适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
若要将数据从 Oracle Server、Netezza、Teradata 或 SQL Server 中的数据仓库复制到Azure Synapse Analytics,必须从多个表加载大量数据。 通常情况下,必须在每个表中对数据分区,以便使用多个线程从单个表并行加载行。 本文介绍可以在这些方案中使用的模板。
注意
如果要将数据从少量数据量相对较小的表复制到Azure Synapse Analytics,则使用 Azure Data Factory 复制数据工具更高效。 本文介绍的模板超出你对该方案的需求。
关于此解决方案模板
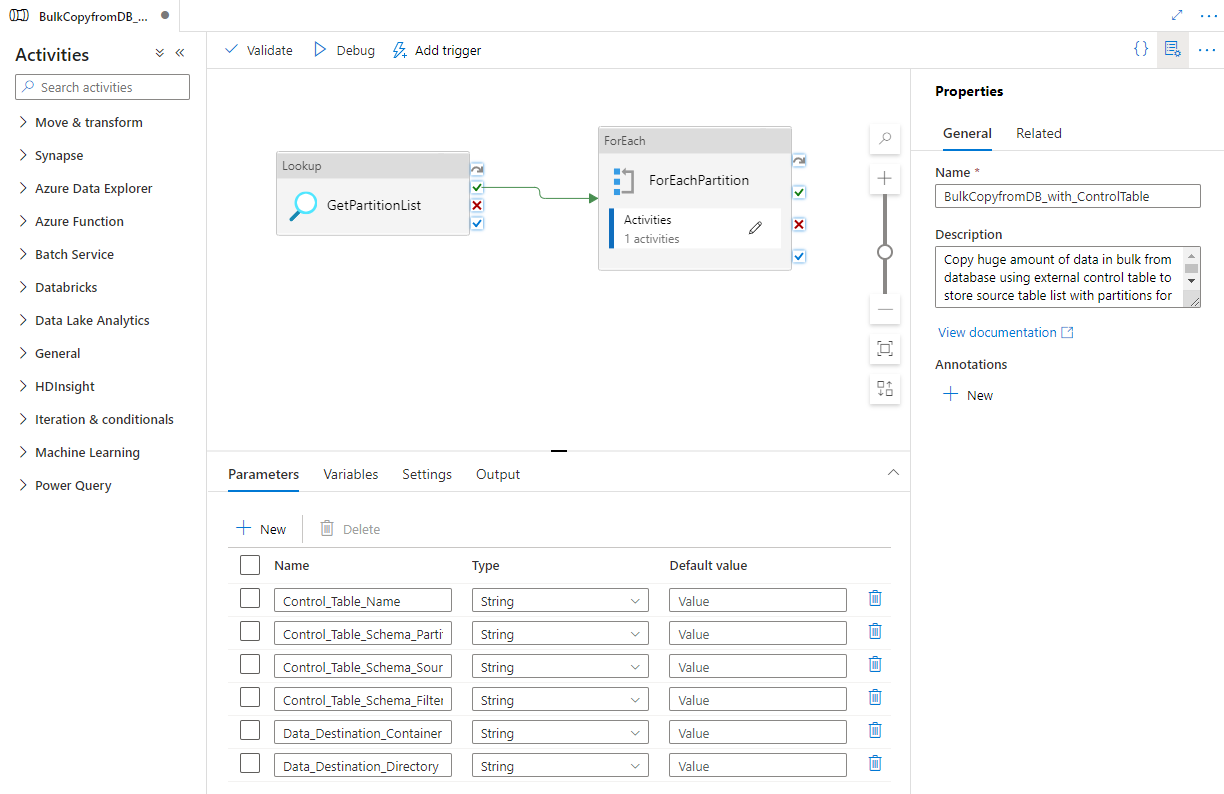
此模板可从外部控制表检索用于复制的源数据库分区的列表。 然后,它会循环访问源数据库中的每个分区,并将数据复制到目标。
该模板包含三个活动:
- 查找可从外部控制表检索确定的数据库分区列表。
- ForEach从查找活动获取分区列表,并将每个分区迭代到Copy activity。
- 复制可将每个分区从源数据库存储复制到目标存储。
模板定义以下参数:
- Control_Table_Name 是外部控制表,用于存储源数据库的分区列表。
- Control_Table_Schema_PartitionID 是外部控制表中用于存储每个分区 ID 的列名。 请确保源数据库中每个分区的分区 ID 都是唯一的。
- Control_Table_Schema_SourceTableName 是外部控制表,用于存储源数据库中的每个表名。
- Control_Table_Schema_FilterQuery 是外部控制表中的列名,用于存储筛选器查询,以从源数据库中的每个分区获取数据。 例如,如果按年份对数据进行分区,则存储在每一行中的查询可能类似于 select * from datasource where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999''。
- Data_Destination_Folder_Path 是将数据复制到目标存储中时使用的路径(当所选目标是“文件系统”时适用)。
- Data_Destination_Container 是将数据复制到目标存储时使用的根文件夹路径。
- Data_Destination_Directory 是将数据复制到目标存储中时使用的根下的目录路径。
仅当所选目标是基于文件的存储时,最后三个参数(定义目标存储中的路径)才可见。 如果选择“Azure Synapse Analytics”作为目标存储,则不需要这些参数。 但是,Azure Synapse Analytics中的表名称和架构必须与源数据库中的表名和架构相同。
如何使用此解决方案模板
在SQL Server或Azure SQL Database中创建控制表,以存储用于大容量复制的源数据库分区列表。 在以下示例中,源数据库有五个分区。 三个分区用于 datasource_table,两个分区用于 project_table。 列 LastModifytime 用于对源数据库中的数据表 datasource_table 中的数据进行分区。 用于读取第一个分区的查询为 'select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' 且 LastModifytime <= ''2015-12-31 23:59:59.999'''。 可以使用类似查询从其他分区读取数据。
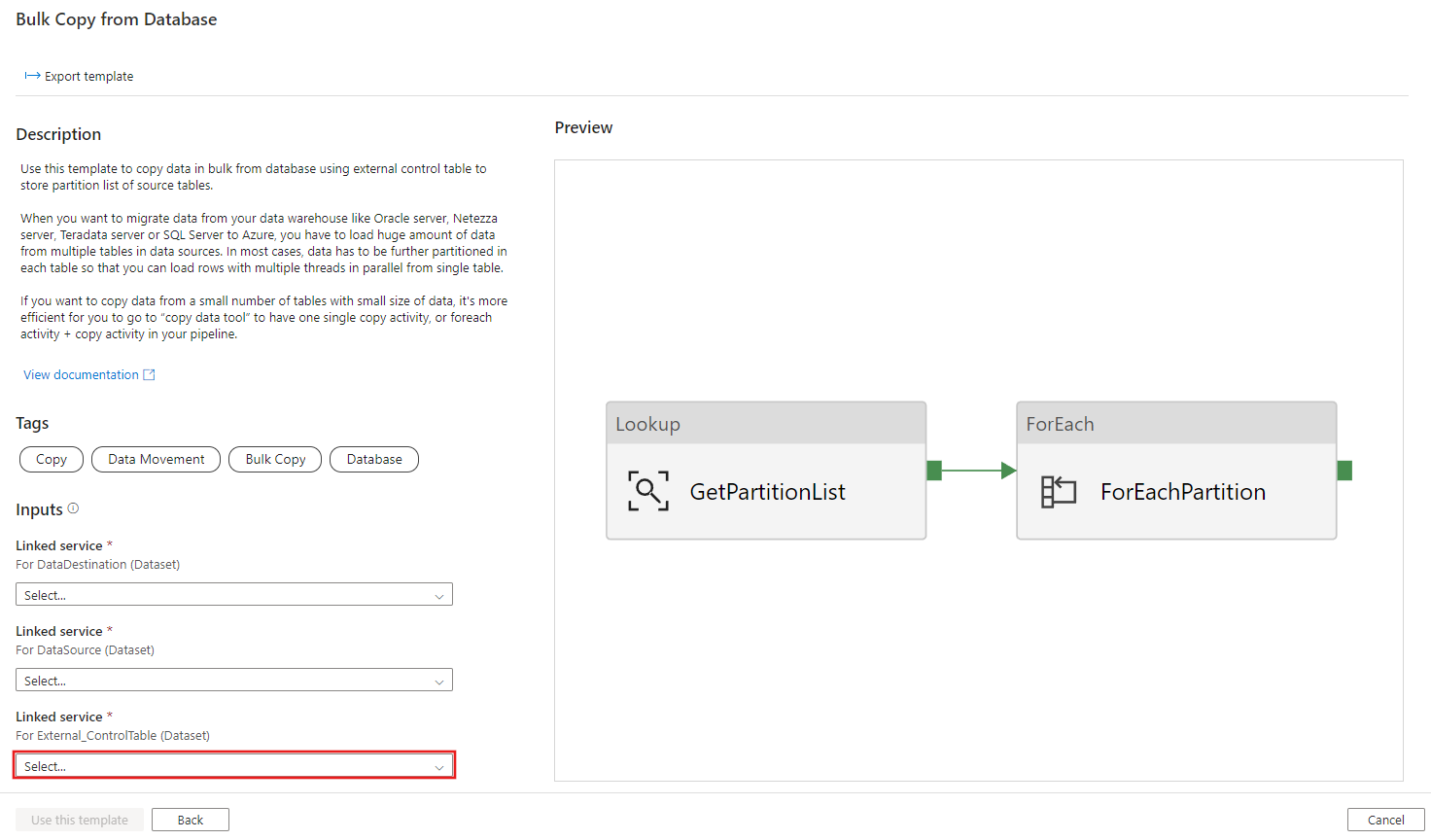
Create table ControlTableForTemplate ( PartitionID int, SourceTableName varchar(255), FilterQuery varchar(255) ); INSERT INTO ControlTableForTemplate (PartitionID, SourceTableName, FilterQuery) VALUES (1, 'datasource_table','select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''), (2, 'datasource_table','select * from datasource_table where LastModifytime >= ''2016-01-01 00:00:00'' and LastModifytime <= ''2016-12-31 23:59:59.999'''), (3, 'datasource_table','select * from datasource_table where LastModifytime >= ''2017-01-01 00:00:00'' and LastModifytime <= ''2017-12-31 23:59:59.999'''), (4, 'project_table','select * from project_table where ID >= 0 and ID < 1000'), (5, 'project_table','select * from project_table where ID >= 1000 and ID < 2000');转到“从数据库进行大容量复制”模板。 创建一个与您在步骤 1 中创建的外部控制表的新的连接。
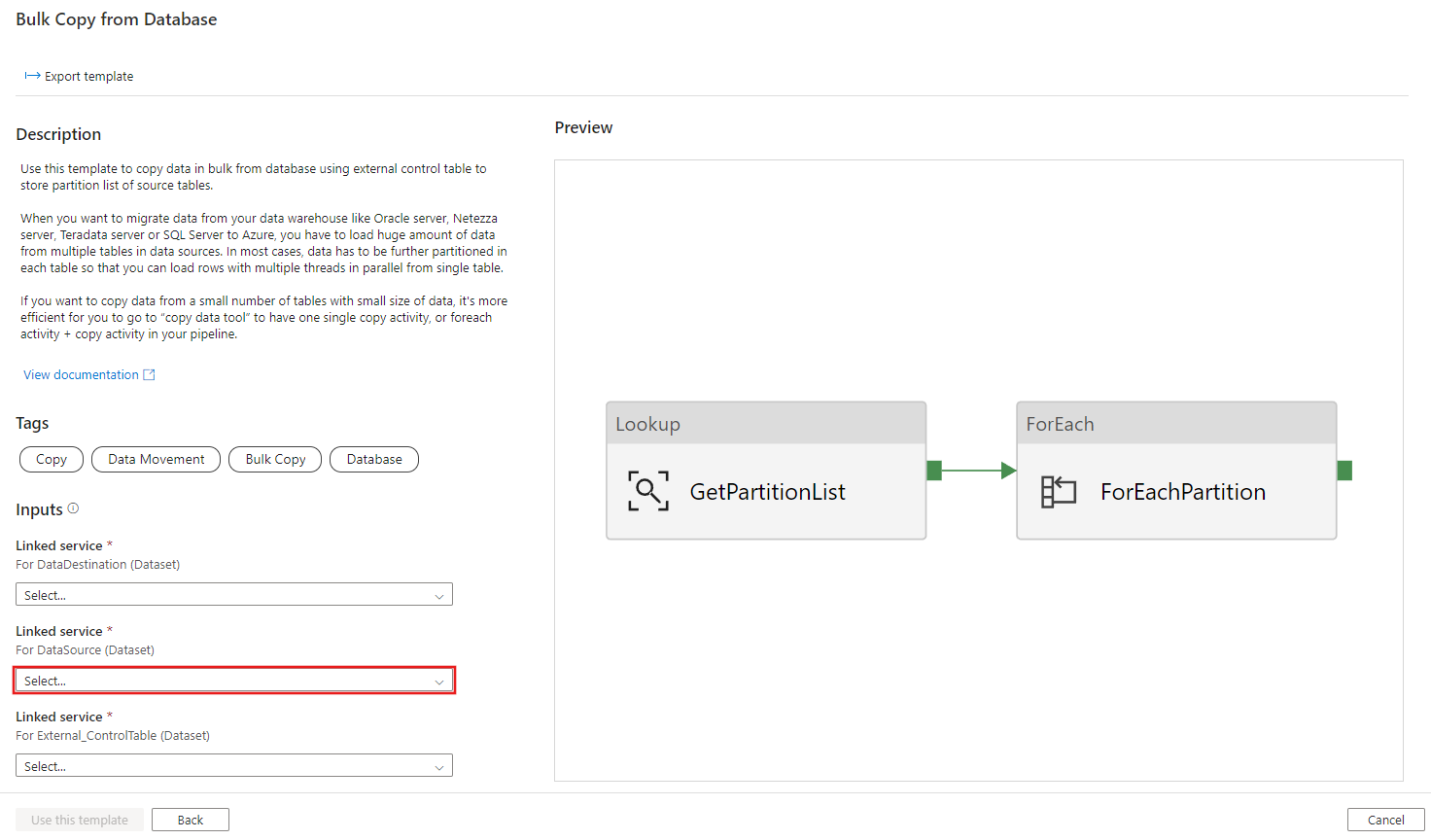
创建与要从中复制数据的源数据库的新连接。
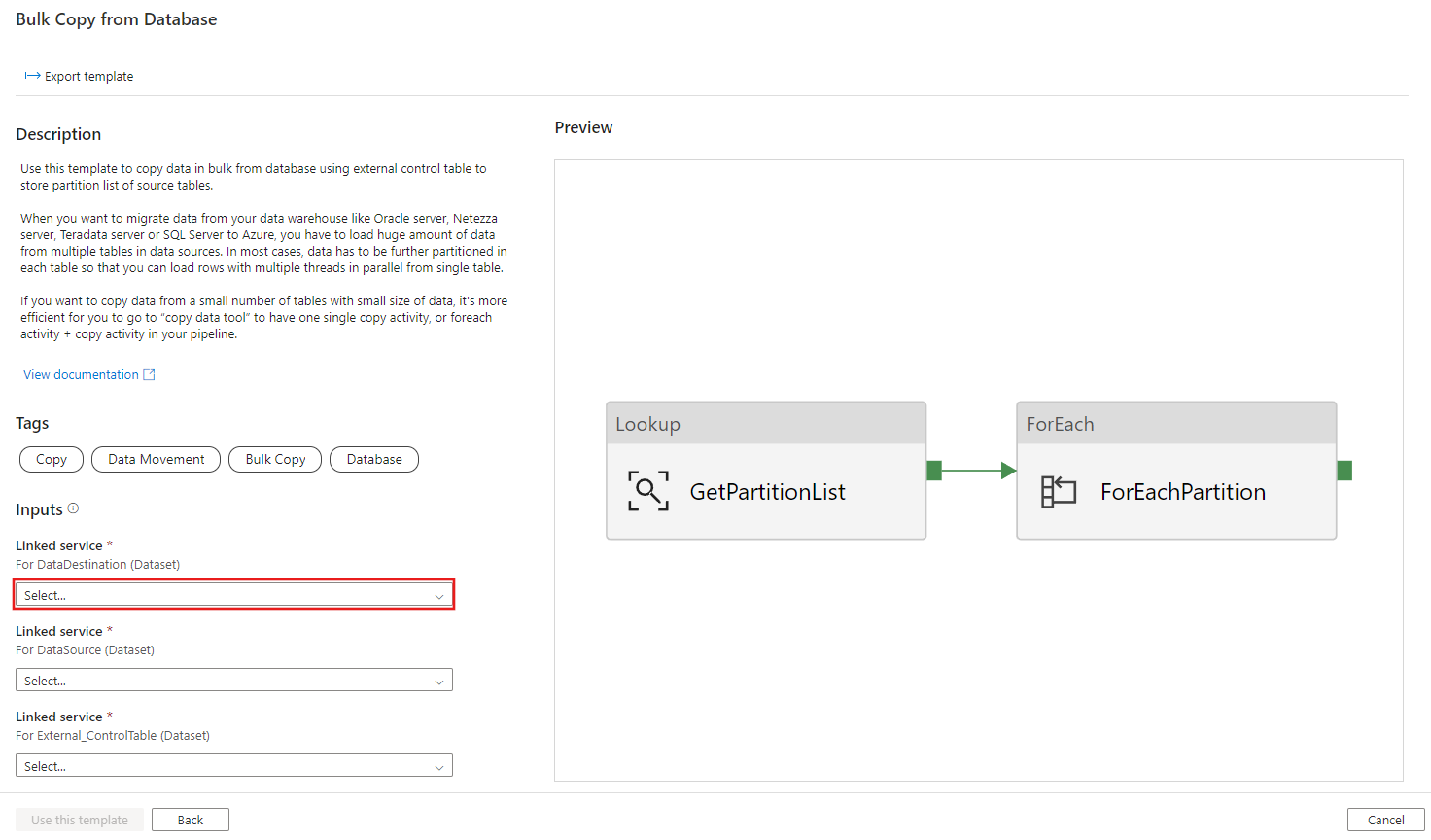
创建与要将数据复制到其中的目标数据存储的新连接。
选择“使用此模板” 。
可以看到管道,如以下示例所示:
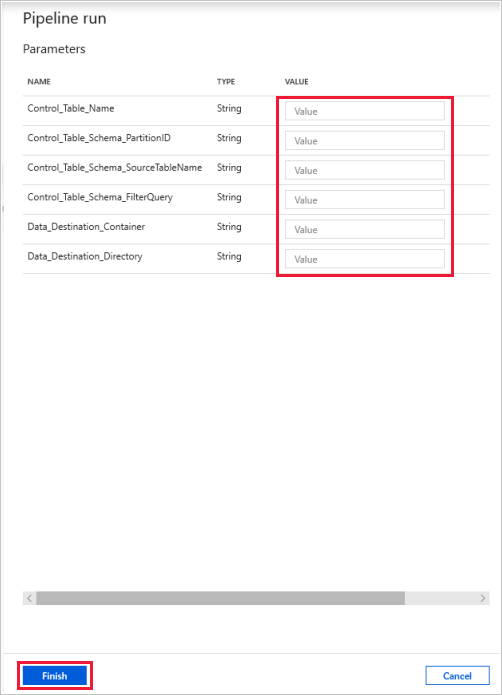
选择“调试”,输入参数,然后选择“完成”。
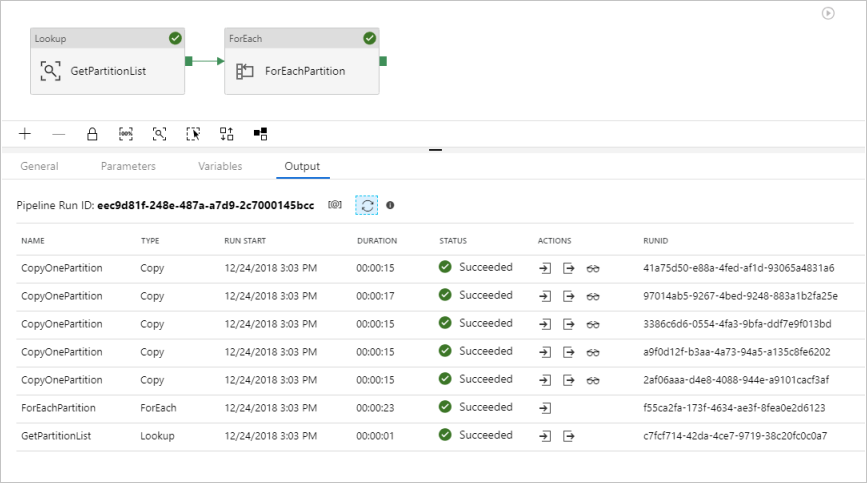
看到的结果类似于以下示例:
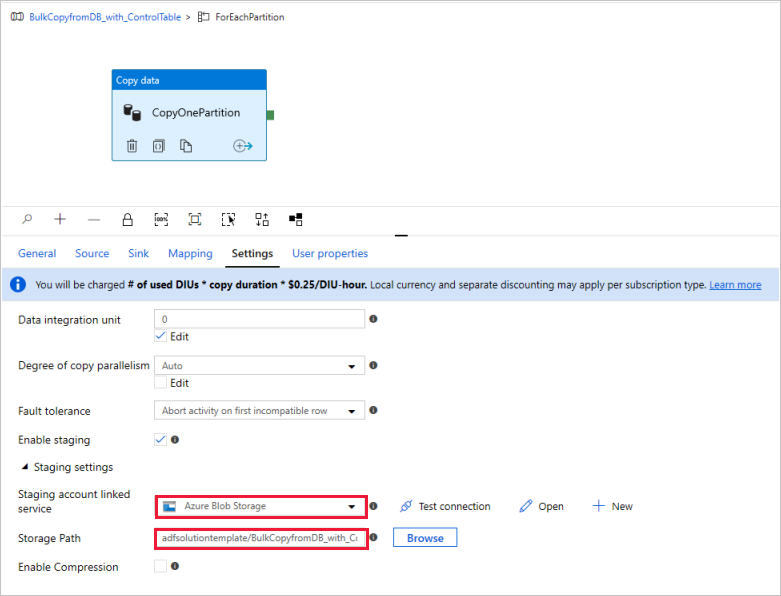
(可选)如果将“Azure Synapse Analytics”设为数据目标,则必须根据 Azure Synapse Analytics Polybase 的规定,输入与 Azure Blob 存储的连接以进行数据暂存。 模板会自动为 Blob 存储生成容器路径。 检查是否在管道运行后创建了容器。