本快速入门介绍如何在独立的 Azure 数据资源管理器 Web UI 中查询数据。 Azure 数据资源管理器提供了一种 Web 体验,使你能够连接到 Azure 数据资源管理器群集并编写、运行和共享 Kusto 查询语言 (KQL) 命令和查询。 该 Web 体验可在 Azure 门户中使用,也可作为独立的 Web 应用程序(即 Azure 数据资源管理器 Web UI)使用。 在 Azure 数据资源管理器 Web UI 中,查询编辑器会在你编写查询时提供建议和警告。 若要自定义收到的建议和警告,请参阅设置查询建议。
先决条件
在开始之前,请确保具有以下项:
- Microsoft 帐户或 Microsoft Entra 用户标识。 无需 Azure 订阅。
- Azure 数据资源管理器群集和数据库。 使用公开提供的帮助群集或创建群集和数据库。
- 登录到 Azure 数据资源管理器 Web UI。
添加群集
首次打开 Web UI 时,应该会在“查询”页面中看到与“help”群集的连接。 本快速入门中的示例使用“help”群集的 StormEvents 数据库中的 Samples 表。
如果要在另一群集上运行查询,则必须添加与该群集的连接。 若要添加新的群集连接,请执行以下操作:
- 在左侧菜单中,选择“查询”。
- 在左上方的窗格中,选择“添加连接”。
- 在“添加连接”对话框中,输入群集“连接 URI”和“显示名称”。
- 选择“添加”以添加连接。
如果没有看到 帮助 群集,请使用前面的步骤添加它,并使用“help”作为 连接 URI。
运行查询
若要运行查询,必须选择要在其上运行查询的数据库才能设置查询上下文。
在“群集连接”窗格中的 help 群集下,选择“示例”数据库。
将以下查询复制并粘贴到查询窗口中。 在窗口顶部,选择“运行”。
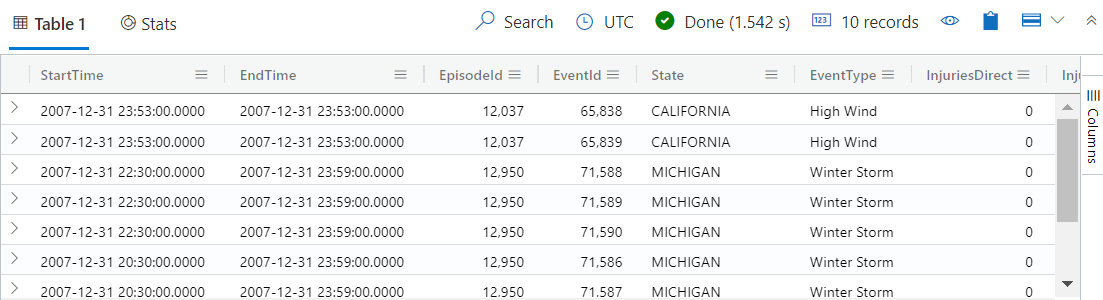
StormEvents | sort by StartTime desc | take 10此查询返回 StormEvents 表中的 10 条最新记录。 结果应如下表所示。
将以下查询复制并粘贴到第一个查询下方的查询窗口中。 请注意,它没有像第一个查询那样在单独行上进行格式化。
StormEvents | sort by StartTime desc | project StartTime, EndTime, State, EventType, DamageProperty, EpisodeNarrative | take 10选择新查询。 按 Shift+Alt+F 设置查询格式,如以下查询所示。

选择“运行”或按 Shift + Enter 以运行查询。 此查询返回与第一条记录相同的记录,但仅包括
project语句中指定的列。 结果应如下表所示。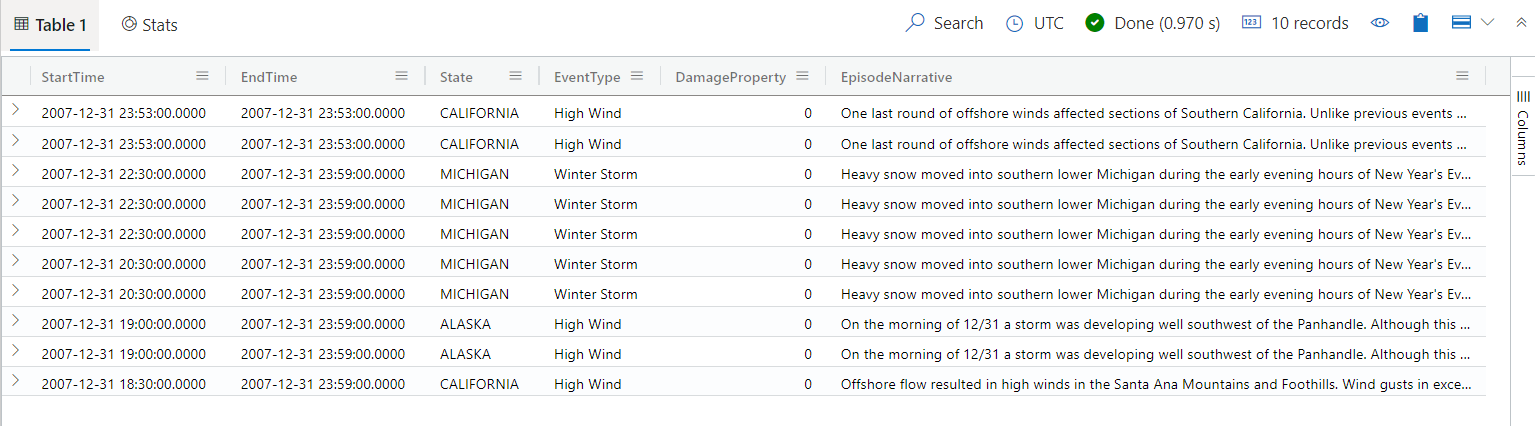
提示
选择查询窗口顶部的“撤回”以显示第一个查询的结果集,而无需重新运行该查询。 通常在分析期间,会运行多个查询,通过“撤回”,你可以检索先前查询的结果。
让我们再运行一个查询来查看不同类型的输出。
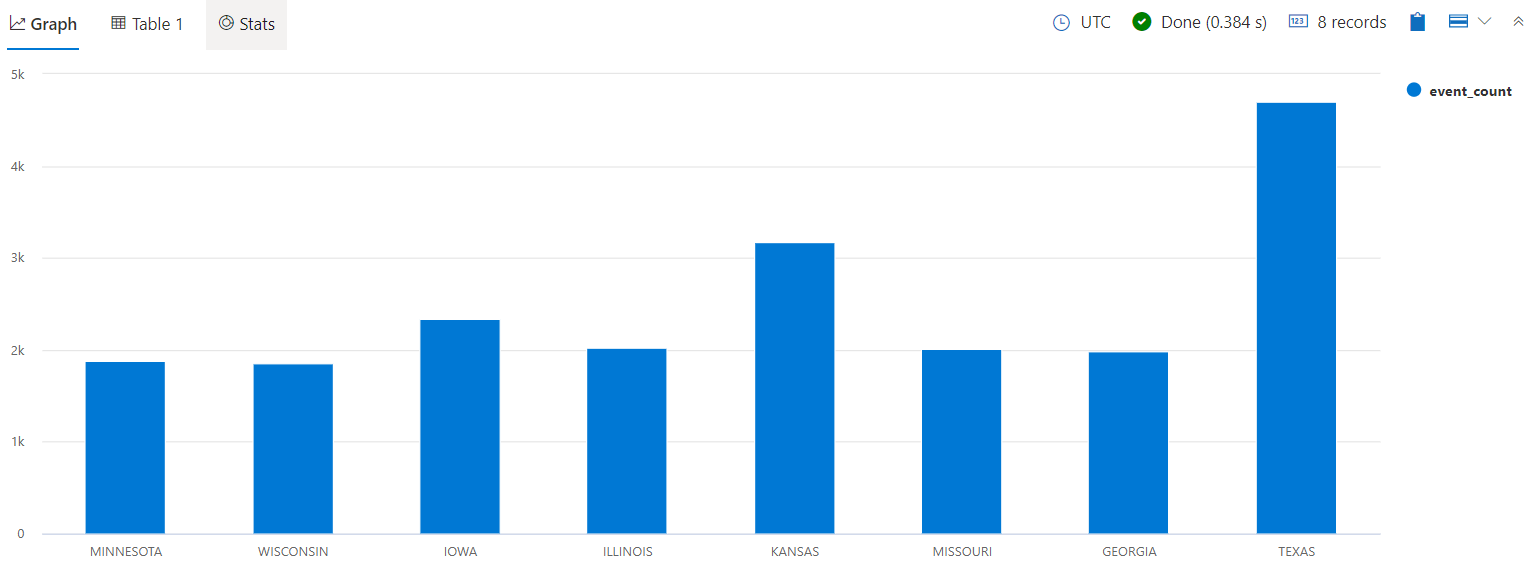
StormEvents | summarize event_count=count(), mid = avg(BeginLat) by State | sort by mid | where event_count > 1800 | project State, event_count | render columnchart结果应如下图所示。
注意
查询表达式中的空白行可能影响执行查询的那一部分。
- 如果未选定文本,则假定以空行分隔查询或命令。
- 如果选定了文本,则运行选定的文本。
提供反馈
请执行以下步骤以提供反馈:
- 在应用程序的右上角,选择反馈图标
 。
。 - 输入反馈,然后选择“提交”。
清理资源
未在此快速入门中创建任何资源,但如果要从应用程序中删除一个或两个群集,请右键单击群集并选择“删除连接”。 另一个选项是从“设置常规”>选项卡中选择“清除本地状态”。此作将删除所有群集连接并关闭所有打开的查询选项卡。