
可将分区集视为地理分散的“超副本集”,它由多个拥有相同键集的副本集构成。 与副本集类似,分区集的成员资格也是动态的,它会因隐式的物理分区管理操作(例如,在容器上扩展吞吐量、向 Azure Cosmos DB 数据库添加或删除区域,以及发生故障时)而波动,动态地向给定的分区集添加或移除分区。 由于(分区集的)每个分区可在其自身的副本集中管理分区集成员身份,因此,成员身份是完全分散且高度可用的。 在重新配置分区集期间,还会建立物理分区之间的叠加层拓扑。 该拓扑是根据源与目标物理分区之间的一致性级别、地理距离和可用网络带宽动态选择的。
通过该服务,可以使用单个写入区域或多个写入区域配置 Azure Cosmos DB 数据库,并根据选择将分区集配置为接受一个或多个区域中的写入。 该系统采用两级别嵌套共识协议 – 一个级别在接受写入的物理分区副本集的副本内运行,另一个级别在分区集的级别运行,以针对分区中提交的所有写入操作提供完全有序的保证。 这种多层嵌套共识对于实现严格的 SLA 以实现高可用性以及实现Azure Cosmos DB 为客户提供的一致性模型至关重要。
冲突解决
我们在更新传播、冲突解决和因果关系跟踪的设计灵感来源于以往 Epidemic 算法和 Bayou 系统工作的启发。 虽然这些想法的内核幸存下来,并提供了一个方便的参考框架来传达Azure Cosmos DB 的系统设计,但它们也经历了重大转换,因为我们将它们应用于 Azure Cosmos DB 系统。 这是必需的,因为以前的系统既不是使用资源治理设计的,也不是Azure Cosmos DB 需要运行的规模,也没有提供功能(例如,有限过期一致性)以及Azure Cosmos DB 交付给其客户的严格和全面的 SLA。
回想一下,分区集分布在多个区域,并遵循 Azure Cosmos DB(多区域写入)复制协议,以在包含给定分区集的物理分区之间复制数据。 (分区集的)每个物理分区通常接受写入到该区域本地的客户端,并为读取操作提供服务。 区域中物理分区接受的写入操作在由客户端确认之前,将以持久方式进行提交并在物理分区中保持高可用性。 这些写入是试探性的,将使用反熵通道传播到分区集中的其他物理分区。 客户端可以通过传递请求标头来请求试探性写入或提交的写入。 反熵传播(包括传播频率)是动态的,基于分区集的拓扑、物理分区的区域邻近性,以及配置的一致性级别。 在分区集中,Azure Cosmos DB 遵循主提交方案,并动态选择仲裁分区。 仲裁器的选择是动态的,在基于叠加层拓扑重新配置分区集时,它是不可或缺的一部分。 可保证提交的写入(包括多行/批处理更新)的顺序。
我们采用编码向量时钟(包含分别对应于每个副本集和分区集共识级别的区域 ID 和逻辑时钟)进行因果关系跟踪,并采用版本向量来检测和解决更新冲突。 拓扑和节点选择算法旨在确保版本向量的固定和最小存储空间以及最小网络开销。 该算法可保证严格的融合属性。
对于配置了多个写入区域的 Azure Cosmos DB 数据库,系统提供了许多灵活的自动冲突解决策略供开发人员选择,包括:
- 最后写入优先 (LWW):默认使用系统定义的时间戳属性(基于时间同步时钟协议)。 Azure Cosmos DB 还允许指定要用于解决冲突的任何其他自定义数值属性。
- 应用程序定义的自定义冲突解决策略(通过合并过程表示):旨在使用应用程序定义的语义来调解冲突。 在服务器端检测到数据库事务造成的写入-写入冲突时,将会调用这些过程。 在执行提交协议过程中,该系统可保证正好执行合并过程一次。 我们提供了多个冲突解决方法示例供你演练。
一致性模型
无论是使用单个或多个写入区域配置 Azure Cosmos DB 数据库,都可以从 five 定义完善的一致性模型中进行选择。 这些模型的范围包括从强一致性到最终一致性的不同级别,并影响分区集内副本同步数据的方式。
在多区域分布的上下文中:
- 有限过期性 使用以速率限制的方式的反熵协议,确保前缀不会积累,并且不会无故限制写入。
- 会话一致性 保证单调读取、单调写入、读取你自己的写入、写入遵循读取和一致的前缀,以及围绕中国的一致前缀。
- 强一致性 要求跨区域同步复制,这意味着多区域写入帐户在使用此级别时,不会受益于低写入延迟或高可用性。
有关一致性级别语义和保证的完整详细信息,请参阅 Azure Cosmos DB 中的 Consistency 级别。 还使用 TLA+ 规范对一致性模型进行数学描述。
后续步骤
接下来,请通过以下文章了解如何配置多区域分布:
- 在数据库帐户中添加/删除区域
- 如何创建自定义冲突解决策略
- 尝试为迁移到 Azure Cosmos DB 做容量规划? 可以使用有关现有数据库群集的信息进行容量规划。
- 若只知道现有数据库群集中的 vCore 和服务器数量,请阅读使用 vCore 或 vCPU 估算请求单位
- 如果您知道当前数据库工作负荷的典型请求速率,请阅读有关使用 Azure Cosmos DB 容量规划工具来估计请求单位的文章