本文提供了 Lakehouse 的体系结构指南,涵盖数据源、引入、转换、查询和处理、服务、分析和存储。
每个参考体系结构都有一个 11 x 17 (A3) 格式的可下载 PDF。
虽然 Databricks 上的湖屋是一个与大型合作伙伴工具生态系统集成的开放平台,但参考体系结构仅关注 Azure 服务和 Databricks 湖屋。 显示的云提供商服务是为说明这些概念而选取的,并不完全涵盖所有服务。
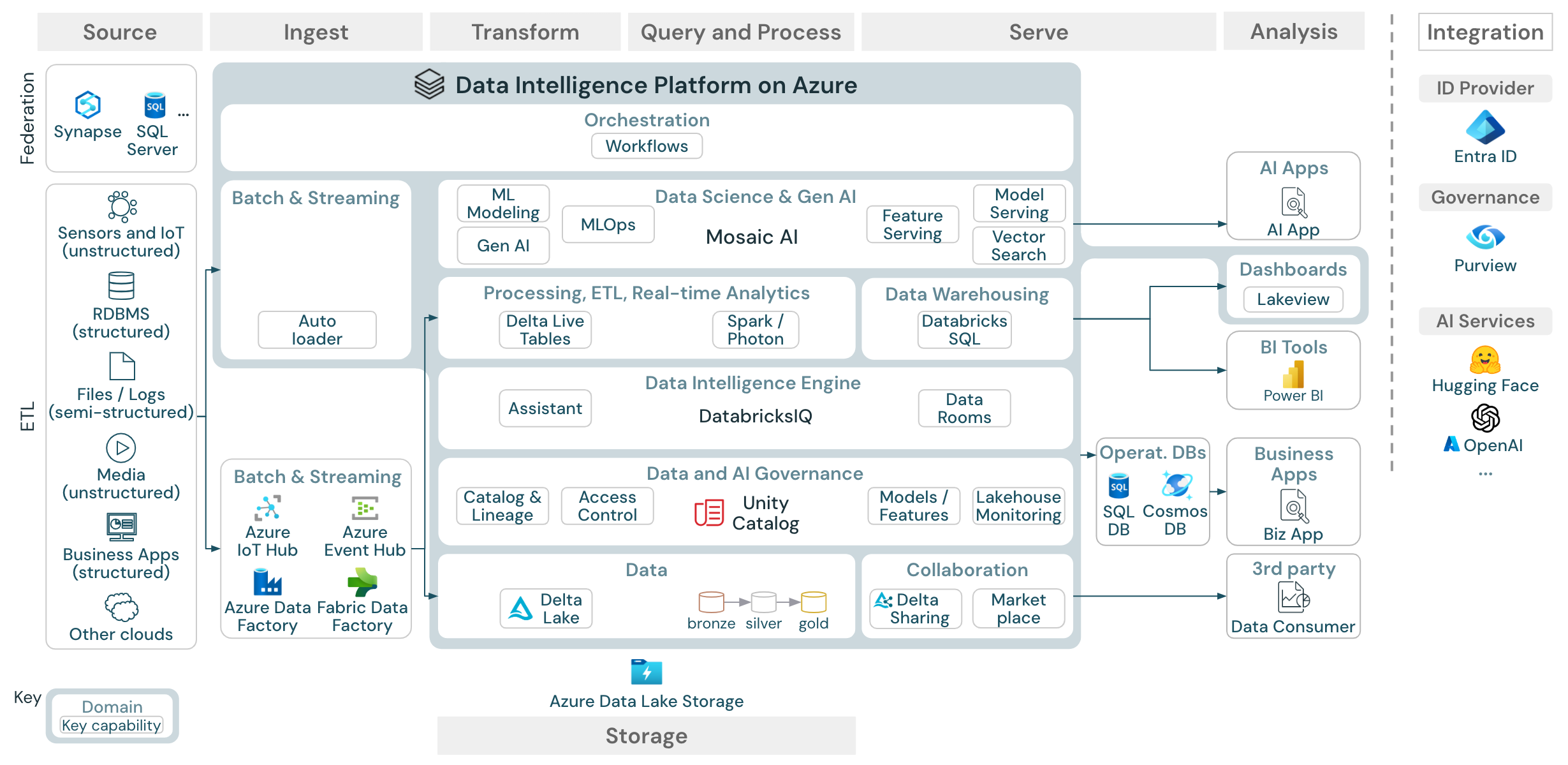
Azure 参考体系结构显示了针对引入、存储、服务提供以及分析的以下 Azure 特定服务:
- 用作 Lakehouse Federation 的源系统的 Azure Synapse 和 SQL Server
- 用于流式引入的 Azure IoT 中心和 Azure 事件中心
- 用于批量引入的 Azure 数据工厂
- Azure Data Lake Storage Gen 2 (ADLS) 作为数据和 AI 资产的对象存储
- Azure SQL DB 和 Azure Cosmos DB,用作操作数据库
- Azure Purview,用作企业目录,UC 会将架构和世系信息导出到该目录中
- Power BI,用作 BI 工具
参考体系结构的组织
参考体系结构是沿以下“泳道”构造的:数据源、引入、转换、查询/处理、服务提供、分析,以及存储:
来源
可通过三种方法将外部数据集成到数据智能平台:
ETL:该平台支持与提供半结构化和非结构化数据的系统(例如传感器、IoT 设备、媒体、文件和日志)以及关系数据库或业务应用程序的结构化数据集成。
Lakehouse Federation:关系数据库等 SQL 源可以集成到 Lakehouse 和 Unity Catalog 中,无需 ETL。 在这种情况下,源系统数据由 Unity 目录管理,查询将推送到源系统。
目录联合:Hive 元存储目录也可以通过 目录联合集成到 Unity 目录中,从而允许 Unity 目录控制 Hive 元存储中存储的表。
摄入
通过批处理或流式处理将数据引入湖屋:
- 可以使用 Databricks 自动加载程序直接加载传送到云存储的文件。
- 为了将数据从企业应用中批量导入 Delta Lake,Databricks lakehouse 依赖于合作伙伴引入工具,这些工具为这些记录系统提供了特定的适配器。
存储
- 数据通常存储在云存储系统中,其中 ETL 管道使用 奖牌体系结构 将数据以特选的方式存储为 Delta 文件/表 或 Apache Iceberg 表。
转换和查询/处理
Databricks lakehouse 使用其引擎 Apache Spark 和 Photon 执行所有转换和查询。
管道 是一个声明性框架,用于简化和优化可靠、可维护且可测试的数据处理管道。
Databricks Data Intelligence Platform 由 Apache Spark 和 Photon 提供支持,支持两种类型的工作负载:通过 SQL 仓库的 SQL 查询,以及通过工作区群集的 SQL、Python 和 Scala 工作负载。
对于数据科学(ML 建模和生成式 AI),Databricks AI 和机器学习平台 提供了专门用于 AutoML 和为 ML 作业编写代码的 ML 运行时。 所有数据科学和 MLOps 工作流都得到 MLflow 的最佳支持。
服务
- 对于数据仓库 (DWH) 和 BI 用例,Databricks Lakehouse 提供 Databricks SQL、由 SQL 仓库提供支持的数据仓库和无服务器 SQL 仓库。
运营数据库
- 外部系统(如作数据库)可用于存储最终数据产品并将其交付给用户应用程序。
协作:
- 业务合作伙伴通过 增量共享安全地访问所需的数据。
分析
- Data Intelligence Platform 还提供了仪表板来构建数据可视化效果并共享见解。
集成
Databricks 平台与标准标识提供者集成,用于用户管理和单一登录 (SSO)。
HuggingFace 等外部 AI 服务可以直接在 Databricks 智能平台内使用。
- 外部业务流程协调程序可以使用全面的 REST API 或专用连接器连接到外部业务流程工具,例如 Apache Airflow。
- Unity 目录用于 Databricks 智能平台中的所有数据和 AI 治理,并且可以通过 Lakehouse Federation 将其他数据库集成到其治理中。
此外,Unity Catalog 可以集成到其他企业目录中,例如 Purview。 有关详细信息,请联系企业目录供应商。
所有工作负载的常见功能
此外,Databricks 湖仓还提供了可以支持所有工作负载的管理功能:
数据和 AI 治理
Databricks Data Intelligence Platform 中的中央数据和 AI 治理系统是 Unity Catalog。 Unity Catalog 提供了单一位置来管理适用于所有工作空间的数据访问策略,并支持在湖屋中创建或使用的所有资产,例如表、卷、功能(功能存储)和模型(模型注册表)。 可以使用 Unity Catalog 在对 Azure Databricks 运行的查询中捕获运行时数据世系。
为实现可观察性,系统表 是由 Databricks 托管的账户操作数据的分析存储。 系统表可用于在您的账户中实现历史可观测性。
自动化和业务流程
Lakeflow 作业 在 Databricks 数据智能平台上协调和管理数据处理、机器学习及分析管道。 使用 Lakeflow Spark 声明性管道 ,可以使用声明性语法生成可靠且可维护的 ETL 管道。 该平台还支持 CI/CD 和 MLOps
Azure 上数据智能平台的高级用例
使用 Lakeflow Connect 从 SaaS 应用和数据库进行内置引入
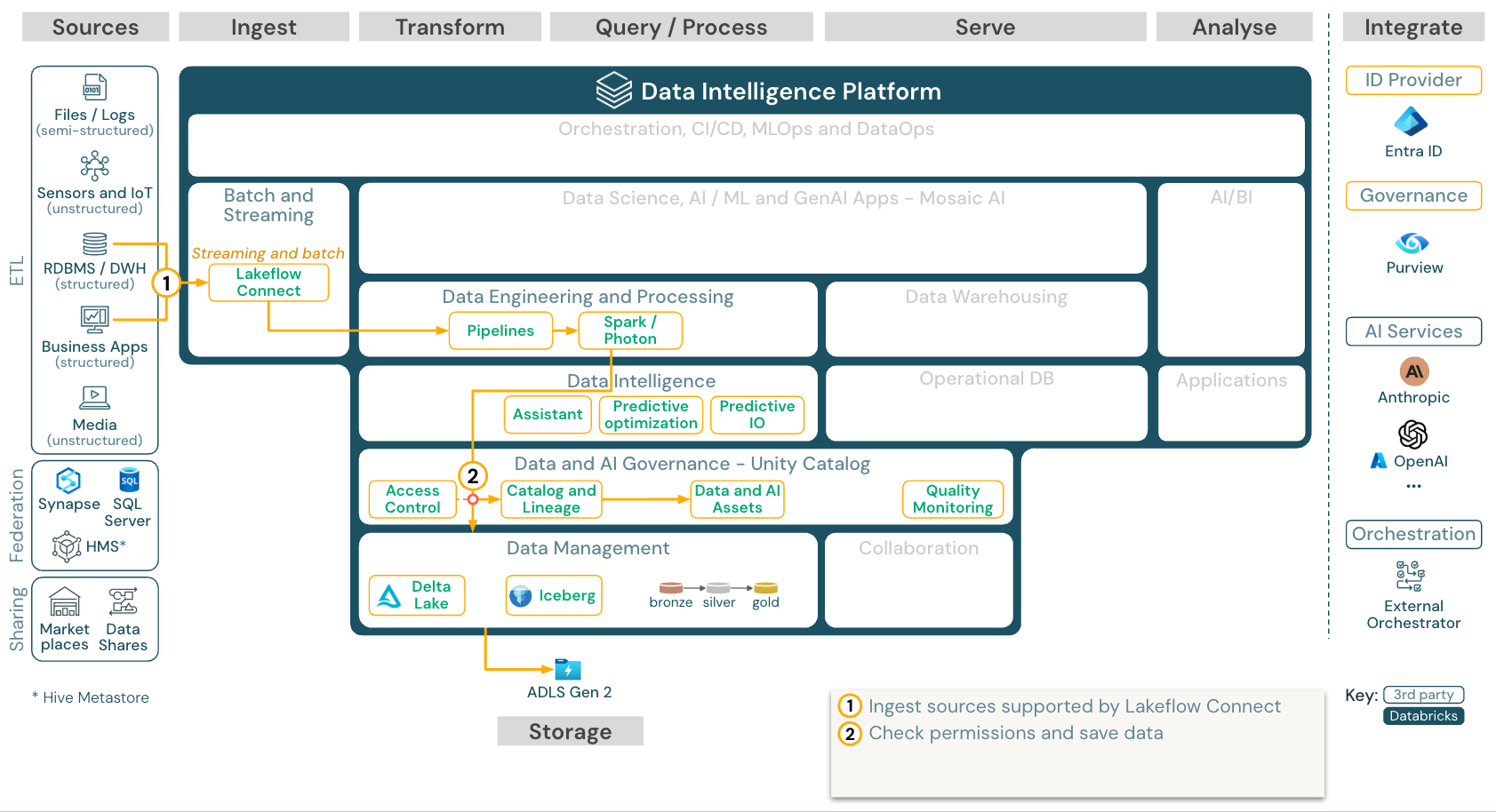
下载:适用于 Azure Databricks 的 Lakeflow Connect 参考体系结构。
Lakeflow Connect 利用高效的增量读取和写入,使数据引入更快、可缩放且更具成本效益,而数据仍保持新鲜,供下游使用。
批量处理引入和 ETL
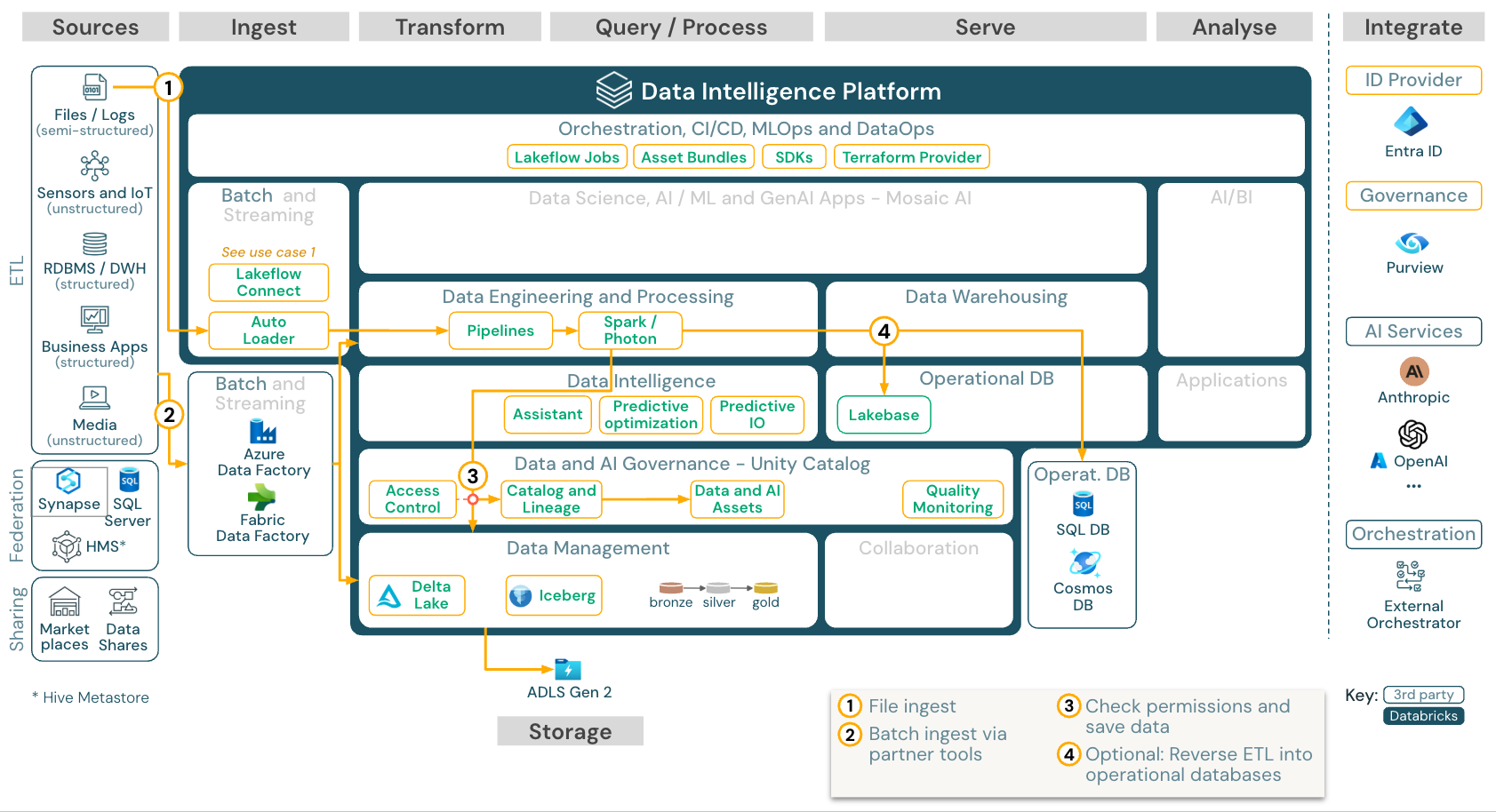
下载:适用于 Azure Databricks 的批量 ETL 参考体系结构
引入工具使用特定于源的适配器从源读取数据,然后将其存储在云存储中(自动加载程序可以从中读取数据),或直接调用 Databricks(例如,通过集成到 Databricks 湖屋中的合作伙伴引入工具)。 若要加载数据,Databricks ETL 和处理引擎通过 管道运行查询。 使用 Lakeflow 作业 协调单个或多任务作业,并使用 Unity 目录(访问控制、审核、世系等)对其进行管理。 若要提供对低延迟的操作系统的特定黄金表的访问,请在 ETL 管道末尾将表导出到操作数据库,例如 RDBMS 或键值存储。
流式处理和变更数据捕获 (CDC)
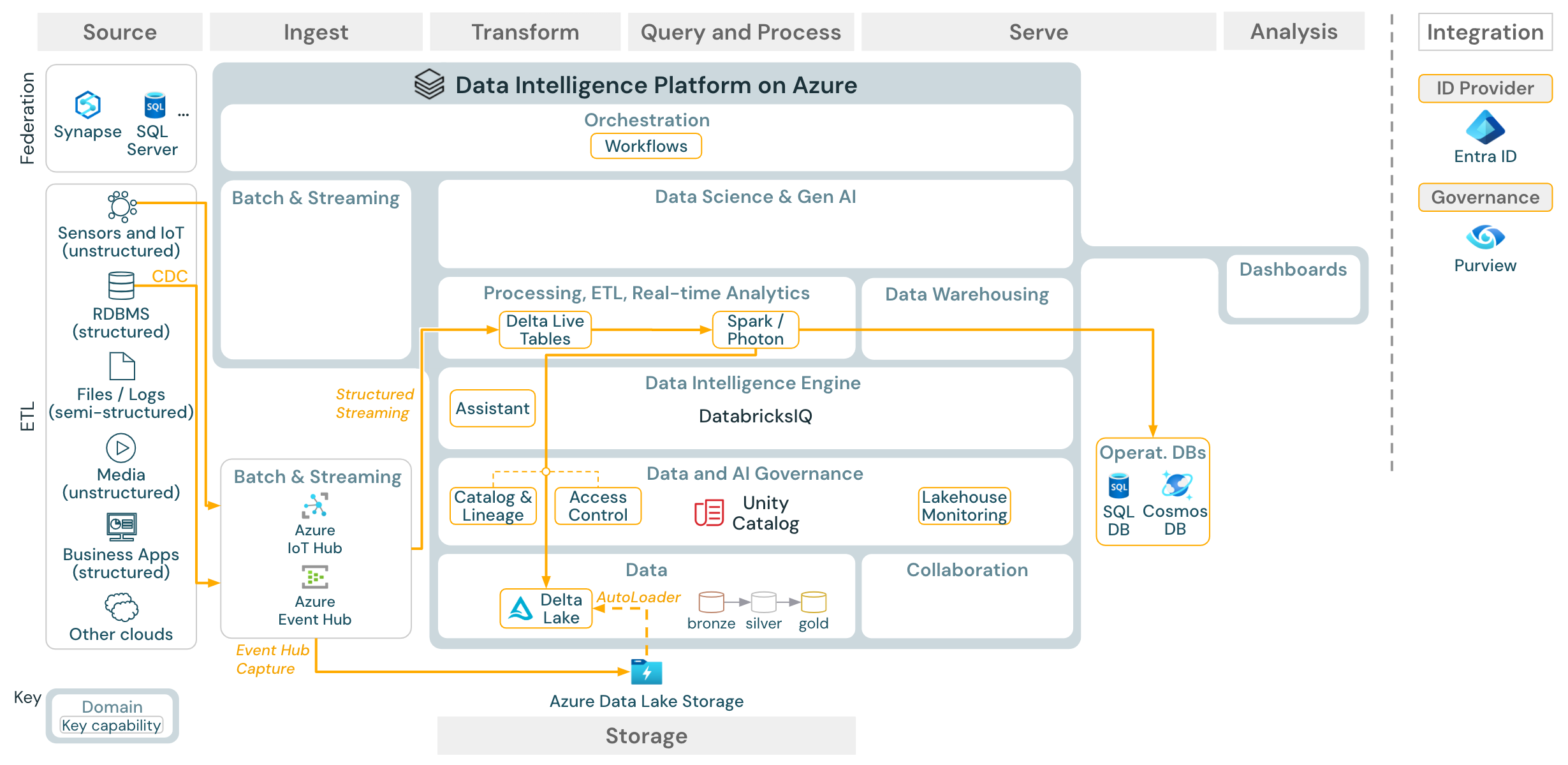
下载:适用于 Azure Databricks 的 Spark 结构化流式处理体系结构
Databricks ETL 引擎使用 Spark 结构化流式处理 从 Apache Kafka 或 Azure 事件中心等事件队列中读取数据。 下游步骤遵循上面的“批量”用例的方法。
实时 更改数据捕获 (CDC)通常将提取的事件存储在事件队列中。 在那里,此用例遵循流式传输的用例。
如果 CDC 批量完成,并且提取的记录首先存储在云存储中,则 Databricks 自动加载程序可以读取这些记录,并且用例遵循 Batch ETL。
机器学习和 AI(传统)
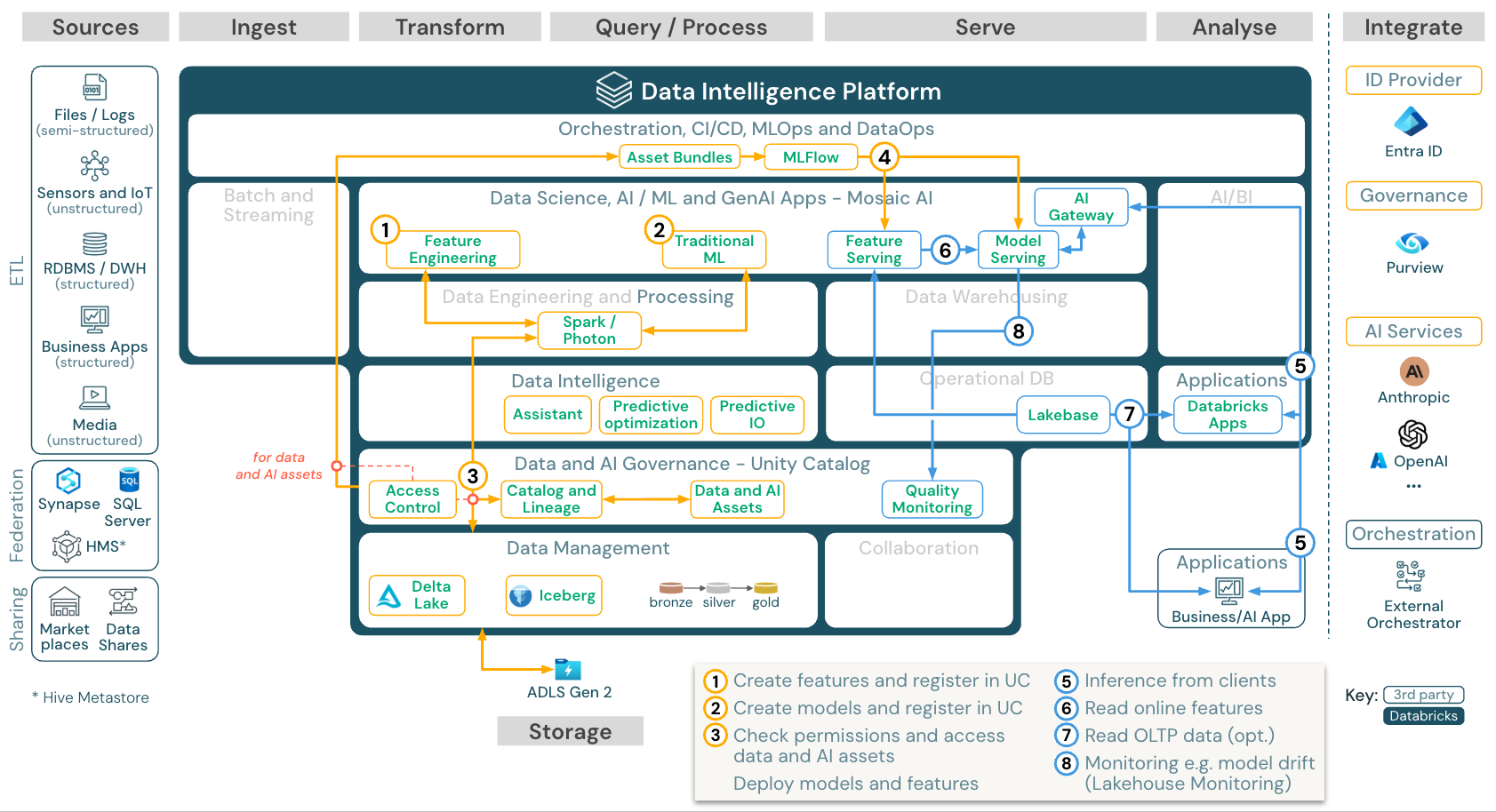
下载:适用于 Azure Databricks 的机器学习和 AI 参考体系结构
对于机器学习,Databricks 数据智能平台提供最先进的 机器学习和深度学习库。 它提供 功能存储 与 模型注册表 (都集成到 Unity 目录中)、使用 AutoML 的低代码功能,以及 MLflow 集成到数据科学生命周期的功能。
Unity 目录管理所有数据科学相关资产(表、功能和模型),数据科学家可以使用 Lakeflow 作业 来协调其作业。
若要以可缩放和企业级的方式部署模型,请使用 MLOps 功能在模型服务中发布模型。
AI 代理应用程序(Gen AI)
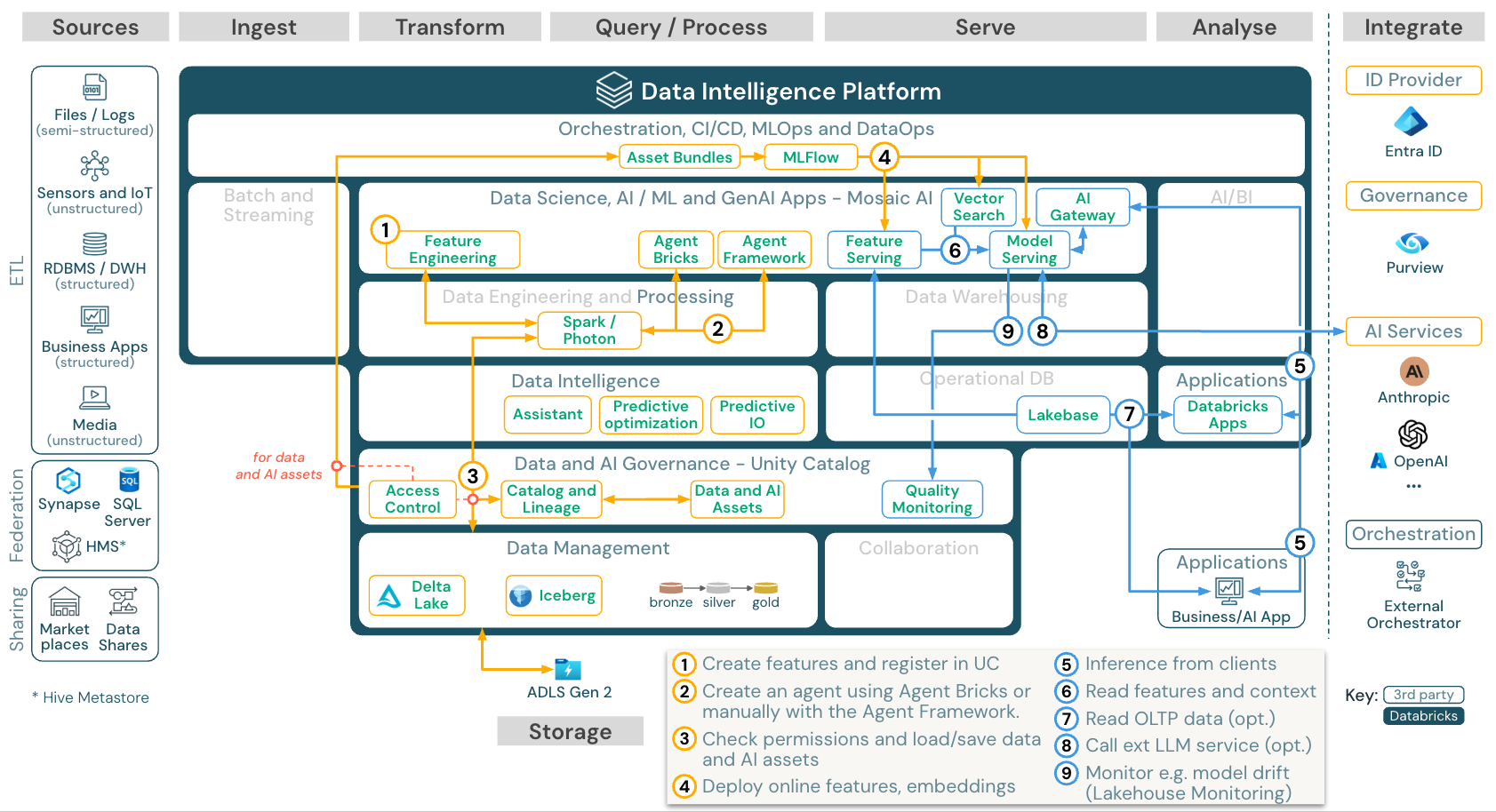
下载:适用于 Azure Databricks 的 Gen AI 应用程序参考体系结构
为了以可缩放的企业级方式部署模型,请使用 MLOps 功能在模型服务中发布模型。
BI 和 SQL 分析
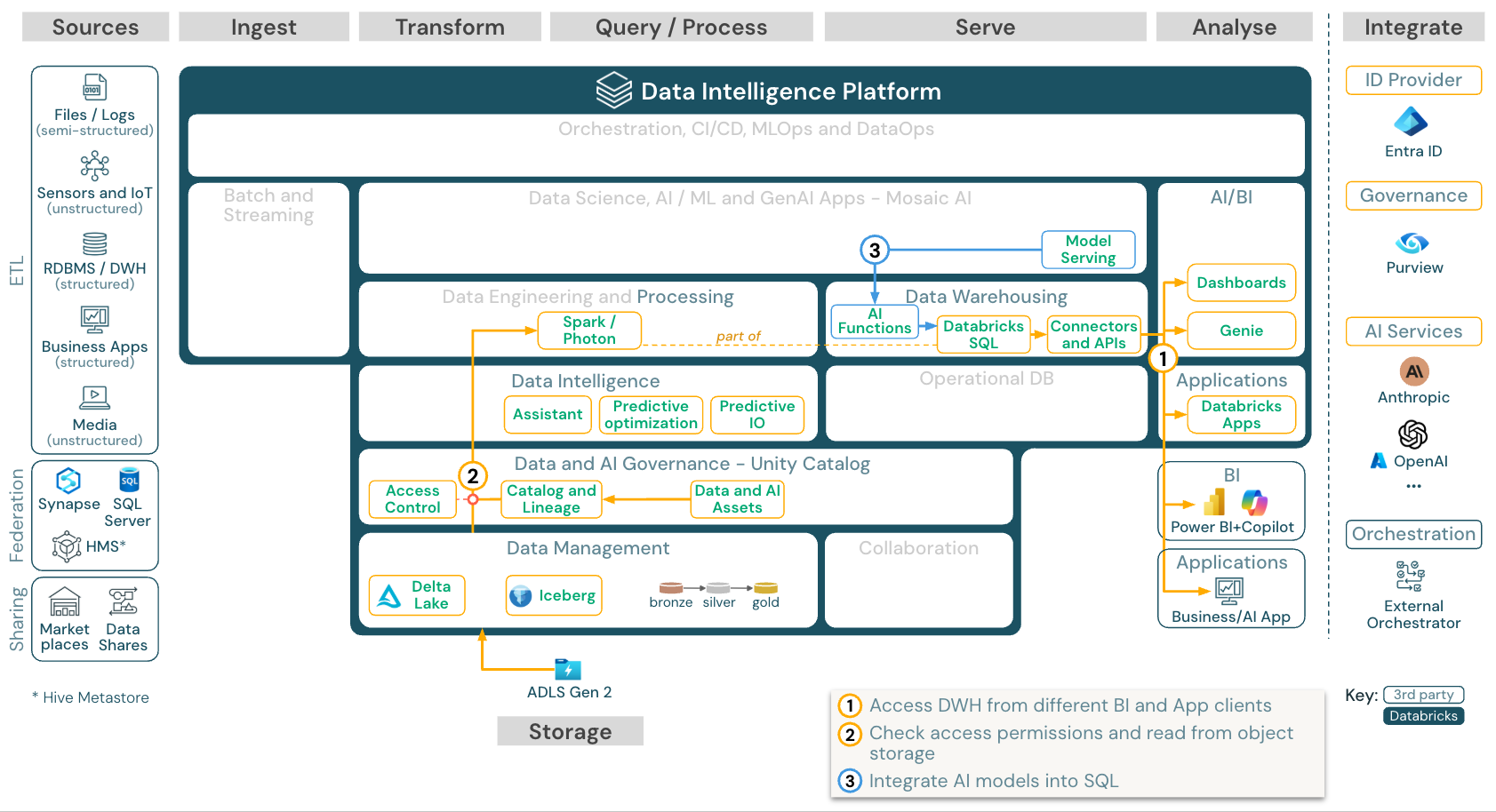
下载:适用于 Azure Databricks 的 BI 和 SQL 分析参考体系结构
对于 BI 用例,业务分析师可以使用 仪表板、 Databricks SQL 编辑器 或 BI 工具 ,例如 Tableau 或 Power BI。 在所有情况下,引擎都是 Databricks SQL(无服务器或无服务器),Unity 目录提供数据发现、浏览和访问控制。
Lakehouse Federation
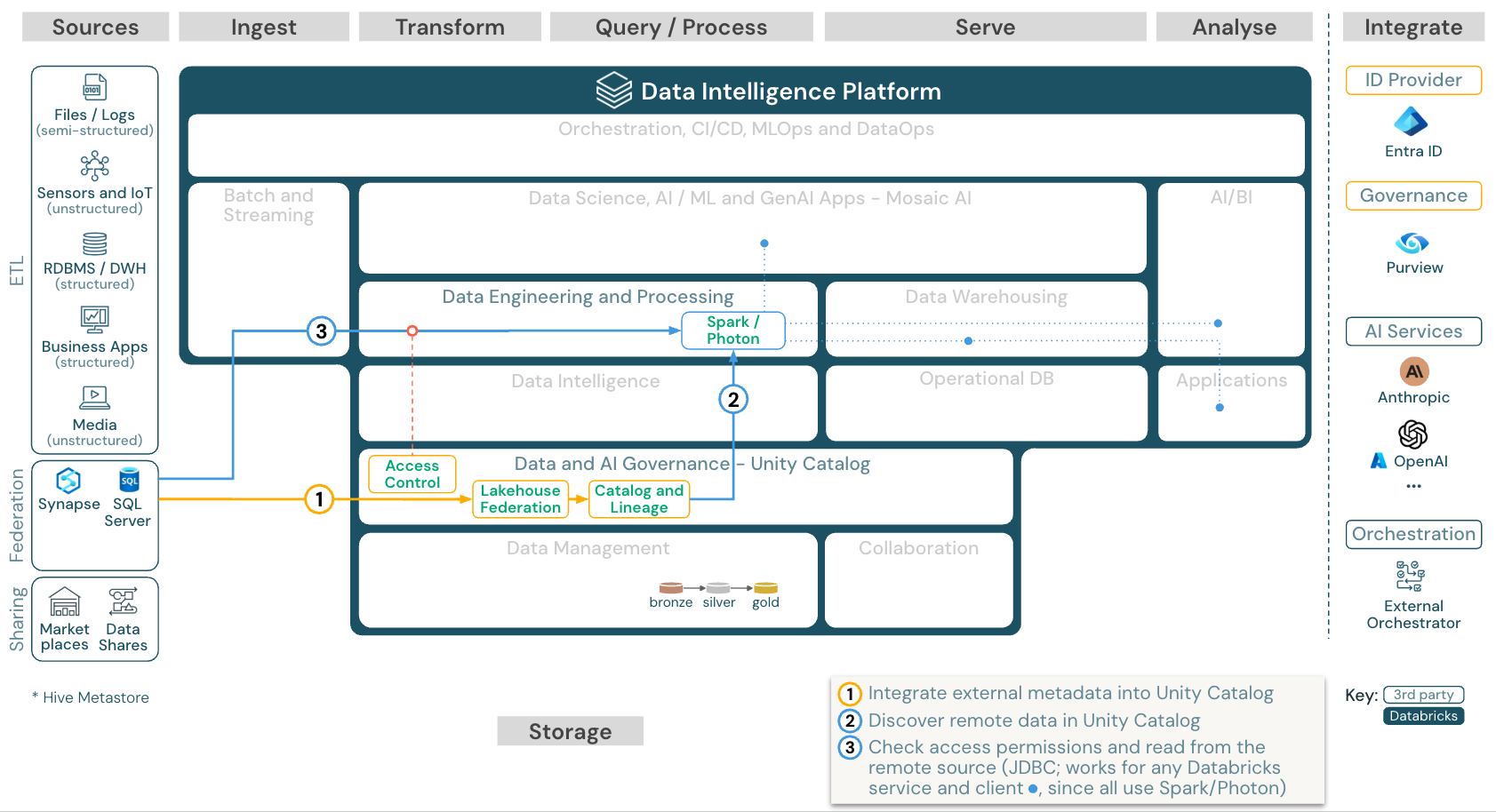
下载:Azure Databricks 的 Lakehouse Federation 参考体系结构
Lakehouse 联合架构 允许外部 SQL 数据库(如 MySQL、Postgres、SQL Server 或 Azure Synapse)与 Databricks 集成。
所有工作负载(AI、DWH 和 BI)都可以从中受益,因为不需要首先提取、转换数据并将其加载到对象存储中。 外部源目录映射到 Unity Catalog,并且可以应用精细访问控制,以通过 Databricks 平台进行访问。
目录联合
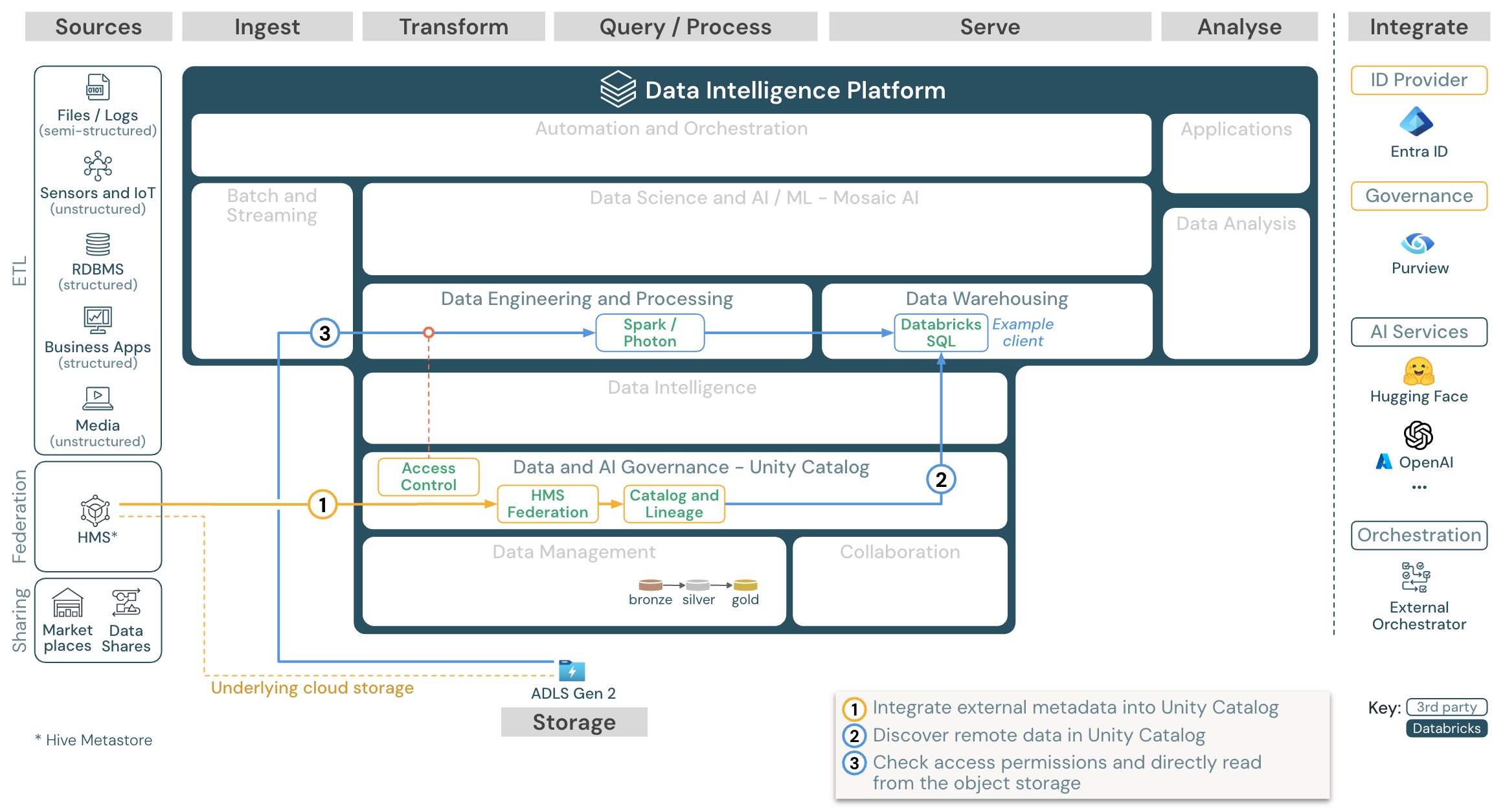
下载:Azure Databricks 的目录联合参考体系结构
目录联合允许将外部 Hive 元存储(例如 MySQL、Postgres、SQL Server 或 Azure Synapse)与 Databricks 集成。
所有工作负载(AI、DWH 和 BI)都可以从中受益,因为不需要首先提取、转换数据并将其加载到对象存储中。 外部源目录被添加到 Unity Catalog 中,其中通过 Databricks 平台应用精细访问控制。
使用第三方工具共享数据
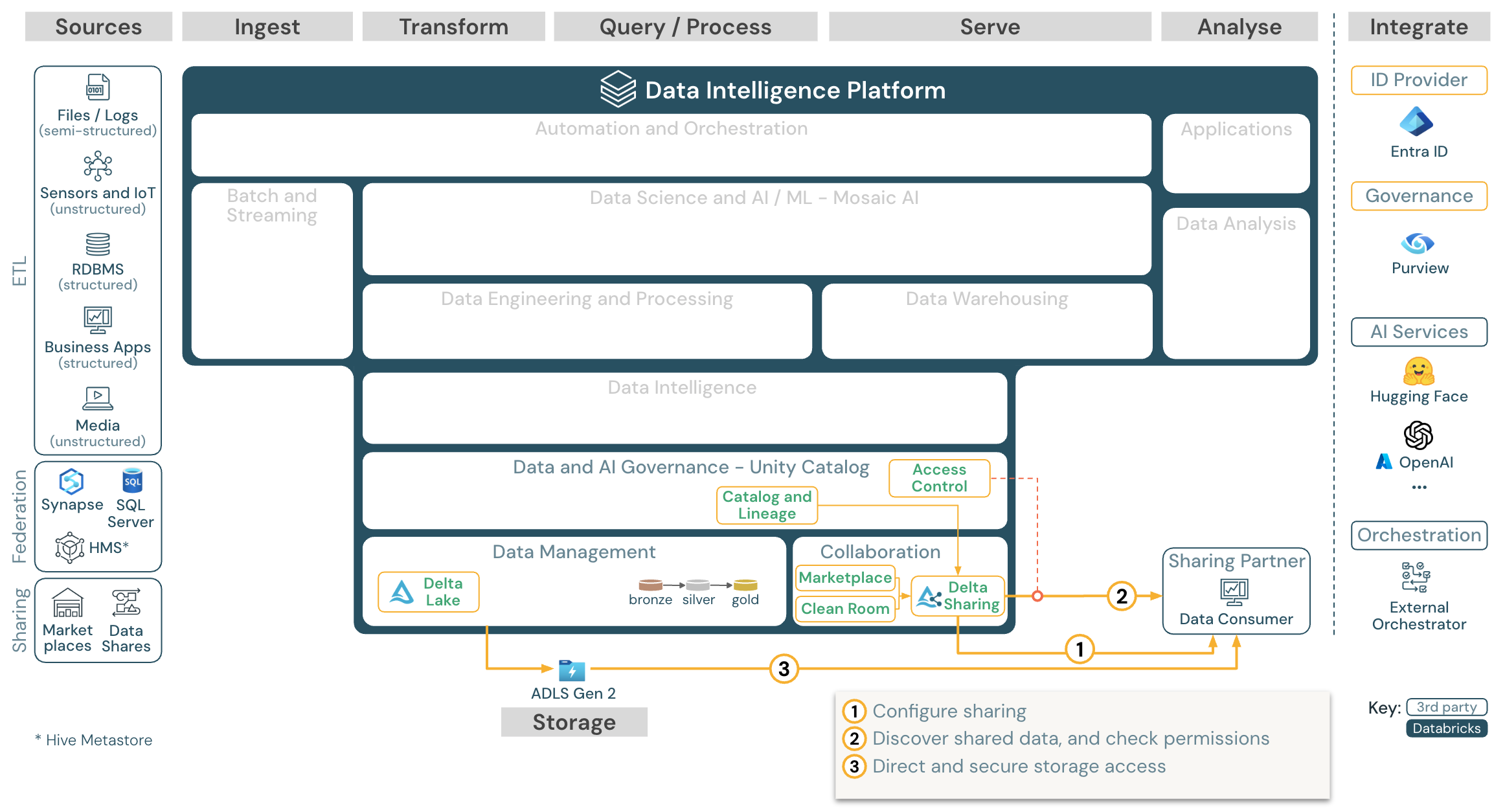
下载:使用 Azure Databricks 的第三方工具参考体系结构共享数据
Delta Sharing 提供与第三方的企业级数据共享。 它允许直接访问受 Unity 目录保护的对象存储中的数据。
使用 Databricks 中的共享数据
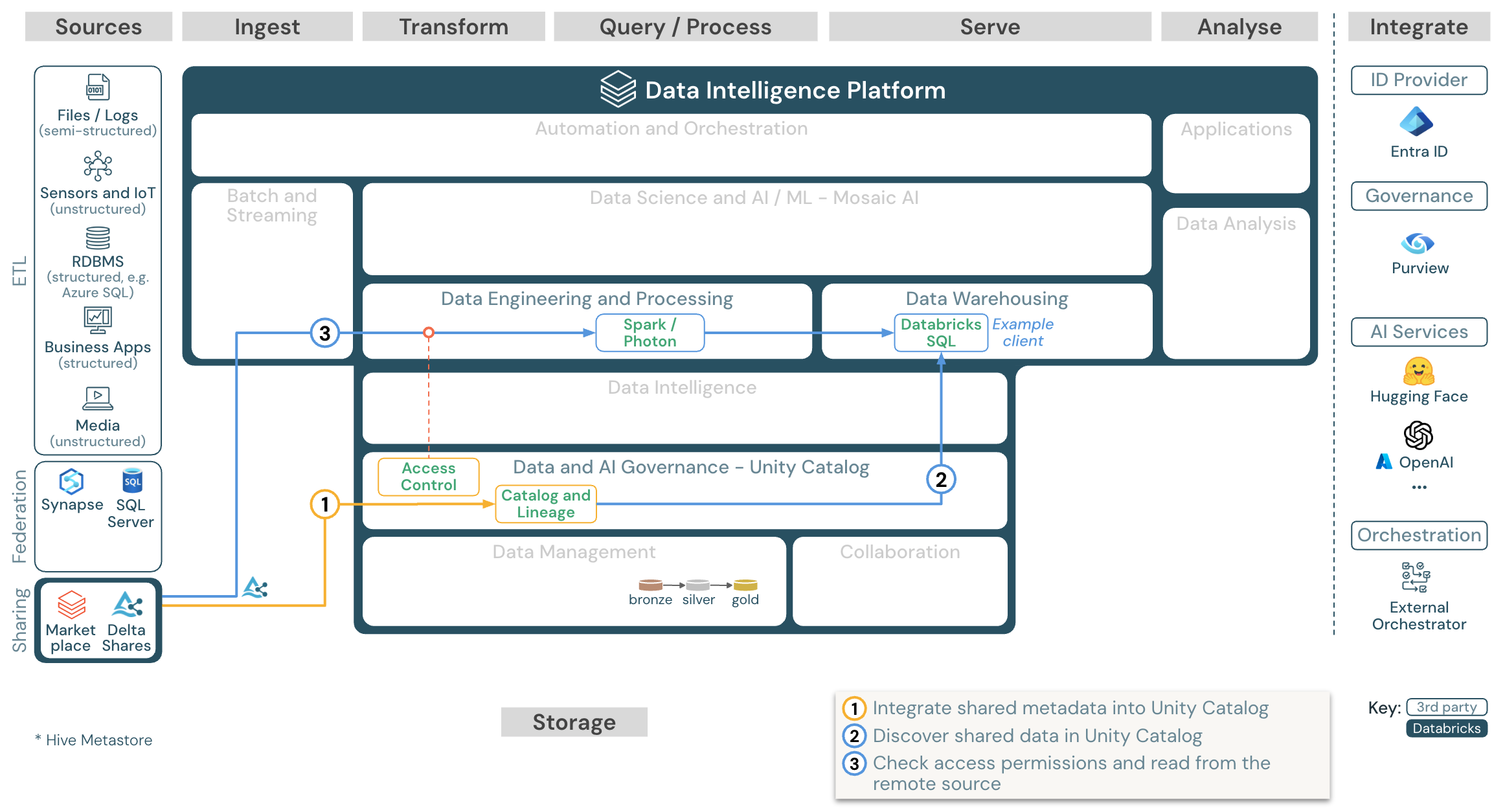
下载:使用 Azure Databricks 的 Databricks 参考体系结构中的共享数据
Delta 共享 Databricks 到 Databricks 协议 允许用户在任何账户或云主机下,只要有权限访问启用了 Unity Catalog 的工作区,便可与任何 Databricks 用户安全共享数据。