使用 Azure Databricks AutoML UI 训练 ML 模型
本文演示如何使用 AutoML 和 Databricks 机器学习 UI 训练机器学习模型。 AutoML UI 可引导你完成基于数据集训练分类、回归或预测模型。
请参阅 AutoML 试验的要求。
打开 AutoML UI
要访问 AutoML UI:
在边栏中,选择“新建”>“AutoML 试验”。
还可以从“试验”页创建新的 AutoML 试验。
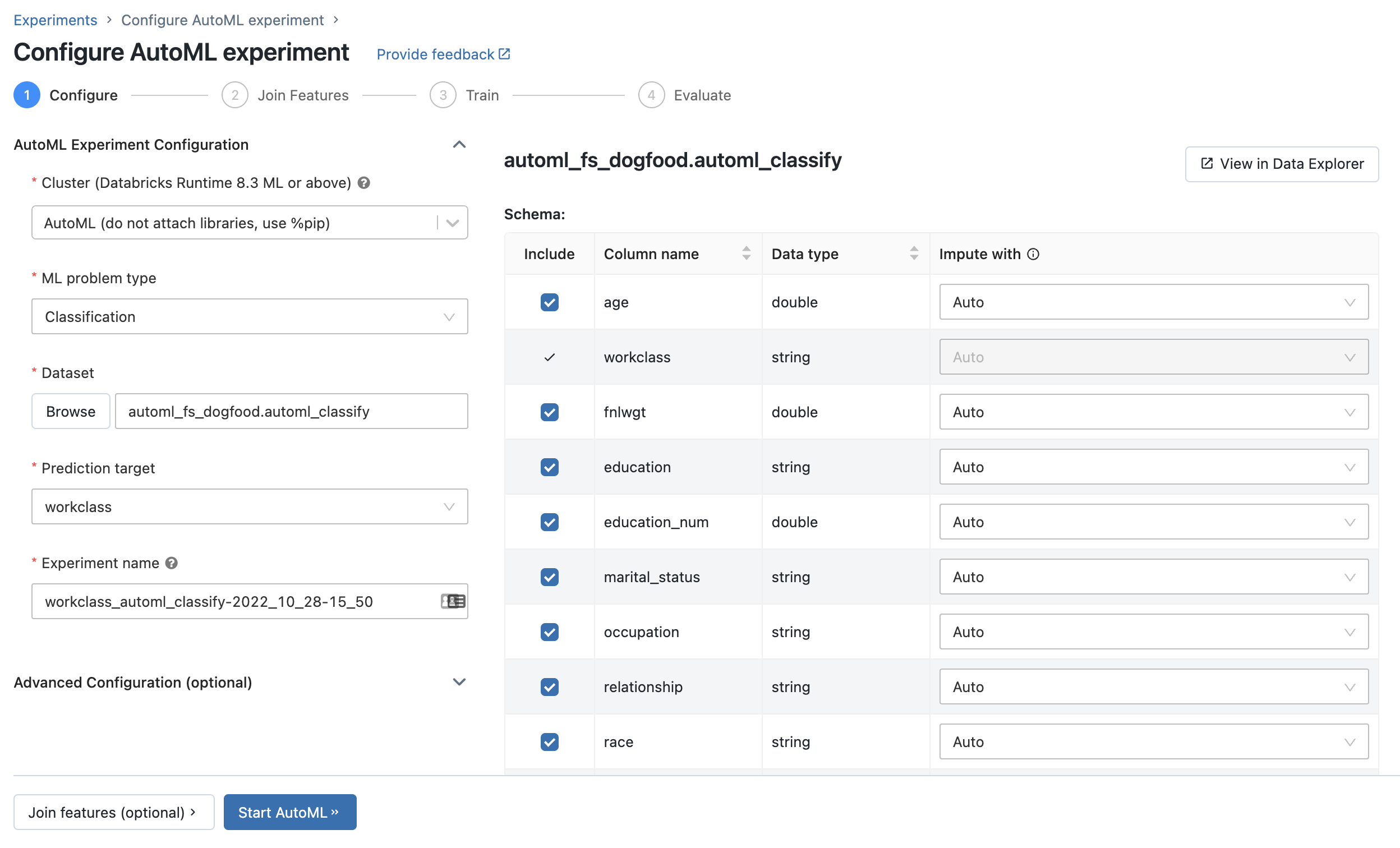
此时会显示“配置 AutoML 试验”页。 在此页上,指定数据集、问题类型、要预测的目标或标签列、要用于评估试验运行并为其评分的指标,以及停止条件,来配置 AutoML 过程。
设置分类或回归问题
可以按照以下步骤使用 AutoML UI 设置分类或回归问题:
在“计算”字段中,选择一个运行 Databricks Runtime ML 的群集。
在“ML 问题类型”下拉菜单中,选择“回归”或“分类”。 如果你正在尝试预测每个观测项的连续数字值(例如年度收入),请选择“回归”。 如果你正在尝试将每个观测项分配给一组离散类中的一个(例如良好信用风险或不良信用风险),请选择“分类”。
在“数据集”下,选择“浏览”。
导航到要使用的表,然后单击“选择”。 此时会显示表架构。
在 Databricks Runtime 10.3 ML 和更高版本中,可以指定 AutoML 应使用哪些列进行训练。 不能删除选作预测目标的列,或用于拆分数据的时间列。
在 Databricks Runtime 10.4 LTS ML 及更高版本中,可以从“插补方式”下拉列表中进行选择,以指定如何插补 null 值。 默认情况下,AutoML 会根据列类型和内容选择一种插补方法。
注意
如果你指定了非默认插补方法,则 AutoML 不会执行语义类型检测。
单击“预测目标”字段。 此时会显示一个下拉列表,其中列出了架构中显示的列。 选择希望模型预测的列。
“试验名称”字段显示默认名称。 若要更改该名称,请在字段中键入新名称。
你还可以:
- 指定其他配置选项。
- 使用特征存储中的现有特征表来补充原始输入数据集。
设置预测问题
可以按照以下步骤使用 AutoML UI 设置预测问题:
在“计算”字段中,选择一个运行 Databricks Runtime 10.0 ML 或更高版本的群集。
在“ML 问题类型”下拉菜单中,选择“预测”。
在“数据集”下,单击“浏览”。 导航到要使用的表,然后单击“选择”。 此时会显示表架构。
单击“预测目标”字段。 此时会显示一个下拉菜单,其中列出了架构中显示的列。 选择希望模型预测的列。
单击“时间列”字段。 将显示一个下拉列表,其中显示类型为
timestamp或date的数据集列。 选择包含时序时间段的列。对于多序列预测,请从“时序标识符”下拉列表中选择标识单个时序的列。 AutoML 按这些列将数据分组为不同的时序,并单独训练每个序列的模型。 如果将此字段留空,AutoML 会假定数据集包含单个时序。
在“预测范围和频率”字段中,指定 AutoML 应计算预测值的未来时间段数。 在左侧框中,输入要预测的时间段整数。 在右侧框中,选择单位。
注意
要使用 Auto-ARIMA,时序必须具有固定频率(其中任意两点之间的间隔必须在整个时序中相同)。 频率必须与 API 调用或 AutoML UI 中指定的频率单元匹配。 AutoML 通过用前一个值填充这些值,以此来处理丢失的时间步长。
在 Databricks Runtime 11.3 LTS ML 及更高版本中,可以保存预测结果。 为此,请在“输出数据库”字段中指定一个数据库。 单击“浏览”并从对话框中选择数据库。 AutoML 会将预测结果写入此数据库中的表。
“试验名称”字段显示默认名称。 若要更改该名称,请在字段中键入新名称。
你还可以:
- 指定其他配置选项。
- 使用特征存储中的现有特征表来补充原始输入数据集。
使用 Databricks 特征存储中的现有特征表
在 Databricks Runtime 11.3 LTS ML 及更高版本中,可以使用 Databricks 特征存储中的特征表扩展输入训练数据集以解决分类和回归问题。
在 Databricks Runtime 12.2 LTS ML 及更高版本中,可以使用 Databricks 特征存储中的特征表来扩展所有 AutoML 问题(分类、回归和预测)的输入训练数据集。
若要创建特征表,请参阅 在 Unity Catalog 中创建特征表 或 在 Databricks 功能存储中创建特征表。
配置 AutoML 试验后,可以使用以下步骤选择特征表:
单击“加入特征(可选)”。
在“加入其他功能”页的“特征表”字段中选择一个特征表。
对于每个特征表主键,选择相应的查找键。 查找键应该是为 AutoML 试验提供的训练数据集中的列。
对于时序特征表,请选择相应的时间戳查找键。 同样,时间戳查找键应该是为 AutoML 试验提供的训练数据集中的列。
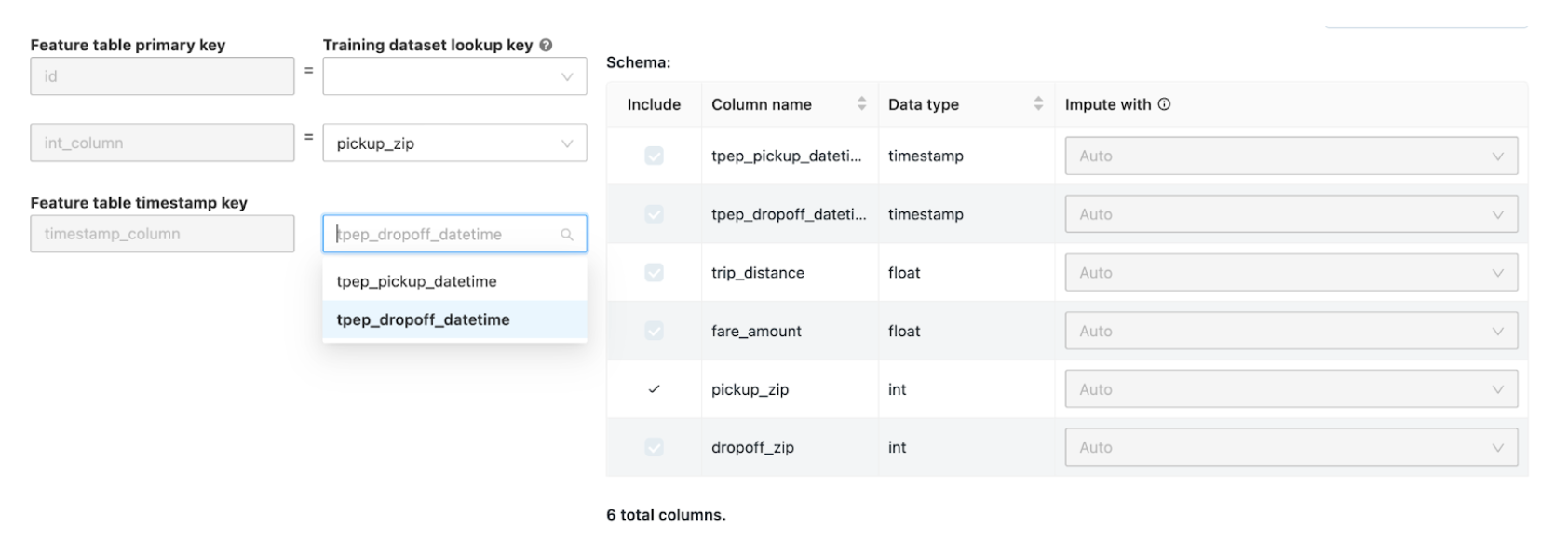
若要添加更多特征表,请单击“添加另一个表”并重复上述步骤。
高级配置
打开“高级配置 (可选)”部分以访问这些参数。
- 评估指标是用来为运行评分的主要指标。
- 在 Databricks Runtime 10.4 LTS ML 及更高版本中,可将训练框架排除在考虑范围之外。 默认情况下,AutoML 使用 AutoML 算法下列出的框架训练模型。
- 你可以编辑停止条件。 默认停止条件为:
- 对于预测实验,请在 120 分钟后停止。
- 在 Databricks Runtime 10.4 LTS ML 及更低版本中,对于分类和回归试验,请在 60 分钟或完成 200 次试验后停止,以较早发生者为准。 对于 Databricks Runtime 11.0 ML 及更高版本,试验次数不会用作停止条件。
- 在 Databricks Runtime 10.4 LTS ML 及更高版本中,对于分类和回归试验,AutoML 合并了提前停止;如果验证指标不再有改善,它将停止训练和优化模型。
- 在 Databricks Runtime 10.4 LTS ML 及更高版本中,可以选择一个时间列来按时间顺序拆分用于训练、验证和测试的数据(仅适用于分类和回归)。
- Databricks 建议不要填充“数据目录”字段。 这样做会触发默认行为,将数据集安全地存储为 MLflow 项目。 可以指定 DBFS 路径,但在这种情况下,数据集不会继承 AutoML 试验的访问权限。
运行实验并监视结果
若要启动 AutoML 试验,请单击“启动 AutoML”。 试验随即开始运行,此时会显示 AutoML 训练页。 若要刷新运行表,请单击 。
。
在此页中,可以:
- 随时停止试验。
- 打开数据探索笔记本。
- 监视运行。
- 导航到任一运行的运行页。
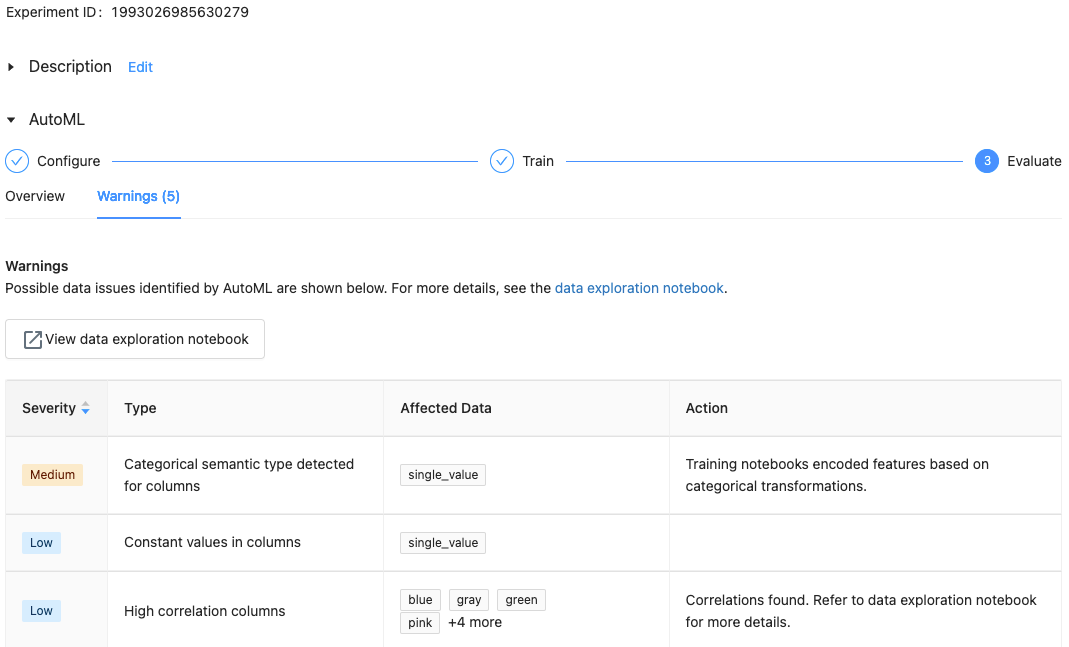
对于 Databricks Runtime 10.1 ML 和更高版本,AutoML 会显示有关数据集潜在问题的警告,例如不支持的列类型或高基数列。
注意
Databricks 会尽力指出潜在的错误或问题。 但是,这可能并不全面,并且可能无法捕获可能正在搜索的问题或错误。
要查看数据集的任何警告,请点击训练页或试验页(试验完成后)上的“警告”选项卡。
试验完成后,可以:
- 使用 MLflow 注册和部署某个模型。
- 选择“查看最佳模型的笔记本”以查看和编辑创建了最佳模型的笔记本。
- 选择“查看数据探索笔记本”打开数据探索笔记本。
- 搜索、筛选运行表中的运行以及对其进行排序。
- 查看任一运行的详细信息:
- 可以通过单击 MLflow 运行找到包含源代码的已生成笔记本进行试运行。 笔记本保存在运行页的“项目”部分。 如果工作区管理员启用了下载项目的功能,则可以下载此笔记本并将其导入工作区。
- 要查看运行结果,请点击“模型”列或“开始时间”列。 此时将出现运行页,其中显示了有关试运行的信息(例如参数、指标和标记)和该运行创建的项目(包括模型)。 此页面还包含可用于对模型进行预测的代码片段。
以后若要返回到此 AutoML 试验,可在“试验”页上的表中找到它。 每个 AutoML 实验的结果(包括数据探索和训练笔记本)都存储在运行实验的用户的主文件夹中的一个 databricks_automl 文件夹中。
注册和部署模型
可以使用 AutoML UI 注册和部署模型:
- 选择要注册的模型的“模型”列中的链接。 运行完成后,最佳模型(基于主要指标)将显示在最前面的行中。
- 选择
 以在模型注册表中注册该模型。
以在模型注册表中注册该模型。 - 选择边栏中的“模型”导航到“模型注册表”
 。
。 - 在模型表中选择你的模型名称。
没有名为“pandas.core.indexes.numeric”的模块
通过模型服务为使用 AutoML 生成的模型提供服务时,可能会收到错误:No module named 'pandas.core.indexes.numeric。
这是由于 AutoML 和模型服务终结点环境之间的 pandas 版本是不兼容的版本。 可以通过运行 add-pandas-dependency.py 脚本解决此错误。 该脚本会为你记录的模型编辑 requirements.txt 和 conda.yaml,以包含适当的 pandas 依赖项版本:pandas==1.5.3
- 修改脚本以包含记录模型时所在的 MLflow 运行的
run_id。 - 将模型重新注册到 MLflow 模型注册表。
- 尝试为新版 MLflow 模型提供服务。