Azure Cosmos DB 是一个快速灵活的分布式数据库,可无缝缩放,并保证延迟和吞吐量。 无需进行重大体系结构更改或编写复杂的代码,才能使用 Azure Cosmos DB 缩放数据库。 扩展和缩减操作就像执行单个 API 调用一样简单。 若要了解详细信息,请参阅 如何预配容器吞吐量 或 如何预配数据库吞吐量。 但是,由于Azure Cosmos DB 是通过网络调用访问的,因此在使用 SQL .NET SDK 时,可以通过客户端优化来实现最佳性能。
因此,如果尝试提高数据库性能,请考虑以下选项:
升级到 .NET V3 SDK
.NET v3 SDK 已发布。 如果使用 .NET v3 SDK,请参阅 .NET v3 性能指南了解以下信息:
- 默认为直接 TCP 模式
- 流 API 支持
- 支持自定义序列化程序以允许使用System.Text.JSON
- 集成批处理和批量支持
托管方面的建议
打开服务器端垃圾回收 (GC)
在某些情况下,降低垃圾回收的频率可能会有帮助。 在 .NET 中,将 gcServer 设置为 true。
扩展客户端工作负载
如果您在高吞吐量级别(超过 50,000 RU/秒)进行测试,客户端应用程序可能会成为瓶颈,因为计算机的 CPU 或网络使用率达到了上限。 如果达到此目标,可以通过将客户端应用程序分布到多个服务器上,进一步提升和优化 Azure Cosmos DB 帐户的性能。
注释
CPU 使用率高可能导致延迟增加和请求超时异常。
元数据操作
请勿在热路径中或进行项操作之前通过调用 Create...IfNotExistsAsync 和/或 Read...Async 来验证数据库和/或集合是否存在。 只有在应用程序启动并且预计将删除它们时才需要进行验证(否则不需要)。 这些元数据操作将产生额外的没有 SLA 的端到端延迟,且它们各自的限制并不像数据操作那样具有可扩展性。
日志记录和跟踪
某些环境已启用 .NET DefaultTraceListener。 DefaultTraceListener 在生产环境中造成性能问题,导致高 CPU 和 I/O 瓶颈。 检查并确保已对应用程序禁用 DefaultTraceListener,方法是将其从生产环境中的 TraceListeners 删除。
最新 SDK 版本(大于 2.16.2)在检测到它时自动将其删除,使用旧版本,可以通过以下方式将其删除:
if (!Debugger.IsAttached)
{
Type defaultTrace = Type.GetType("Microsoft.Azure.Documents.DefaultTrace,Microsoft.Azure.DocumentDB.Core");
TraceSource traceSource = (TraceSource)defaultTrace.GetProperty("TraceSource").GetValue(null);
traceSource.Listeners.Remove("Default");
// Add your own trace listeners
}
网络
连接策略:使用直接连接模式
.NET V2 SDK 默认连接模式为网关。 使用DocumentClient参数在构造ConnectionPolicy实例的过程中配置连接模式。 如果使用直接模式,则还需要通过参数Protocol设置ConnectionPolicy。 若要详细了解不同的连接性选项,请参阅连接性模式一文。
Uri serviceEndpoint = new Uri("https://contoso.documents.azure.cn");
string authKey = "your authKey from the Azure portal";
DocumentClient client = new DocumentClient(serviceEndpoint, authKey,
new ConnectionPolicy
{
ConnectionMode = ConnectionMode.Direct, // ConnectionMode.Gateway is the default
ConnectionProtocol = Protocol.Tcp
});
临时端口耗尽
如果实例上的连接量较高或端口使用率较高,请先确认客户端实例是否为单一实例。 换句话说,客户端实例在应用程序生存期内应是唯一的。
在 TCP 协议上运行时,客户端使用生存期较长的连接(而不是 HTTPS 协议)优化延迟,该协议在 2 分钟处于非活动状态后终止连接。
在访问稀疏的情况下,如果您发现连接数量较网关模式下的连接计数更高,则可以:
将 ConnectionPolicy.PortReuseMode 属性配置为
PrivatePortPool(适用于框架版本>= 4.6.1 和 .NET Core 版本 >= 2.0):此属性允许 SDK 使用一小部分临时端口池,以支持不同的 Azure Cosmos DB 目标终结点。配置 ConnectionPolicy.IdleConnectionTimeout 属性必须大于或等于 10 分钟。 建议的值介于 20 分钟到 24 小时之间。
调用 OpenAsync 以避免第一个请求的启动延迟
默认情况下,第一个请求的延迟较高,因为它需要提取地址路由表。 使用 SDK V2 时,在初始化期间调用 OpenAsync() 一次,以避免在第一个请求上出现此启动延迟。 调用如下所示: await client.OpenAsync();
注释
OpenAsync 将生成用于获取帐户中所有容器的地址路由表的请求。 对于具有许多容器但应用程序访问其中一部分容器的帐户, OpenAsync 将生成不必要的流量量,这将使初始化速度变慢。 因此,在这种情况下,使用 OpenAsync 可能不起作用,因为它会降低应用程序启动速度。
为性能,将客户端并置在同一Azure区域中
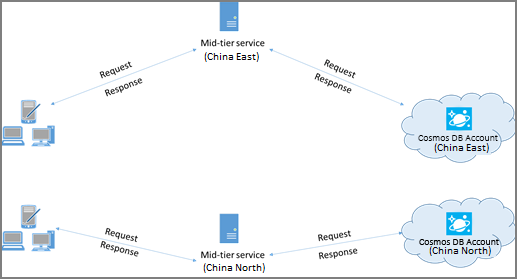
如果可能,请将调用 Azure Cosmos DB 的任何应用程序置于与 Azure Cosmos DB 数据库相同的区域中。 下面是一个近似比较:对同一区域内 Azure Cosmos DB 的调用完成时间为 1 毫秒到 2 毫秒,但中国东部和北部区域之间的延迟超过几十毫秒。 此延迟可能因请求到请求而异,具体取决于请求从客户端传递到Azure数据中心边界时所采用的路由。 通过确保调用应用程序与预配的 Azure Cosmos DB 终结点位于同一Azure区域中,可以获得最低的延迟。 有关可用区域的列表,请参阅 Azure 区域。
由于对 Azure Cosmos DB 的调用是通过网络进行的,因此可能需要改变请求的并行度,以便客户端应用程序在请求之间等待的时间最短。 例如,如果使用 .NET Task 并行库,请创建数百个任务以从或写入 Azure Cosmos DB。
启用加速网络
为了减少延迟和 CPU 抖动,我们建议在客户端virtual machines上启用加速网络。 请参阅 创建具有加速网络的 Windows 虚拟机 ,或 创建具有加速网络的 Linux 虚拟机。
SDK 用法
安装最新的 SDK
Azure Cosmos DB SDK 不断改进,以提供最佳性能。 请参阅 Azure Cosmos DB SDK 页来确定最新的 SDK 并查看改进。
在应用程序的生命周期内使用单例 Azure Cosmos DB 客户端
每个 DocumentClient 实例都是线程安全的,在直接模式下运行时,执行高效的连接管理和地址缓存。 若要实现高效的连接管理和更好的 SDK 客户端性能,我们建议在应用程序的生存期内为每个 AppDomain 实例使用一个实例。
避免阻塞调用
Azure Cosmos DB SDK 应设计为同时处理许多请求。 异步 API 允许较小线程池处理数千个并发请求,无需等待阻塞调用。 线程可以处理另一个请求,而不是等待长时间运行的同步任务完成。
使用 Azure Cosmos DB SDK 的应用中的常见性能问题是阻止可能异步的调用。 许多同步阻塞调用都会导致线程池饥饿和响应时间降低。
禁止行为:
- 通过调用 Task.Wait 或 Task.Result 阻止异步执行。
- 使用 Task.Run 使同步 API 异步。
- 获取常见代码路径中的锁。 Azure Cosmos DB .NET SDK 在构建为并行运行代码时性能最高。
- 调用 Task.Run 并立即等待它完成。 ASP.NET Core已在正常的线程池线程上运行应用代码,因此调用 Task.Run 只会产生额外的不必要的线程池计划。 即使计划代码会阻止线程,Task.Run 也不会阻止该线程。
- 使用 ToList()
DocumentClient.CreateDocumentQuery(...)使用阻塞调用来同步清空查询。 使用 AsDocumentQuery()异步清空查询。
建议做法:
异步调用 Azure Cosmos DB .NET API。
为了获益于 async/await 模式,整个调用堆栈都是异步的。
探查器(如 PerfView)可用于查找经常添加到 Thread Pool 的线程。
Microsoft-Windows-DotNETRuntime/ThreadPoolWorkerThread/Start 事件表示有线程被添加到线程池。
使用网关模式时,增加每个主机的 System.Net MaxConnections
使用网关模式时,Azure Cosmos DB 请求是通过 HTTPS/REST 发出的。 它们受每个主机名或 IP 地址的默认连接限制。 可能需要将 MaxConnections 设置为更高的值(100 到 1,000),以便客户端库可以使用多个同时连接来Azure Cosmos DB。 在 .NET SDK 1.8.0 及更高版本中,ServicePointManager.DefaultConnectionLimit的默认值为 50。 若要更改值,可以将 Documents.Client.ConnectionPolicy.MaxConnectionLimit 设置为更高的值。
在 RetryAfter 间隔处实现回退
在性能测试期间,应增加负载,直到少量的请求被限制。 如果请求受到限制,客户端应用程序应在服务器指定的重试间隔内降低请求频率并进行退避。 尊重退避策略可确保在重试之间花费最少的等待时间。
这些 SDK 中包括重试策略支持:
- 适用于 SQL 的 .NET SDK 版本 1.8.0 及更高版本 和 Java SDK
- 适用于 SQL 的Node.js SDK 和适用于 SQL 的 Python SDK 的版本 1.9.0 及更高版本
- .NET Core SDK 的所有支持版本
有关详细信息,请参阅 RetryAfter。
在 .NET SDK 版本 1.19 及更高版本中,有一种用于记录其他诊断信息和排查延迟问题的机制,如以下示例所示。 可以为读取延迟较高的请求记录诊断字符串。 捕获的诊断字符串将帮助你了解收到给定请求的 429 错误次数。
ResourceResponse<Document> readDocument = await this.readClient.ReadDocumentAsync(oldDocuments[i].SelfLink);
readDocument.RequestDiagnosticsString
缓存文档 URI 以降低读取延迟
尽可能缓存文档 URI,以获得最佳读取性能。 创建资源时,需要定义逻辑来缓存资源 ID。 基于资源 ID 的查找比基于名称的查找更快,因此缓存这些值可以提高性能。
增加线程/任务数目
请参阅本文网络部分中 的“增加线程/任务数 ”。
查询操作
有关查询操作,请参阅查询的性能提示。
索引编制策略
从索引中排除未使用的路径以加快写入速度
Azure Cosmos DB 索引策略还允许你通过使用索引路径(IndexingPolicy.IncludedPaths 和 IndexingPolicy.ExcludedPaths)指定要包含在索引中或从索引中排除的文档路径。 索引路径可提高写入性能,并降低在查询模式已知的场景中的索引存储。 这是因为,索引成本与已编制索引的唯一路径数目直接相关。 例如,此代码演示如何使用“*”通配符从索引中排除文档(子树)的整个部分:
var collection = new DocumentCollection { Id = "excludedPathCollection" };
collection.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
collection.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/nonIndexedContent/*");
collection = await client.CreateDocumentCollectionAsync(UriFactory.CreateDatabaseUri("db"), collection);
有关详细信息,请参阅 Azure Cosmos DB 索引策略。
吞吐量
度量和优化较低的请求单位/秒使用情况
Azure Cosmos DB 提供了一组丰富的数据库操作。 这些操作包括使用用户定义函数(UDF)、存储过程和触发器的关系查询和分层查询,所有操作都在数据库集合中的文档上运行。 与每个操作相关的成本因完成操作所需的 CPU、I/O 和内存而异。 可以将请求单位(RU)视为执行各种数据库作和服务应用程序请求所需的资源的单个度量值,而不是考虑和管理硬件资源。
吞吐量的预配取决于为每个容器设置的请求单位数。 请求单位消耗计算为每秒速率。 超出其容器预配的请求单位速率的应用程序受到限制,直到速率低于容器的预配级别。 如果应用程序需要更高的吞吐量级别,可以通过预配其他请求单位来提高吞吐量。
查询的复杂性会影响执行操作时消耗的请求单位数。 谓词数、谓词的性质、UDF 的数量和源数据集的大小都会影响查询作的成本。
为了测量任何操作(创建、更新或删除)的开销,请检查 x-ms-request-charge 标头(或 .NET SDK 中 RequestCharge 属性和等效的 ResourceResponse\<T> 或 FeedResponse\<T>)以计算这些操作消耗的请求单位数。
// Measure the performance (Request Units) of writes
ResourceResponse<Document> response = await client.CreateDocumentAsync(collectionSelfLink, myDocument);
Console.WriteLine("Insert of document consumed {0} request units", response.RequestCharge);
// Measure the performance (Request Units) of queries
IDocumentQuery<dynamic> queryable = client.CreateDocumentQuery(collectionSelfLink, queryString).AsDocumentQuery();
while (queryable.HasMoreResults)
{
FeedResponse<dynamic> queryResponse = await queryable.ExecuteNextAsync<dynamic>();
Console.WriteLine("Query batch consumed {0} request units", queryResponse.RequestCharge);
}
此标头中返回的请求费用是预配吞吐量的一小部分(即 2,000 RU/秒)。 例如,如果上述查询返回 1,000 个 1-KB 的文档,则操作成本是 1,000。 因此,在一秒钟内,服务器只遵循两个此类请求,然后再对以后的请求进行速率限制。 有关详细信息,请参阅 Request Units 和 Request Unit calculator。
处理速率限制/请求速率太大
客户端尝试超过为帐户保留的吞吐量时,服务器的性能不会降低,并且不会使用超过保留级别的吞吐量容量。 服务器会先发制人地使用 RequestRateTooLarge(HTTP 状态代码 429)结束请求。 它将返回 x-ms-retry-after-ms 标头,该标头指示用户在再次尝试请求之前必须等待的时间量(以毫秒为单位)。
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK 全部都会隐式捕获此响应,并遵循服务器指定的 retry-after 标头,并重试请求。 除非多个客户端同时访问帐户,否则下次重试就会成功。
如果有多个客户端累积运行一致高于请求速率,则客户端当前在内部设置为 9 的默认重试计数可能不足以满足要求。 在这种情况下,客户端会向应用程序引发状态代码为 429 的 DocumentClientException。
可以通过在 RetryOptions 实例上设置 ConnectionPolicy 来更改默认重试计数。 默认情况下,如果请求继续运行高于请求速率,则状态代码为 429 的 DocumentClientException 在累积等待时间 30 秒后返回。 即使当前重试计数小于最大重试计数,当前值是默认值为 9 还是用户定义的值,也会返回此错误。
自动重试行为有助于改善大多数应用程序的复原能力和可用性。 但是,在进行性能基准测试时(尤其是在测量延迟时),这可能不是最佳行为。 如果实验触发服务器节流并导致客户端 SDK 自动重试,则客户端观测到的延迟会剧增。 为了避免性能实验期间出现延迟高峰,应评估每个操作返回的费用,并确保请求在低于预定请求速率的水平下运行。 有关详细信息,请参阅请求单位。
针对较小文档进行设计以提高吞吐量
给定作的请求费用(即请求处理成本)直接关联到文档的大小。 大型文档的操作成本高于小型文档的操作成本。
后续步骤
若要详细了解如何设计应用程序以进行缩放和达到高性能,请参阅 Azure Cosmos DB 中的分区和缩放。