适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
“复制数据”工具可简化并优化将数据引入 Data Lake 的过程,这通常是端到端数据集成方案的第一步。 这可节省时间,尤其是首次使用服务引入数据源中的数据时。 下面是使用此工具的一些优势:
- 使用“复制数据”工具时,无需了解链接的数据、数据集、管道、活动和触发器的服务定义。
- 对于将数据加载到 Data Lake 中,“复制数据”工具的流程非常直观。 该工具会自动创建将数据从所选源数据存储复制到所选目标/接收器数据存储所需的所有资源。
- “复制数据”工具有助于在创作时验证正在引入的数据,从而在开始时避免出现任何潜在错误。
- 如果需要实现复杂的业务逻辑,以便将数据加载到 Data Lake 中,仍可使用 UI 中的“每活动创作”来编辑“复制数据”工具创建的数据工厂资源。
下表提供了有关在何时使用 UI 中的“复制数据”工具与“每活动创作”的指南:
| 复制数据工具 | 每活动(复制活动)创作 |
|---|---|
| 需要轻松构建数据加载任务,而无需了解实体(链接的服务、数据集和管道等) | 需要实现复杂而灵活的逻辑,将数据加载到 Lake 中。 |
| 需要将大量数据项目快速加载到 Data Lake 中。 | 需要将复制活动与后续活动链接在一起,以清理或处理数据。 |
要启动“复制数据”工具,请单击数据工厂或 Synapse Studio UI 的主页上的“引入”磁贴。
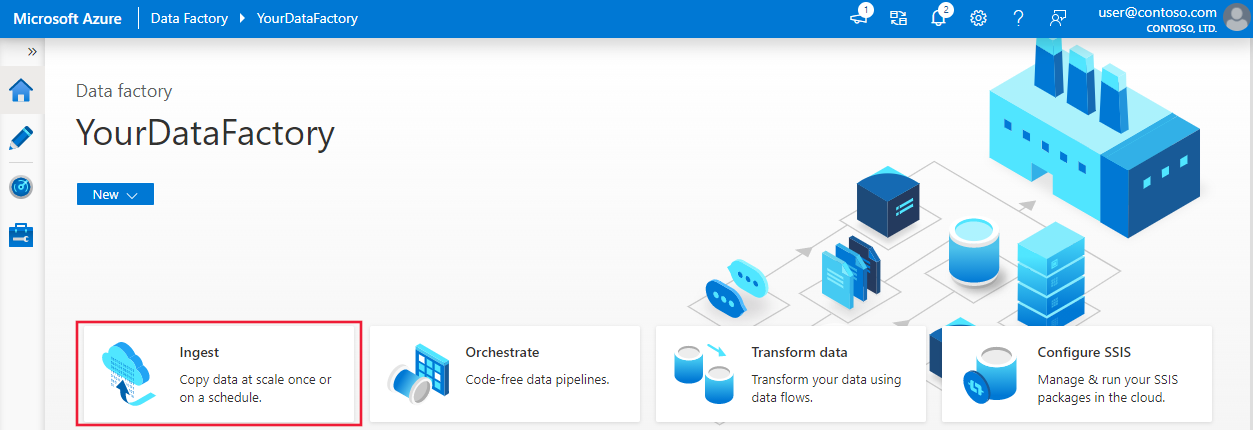
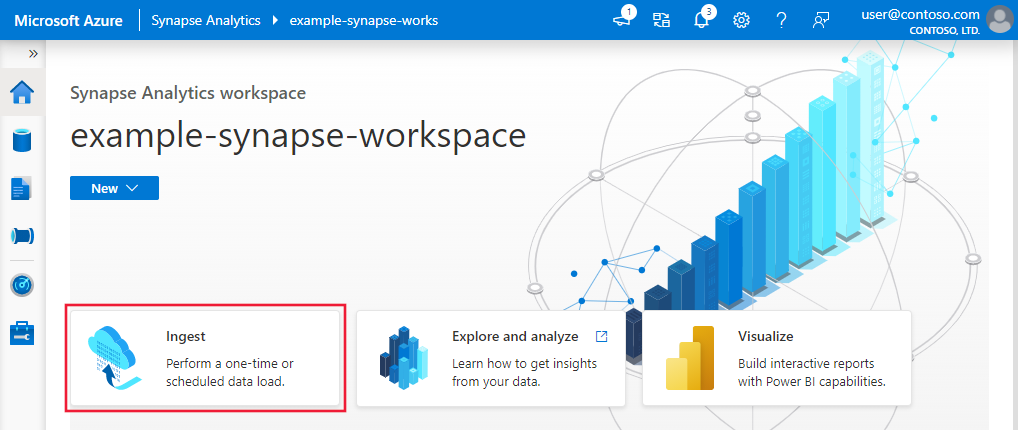
在启动“复制数据”工具后,将出现两种类型的任务:一种是内置复制任务,另一种是元数据驱动的复制任务 。 内置复制任务会引导你在 5 分钟内创建管道来复制数据,无需了解实体。 元数据驱动的复制任务会简化创建参数化管道和外部控制表的历程,以便设法大规模复制大量对象(例如成千上万个表)。 在元数据驱动的复制数据中可以看到更多详细信息。
将数据加载到 Data Lake 中的直观流程
使用此工具,可通过一个直观的流程在数分钟内轻松地将数据从各种源移动到目标:
配置“源”的设置。
配置“目标”的设置。
配置复制操作的高级设置,如列映射、性能设置和容错设置。
指定数据加载任务的“计划”。
查看要创建的实体的摘要。
编辑管道,根据需要更新复制活动的设置。
该工具从设计之初就考虑到了大数据,支持多种数据和对象类型。 可利用该工具移动数百个文件夹、文件或表。 该工具支持自动数据预览、构架捕获和自动映射,以及筛选数据。
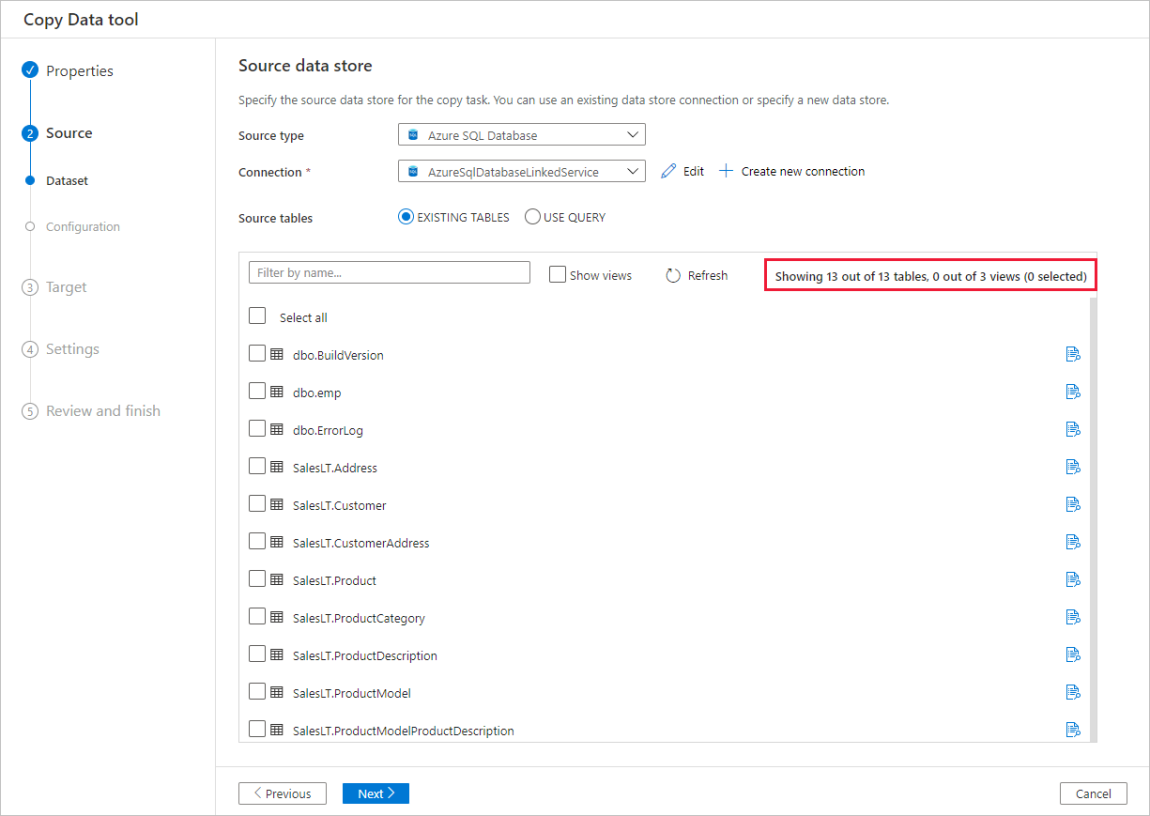
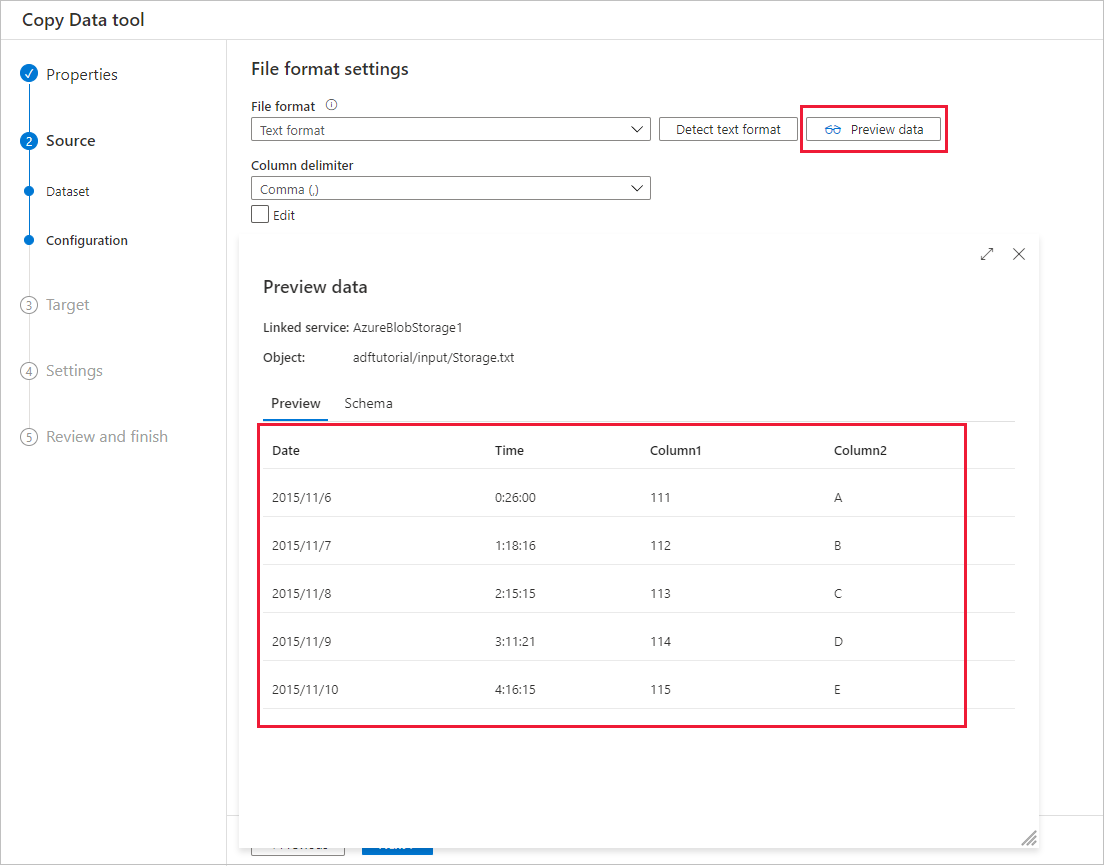
自动数据预览
可从选定的源数据存储预览部分数据,这样便可验证正在复制的数据。 此外,如果源数据在文本文件中,“复制数据”工具会分析文本文件,以自动检测行和列分隔符以及架构。
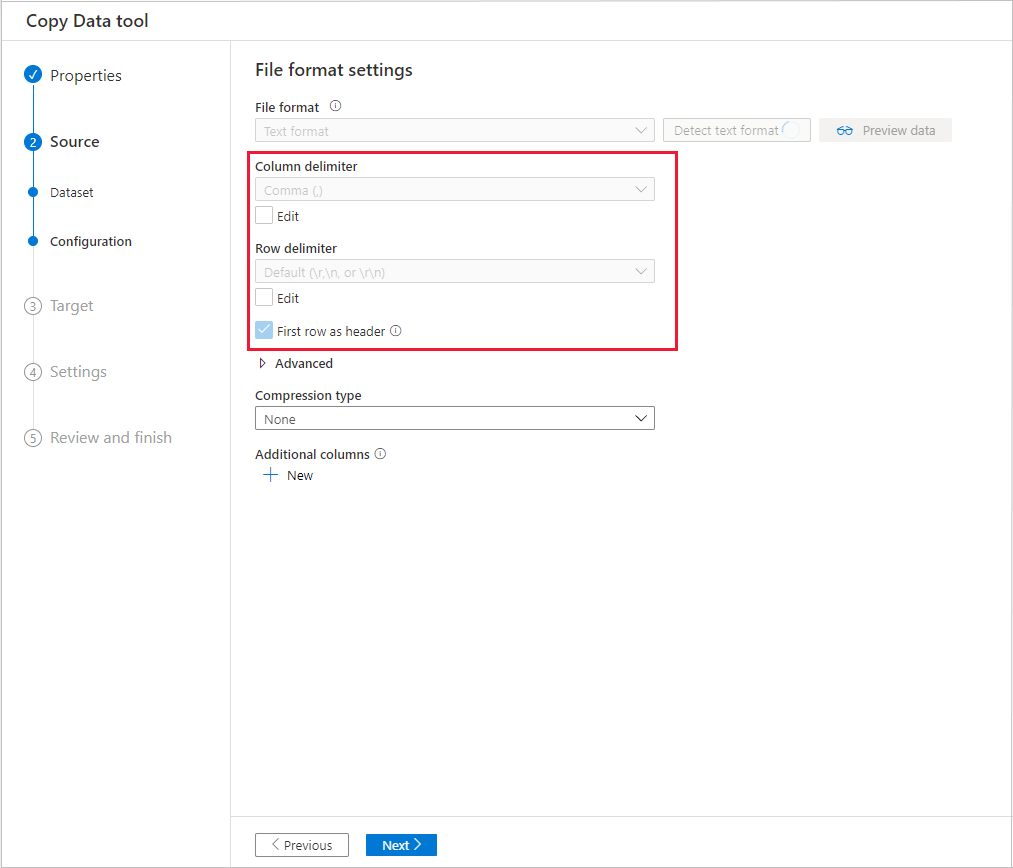
检测后,选择“预览数据”:
架构捕获和自动映射
在很多情况下,数据源的架构可能与数据目标的架构不同。 在这种情况下,需要将源架构中的列映射到目标架构中的列。
“复制数据”工具可监视并学习用户在源和目标存储之间映射列时的行为。 从源数据存储中选择一个或几个列并将其映射到目标架构之后,“复制数据”工具开始分析从两侧选取的列对的模式。 然后,它将相同的模式应用到其余的列。 因此,只需单击几次,即可看到所有列已经按所需方式映射到目标。 如果对“复制数据”工具提供的列映射选项不满意,可以忽略该选项并继续手动映射列。 同时,“复制数据”工具不断学习和更新相关模式,最终达到所需的正确列映射模式。
注意
将数据从 SQL Server 或 Azure SQL 数据库复制到 Azure Synapse Analytics 时,如果目标存储中不存在表,“复制数据”工具支持使用源架构自动创建表。
筛选数据
可筛选源数据,仅选择需要复制到接收器数据存储的数据。 筛选能够减少复制到接收器数据存储的数据量,从而增强复制操作的吞吐量。 使用“复制数据”工具,可使用 SQL 查询语言灵活筛选关系数据库中的数据,也可灵活筛选 Azure Blob 文件夹中的文件。
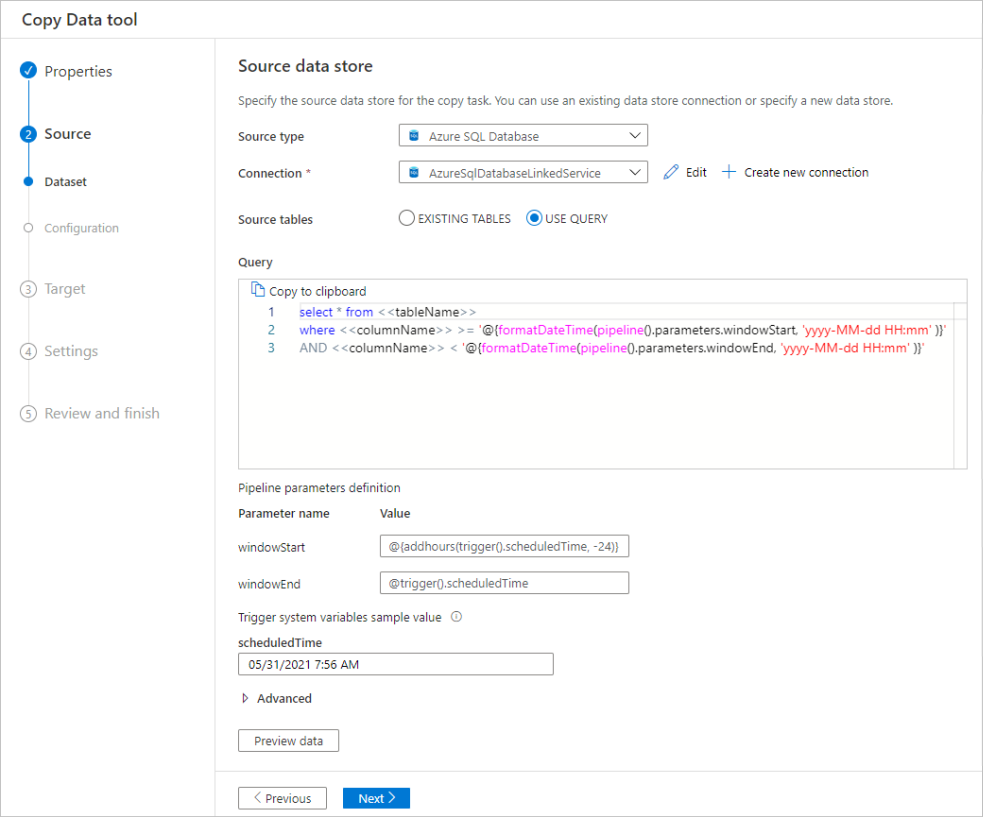
筛选数据库中的数据
以下屏幕截图显示用于筛选数据的 SQL 查询。
筛选 Azure Blob 文件夹中的数据
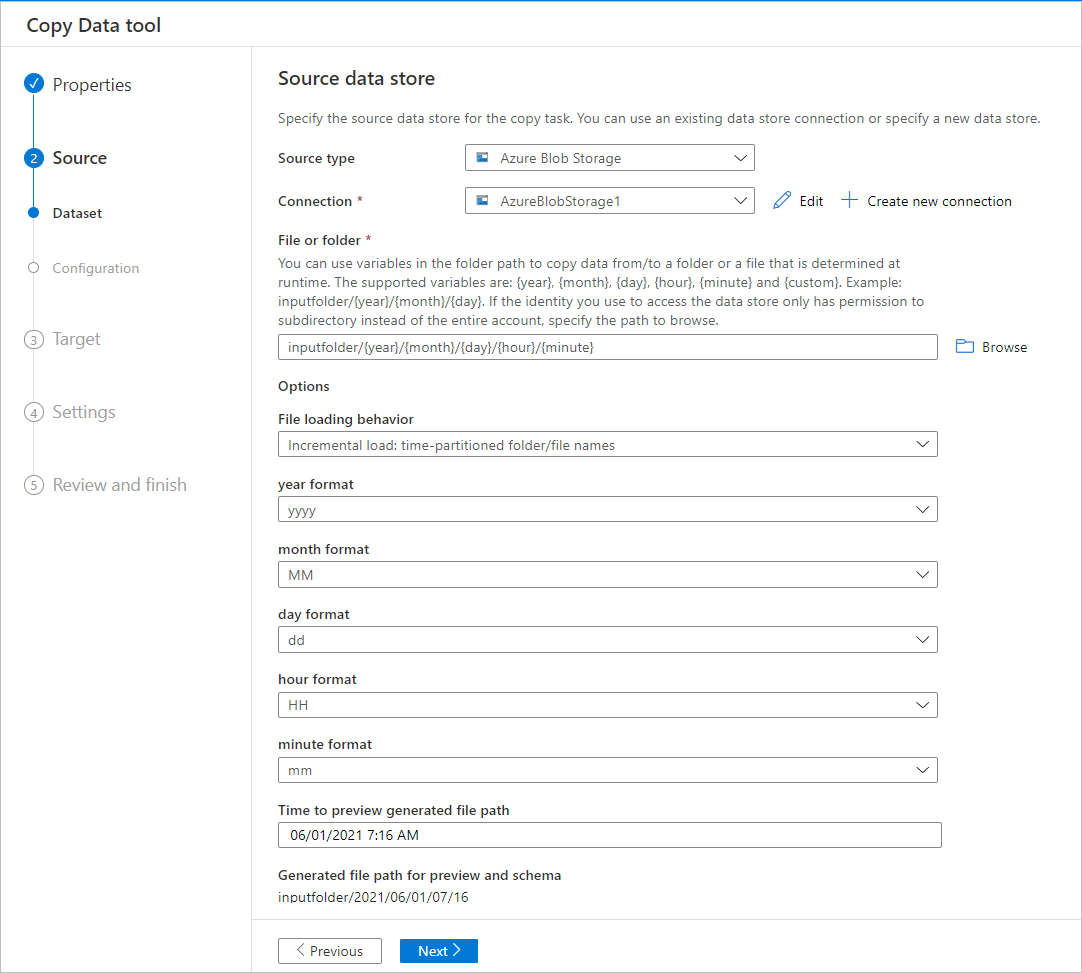
可在文件夹路径中使用变量来复制文件夹中的数据。 支持的变量包括:{year}、{month}、{day}、{hour} 和 {minute} 。 例如:inputfolder/{year}/{month}/{day}。
假设输入文件夹格式如下:
2016/03/01/01
2016/03/01/02
2016/03/01/03
...
单击“文件或文件夹”的“浏览”按钮,浏览到其中一个文件夹(例如,2016->03->01->02),并单击“选择”。 文本框中应该会显示 2016/03/01/02。
然后,请用 {year} 代替 2016、{month} 代替 03、{day} 代替 01、{hour} 代替 02,并按 Tab 键 。 在“文件加载行为”部分选择“增量加载: 按时间分区的文件夹名称/文件名”并在“属性”页上选择“计划”或“翻转窗口”时,你应该看到用于选择这四个变量的格式的下拉列表:
创建管道时,“复制数据”工具生成包含表达式、函数和系统变量的参数,用于表示 {year}、{month}、{day}、{hour} 和 {minute}。
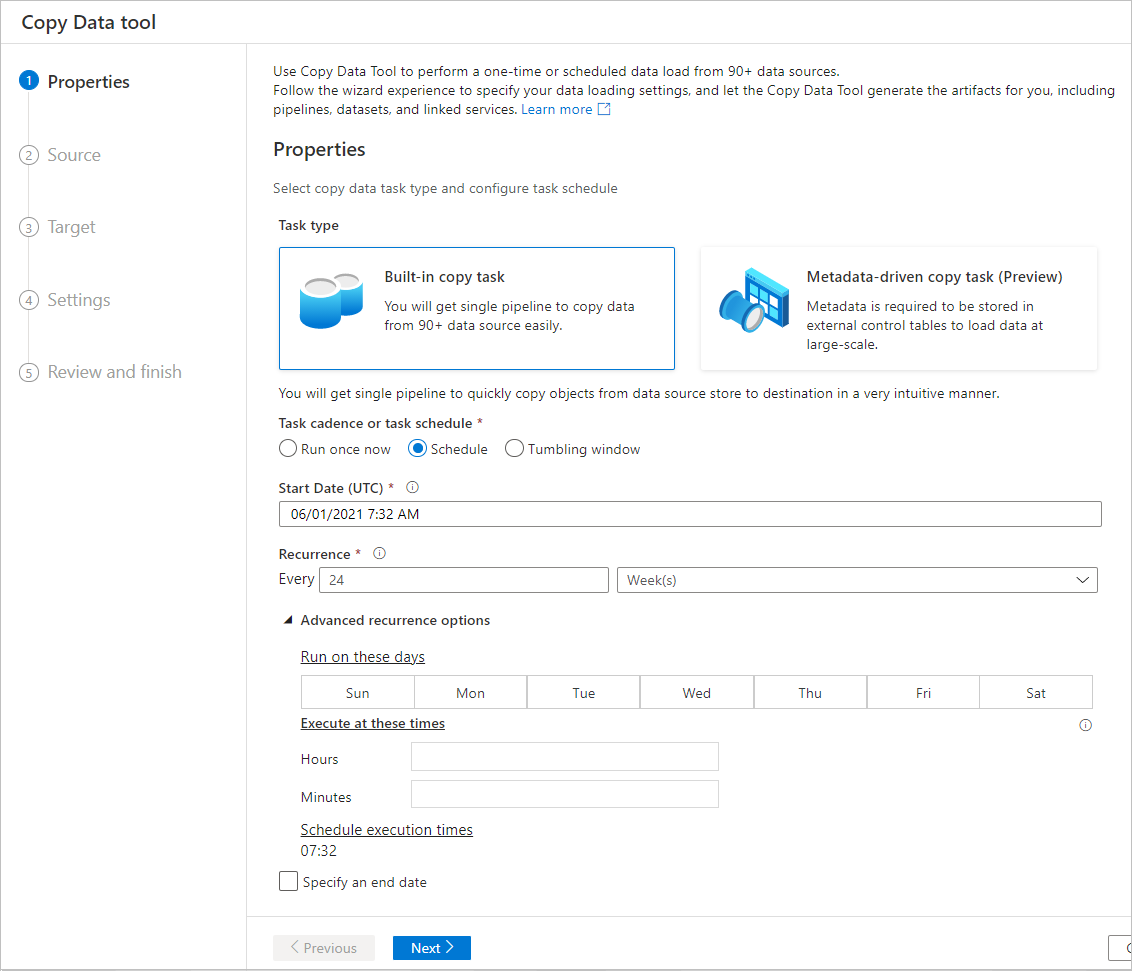
计划选项
可以一次性运行复制操作,也可按计划运行(每小时、每天等)。 这些选项可用于跨不同环境(包括本地、云和本地桌面)的连接器。
一次性复制操作仅支持一次性将数据从源移动到目标。 它适用于任何大小的数据和任何受支持的格式。 使用计划的复制,可按指定的重复周期复制数据。 可使用丰富的设置(例如,重试、超时和警报)来配置计划的复制。
相关内容
请尝试以下使用“复制数据”工具的教程: