适用范围:![]() NoSQL
NoSQL
- Java SDK v4
- 异步 Java SDK v2
- 同步 Java SDK v2
- .NET SDK v3
- .NET SDK v2
- Python SDK
重要
本文中的性能提示仅适用于 Azure Cosmos DB Java SDK v4。 有关详细信息,请查看 Azure Cosmos DB Java SDK v4 发行说明、 Maven 存储库和 Azure Cosmos DB Java SDK v4 故障排除指南 。 如果当前使用的是低于 v4 的版本,请参阅 迁移到 Azure Cosmos DB Java SDK v4 指南,获取升级到 v4 的帮助。
Azure Cosmos DB 是一个快速、弹性的分布式数据库,可以在提供延迟与吞吐量保证的情况下无缝缩放。 凭借 Azure Cosmos DB,无需对体系结构进行重大更改或编写复杂的代码即可缩放数据库。 扩展和缩减操作就像执行单个 API 调用或 SDK 方法调用一样简单。 但是,由于 Azure Cosmos DB 是通过网络调用访问的,因此,使用 Azure Cosmos DB Java SDK v4 时,可以通过客户端优化获得最高性能。
因此,如果询问“如何提高数据库性能?”,请考虑以下选项:
网络
如果可能,请将任何调用 Azure Cosmos DB 的应用程序放在与 Azure Cosmos DB 数据库所在的相同区域中。 根据请求采用的路由,各项请求从客户端传递到 Azure 数据中心边界时的此类延迟可能有所不同。 通过确保在与预配 Azure Cosmos DB 终结点所在的同一 Azure 区域中调用应用程序,可能会实现最低的延迟。 有关可用区域的列表,请参阅 Azure Regions(Azure 区域)。
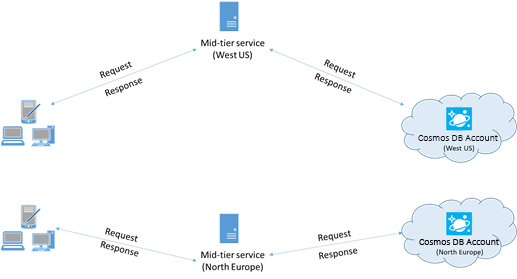
与多区域 Azure Cosmos DB 帐户交互的应用需要配置首选位置,以确保请求进入并置区域。
启用加速网络以减少延迟和 CPU 抖动
强烈建议按照说明在 Windows(选中以获取说明)或 Linux(选中以获取说明)Azure VM 中启用加速网络,以最大程度提高性能(减少延迟和 CPU 抖动)。
如果不使用加速网络,则在 Azure VM 与其他 Azure 资源之间传输的 IO 可能会通过位于 VM 与其网卡之间的主机和虚拟交换机进行路由。 在数据路径中以内联方式放置主机和虚拟交换机不仅会增加信道中的延迟和抖动,还会占用 VM 的 CPU 周期。 通过加速网络,VM 可以直接与 NIC 连接,而无需中介。 所有网络策略详细信息均在 NIC 的硬件中处理,会绕过主机和虚拟交换机。 通常情况下,当启用加速网络后,应会降低延迟并提高吞吐量,同时会提高延迟一致性并降低 CPU 利用率。
限制:加速网络必须受 VM OS 支持,并且只能在已停止并解除分配 VM 的情况下启用。 不能通过 Azure 资源管理器部署此 VM。 应用服务未启用加速网络。
有关详细信息,请参阅 Windows 和 Linux 说明。
高可用性
有关在 Azure Cosmos DB 中配置高可用性的一般指南,请参阅 Azure Cosmos DB 中的高可用性。
除了在数据库平台中进行良好的基础设置外,还可以在 Java SDK 中实现特定的技术,这有助于在中断情况下提供帮助。 两个值得注意的策略是基于阈值的可用性策略和分区级断路器。
这些技术提供高级机制来应对特定的延迟和可用性挑战,超越了默认情况下内置于 SDK 中的跨区域重试功能。 通过主动管理请求和分区级别的潜在问题,这些策略可以显著提高应用程序的复原能力和性能,尤其是在高负载或性能下降的情况下。
基于阈值的可用性策略
基于阈值的可用性策略可以通过向次要区域(如定义) preferredRegions发送并行读取请求并接受最快的响应来提高尾部延迟和可用性。 此方法可以大幅降低区域性中断或高延迟条件对应用程序性能的影响。 此外,可以采用主动连接管理,在当前读取区域和首选远程区域中预热连接和缓存,从而进一步提升性能。
示例配置:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
工作原理:
初始请求: 在 T1 时,向主要区域(例如中国北部 3)发出读取请求。 SDK 等待响应的时间最多为 500 毫秒(
threshold值)。第二个请求: 如果在 500 毫秒内没有主要区域的响应,则会将并行请求发送到下一个首选区域(例如中国北部 2)。
第三个请求: 如果主要区域和次要区域均未在 600 毫秒(500 毫秒 + 100 毫秒)内响应,
thresholdStep则 SDK 会将另一个并行请求发送到第三个首选区域(例如中国东部 2)。最快响应获胜:哪个区域最先响应,就接受哪个区域的响应,并忽略其他并行请求。
主动连接管理可以跨首选区域的容器预热连接和缓存,减少故障转移时或在多区域设置中写入时的冷启动延迟。
在特定区域速度缓慢或暂时不可用的情况下,此策略可以显著改善延迟,但在需要并行跨区域请求时,可能会产生更多的请求单位成本。
注意
如果第一个首选区域返回非暂时性错误状态代码(例如找不到文档、授权错误、冲突等),则作本身将快速失败,因为可用性策略在此方案中没有任何好处。
分区级断路器
分区级断路器可以跟踪和短路发送到运行不正常的物理分区的请求,从而改善尾部延迟和写入可用性。 它通过避开已知有问题的分区并将请求重定向到运行更正常的区域来提高性能。
示例配置:
启用分区级断路器:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
设置用于检查不可用区域的后台进程频率:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
设置分区不可用的持续时间:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
工作原理:
跟踪失败: SDK 跟踪特定区域中各个分区的终端故障(例如 503s、500s、timeouts)。
标记为不可用: 如果区域中的分区超出配置的故障阈值,则标记为“不可用”。对此分区的后续请求会短路,并重定向到其他更健康的区域。
自动恢复:后台线程会定期检查不可用分区。 经过一定时间后,这些分区会被暂时标记为“HealthyTentative”,并接受测试请求以验证恢复情况。
健康状况提升/降级:根据这些测试请求的成功或失败,分区的状态将提升回“正常”或再次降级为“不可用”。
此机制有助于持续监视分区的健康状况,确保请求以最小的延迟和最大可用性得到处理,不会因有问题的分区而受到阻碍。
注意
断路器仅适用于多区域写入帐户,因为当分区被标记为 Unavailable 时,读取和写入都将移动到下一个首选区域。 这是为了防止来自不同区域的读取和写入由同一客户端实例处理,因为这将是一种反模式。
重要
必须使用 Java SDK 版本 4.63.0 或更高版本才能激活分区级断路器。
比较可用性优化
基于阈值的可用性策略:
- 优点:通过将并行读取请求发送到次要区域来减少尾部延迟,并通过抢占将导致网络超时的请求来提高可用性。
- 权衡:与断路器相比,会产生额外的 RU(请求单位)成本,因为其他并行跨区域请求(尽管仅在违反阈值的时间段内)。
- 用例:最适合读取密集型的工作负载,在这种工作负载中,减少延迟至关重要,而一些额外成本(在 RU 费用和客户端 CPU 压力方面)是可以接受的。 如果选择使用非幂等写入重试策略,并且帐户具有多区域写入,则写入操作也会受益。
分区级断路器:
- 优点:通过避开运行不正常的分区,确保将请求路由到运行更正常的区域,从而提高可用性并降低延迟。
- 权衡:不会产生更多的 RU 成本,但仍可能导致导致网络超时的请求出现一些初始可用性损失。
- 用例:非常适合写入密集型或混合工作负载,在这些工作负载中,一致的性能至关重要,尤其是在处理可能间歇性变得不正常的分区时。
这两种策略都可用于提高读取和写入可用性,并减少尾部延迟。 分区级断路器可以处理各种短暂故障场景,包括可能导致副本性能下降的故障,而无需发出并行请求。 此外,如果可接受额外 RU 成本,添加基于阈值的可用性策略将进一步最大程度地减少尾部延迟并消除可用性损失。
通过实施这些策略,开发人员可以确保其应用程序保持复原能力、维持高性能,并在区域性中断或高延迟条件下提供更好的用户体验。
区域范围内的会话一致性
概述
有关一般一致性设置的详细信息,请参阅 Azure Cosmos DB 中的一致性级别。 Java SDK 将会话一致性限制在特定区域内,从而优化了多区域写入帐户的会话一致性。 这样可以通过最大程度地减少客户端重试来缓解跨区域复制延迟,从而提高了性能。 这是通过在区域级别而不是全局级别管理会话令牌来实现的。 如果应用程序只需要在几个区域中保持一致性,则使用区域范围的会话一致性可以通过减少跨区域复制延迟和重试来提高多写入帐户中读取和写入的性能和可靠性。
好处
- 降低延迟:通过将会话令牌验证本地化为区域级别,可以减少成本高昂的跨区域重试的可能性。
- 增强性能:最大程度地减少区域性故障转移和复制延迟的影响,从而提高了读/写一致性,降低了 CPU 利用率。
- 优化资源利用率:通过限制重试和跨区域调用的需求来减少客户端应用程序的 CPU 和网络开销,从而优化资源使用率。
- 高可用性:通过维护区域范围内的会话令牌,即使某些区域出现较高的延迟或临时故障,应用程序也能继续顺利运行。
- 一致性保证:确保能够更可靠地实现会话一致性(读取写入、单调读取)保证,无需不必要的重试。
- 成本效益:减少跨区域调用的次数,从而可能降低区域之间数据传输的相关成本。
- 可伸缩性:通过减少与维护全局会话令牌相关的争用和开销,尤其是在多区域设置中,让应用程序能够更有效地缩放。
权衡
- 增加内存使用量:布隆筛选器和特定于区域的会话令牌存储需要更多的内存,对于资源有限的应用程序,这可能是一个需要考虑的问题。
- 配置复杂性:微调布隆筛选器的预期插入次数和误报率会增加配置过程的复杂性。
- 误报的可能性: 虽然 Bloom 过滤器将跨区域重试降到最低,但误报仍然有可能影响会话令牌验证,尽管误报率是可以控制的。 误报表示全局会话令牌已解析,因此,如果本地区域还未同步到此全局会话,则会增加跨区域重试的可能性。 即使存在误报,会话保证也会得到满足。
- 适用性:此功能最适用于逻辑分区基数较高和经常重启的应用程序。 逻辑分区较少或重启不频繁的应用程序可能不会明显受益。
工作原理
设置会话令牌
- 请求完成:请求完成后,SDK 会捕获会话令牌,并将其与区域和分区键相关联。
-
区域级存储:会话令牌存储在嵌套的
ConcurrentHashMap中,它可维护分区键范围与区域级进度之间的映射。 - 布隆筛选器:布隆筛选器会跟踪每个逻辑分区访问的区域,帮助本地化会话令牌验证。
解析会话令牌
- 请求初始化:在发送请求之前,SDK 会尝试解析相应区域的会话令牌。
- 令牌检查:根据特定于区域的数据检查令牌,确保将请求路由到最新的副本。
- 重试逻辑: 如果未在当前区域中验证会话令牌,则 SDK 会与其他区域一起重试,但考虑到本地化存储,这不太频繁。
使用 SDK
下面演示了如何使用区域范围内的会话一致性初始化 CosmosClient:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
启用区域范围内的会话一致性
若要在应用程序中启用区域范围内的会话捕获,请设置以下系统属性:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
配置布隆筛选器
通过配置布隆筛选器的预期插入和误报率,对性能进行微调:
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
内存影响
下面是内部会话容器(由 SDK 管理)的保留大小(对象大小及其依赖项的大小),其中在布隆筛选器中的预期插入量有所不同。
| 预期插入量 | 误报率 | 保留的大小 |
|---|---|---|
| 10, 000 | 0.001 | 21 KB |
| 100, 000 | 0.001 | 183 KB |
| 1 百万 | 0.001 | 1.8 MB |
| 1 千万 | 0.001 | 17.9 MB |
| 1 亿 | 0.001 | 179 MB |
| 10 亿 | 0.001 | 1.8 GB |
重要
必须使用 Java SDK 版本 4.60.0 或更高版本才能激活区域范围内的会话一致性。
排除区域
排除的区域功能允许根据每个请求从首选位置中排除特定区域,从而对请求路由进行精细控制。 此功能在 Azure Cosmos DB Java SDK 4.47.0 及更高版本中提供。
主要优势:
- 处理速率限制:遇到 429 个(请求过多)响应时,会自动将请求路由到具有可用吞吐量的备用区域
- 定向路由:通过排除所有其他路由,确保从特定区域提供请求
- 绕过首选顺序:覆盖单个请求的默认首选区域列表,而无需创建单独的客户端
配置:
可以在客户端级别和请求级别配置排除的区域:
CosmosExcludedRegions excludedRegions = new CosmosExcludedRegions(Set.of("China North 3"));
// Using AtomicReference to simulate dynamic changes to excluded regions. Excluded regions can be set at the
// client level
AtomicReference<CosmosExcludedRegions> excludedRegionsAtomicReference = new AtomicReference<>(excludedRegions);
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint("")
.key("")
.preferredRegions(List.of(new String[]{"China North 3", "China North 2"}))
.excludedRegionsSupplier(excludedRegionsAtomicReference::get)
.buildAsyncClient();
CosmosAsyncDatabase cosmosAsyncDatabase = client.getDatabase("Test");
CosmosAsyncContainer cosmosAsyncContainer = cosmosAsyncDatabase.getContainer("TestItems");
// Excluded regions can also be set at the request level
CosmosItemRequestOptions cosmosItemRequestOptions = new CosmosItemRequestOptions().setExcludedRegions(List.of("China North 2"));
TestObject testItem = TestObject.create("mypkValue");
cosmosAsyncContainer.createItem(testItem, cosmosItemRequestOptions).block();
调整一致性与可用性的平衡
排除的区域功能提供了一种额外的机制,用于平衡应用程序中的一致性和可用性权衡。 此功能在动态方案中非常有用,在这些方案中,要求可能会根据作条件变化:
动态中断处理:当主要区域遇到中断和分区级断路器阈值证明不足时,排除的区域可以立即进行故障转移,而无需更改代码或应用程序重启。 与等待自动断路器激活相比,这可以更快地响应区域问题。
条件一致性首选项:应用程序可以根据作状态实现不同的一致性策略:
- 稳定状态:通过排除除主要区域以外的所有区域来确定一致性读取的优先级,确保数据一致性,并可能带来可用性成本
- 中断场景:通过允许跨区域路由,接受潜在的数据延迟,以换取持续的服务可用性,更加注重可用性而非严格一致性。
此方法允许外部机制(例如流量管理器或负载均衡器)协调故障转移决策,而应用程序通过区域排除模式保持对一致性要求的控制。
排除所有区域后,请求将路由到主要/中心区域。 此功能适用于所有请求类型,包括查询,并且有助于维护单一实例客户端实例,同时实现灵活的路由行为。
优化直接连接和网关连接配置
若要优化直接连接和网关模式连接配置,请参阅如何优化 Java SDK v4 的连接配置。
SDK 用法
- 安装最新的 SDK
Azure Cosmos DB SDK 正在不断改进以提供最佳性能。 若要确定最近的 SDK 改进,请访问 Azure Cosmos DB SDK。
每个 Azure Cosmos DB 客户端实例都是线程安全的,可执行高效的连接管理和地址缓存。 要通过 Azure Cosmos DB 客户端获得高效的连接管理和更好的性能,我们强烈建议在应用程序生存期内使用单个 Azure Cosmos DB 客户端实例。
创建 CosmosClient 时,在未显式设置的情况下,所使用的默认一致性是“会话”。 如果应用程序逻辑不要求“会话”一致性,请将“一致性”设置为“最终”。 注意:建议在采用 Azure Cosmos DB 更改源处理器的应用程序中至少使用“会话”一致性。
- 使用异步 API 最大化预配的吞吐量
Azure Cosmos DB Java SDK v4 捆绑了两个 API:同步 API 和异步 API。 大致说来,异步 API 用于实现 SDK 功能,而同步 API 则是一种精简的包装器,用于向异步 API 发出阻止调用。 这与较旧的 Azure Cosmos DB Async Java SDK v2 和 Azure Cosmos DB Sync Java SDK v2 都不同,前者只支持异步,后者只支持同步并且具有不同的实现。
API 的选择在客户端初始化期间确定;CosmosAsyncClient 支持异步 API,而 CosmosClient 支持同步 API。
异步 API 可实现非阻止 IO,如果你的目标是在向 Azure Cosmos DB 发出请求时最大化吞吐量,则它是最佳选择。
如果希望或需要在对每个请求的响应中阻止某个 API,或者如果同步操作是应用程序中的主导模式,则使用同步 API 可能是正确的选择。 例如,在吞吐量并不重要的情况下,若要在微服务应用程序中将数据持久保存到 Azure Cosmos DB,则可以使用同步 API。
请注意,同步 API 吞吐量会随请求响应时间的增加而降低,而异步 API 可能会使硬件的全部带宽功能饱和。
使用同步 API 时,进行地理并置可以获得更高且更一致的吞吐量(请参阅将客户端并置在同一 Azure 区域内以提高性能),但应不会超过异步 API 可获得的吞吐量。
某些用户可能还不熟悉 Project Reactor,这是用于实现 Azure Cosmos DB Java SDK v4 异步 API 的响应式流框架。 如果存在此问题,建议你阅读我们的简介性文章:Reactor Pattern Guide(Reactor 模式指南),然后查看此响应式编程简介,自行熟悉相关内容。 如果你已将 Azure Cosmos DB 与异步接口一起使用,并且所使用的 SDK 是 Azure Cosmos DB Async Java SDK v2,则可能已熟悉 ReactiveX/RxJava,但不确定 Project Reactor 中的更改。 在这种情况下,请查看我们的 Reactor 与RxJava 指南 以熟悉相关内容。
以下代码片段演示了如何分别针对异步 API 或同步 API 操作初始化 Azure Cosmos DB 客户端:
Java SDK V4 (Maven com.azure::azure-cosmos) 异步 API
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- 增大客户端工作负荷
如果以高吞吐量级别进行测试,客户端应用程序可能成为瓶颈,因为计算机的 CPU 或网络利用率将达到上限。 如果达到此上限,可以跨多个服务器横向扩展客户端应用程序以继续进一步推送 Azure Cosmos DB 帐户。
一个好的经验法则是,在任何给定的服务器上,CPU 利用率都不超过 >50%,以保持较低的延迟。
- 使用相应的计划程序(避免窃取事件循环 IO Netty 线程)
Azure Cosmos DB Java SDK 的异步功能基于 netty 非阻止 IO。 SDK 使用固定数量的 IO netty 事件循环线程(数量与计算机提供的 CPU 核心数相同)来执行 IO 操作。 API 返回的 Flux 会将结果发送到某个共享 IO 事件循环 netty 线程上。 因此,切勿阻塞共享的 IO 事件循环 netty 线程。 针对 IO 事件循环 netty 线程执行 CPU 密集型工作或者阻塞操作可能导致死锁,或大大减少 SDK 吞吐量。
例如,以下代码针对事件循环 IO netty 线程执行 CPU 密集型工作:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
收到结果后,应避免在事件循环 IO netty 线程上对结果执行任何 CPU 密集型操作。 你可以改为提供自己的计划程序,以便提供自己的线程来运行工作,如下所示(需要 import reactor.core.scheduler.Schedulers)。
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.subscribeOn(Schedulers.elastic())
.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
根据工作的类型,应该使用相应的现有 Reactor 计划程序来执行工作。 请阅读 Schedulers。
要进一步了解项目 Reactor 的线程和计划模型,请参阅 Project Reactor 的博客文章。
有关 Azure Cosmos DB Java SDK v4 的详细信息,请参阅 GitHub 上 Azure SDK for Java 单存储库的 Azure Cosmos DB 目录。
- 优化应用程序中的日志记录设置
出于各种原因,应在生成高请求吞吐量的线程中添加日志记录。 如果你的目标是使用此线程生成的请求使容器的预配吞吐量完全饱和,则日志记录优化可以极大地提升性能。
- 配置异步记录器
生成请求的线程的总体延迟计算必然会考虑到同步记录器延迟的因素。 建议使用异步记录器(例如 log4j2),以便将日志记录开销与高性能应用程序线程分开。
- 禁用 netty 的日志记录
Netty 库日志记录非常琐碎,因此需要将其关闭(在配置中禁止登录可能并不足够),以避免产生额外的 CPU 开销。 如果不处于调试模式,请一起禁用 netty 日志记录。 因此,如果要使用 Log4j 来消除 netty 中 org.apache.log4j.Category.callAppenders() 产生的额外 CPU 开销,请将以下行添加到基代码:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- OS 打开文件资源限制
某些 Linux 系统(例如 CentOS)对打开的文件数和连接总数施加了上限。 运行以下命令以查看当前限制:
ulimit -a
打开的文件数 (nofile) 需要足够大,以便为配置的连接池大小和 OS 打开的其他文件留出足够的空间。 可以修改此参数,以增大连接池大小。
打开 limits.conf 文件:
vim /etc/security/limits.conf
添加/修改以下行:
* - nofile 100000
- 在点写入中指定分区键
若要提高点写入的性能,请在点写入 API 调用中指定项分区键,如下所示:
Java SDK V4 (Maven com.azure::azure-cosmos) 异步 API
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
而不是仅提供项实例,如下所示:
后者是受支持的,但会增加应用程序的延迟;SDK 必须分析项并提取分区键。
查询操作
有关查询操作,请参阅查询的性能提示。
索引策略
- 从索引中排除未使用的路径以加快写入速度
借助 Azure Cosmos DB 的索引策略,可以通过使用索引路径(setIncludedPaths 和 setExcludedPaths)来指定要在索引中包括或排除的文档路径。 在事先知道查询模式的方案中,使用索引路径可改善写入性能并降低索引存储空间,因为索引成本与索引的唯一路径数目直接相关。 例如,以下代码演示如何使用“*”通配符从索引编制中纳入和排除文档的整个部分(也称为子树)。
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
有关索引的详细信息,请参阅 Azure Cosmos DB 索引策略。
吞吐量
- 测量和优化较低的每秒请求单位使用量
Azure Cosmos DB 提供一组丰富的数据库操作,包括 UDF 的关系和层次查询、存储过程和触发 – 所有都在数据库集合的文档上操作。 与这些操作关联的成本取决于完成操作所需的 CPU、IO 和内存。 与考虑和管理硬件资源不同的是,可以考虑将请求单位 (RU) 作为所需资源的单个措施,以执行各种数据库操作和服务应用程序请求。
吞吐量是基于为每个容器设置的请求单位数量预配的。 请求单位消耗以每秒速率评估。 如果应用程序的速率超过了为其容器预配的请求单位速率,则会受到限制,直到该速率降到容器的预配级别以下。 如果应用程序需要较高级别的吞吐量,可以通过预配更多请求单位来增加吞吐量。
查询的复杂性会影响操作使用的请求单位数量。 谓词数、谓词性质、UDF 数目和源数据集的大小都会影响查询操作的成本。
若要测量任何操作(创建、更新或删除)的开销,请检查 x-ms-request-charge 标头来测量这些操作占用的请求单位数。 也可以在 ResourceResponse<T> 或 FeedResponse<T> 中找到等效的 RequestCharge 属性。
Java SDK V4 (Maven com.azure::azure-cosmos) 异步 API
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
在此标头中返回的请求费用是预配吞吐量的一小部分。 例如,如果预配了 2000 RU/s,上述查询返回 1000 个 1KB 文档,则操作成本为 1000。 因此在一秒内,服务器在对后续请求进行速率限制之前,只接受两个此类请求。 有关详细信息,请参阅请求单位和请求单位计算器。
- 处理速率限制/请求速率太大
客户端尝试超过帐户保留的吞吐量时,服务器的性能不会降低,并且不会使用超过保留级别的吞吐量容量。 服务器将抢先结束 RequestRateTooLarge(HTTP 状态代码 429)的请求并返回 x-ms-retry-after-ms 标头,该标头指示重新尝试请求前用户必须等待的时间量(以毫秒为单位)。
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK 全部都会隐式捕获此响应,并遵循服务器指定的 retry-after 标头,并重试请求。 除非多个客户端同时访问帐户,否则下次重试就会成功。
如果多个客户端一直以高于请求速率的方式累积运行,则客户端当前在内部设置为 9 的默认重试计数可能无法满足需要;在这种情况下,客户端就会向应用程序引发 CosmosClientException,其状态代码为 429。 可以通过在 setMaxRetryAttemptsOnThrottledRequests() 实例上使用 ThrottlingRetryOptions 来更改默认重试计数。 默认情况下,如果请求继续以高于请求速率的方式运行,则会在 30 秒的累积等待时间后返回 CosmosClientException 和状态代码 429。 即使当前的重试计数小于最大重试计数(默认值 9 或用户定义的值),也会发生这种情况。
尽管自动重试行为有助于改善大多数应用程序的复原能力和可用性,但是在执行性能基准测试时可能会造成冲突(尤其是在测量延迟时)。 如果实验达到服务器限制并导致客户端 SDK 静默重试,则客户端观测到的延迟会剧增。 若要避免性能实验期间出现延迟高峰,可以测量每个操作返回的费用,并确保请求以低于保留请求速率的方式运行。 有关详细信息,请参阅请求单位。
- 针对小型文档进行设计以提高吞吐量
给定操作的请求费用(请求处理成本)与文档大小直接相关。 大型文档的操作成本高于小型文档的操作成本。 理想情况下,应将应用程序和工作流的项大小设计为 1 KB 左右,或相似的等级或数量级。 对于延迟敏感的应用程序,应避免出现大项 - 几 MB 的文档会降低应用程序的速度。
后续步骤
若要深入了解如何设计应用程序以实现缩放和高性能,请参阅 Azure Cosmos DB 中的分区和缩放。
尝试为迁移到 Azure Cosmos DB 进行容量计划? 可以使用有关现有数据库群集的信息进行容量规划。
- 如果你只知道现有数据库群集中的 vCore 和服务器数量,请阅读根据 vCore 或 vCPU 数量估算请求单位数
- 若知道当前数据库工作负载的典型请求速率,请阅读使用 Azure Cosmos DB 容量计划工具估算请求单位