Azure Data Explorer通过使用更改馈送,支持从用于NoSql的Azure Cosmos DB进行数据摄取。 Cosmos DB 更改源数据连接是一个引入管道,用于侦听 Cosmos DB 更改源并将数据引入到Data Explorer表中。 更改源侦听新文档和更新的文档,但不记录删除。 有关Azure Data Explorer中的数据引入的一般信息,请参阅 Azure Data Explorer 数据引入概述。
每个数据连接侦听特定的 Cosmos DB 容器,并将数据引入指定表(多个连接可以引入到单个表中)。 该引入方法支持流式引入(如果已启用)和排队引入。
使用 Cosmos DB 更改源数据连接的两个主要方案:
本文介绍如何设置 Cosmos DB 更改源数据连接,以便使用系统托管标识将数据引入Azure Data Explorer。 在开始之前,请查看注意事项。
使用以下步骤设置连接器:
第一步:选择一个Azure Data Explorer表并配置其表映射
步骤 2:创建 Cosmos DB 数据连接
步骤 3:测试数据连接
先决条件
在创建数据连接之前,请创建一个表,在其中存储引入的数据并应用与源 Cosmos DB 容器中的架构匹配的映射。 如果你的方案需要的不仅仅是简单的字段映射,则可以使用更新策略来转换和映射从更改源中引入的数据。
下面显示了 Cosmos DB 容器中某个项的示例架构:
{
"id": "17313a67-362b-494f-b948-e2a8e95e237e",
"name": "Cousteau",
"_rid": "pL0MAJ0Plo0CAAAAAAAAAA==",
"_self": "dbs/pL0MAA==/colls/pL0MAJ0Plo0=/docs/pL0MAJ0Plo0CAAAAAAAAAA==/",
"_etag": "\"000037fc-0000-0700-0000-626a44110000\"",
"_attachments": "attachments/",
"_ts": 1651131409
}
使用以下步骤创建表并应用表映射:
在Azure Data Explorer Web UI 中,从左侧导航菜单中选择Query,然后选择要在其中创建表的数据库。
运行以下命令来创建一个名为 TestTable 的表。
.create table TestTable(Id:string, Name:string, _ts:long, _timestamp:datetime)
运行以下命令来创建表映射。
该命令将 Cosmos DB JSON 文档中的自定义属性映射到 TestTable 表中的列,如下所示:
| Cosmos DB 属性 |
表列 |
转换 |
|
id |
ID |
无 |
|
name |
名称 |
无 |
| _ts |
_ts |
无 |
| _ts |
_timestamp |
使用 DateTimeFromUnixSeconds 将 转换_ts (UNIX 秒)为 _timestamp (datetime) |
注意事项
使用以下时间戳列:
- _ts:使用此列将数据与 Cosmos DB 协调。
- _timestamp:使用此列在 Kusto 查询中运行高效的时间筛选器。 有关详细信息,请参阅 Query 最佳做法。
.create table TestTable ingestion json mapping "DocumentMapping"
```
[
{"column":"Id","path":"$.id"},
{"column":"Name","path":"$.name"},
{"column":"_ts","path":"$._ts"},
{"column":"_timestamp","path":"$._ts", "transform":"DateTimeFromUnixSeconds"}
]
```
如果您的方案需要的不仅仅是字段的简单映射,请使用更新策略来转换和映射从更改源引入的数据。
Update 策略在将数据引入表中时进行转换。 使用 Kusto 查询语言编写它们,并在引入管道上运行它们。 使用它们将数据从 Cosmos DB 更改源数据流引入中转换,例如在以下方案中:
- 文档包含的数组在使用
mv-expand 运算符转换为多行时更易于查询。
- 你想要过滤掉文档。 例如,可以使用
where 运算符按类型筛选出文档。
- 你的复杂逻辑无法在表映射中表示。
有关如何创建和管理更新策略的信息,请参阅 Update 策略概述。
步骤 2:创建 Cosmos DB 数据连接
使用以下方法创建数据连接器:
在Azure portal中,转到群集概述页,然后选择Getting started选项卡。
在数据摄取磁贴上,选择创建数据连接>Cosmos DB。
在 Cosmos DB “创建数据连接 ”窗格中,用下表中的信息填写表单:
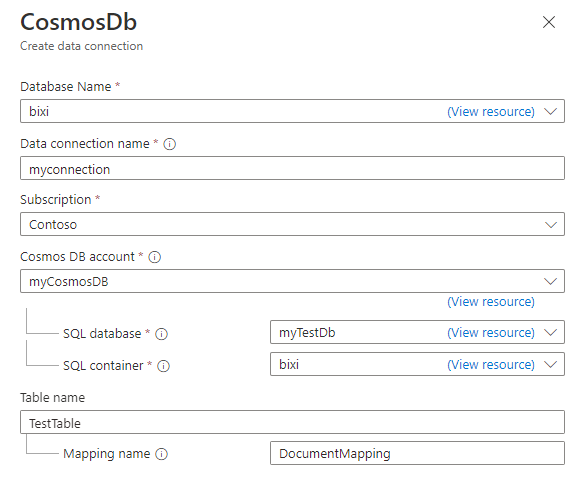
| 字段 |
说明 |
|
数据库名称 |
选择要将数据引入到其中的Azure Data Explorer数据库。 |
|
数据连接名称 |
指定数据连接的名称。 |
|
订阅 |
选择包含 Cosmos DB NoSQL 帐户的订阅。 |
| Cosmos DB 帐户 |
选择要从中引入数据的 Cosmos DB 帐户。 |
| SQL 数据库 |
选择要从中引入数据的 Cosmos DB 数据库。 |
|
SQL 容器 |
选择要从中引入数据的 Cosmos DB 容器。 |
|
表名称 |
指定要将数据引入的 Azure Data Explorer 表名称。 |
| 映射名称 |
(可选)指定要用于数据连接的映射名称。 |
(可选)在 “高级设置” 部分下,输入以下信息:
指定“事件检索开始日期”。 此值是连接器开始引入数据的时间。 如果未指定时间,连接器将从创建数据连接时开始引入数据。 建议的日期格式是 ISO 8601 UTC 标准,按以下方式指定:yyyy-MM-ddTHH:mm:ss.fffffffZ。
选择用户分配,然后选择身份。 默认情况下,连接使用 系统分配的 托管标识。 如有必要,可以使用用户分配的标识。
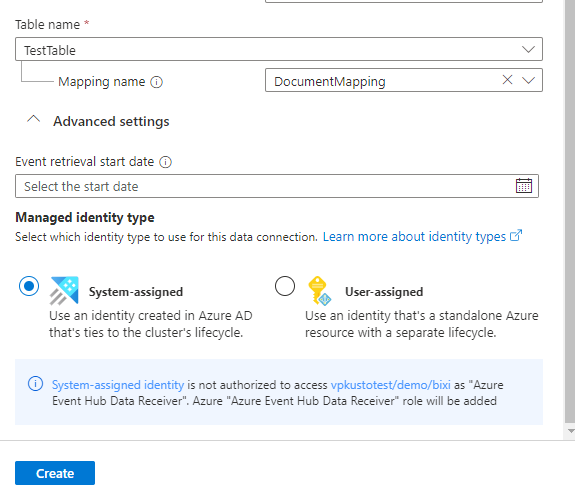
选择“ 创建 ”以创建数据连接。
使用以下示例 ARM 模板作为创建自己的数据连接模板的基础,然后在 Azure portal 中部署它。
若要配置 Cosmos DB 连接,请执行以下操作:
配置系统托管标识以用于 Cosmos DB 连接身份验证。
- 在 Azure Data Explorer Web UI 中,从左侧导航菜单中选择 Query,然后选择数据连接的群集或数据库。
授予数据连接权限以访问您的 Cosmos DB 帐户。 通过为您的 Cosmos DB 提供数据连接访问权限,系统可以访问并从数据库中检索数据。 需要群集的主体 ID,可在Azure portal中找到该 ID。 有关详细信息,请参阅为群集配置托管标识。
注意事项
- 将这些角色分配给主体 ID 的步骤如下:
- Cosmos DB 内置数据读取器
- 无法使用 Azure 门户的角色分配功能分配 Cosmos DB Built-in Data Reader 角色。
-
Cosmos DB 帐户读取者角色
使用以下选项之一向 Cosmos DB 帐户授予访问权限:
通过 Azure CLI 授予访问权限:运行 CLI 命令,使用下表中的信息将占位符替换为适当的值:
az cosmosdb sql role assignment create --account-name <CosmosDbAccountName> --resource-group <CosmosDbResourceGroup> --role-definition-id 00000000-0000-0000-0000-000000000001 --principal-id <ClusterPrincipalId> --scope "/"
az role assignment create --role fbdf93bf-df7d-467e-a4d2-9458aa1360c8 --assignee <ClusterPrincipalId> --scope <CosmosDBAccountResourceId>
| 占位符 |
说明 |
|
<CosmosDBAccountName> |
Cosmos DB 帐户的名称。 |
|
<CosmosDBResourceGroup> |
包含 Cosmos DB 帐户的资源组的名称。 |
|
<CosmosDBAccountResourceId> |
Cosmos DB 帐户的Azure资源 ID(从 subscriptions/ 开始)。 |
|
<集群主体ID> |
分配给群集的托管标识的主体 ID。 可以在Azure portal中找到群集的主体 ID。 有关详细信息,请参阅为群集配置托管标识。 |
使用 ARM 模板授予访问权限:在 Cosmos DB 帐户资源组中部署以下模板:
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"clusterPrincipalId": {
"type": "string",
"metadata": { "description": "The principle ID of your cluster." }
},
"cosmosDbAccount": {
"type": "string",
"metadata": { "description": "The name of your Cosmos DB account." }
},
"cosmosDbAccountResourceId": {
"type": "string",
"metadata": { "description": "The resource ID of your Cosmos DB account." }
}
},
"variables": {
"cosmosDataReader": "00000000-0000-0000-0000-000000000001",
"dataRoleDefinitionId": "[format('/subscriptions/{0}/resourceGroups/{1}/providers/Microsoft.DocumentDB/databaseAccounts/{2}/sqlRoleDefinitions/{3}', subscription().subscriptionId, resourceGroup().name, parameters('cosmosDbAccount'), variables('cosmosDataReader'))]",
"roleAssignmentId": "[guid(parameters('cosmosDbAccountResourceId'), parameters('clusterPrincipalId'))]",
"rbacRoleDefinitionId": "[format('/subscriptions/{0}/providers/Microsoft.Authorization/roleDefinitions/{1}', subscription().subscriptionId, 'fbdf93bf-df7d-467e-a4d2-9458aa1360c8')]"
},
"resources": [
{
"type": "Microsoft.DocumentDB/databaseAccounts/sqlRoleAssignments",
"apiVersion": "2022-08-15",
"name": "[concat(parameters('cosmosDbAccount'), '/', guid(parameters('clusterPrincipalId'), parameters('cosmosDbAccount')))]",
"properties": {
"principalId": "[parameters('clusterPrincipalId')]",
"roleDefinitionId": "[variables('dataRoleDefinitionId')]",
"scope": "[resourceId('Microsoft.DocumentDB/databaseAccounts', parameters('cosmosDbAccount'))]"
}
},
{
"type": "Microsoft.Authorization/roleAssignments",
"apiVersion": "2022-04-01",
"name": "[variables('roleAssignmentId')]",
"scope": "[format('Microsoft.DocumentDb/databaseAccounts/{0}', parameters('cosmosDbAccount'))]",
"properties": {
"description": "Giving RBAC reader on Cosmos DB",
"principalId": "[parameters('clusterPrincipalId')]",
"principalType": "ServicePrincipal",
"roleDefinitionId": "[variables('rbacRoleDefinitionId')]"
}
}
]
}
部署以下 ARM 模板以创建 Cosmos DB 数据连接。 将占位符替换为适当的值。
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"kustoClusterName": {
"type": "string",
"metadata": { "description": "Kusto Cluster name" }
},
"kustoDbName": {
"type": "string",
"metadata": { "description": "Kusto Database name" }
},
"kustoConnectionName": {
"type": "string",
"metadata": { "description": "Kusto Database connection name" }
},
"kustoLocation": {
"type": "string",
"metadata": { "description": "Location (Azure Region) of the Kusto cluster" }
},
"kustoTable": {
"type": "string",
"metadata": { "description": "Kusto Table name where to ingest data" }
},
"kustoMappingRuleName": {
"type": "string",
"defaultValue": "",
"metadata": { "description": "Mapping name of the Kusto Table (if omitted, default mapping is applied)" }
},
"managedIdentityResourceId": {
"type": "string",
"metadata": { "description": "ARM resource ID of the managed identity (cluster resource ID for system or user identity)" }
},
"cosmosDbAccountResourceId": {
"type": "string",
"metadata": { "description": "ARM resource ID of Cosoms DB account" }
},
"cosmosDbDatabase": {
"type": "string",
"metadata": { "description": "Cosmos DB Database name" }
},
"cosmosDbContainer": {
"type": "string",
"metadata": { "description": "Cosmos DB container name" }
},
"retrievalStartDate": {
"type": "string",
"defaultValue": "",
"metadata": { "description": "Date-time at which to start the data retrieval; default: 'now' if not provided. Recommended format: yyyy-MM-ddTHH:mm:ss.fffffffZ" }
}
},
"variables": { },
"resources": [{
"type": "Microsoft.Kusto/Clusters/Databases/DataConnections",
"apiVersion": "2022-11-11",
"name": "[concat(parameters('kustoClusterName'), '/', parameters('kustoDbName'), '/', parameters('kustoConnectionName'))]",
"location": "[parameters('kustoLocation')]",
"kind": "CosmosDb",
"properties": {
"tableName": "[parameters('kustoTable')]",
"mappingRuleName": "[parameters('kustoMappingRuleName')]",
"managedIdentityResourceId": "[parameters('managedIdentityResourceId')]",
"cosmosDbAccountResourceId": "[parameters('cosmosDbAccountResourceId')]",
"cosmosDbDatabase": "[parameters('cosmosDbDatabase')]",
"cosmosDbContainer": "[parameters('cosmosDbContainer')]",
"retrievalStartDate": "[parameters('retrievalStartDate')]"
}
}]
}
步骤 3:测试数据连接
在 Cosmos DB 容器中,插入以下文档:
{
"name":"Cousteau"
}
在 Azure Data Explorer Web UI 中,运行以下查询:
TestTable
结果集应如下图所示:

注意事项
Azure 数据资源管理器使用用于排队数据引入的聚合(批处理)策略来优化引入过程。 当批满足以下条件之一时,默认批处理策略会密封一个批:最长延迟时间为 5 分钟、总大小为 1 GB 或 1,000 个 blob。 因此,可能会遇到延迟。 有关详细信息,请参阅 批处理策略。 若要降低延迟,请将表配置为支持流式处理。 请参阅 流媒体策略。
注意事项
以下注意事项适用于 Cosmos DB 更改源:
变更日志不会公开“删除”事件。
Cosmos DB 更改源仅包括新文档和更新的文档。 如果您需要了解有关已删除文档的信息,您可以配置数据流为使用软标记将 Cosmos DB 文档标记为已删除。 添加了一个属性到更新事件中,以指示文档是否被删除。 然后,可以在查询中使用 where 运算符来筛选出它们。
例如,如果将 deleted 属性映射到名为“IsDeleted”的表列,则可以使用以下查询筛选出已删除的文档:
TestTable
| where not(IsDeleted)
更改提要只展示文档的最新更新。
若要了解第二个注意事项的影响,请查看以下方案:
Cosmos DB 容器包含文档 A 和 B。下表显示了对名为 foo 的属性的更改:
| 文档编号 |
属性 foo |
事件 |
文档时间戳记 (_ts) |
| A |
红色 |
创建 |
10 |
| B |
蓝色 |
创建 |
20 |
| A |
橙色 |
更新 |
30 |
|
A |
粉色 |
更新 |
40 |
| B |
紫罗兰色 |
更新 |
50 |
| A |
胭脂红色 |
更新 |
50 |
| B |
霓虹蓝色 |
更新 |
70 |
数据连接器定期轮询更改源 API,通常每隔几秒钟轮询一次。 每个轮询都包含两次调用之间容器中发生的更改(但每个文档只有最新版的更改)。
为了说明此问题,请考虑带有时间戳 15、35、55 和 75 的一系列 API 调用,如下表所示:
| API 调用时间戳 |
文档编号 |
属性 foo |
文档时间戳记 (_ts) |
| 15 |
A |
红色 |
10 |
| 35 |
B |
蓝色 |
20 |
| 35 |
A |
橙色 |
30 |
| 55 |
B |
紫罗兰色 |
50 |
| 55 |
A |
胭脂红色 |
60 |
| 75 |
B |
霓虹蓝色 |
70 |
将 API 结果与 Cosmos DB 文档中所做的更改列表进行比较,你会注意到它们不匹配。 文档A的更新事件(在更改表中时间戳为40的一行进行了突出显示)未显示在API调用结果中。
若要了解事件为何未出现,请查阅时间戳 35 到 55 之间的 API 调用对文档 A 的更改。 在这两次调用之间,文档 A 更改了两次,如下所示:
| 文档编号 |
属性 foo |
事件 |
文档时间戳记 (_ts) |
| A |
粉色 |
更新 |
40 |
| A |
胭脂红色 |
更新 |
50 |
在时间戳 55 时进行 API 调用的时候,更改源 API 返回文档的最新版本。 在此情况下,文档A的最新版本是在时间戳50时的更新,即将属性foo从粉红更新为胭脂红。
由于这种情况,数据连接器可能会错过一些中间文档更改。 例如,如果数据连接服务关闭几分钟,或者文档更改的频率高于 API 轮询频率,则数据连接器可能会错过一些事件。 但是,每个文档的最新状态均会被捕获。
不支持删除和重新创建 Cosmos DB 容器。
Azure Data Explorer通过检查源位于源中的“位置”来跟踪更改源。 此过程在容器的每个物理分区上使用延续令牌。 删除并重新创建容器时,延续令牌将变为无效且不会重置。 在这种情况下,必须删除并重新创建数据连接。
估算成本
使用 Cosmos DB 数据连接对 Cosmos DB 容器 的请求单位(RU) 使用情况有何影响?
连接器在容器的每个物理分区上调用 Cosmos DB 更改源 API,每秒最多调用一次。 以下成本与这些调用相关:
| 成本 |
说明 |
| 固定成本 |
固定成本大约是每个物理分区每秒消耗两个 RU。 |
| 可变成本 |
变量成本大约占用来编写文档的 RU 的 2%,但这一数值可能会根据具体情况有所不同。 例如,如果将 100 个文档写入 Cosmos DB 容器,则写入这些文档的成本为 1,000 RU。 使用连接器读取文档的相应成本约为 2% 写入文档的成本约为 20 RU。 |
相关内容