载入Azure 数据资源管理器时常见的情况是引入历史数据,有时称为回填。 此过程涉及将数据从现有存储系统引入到表中,该表是由区段组成的集合。
通过使用 creationTime 引入属性 引入历史数据,将盘区创建时间设置为 创建数据的时间。 通过将创建时间用作引入分区标准,数据可以按照缓存和保留策略老化,并使时间筛选器更高效。
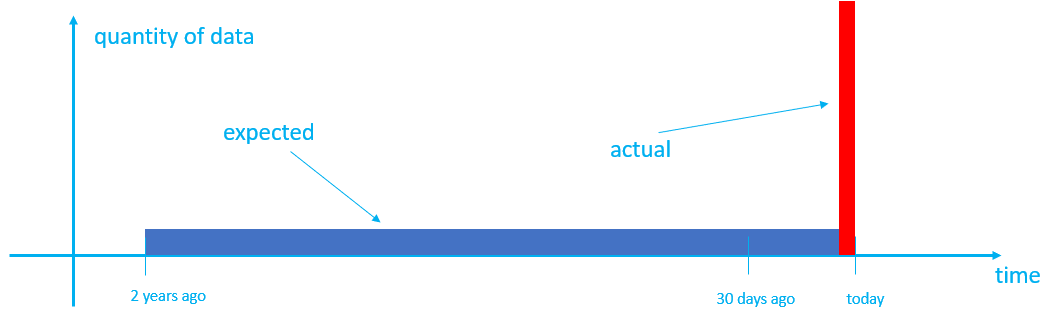
默认情况下,盘区创建时间设置为引入数据的时间,这可能不产生预期的行为。 例如,假设你有一个表,其缓存期为 30 天,保留期为 2 年。 在正常流中,生成的数据会缓存 30 天,然后移动到冷存储。 两年后,旧数据会根据其创建时间逐日删除。 但是,如果你引入两年的历史数据,默认情况下,数据会被标记为创建时间,即数据被引入的时间。 此行为可能不会产生所需的结果,因为:
- 所有数据都进入缓存并保留 30 天,使用的缓存比预期的要多。
- 较旧的数据不会一天移除一次;因此,数据在群集中保留的时间超过必要时间,并且在两年后一次性全部移除。
- 以前按源系统中的日期分组的数据现在可能在同一范围内 进行批处理 ,从而导致查询效率低下。
在本文中,你将学习如何对历史数据进行分区:
creationTime在引入期间使用引入属性(建议)如果可能,通过使用
creationTime摄取属性摄取历史数据,可以利用该属性从文件或 Blob 路径中提取信息,以设置盘区的创建时间。 如果文件夹结构不使用创建日期模式,请重构文件或 Blob 路径以反映创建时间。 使用此方法可将数据引入到具有正确创建时间的表中,并正确应用缓存和保留期。注意
默认情况下,分片按其创建(引入)时间进行分区,在大多数情况下,不需要设置数据分区策略。
在引入后使用分区策略
如果无法使用
creationTime引入属性,例如,如果使用无法控制创建时间的 Azure Cosmos DB 连接器引入数据 ,或者无法重新构造文件夹结构,则可以使用 分区策略对引入后的表进行重新分区,以实现相同的效果。 但是,此方法可能需要一些试用和错误来优化策略属性,并且效率低于使用creationTime引入属性。 仅在无法使用creationTime引入属性时才使用此方法。
先决条件
- Microsoft 帐户或 Microsoft Entra 用户标识。 不需要 Azure 订阅。
- Azure 数据资源管理器集群和数据库。 创建群集和数据库。
- 一个存储帐户。
- 如需在引入期间使用
creationTime引入属性的建议方法,请安装 LightIngest。
引入历史数据
在引入期间使用引入属性对 creationTime 历史数据进行分区。 如果无法使用该方法,可以使用分区策略在导入后重新分区表。
LightIngest 可用于将历史数据从现有存储系统加载到 Azure 数据资源管理器。 虽然可以使用 命令行参数列表生成自己的命令,但本文介绍如何通过引入向导自动生成此命令。 除了创建命令,还可以使用此过程创建新表并创建架构映射。 此工具从数据集推断架构映射。
目标
在 Azure 数据资源管理器 Web UI 中,从左侧菜单中选择Query。
右键单击要在其中引入数据的数据库,然后选择 LightIngest。
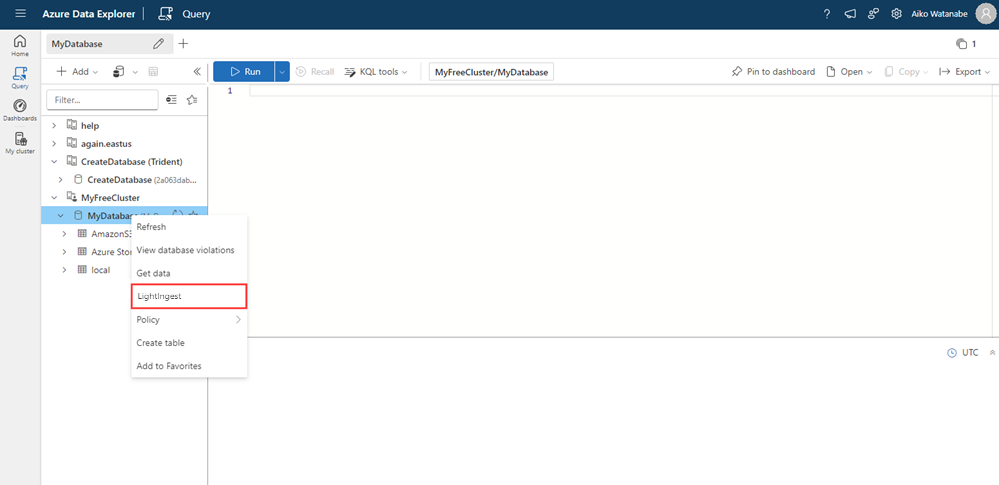
“引入数据”窗口随即打开,其中的“目标”选项卡处于选中状态。 系统会自动填充“群集”和“数据库”字段。
选择目标表。 若要将数据引入新表,请选择“ 新建表”,然后输入表名称。
注意
表名最多可包含 1,024 个字符,包括空格、字母数字字符、连字符和下划线。 不支持特殊字符。
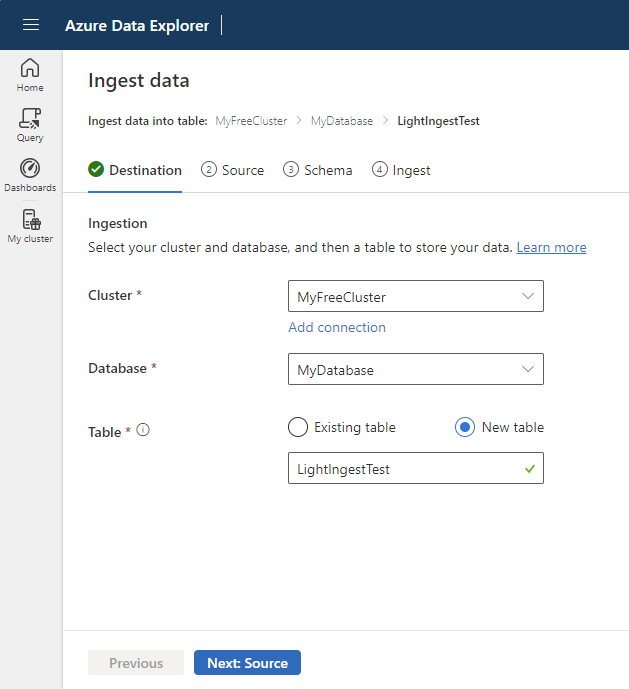
选择“下一步: 源”。

Source
在“选择源”下,选择“添加 URL”或“选择容器”。
注意
引入支持的最大文件大小为 6 GB。 建议引入 100 MB 到 1 GB 的文件。
选择 “高级设置” ,使用 LightIngest 为引入过程定义其他设置。
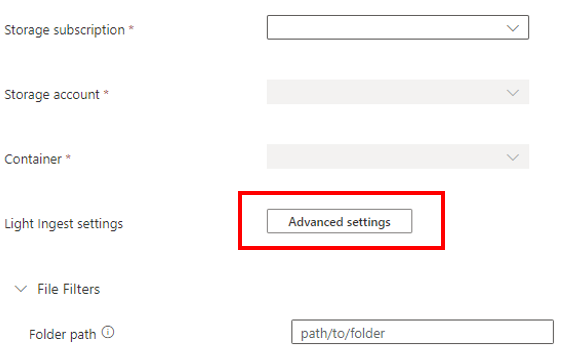
在“高级配置”面板中,根据下表定义 LightIngest 设置。
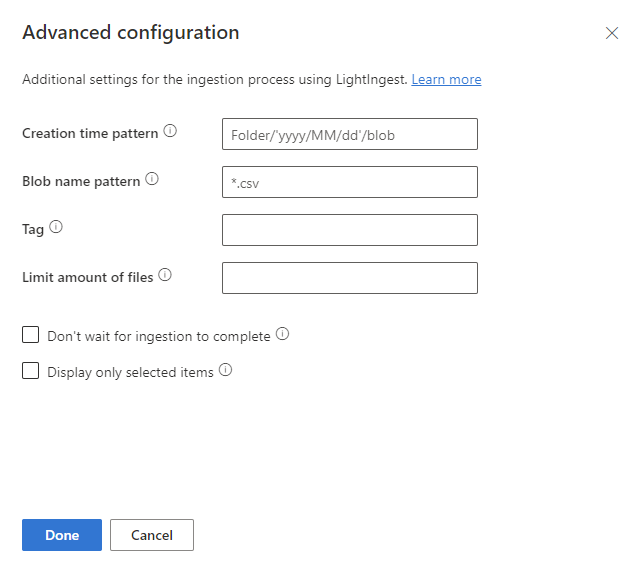
属性 说明 创建时间模式 指定要使用一种模式覆盖所创建区段的引入时间属性,例如根据容器的文件夹结构应用日期。 另请参阅创建时间模式。 Blob 名称模式 指定用于识别要引入的文件的模式。 引入与给定容器中的 blob 名称模式匹配的所有文件。 支持通配符。 将模式括在双引号中。 标记 分配给引入数据的标记。 标记可以是任意字符串。 限制文件数量 指定要引入的文件数。 导入符合 blob 名称模式的首批 n文件,最多至指定数量。不要等待摄取完成 如果设置此属性,则在不监视引入过程的情况下将 blob 排队引入。 如果未设置,LightIngest 将继续持续检查引入进度,直到引入完成。 仅显示所选项目 列出容器中的文件,但不引入这些文件。 选择“完成”,返回到“源”选项卡。
根据需要,选择“文件筛选器”筛选数据,以仅引入特定文件夹路径中的文件或带有特定文件扩展名的文件。
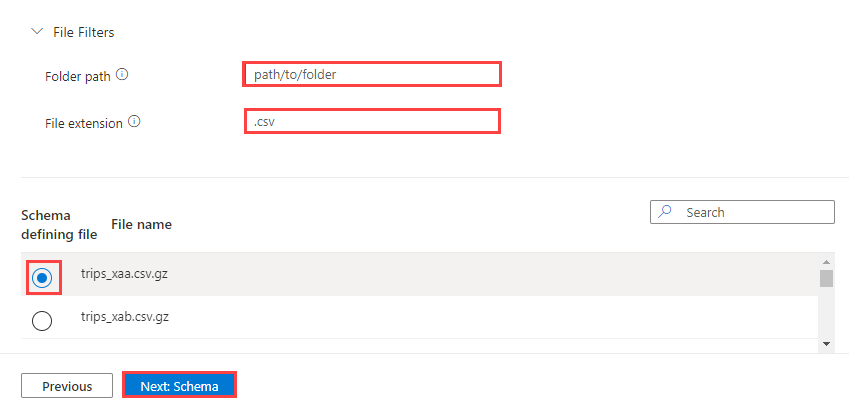
默认情况下,会随机选择容器中的其中一个文件,用于生成表的架构。
(可选)在 架构定义文件下,指定要使用的文件。
选择“下一步: 架构”以查看和编辑表列配置。
架构
“架构”选项卡提供数据的预览。
要生成 LightIngest 命令,请选择“下一步: 开始引入”。
(可选) 您可以:
- 通过从下拉菜单中选择所需格式来更改自动推断的数据格式。
- 更改自动推断的映射名称。 可以使用字母数字字符和下划线。 不支持空格、特殊字符和连字符。
- 使用现有表时,如果表架构与所选格式匹配,可以保留当前表架构。
- 选择“命令查看器”以查看和复制基于输入生成的自动命令。
- 编辑列。 在“部分数据预览”下,选择列下拉菜单以更改表的各个方面。
以下参数决定了你可在表中进行的更改:
- 表类型为“新”或“现有”
- 映射类型为“新”或“现有”
| 表类型 | 映射类型 | 可进行的调整 |
|---|---|---|
| 新建表 | 新映射 | 更改数据类型,重命名列,新建列,删除列,更新列,升序排序,降序排序 |
| 现有表 | 新映射 | 新建列(你随后可在其上更改数据类型、进行重命名和更新), 更新列,升序排序,降序排序 |
| 现有映射 | 升序排序,降序排序 |
注意
添加新列或更新列时,可更改映射转换。 有关详细信息,请参阅映射转换
引入
当表、映射和 LightIngest 命令显示绿色复选标记时,选择“生成”命令框右上角的复制图标以复制生成的 LightIngest 命令。
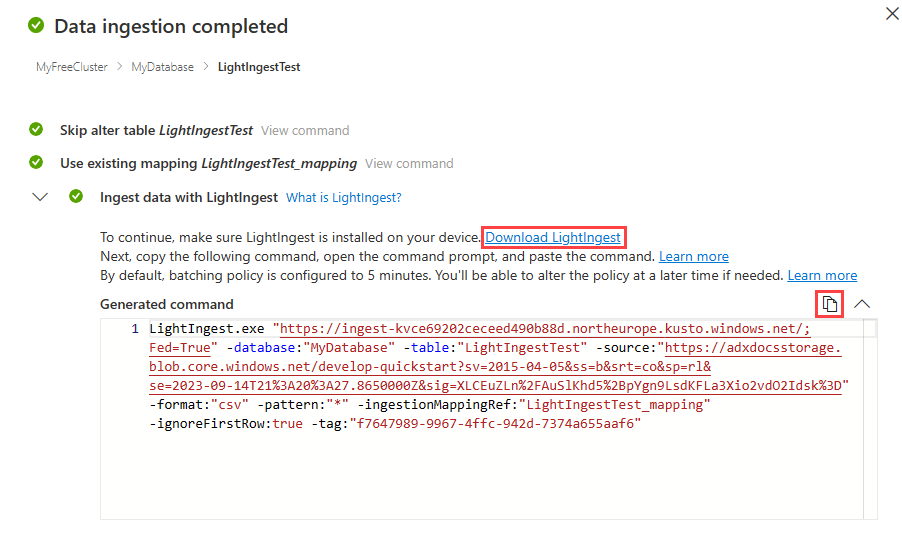
注意
如果需要,可以通过选择“下载 LightIngest”来下载 LightIngest 工具。
要完成引入过程,必须使用此复制的命令运行 LightIngest。
