适用于: Azure 数据工厂
Azure 数据工厂  Azure Synapse Analytics
Azure Synapse Analytics
本教程使用 Azure 门户创建 Azure 数据工厂管道。 该管道使用 Spark 活动和按需 Azure HDInsight 链接服务转换数据。
在本教程中执行以下步骤:
- 创建数据工厂。
- 创建使用 Spark 活动的管道。
- 触发管道运行。
- 监视管道运行。
如果没有 Azure 订阅,可在开始前创建一个试用帐户。
先决条件
注意
建议使用 Azure Az PowerShell 模块与 Azure 交互。 请参阅安装 Azure PowerShell 以开始使用。 若要了解如何迁移到 Az PowerShell 模块,请参阅 将 Azure PowerShell 从 AzureRM 迁移到 Az。
- Azure 存储帐户。 创建 Python 脚本和输入文件,并将其上传到 Azure 存储。 Spark 程序的输出存储在此存储帐户中。 按需 Spark 群集使用相同的存储帐户作为其主存储。
注意
HdInsight 仅支持标准层的常规用途存储帐户。 请确保该帐户不是高级或仅 blob 存储帐户。
- Azure PowerShell。 遵循如何安装和配置 Azure PowerShell 中的说明。
将 Python 脚本上传到 Blob 存储帐户
创建包含以下内容的名为 WordCount_Spark.py 的 Python 文件:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.chinacloudapi.cn/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.chinacloudapi.cn/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()将 <storageAccountName> 替换为 Azure 存储帐户的名称。 然后保存文件。
在 Azure Blob 存储中,创建名为 adftutorial 的容器(如果尚不存在)。
创建名为 spark 的文件夹。
在 spark 文件夹中创建名为 script 的子文件夹。
将 WordCount_Spark.py 文件上传到 script 子文件夹。
上传输入文件
- 创建包含一些文本的名为 minecraftstory.txt 的文件。 Spark 程序会统计此文本中的单词数量。
- 在 spark 文件夹中创建名为 inputfiles 的子文件夹。
- 将 minecraftstory.txt 文件上传到 inputfiles 子文件夹。
创建数据工厂
如果你还没有数据工厂可供使用,请按照快速入门:使用 Azure 门户创建数据工厂一文中的步骤创建数据工厂。
创建链接服务
在本部分创作两个链接服务:
- 一个用于将 Azure 存储帐户链接到数据工厂的 Azure 存储链接服务。 按需 HDInsight 群集使用此存储。 此存储还包含要运行的 Spark 脚本。
- 一个按需 HDInsight 链接服务。 Azure 数据工厂自动创建 HDInsight 群集并运行 Spark 程序。 然后,当群集空闲预配置的时间后,就会删除 HDInsight 群集。
创建 Azure 存储链接服务
在主页上,切换到左侧面板中的“管理”选项卡。
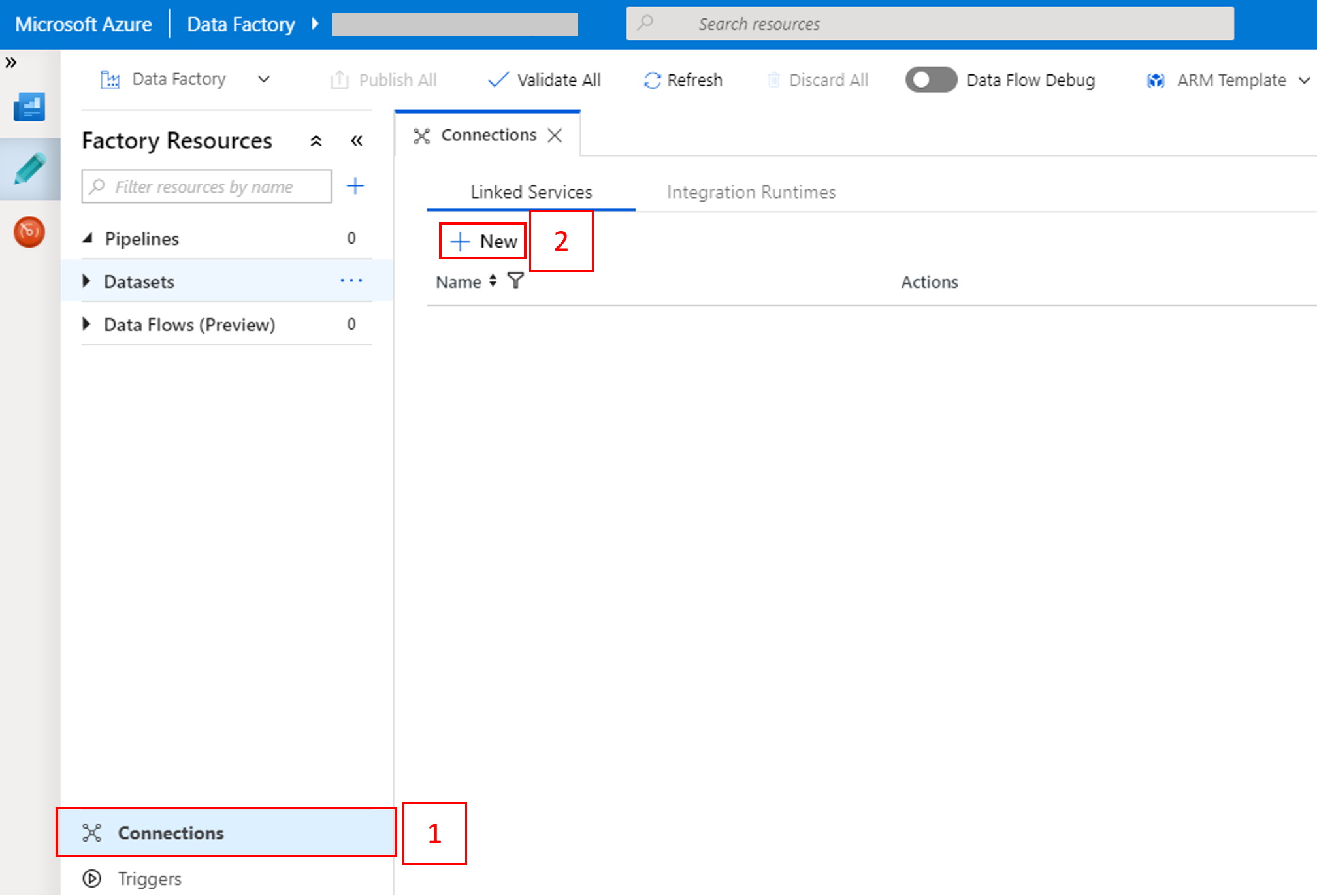
选择窗口底部的“连接”,然后选择“+ 新建”。
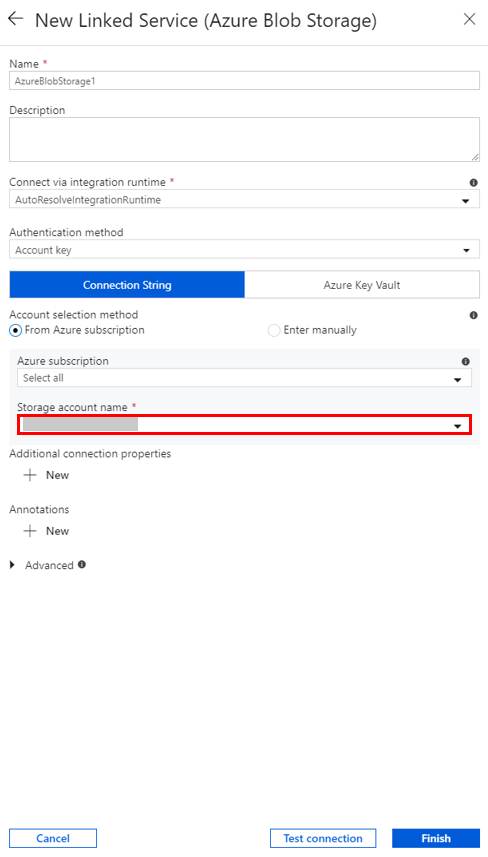
在“新建链接服务”窗口中,选择“数据存储”>“Azure Blob 存储”,然后选择“继续”。

至于“存储帐户名称”,请从列表中选择名称,然后选择“保存”。
创建按需 HDInsight 链接服务
再次选择“+ 新建”按钮,创建另一个链接服务。
在“新建链接服务”窗口中,选择“计算”>“Azure HDInsight”,然后选择“继续”。

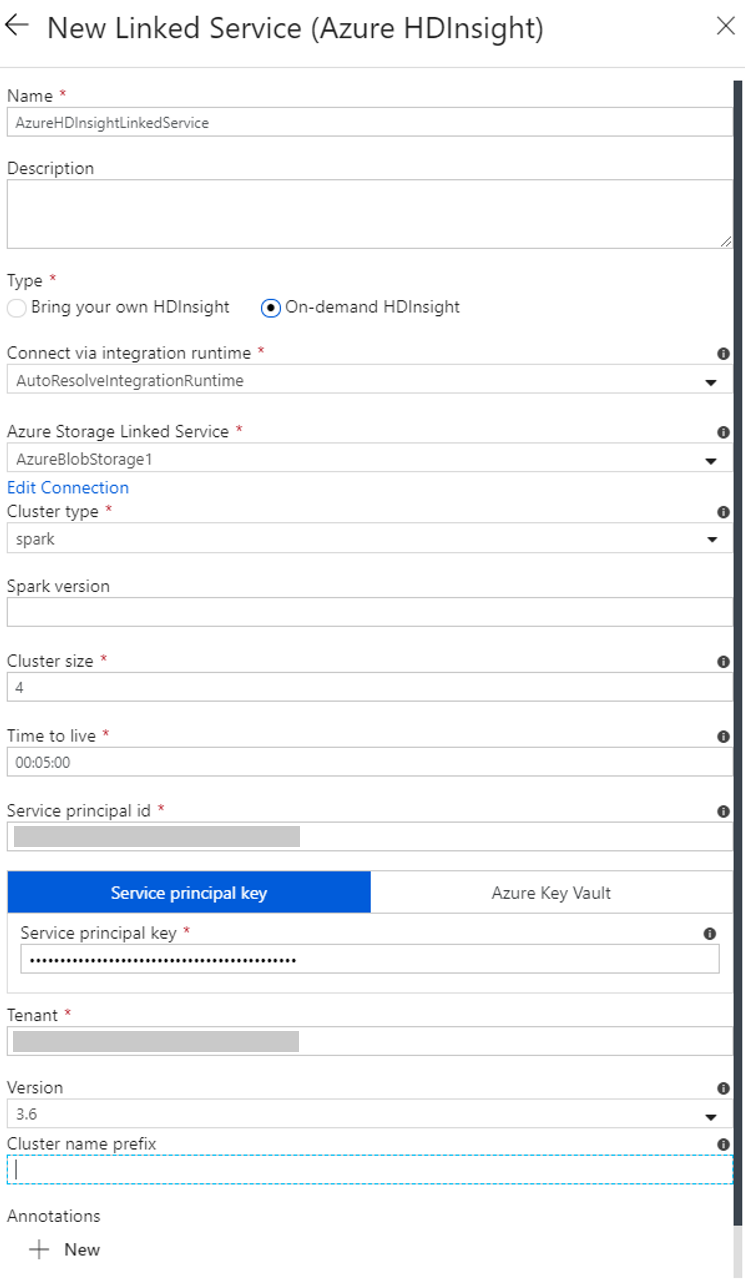
在“新建链接服务” 窗口中完成以下步骤:
a. 至于“名称”,请输入 AzureHDInsightLinkedService。
b. 至于“类型”,请确认选择了“按需 HDInsight”。
c. 对于“Azure 存储链接服务”,请选择“AzureBlobStorage1”。 前面已创建此链接服务。 如果使用了其他名称,请在此处指定正确的名称。
d. 至于“群集类型”,请选择“spark”。
e. 至于“服务主体 ID”,请输入有权创建 HDInsight 群集的服务主题的 ID。
此服务主体需是订阅“参与者”角色的成员,或创建群集的资源组的成员。 有关详细信息,请参阅创建 Microsoft Entra 应用程序和服务主体。 服务主体 ID 等效于应用程序 ID,服务主体密钥等效于客户端密码的值。
f. 至于“服务主体密钥”,请输入此密钥。
g. 至于“资源组”,请选择创建数据工厂时使用的资源组。 将在此资源组中创建 Spark 群集。
h. 展开“OS 类型”。
i. 输入名称作为群集用户名。
j. 输入该用户的群集密码。
k. 选择“完成”。
注意
Azure HDInsight 限制可在其支持的每个 Azure 区域中使用的核心总数。 对于按需 HDInsight 链接服务,将在用作其主存储的同一 Azure 存储位置创建 HDInsight 群集。 请确保有足够的核心配额,以便能够成功创建群集。 有关详细信息,请参阅使用 Hadoop、Spark、Kafka 等在 HDInsight 中设置群集。
创建管道
选择“+ (加)”按钮,然后在菜单上选择“管道”。
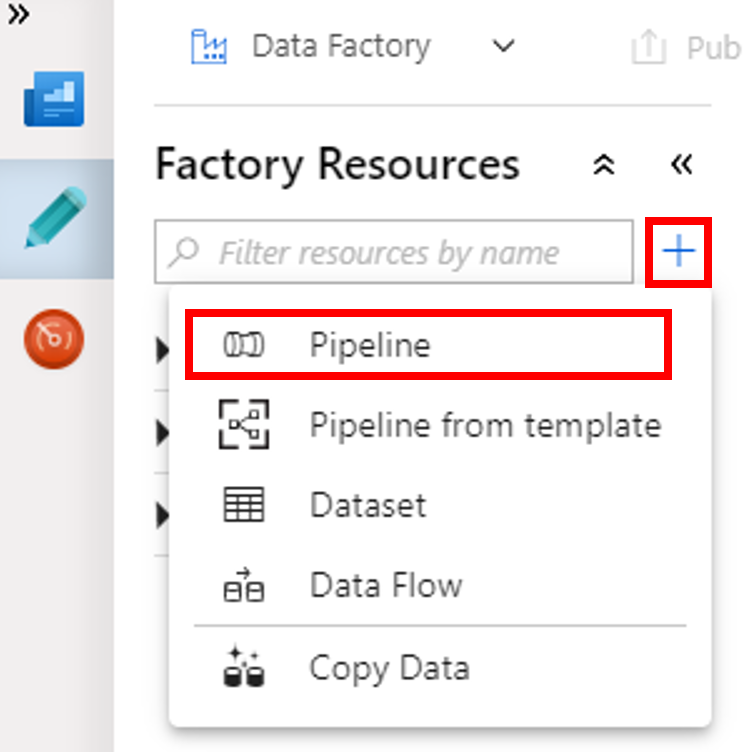
在“活动”工具箱中,展开“HDInsight”。 将“Spark”活动从“活动”工具箱拖到管道设计器图面。
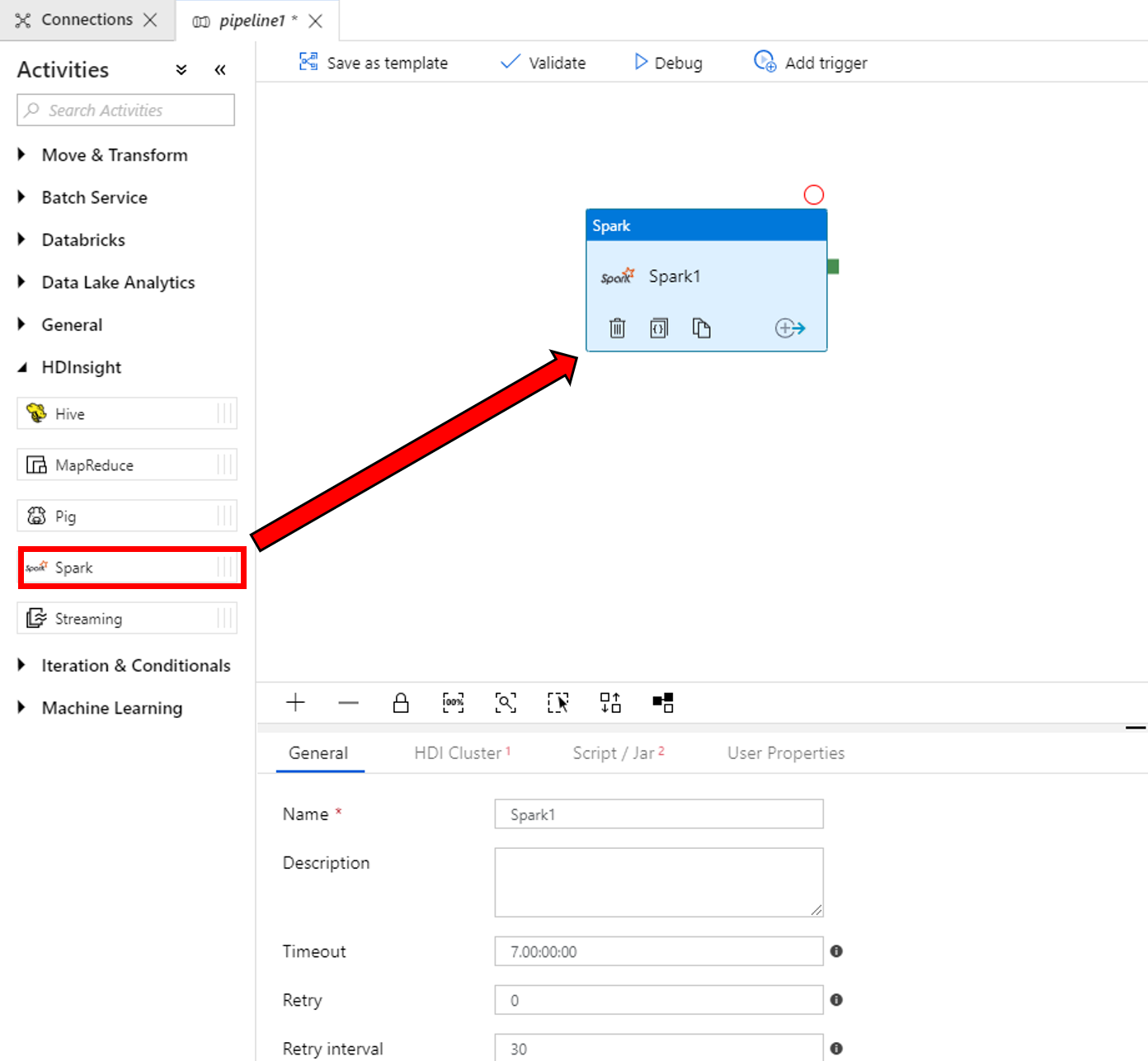
在底部“Spark”活动窗口的属性中完成以下步骤:
a. 切换到“HDI 群集”选项卡。
b. 选择 AzureHDInsightLinkedService(在上一过程中创建)。
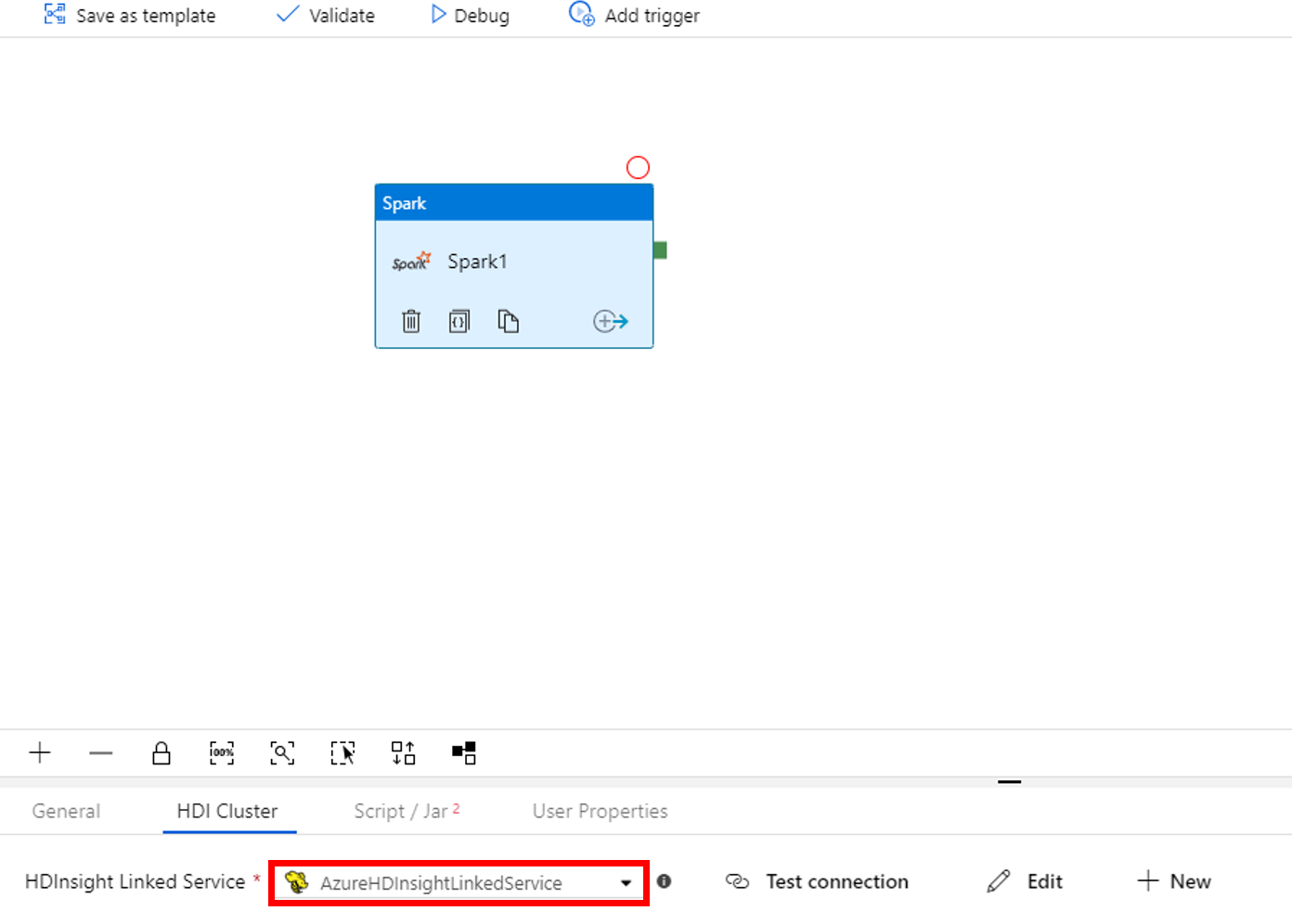
切换到“脚本/Jar”选项卡,然后完成以下步骤:
a. 对于“作业链接服务”,请选择“AzureBlobStorage1”。
b. 选择“浏览存储”。

c. 浏览到“adftutorial/spark/script”文件夹,选择“WordCount_Spark.py”,然后选择“完成”。
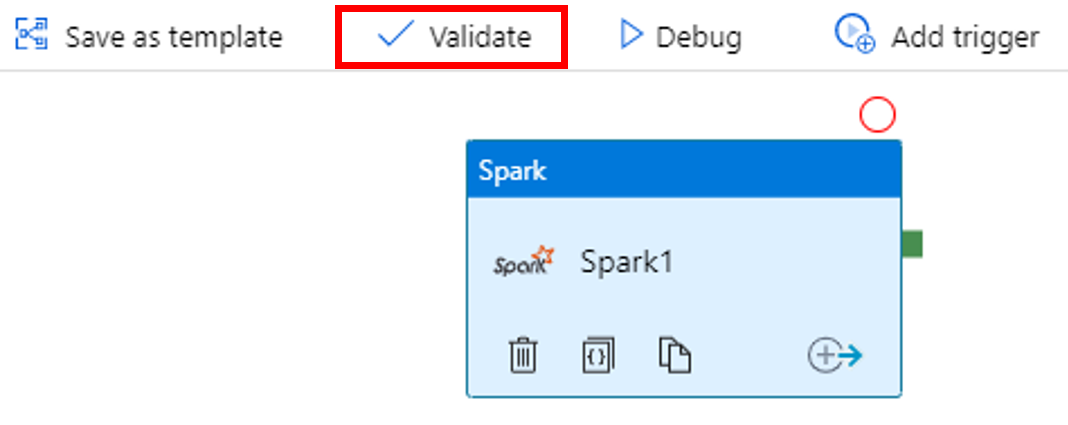
若要验证管道,请选择工具栏中的“验证”按钮。 选择 >> (右键头)按钮,关闭验证窗口。
选择“全部发布”。 数据工厂 UI 会将实体(链接服务和管道)发布到 Azure 数据工厂服务。
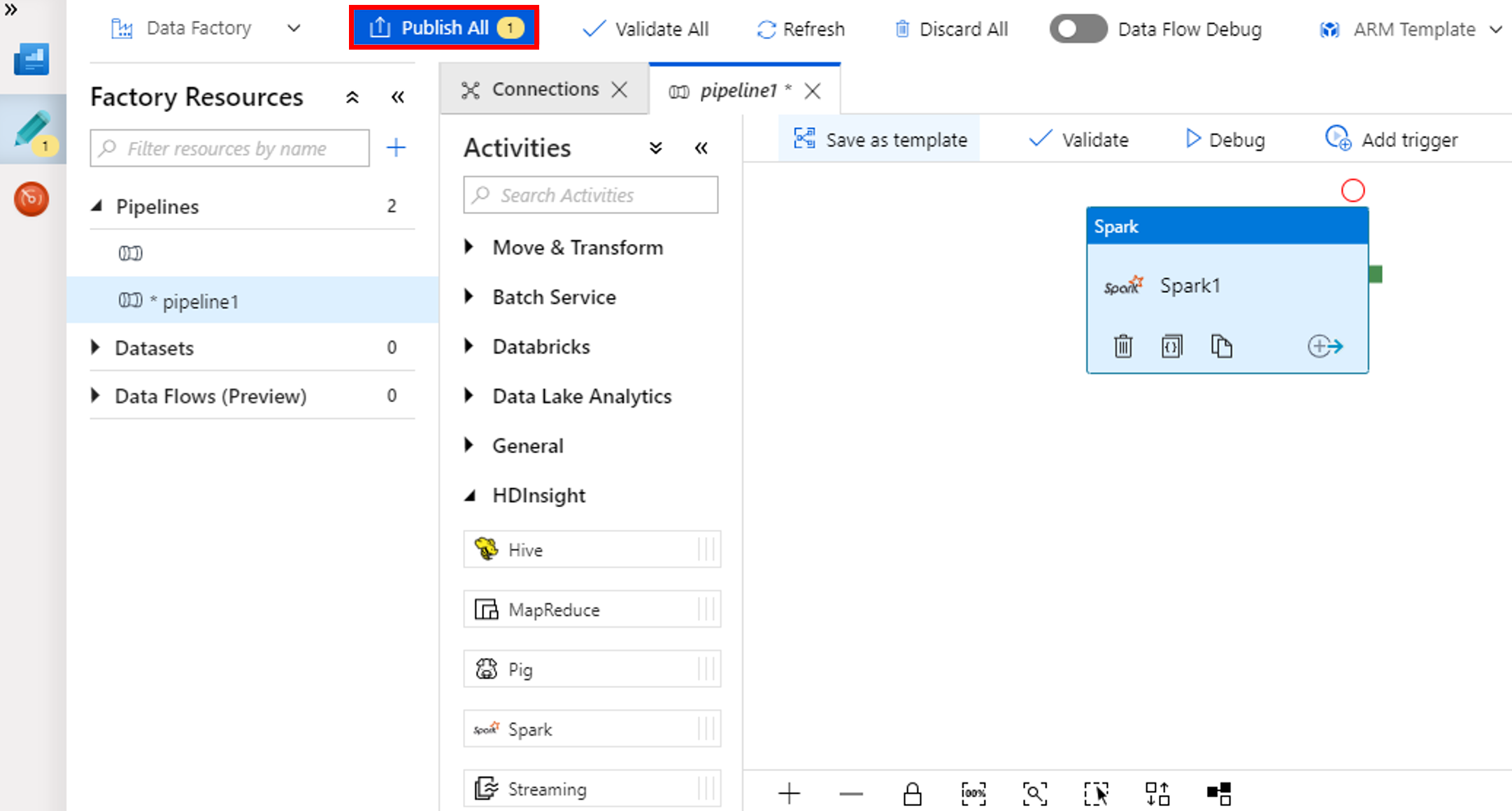
触发管道运行
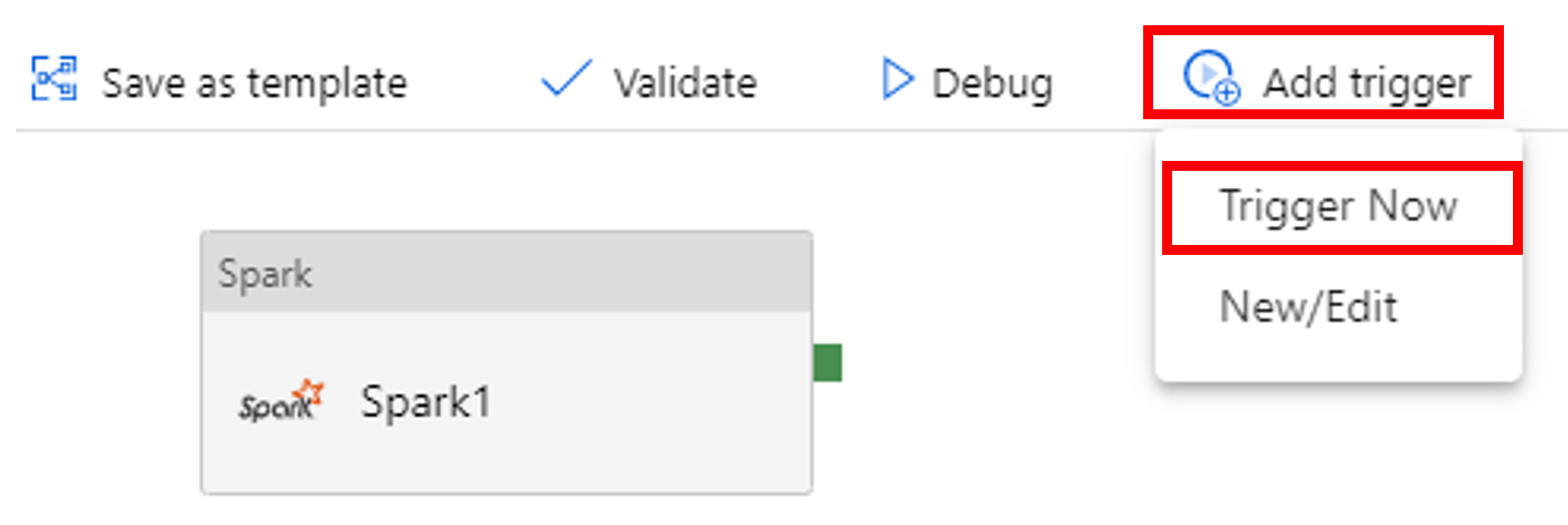
选择工具栏中的“添加触发器”,然后选择“立即触发”。
监视管道运行
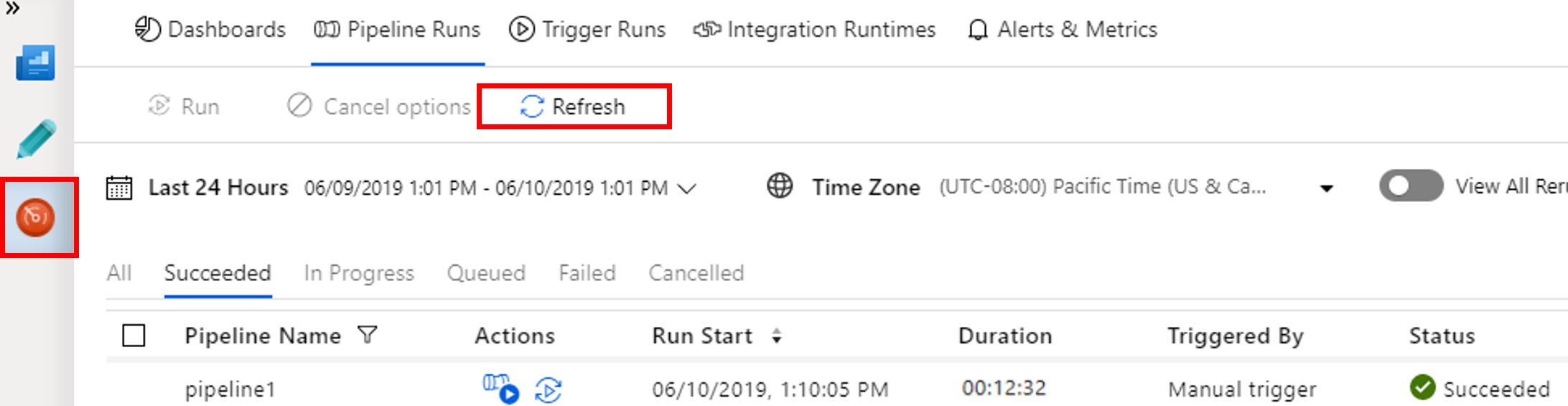
切换到“监视”选项卡。 确认可以看到一个管道运行。 创建 Spark 群集大约需要 20 分钟。
定期选择“刷新”以检查管道运行的状态。
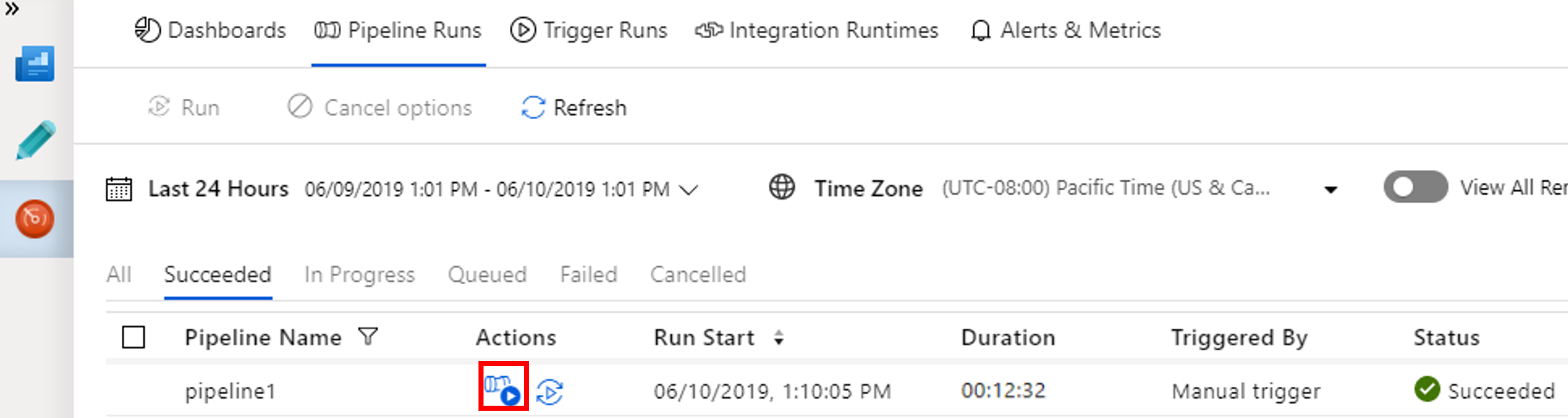
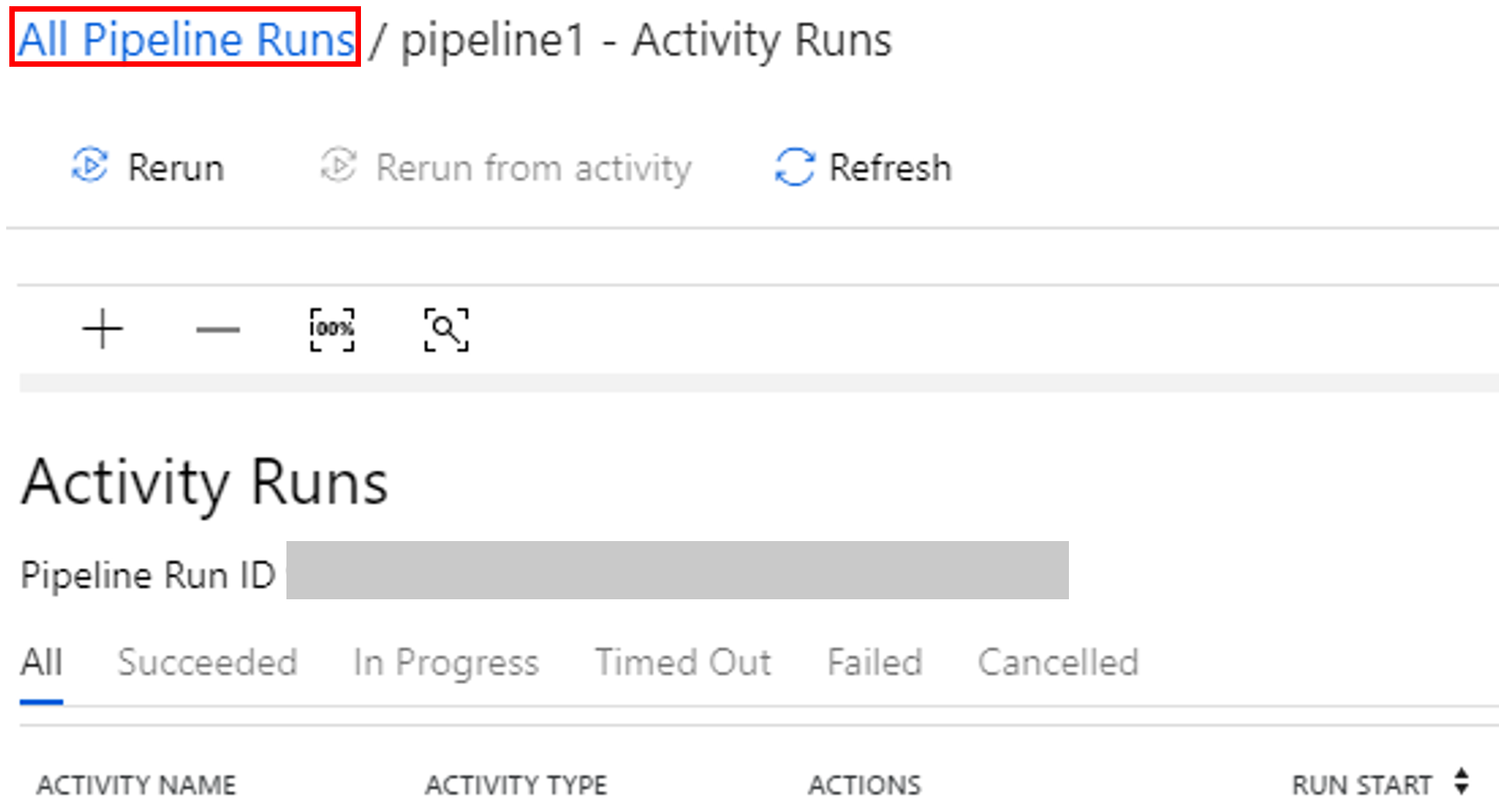
若要查看与管道运行相关联的活动运行,请选择“操作”列中的“查看活动运行”。
选择顶部的“所有管道运行”链接可以切换回到管道运行视图。
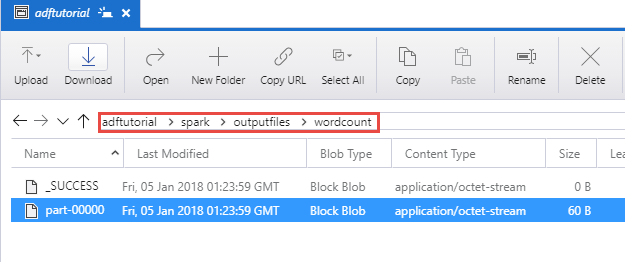
验证输出
验证 adftutorial 容器的 spark/otuputfiles/wordcount 文件夹中是否创建了一个输出文件。
该文件应包含输入文本文件中的每个单词,以及该单词在该文件中出现的次数。 例如:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
相关内容
此示例中的管道使用 Spark 活动和按需 HDInsight 链接服务转换数据。 你已了解如何执行以下操作:
- 创建数据工厂。
- 创建使用 Spark 活动的管道。
- 触发管道运行。
- 监视管道运行。
若要了解如何通过在虚拟网络的 Azure HDInsight 群集上运行 Hive 脚本来转换数据,请转到下一教程: