在需要实现引入和查询之间的低延迟时,流式引入对于加载数据非常有用。 对于以下情况,请考虑使用流式引入:
- 要求延迟少于一秒钟。
- 需要优化多个表的操作处理,其中进入每个表的数据流相对较小(每秒几条记录),但总体数据引入量较大(每秒成千上万条记录)。
如果每个表中的数据流较高(每小时超过 4 GB),请考虑使用 排队引入。
若要详细了解各种引入方法,请参阅数据引入概述。
有关基于早期 SDK 版本的代码示例,请参阅 archived 文章。
选择适当的流式引入类型
支持两种流式引入类型:
| 引入类型 |
说明 |
| 数据连接 |
事件中心、IoT Hub和事件网格数据连接可以使用流式引入,前提是它在群集级别启用。 使用流式引入的决定是根据在目标表上配置的流式引入策略来完成的。
有关管理数据连接的信息, 请参阅 Event Hub、IoT Hub 和 Event Grid。 |
| 自定义引入 |
自定义引入要求编写使用其中一个 Azure Data Explorer client 库的应用程序。
使用本文中的信息配置自定义引入。 您可能也会发现 C?view=azure-data-explorer&preserve-view=true# 实时数据流摄取示例应用程序很有帮助。 |
使用下表帮助你选择适合你的环境的引入类型:
| 条件 |
数据连接 |
自定义引入 |
| 数据从引入开始到可供查询之间的延迟 |
延迟时间更长 |
延迟更短 |
| 开发开销 |
快速而简便的设置,无需任何开发负担 |
创建用于引入数据、处理错误以及确保数据一致性的应用程序的开发成本较高。 |
注意事项
可以使用 Azure 门户或通过 C# 编程方式管理群集上启用和禁用流式引入的过程。 如果对 自定义应用程序使用 C#,则可能发现使用编程方法更方便。
先决条件
可能影响流式引入的主要因素有:
- VM 和群集大小:增大 VM 和群集大小可以提高流式引入的性能和容量。 并发引入请求数量限制为每个核心六个。 例如,对于 16 核 SKU(如 D14 和 L16),支持的最大负载为 96 个并发引入请求。 对于双核 SKU(例如 D11),支持的最大负载为 12 个并发引入请求。
- 数据大小限制:流式引入请求的数据大小限制为 4 MB。 这包括引入期间为更新策略创建的任何数据。
- 架构更新:对流式引入服务进行架构更新(例如创建和修改表与引入映射)最长可能需要花费 5 分钟时间。 有关详细信息,请参阅 流式引入和架构更改。
-
SSD 容量:在群集上启用流式引入功能,即使数据不是通过流式方法引入,也会使用群集计算机本地 SSD 磁盘的一部分来存储流式引入的数据,从而减少可用于热缓存的存储空间。
-
数据库游标:使用流式引入时, 数据库游标 更新可能会滞后于数据可用性长达 60 秒。 这种延迟源于异步后台密封过程,这些进程将数据从流式处理缓冲区转换为永久性列存储区,在此期间,游标(用于增量处理、连续导出或具体化视图)会更新。 如果您的负载需要立即的游标一致性以实现一次性语义,请考虑改用队列摄取,或在应用程序逻辑中应对可能的延迟。
在群集上启用流式引入
必须先在群集上启用流式引入,并定义流式引入策略,然后才能使用流式引入。
创建群集或将其添加到现有群集时,可以启用该功能。
创建新群集时启用流式引入
可以使用 Azure portal 或以编程方式在 C# 中创建新群集时启用流式引入。
若要在创建新的Azure Data Explorer群集时启用流式引入,请运行以下代码:
using System.Threading.Tasks;
using Azure;
using Azure.Core;
using Azure.Identity; // Required package Azure.Identity
using Azure.ResourceManager;
using Azure.ResourceManager.Kusto; // Required package Azure.ResourceManager.Kusto
using Azure.ResourceManager.Kusto.Models;
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
var subscriptionId = "<subscriptionId>";
var credentials = new ClientSecretCredential(appTenant, appId, appKey);
var resourceManagementClient = new ArmClient(credentials, subscriptionId);
var resourceGroupName = "<resourceGroupName>";
var clusterName = "<clusterName>";
var subscription = await resourceManagementClient.GetDefaultSubscriptionAsync();
var resourceGroup = (await subscription.GetResourceGroupAsync(resourceGroupName)).Value;
var clusters = resourceGroup.GetKustoClusters();
var location = new AzureLocation("<location>");
var skuName = new KustoSkuName("<skuName>");
var skuTier = new KustoSkuTier("<skuTier>");
var clusterData = new KustoClusterData(location, new KustoSku(skuName, skuTier)) { IsStreamingIngestEnabled = true };
await clusters.CreateOrUpdateAsync(WaitUntil.Completed, clusterName, clusterData);
}
}
在现有群集上启用流式引入
如果有现有群集,则可以使用 Azure portal 或以编程方式在 C# 中启用流式引入。
在Azure portal中,转到Azure Data Explorer群集。
在“设置”中选择“配置”。
在“配置”窗格中,选择“开启”以启用“流式引入”。
选择“保存” 。
在 Azure Data Explorer 中开启流式引入。
更新现有Azure Data Explorer群集时,可以启用流式引入。
using System.Threading.Tasks;
using Azure;
using Azure.Identity; // Required package Azure.Identity
using Azure.ResourceManager;
using Azure.ResourceManager.Kusto; // Required package Azure.ResourceManager.Kusto
using Azure.ResourceManager.Kusto.Models;
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
var subscriptionId = "<subscriptionId>";
var credentials = new ClientSecretCredential(appTenant, appId, appKey);
var resourceManagementClient = new ArmClient(credentials, subscriptionId);
var resourceGroupName = "<resourceGroupName>";
var clusterName = "<clusterName>";
var subscription = await resourceManagementClient.GetDefaultSubscriptionAsync();
var resourceGroup = (await subscription.GetResourceGroupAsync(resourceGroupName)).Value;
var cluster = (await resourceGroup.GetKustoClusterAsync(clusterName)).Value;
var clusterPatch = new KustoClusterPatch(cluster.Data.Location) { IsStreamingIngestEnabled = true };
await cluster.UpdateAsync(WaitUntil.Completed, clusterPatch);
}
}
创建目标表并定义策略
创建一个表以接收流式引入数据,并使用 C# Azure portal或以编程方式定义其相关策略。
在Azure portal中,导航到群集。
选择“查询”。
Azure Data Explorer门户中的
将以下命令复制到“查询窗格”中,然后选择“运行”以创建将通过流式引入接收数据的表 。
.create table TestTable (TimeStamp: datetime, Name: string, Metric: int, Source:string)
创建表以将流式数据引入 Azure Data Explorer。
将以下命令之一复制到“查询窗格”并选择“运行” 。 这将定义创建的表或包含表的数据库上的流式引入策略。
提示
在数据库级别定义的策略适用于数据库中的所有现有表和未来表。 在数据库级别启用策略时,无需为每个表启用该策略。
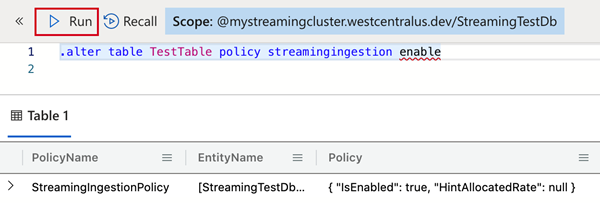
using Kusto.Data; // Requires Package Microsoft.Azure.Kusto.Data
using Kusto.Data.Common;
using Kusto.Data.Net.Client;
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var clusterPath = "https://<clusterName>.<region>.kusto.chinacloudapi.cn";
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
// Create Kusto connection string with App Authentication
var connectionStringBuilder = new KustoConnectionStringBuilder(clusterPath)
.WithAadApplicationKeyAuthentication(
applicationClientId: appId,
applicationKey: appKey,
authority: appTenant
);
using var client = KustoClientFactory.CreateCslAdminProvider(connectionStringBuilder);
var tableName = "<tableName>";
var tableSchema = new TableSchema(
tableName,
new ColumnSchema[]
{
new("TimeStamp", "System.DateTime"),
new("Name", "System.String"),
new("Metric", "System.int"),
new("Source", "System.String"),
});
var tableCreateCommand = CslCommandGenerator.GenerateTableCreateCommand(tableSchema);
var tablePolicyAlterCommand = CslCommandGenerator.GenerateTableAlterStreamingIngestionPolicyCommand(tableName, isEnabled: true);
await client.ExecuteControlCommandAsync(tableCreateCommand);
await client.ExecuteControlCommandAsync(tablePolicyAlterCommand);
}
}
创建流式引入应用程序以将数据引入群集
创建应用程序,以使用首选语言将数据引入群集。
using System.IO;
using System.Threading.Tasks;
using Kusto.Data; // Requires Package Microsoft.Azure.Kusto.Data
using Kusto.Data.Common;
using Kusto.Ingest; // Requires Package Microsoft.Azure.Kusto.Ingest
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var clusterPath = "https://<clusterName>.<region>.kusto.chinacloudapi.cn";
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
// Create Kusto connection string with App Authentication
var connectionStringBuilder = new KustoConnectionStringBuilder(clusterPath)
.WithAadApplicationKeyAuthentication(
applicationClientId: appId,
applicationKey: appKey,
authority: appTenant
);
// Create a disposable client that will execute the ingestion
using var client = KustoIngestFactory.CreateStreamingIngestClient(connectionStringBuilder);
// Ingest from a compressed file
var fileStream = File.Open("MyFile.gz", FileMode.Open);
// Initialize client properties
var ingestionProperties = new KustoIngestionProperties(databaseName: "<databaseName>", tableName: "<tableName>");
// Create source options
var sourceOptions = new StreamSourceOptions { CompressionType = DataSourceCompressionType.gzip, };
// Ingest from stream
await client.IngestFromStreamAsync(fileStream, ingestionProperties, sourceOptions);
}
}
from azure.kusto.data import KustoConnectionStringBuilder, DataFormat
from azure.kusto.ingest import IngestionProperties, KustoStreamingIngestClient
clusterPath = "https://<clusterName>.<region>.kusto.chinacloudapi.cn"
appId = "<appId>"
appKey = "<appKey>"
appTenant = "<appTenant>"
dbName = "<dbName>"
tableName = "<tableName>"
csb = KustoConnectionStringBuilder.with_aad_application_key_authentication(
clusterPath,
appId,
appKey,
appTenant
)
client = KustoStreamingIngestClient(csb)
ingestionProperties = IngestionProperties(
database=dbName,
table=tableName,
data_format=DataFormat.CSV
)
# Ingest from file
# Automatically detects gz format
client.ingest_from_file("MyFile.gz", ingestion_properties=ingestionProperties)
// Load modules using ES6 import statements:
import { DataFormat, IngestionProperties, StreamingIngestClient } from "azure-kusto-ingest";
import { KustoConnectionStringBuilder } from "azure-kusto-data";
// For earlier version, load modules using require statements:
// const IngestionProperties = require("azure-kusto-ingest").IngestionProperties;
// const KustoConnectionStringBuilder = require("azure-kusto-data").KustoConnectionStringBuilder;
// const {DataFormat} = require("azure-kusto-ingest").IngestionPropertiesEnums;
// const StreamingIngestClient = require("azure-kusto-ingest").StreamingIngestClient;
const clusterPath = "https://<clusterName>.<region>.kusto.chinacloudapi.cn";
const appId = "<appId>";
const appKey = "<appKey>";
const appTenant = "<appTenant>";
const dbName = "<dbName>";
const tableName = "<tableName>";
const mappingName = "<mappingName>"; // Required for JSON formatted files
const ingestionProperties = new IngestionProperties({
database: dbName, // Your database
table: tableName, // Your table
format: DataFormat.JSON,
ingestionMappingReference: mappingName
});
// Initialize client with engine endpoint
const client = new StreamingIngestClient(
KustoConnectionStringBuilder.withAadApplicationKeyAuthentication(
clusterPath,
appId,
appKey,
appTenant
),
ingestionProperties
);
// Automatically detects gz format
await client.ingestFromFile("MyFile.gz", ingestionProperties);
import (
"context"
"github.com/Azure/azure-kusto-go/kusto"
"github.com/Azure/azure-kusto-go/kusto/ingest"
"github.com/Azure/go-autorest/autorest/azure/auth"
)
func ingest() {
clusterPath := "https://<clusterName>.<region>.kusto.chinacloudapi.cn"
appId := "<appId>"
appKey := "<appKey>"
appTenant := "<appTenant>"
dbName := "<dbName>"
tableName := "<tableName>"
mappingName := "<mappingName>" // Optional, can be nil
// Creates a Kusto Authorizer using your client identity, secret, and tenant identity.
// You may also uses other forms of authorization, see GoDoc > Authorization type.
// auth package is: "github.com/Azure/go-autorest/autorest/azure/auth"
authorizer := kusto.Authorization{
Config: auth.NewClientCredentialsConfig(appId, appKey, appTenant),
}
// Create a client
client, err := kusto.New(clusterPath, authorizer)
if err != nil {
panic("add error handling")
}
// Create an ingestion instance
// Pass the client, the name of the database, and the name of table you wish to ingest into.
in, err := ingest.New(client, dbName, tableName)
if err != nil {
panic("add error handling")
}
// Go currently only supports streaming from a byte array with a maximum size of 4 MB.
jsonEncodedData := []byte("{\"a\": 1, \"b\": 10}\n{\"a\": 2, \"b\": 20}")
// Ingestion from a stream commits blocks of fully formed data encodes (JSON, AVRO, ...) into Kusto:
if err := in.Stream(context.Background(), jsonEncodedData, ingest.JSON, mappingName); err != nil {
panic("add error handling")
}
}
import com.microsoft.azure.kusto.data.auth.ConnectionStringBuilder;
import com.microsoft.azure.kusto.ingest.IngestClient;
import com.microsoft.azure.kusto.ingest.IngestClientFactory;
import com.microsoft.azure.kusto.ingest.IngestionProperties;
import com.microsoft.azure.kusto.ingest.result.OperationStatus;
import com.microsoft.azure.kusto.ingest.source.CompressionType;
import com.microsoft.azure.kusto.ingest.source.StreamSourceInfo;
import java.io.FileInputStream;
import java.io.InputStream;
public class FileIngestion {
public static void main(String[] args) throws Exception {
String clusterPath = "https://<clusterName>.<region>.kusto.chinacloudapi.cn";
String appId = "<appId>";
String appKey = "<appKey>";
String appTenant = "<appTenant>";
String dbName = "<dbName>";
String tableName = "<tableName>";
// Build connection string and initialize
ConnectionStringBuilder csb =
ConnectionStringBuilder.createWithAadApplicationCredentials(
clusterPath,
appId,
appKey,
appTenant
);
// Initialize client and its properties
IngestClient client = IngestClientFactory.createClient(csb);
IngestionProperties ingestionProperties =
new IngestionProperties(
dbName,
tableName
);
// Ingest from a compressed file
// Create Source info
InputStream zipInputStream = new FileInputStream("MyFile.gz");
StreamSourceInfo zipStreamSourceInfo = new StreamSourceInfo(zipInputStream);
// If the data is compressed
zipStreamSourceInfo.setCompressionType(CompressionType.gz);
// Ingest from stream
OperationStatus status = client.ingestFromStream(zipStreamSourceInfo, ingestionProperties).getIngestionStatusCollection().get(0).status;
}
}
在群集上禁用流数据引入
在Azure Data Explorer群集上禁用流式引入之前,请从所有相关表和数据库中删除流引入策略。 删除流式引入策略会触发Azure Data Explorer群集内的数据重新排列。 流式引入数据从初始存储移动到列存储(盘区或分片)中的永久存储。 此过程可能需要几秒钟到几个小时,具体取决于初始storage中的数据量。
删除流式引入策略
可以使用 Azure portal 或以编程方式在 C# 中删除流式引入策略。
在Azure portal中,转到Azure Data Explorer群集,然后选择 Query。
要从表中删除流引入策略,请将以下命令复制到“查询窗格”并选择“运行” 。
.delete table TestTable policy streamingingestion
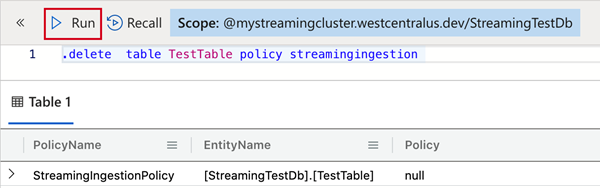
在“设置”中选择“配置”。
在“配置”窗格中,选择“关闭”以禁用“流式引入”。
选择“保存” 。
<c1><c0><sb0>关闭 Azure Data Explorer 中的流式引入。</sb0></c0></c1>
若要从此表删除流式引入策略,请运行以下代码:
using System.Threading.Tasks;
using Kusto.Data; // Requires Package Microsoft.Azure.Kusto.Data
using Kusto.Data.Common;
using Kusto.Data.Net.Client;
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var clusterPath = "https://<clusterName>.<region>.kusto.chinacloudapi.cn";
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
// Create Kusto connection string with App Authentication
var connectionStringBuilder = new KustoConnectionStringBuilder(clusterPath)
.WithAadApplicationKeyAuthentication(
applicationClientId: appId,
applicationKey: appKey,
authority: appTenant
);
using var client = KustoClientFactory.CreateCslAdminProvider(connectionStringBuilder);
var tablePolicyDropCommand = CslCommandGenerator.GenerateTableStreamingIngestionPolicyDropCommand("<dbName>", "<tableName>");
await client.ExecuteControlCommandAsync(tablePolicyDropCommand);
}
}
若要在群集上禁用流式引入策略,请运行以下代码:
using System.Threading.Tasks;
using Azure;
using Azure.Identity; // Required package Azure.Identity
using Azure.ResourceManager;
using Azure.ResourceManager.Kusto; // Required package Azure.ResourceManager.Kusto
using Azure.ResourceManager.Kusto.Models;
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
var subscriptionId = "<subscriptionId>";
var credentials = new ClientSecretCredential(appTenant, appId, appKey);
var resourceManagementClient = new ArmClient(credentials, subscriptionId);
var resourceGroupName = "<resourceGroupName>";
var clusterName = "<clusterName>";
var subscription = await resourceManagementClient.GetDefaultSubscriptionAsync();
var resourceGroup = (await subscription.GetResourceGroupAsync(resourceGroupName)).Value;
var cluster = (await resourceGroup.GetKustoClusterAsync(clusterName)).Value;
var clusterPatch = new KustoClusterPatch(cluster.Data.Location) { IsStreamingIngestEnabled = false };
await cluster.UpdateAsync(WaitUntil.Completed, clusterPatch);
}
}
限制
-
数据映射必须预先创建才能用于流式引入。 单个流式传输引入请求不支持内联数据映射。
- 无法对流式引入数据设置 Extent 标记。
-
更新策略
- 更新策略只能引用源表中新引入的数据,而不能引用数据库中的任何其他数据或表
- 不支持 Python 插件
- 当具有 事务策略 的更新策略失败时,重试将回退到批量引入。
- 对于包含 运算符 的级联更新策略,必须在所有上游表上禁用流式引入。 例如,考虑表 1 更新 Table2、Table2 更新 Table3 和 Table3 更新 Table4 的级联更新策略。 如果 Table4 的更新策略包含联接,则必须在 Table1、Table2 和 Table3 上禁用流式引入。
- 如果在用作后继数据库的先导数据库的群集上启用了流式引入,则必须在后续群集上启用流式引入,以遵循流式引入数据。
相关内容