重要
本文档介绍工作区模型注册表。 如果你的工作区已启用 Unity Catalog,请不要使用此页上的过程。 请改为参阅 Unity Catalog 中的模型。
有关如何从工作区模型注册表升级到 Unity Catalog 的指南,请参阅将工作流和模型迁移到 Unity Catalog。
如果工作区 的默认目录 位于 Unity 目录(而不是 hive_metastore)中,并且使用 Databricks Runtime 13.3 LTS 或更高版本或使用 MLflow 3 运行群集,则模型会自动在工作区默认目录中创建和加载,无需配置。 在这种情况下,要使用工作区模型注册表,必须在工作负载开始时运行import mlflow; mlflow.set_registry_uri("databricks"),以明确指定它。 在少数工作区中,默认目录在 2024 年 1 月之前配置为 Unity Catalog 中的目录,并在 2024 年 1 月之前使用了工作区模型注册表,这些工作区不受此行为限制,并会继续默认使用工作区模型注册表。
本文介绍如何使用工作区模型注册表作为机器学习工作流的一部分来管理 ML 模型的整个生命周期。 工作区模型注册表是 MLflow 模型注册表的托管版本,由 Databricks 提供。
与 MLflow 2.x 中一样, MLflow 3 将继续支持工作区模型注册表。 使用 MLflow 3 时,默认注册表 URI 为 databricks-uc,这意味着将使用 Unity 目录中的 MLflow 模型注册表。 若要使用工作区模型注册表,必须调用 mlflow.set_registry_uri("databricks")。 有关详细信息,请参阅 模型注册表。
工作区模型注册表提供:
按时间顺序的模型世系(MLflow 试验和运行在给定时间生成了该模型)。
模型版本控制。
阶段转换(例如,从暂存阶段转换到生产或存档阶段)。
Webhook,用于根据注册表事件自动触发操作。
模型事件的电子邮件通知。
你还可创建和查看模型说明,并留下注释。
本文包含工作区模型注册表 UI 和工作区模型注册表 API 的说明。
有关工作空间模型注册表概念的概述,请参阅 MLflow 的 ML 模型生命周期。
创建或注册模型
可以使用 UI 创建或注册模型,或者使用 API 注册模型。
使用 UI 创建或注册模型
可以通过两种方式在工作区模型注册表中注册模型。 可以注册已记录到 MLflow 的现有模型,也可以创建并注册一个新的空模型,然后将某个已记录的模型分配给它。
从笔记本中注册现有的已记录模型
在工作区中,标识包含要注册的模型的 MLflow 运行。
在笔记本的右边栏中,单击“试验”图标 。

请在“试验运行”边栏中,单击运行的日期旁边的
 图标。 MLflow 运行页面随即显示。 此页面显示运行详细信息,包括参数、指标、标记和项目列表。
图标。 MLflow 运行页面随即显示。 此页面显示运行详细信息,包括参数、指标、标记和项目列表。
在“构件”部分,单击名为“xxx-model”的目录。
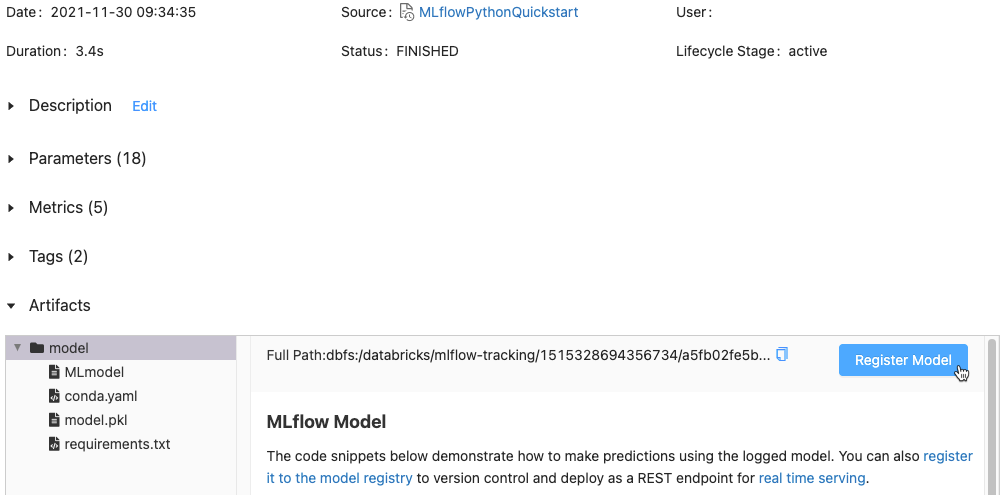
单击最右侧的“注册模型”按钮。
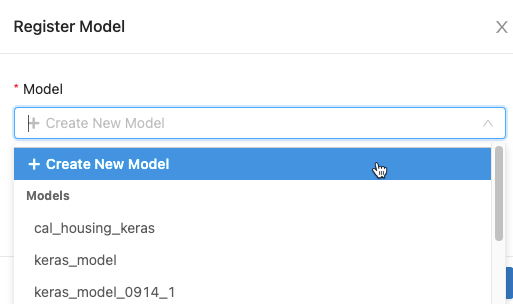
在对话框中,在“模型”框中单击,并执行下列操作之一:
- 从下拉菜单中选择创建新模型。 此时将显示“模型名称”字段。 输入模型名称,例如
scikit-learn-power-forecasting。 - 从下拉菜单中选择一个现有的模型。
- 从下拉菜单中选择创建新模型。 此时将显示“模型名称”字段。 输入模型名称,例如
单击“注册”。
- 如果选中“新建模型”,这将注册一个名为
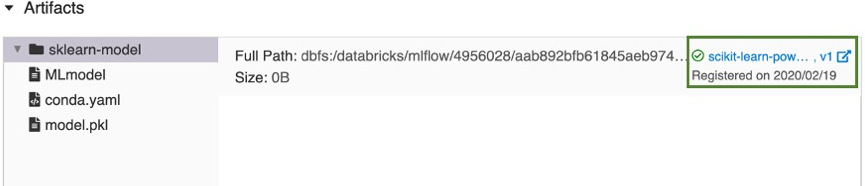
scikit-learn-power-forecasting的模型,将该模型复制到由工作区模型注册表管理的安全位置,并创建该模型的新版本。 - 如果已选中现有模型,则会注册所选模型的新版本。
一会儿之后,“注册模型”按钮会更改为指向新注册的模型版本的链接。
- 如果选中“新建模型”,这将注册一个名为
单击此链接可在工作区模型注册表 UI 中打开新的模型版本。 还可以通过单击边栏中的
 模型来在工作区模型注册表中查找模型。
模型来在工作区模型注册表中查找模型。
创建一个新的注册模型,并将一个已记录的模型分配给它。
可以使用已注册的模型页上的“创建模型”按钮创建一个新的空模型,然后为其分配一个已记录的模型。 请执行下列步骤:
在“已注册的模型”页上,单击“创建模型”。 为该模型输入一个名称,然后单击“创建”。
请按从笔记本注册已记录的现有模型中的步骤 1 到 3 操作。
在“注册模型”对话框中,选择在步骤 1 中创建的模型的名称,然后单击“注册”。 该操作的结果是采用之前创建的名称注册一个模型,将该模型复制到由工作区模型注册表管理的安全位置,并创建模型版本:
Version 1。几分钟后,MLflow 运行 UI 会将“注册模型”按钮替换为指向新注册的模型版本的链接。 现可从“试验运行”页上的“注册模型”对话框中的“模型”下拉列表中选择模型 。 还可以通过在 API 命令(如 Create ModelVersion)中指定模型名称来注册模型的新版本。
使用 API 注册模型
可以通过三种编程式方法在工作区模型注册表中注册模型。 所有方法都将模型复制到由工作区模型注册表管理的安全位置。
若要记录模型并在 MLflow 试验期间将其注册为指定名称,请使用
mlflow.<model-flavor>.log_model(...)方法。 如果还没有模型注册为该名称,该方法将注册一个新模型,创建版本 1,并返回ModelVersionMLflow 对象。 如果已有模型注册为该名称,该方法将创建一个新的模型版本并返回版本对象。with mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" )若要在所有试验运行完成后使用指定名称注册模型,并且已确定最适合添加到注册表的模型,请使用
mlflow.register_model()方法。 采用此方法时,需要mlruns:URI参数的运行 ID。 如果还没有模型注册为该名称,该方法将注册一个新模型,创建版本 1,并返回ModelVersionMLflow 对象。 如果已有模型注册为该名称,该方法将创建一个新的模型版本并返回版本对象。result=mlflow.register_model("runs:<model-path>", "<model-name>")若要创建具有指定名称的新的注册模型,请使用 MLflow 客户端 API
create_registered_model()方法。 如果模型名称存在,此方法将引发MLflowException。client = MlflowClient() result = client.create_registered_model("<model-name>")
还可以向 Databricks Terraform 提供程序和 databricks_mlflow_model 注册模型。
配额限制
从 2024 年 5 月开始,对于所有 Databricks 工作区,工作区模型注册表将对每个工作区的已注册模型和模型版本总数施加配额限制。 请参阅资源限制。 如果你超出了注册表配额,Databricks 建议删除已注册的模型和不再需要的模型版本。 Databricks 还建议调整模型注册和保留期策略,以防超出限制。 如果需要提高工作区限制,请联系你的 Databricks 帐户团队。
以下笔记本演示如何清点和删除模型注册表实体。
清点工作区模型注册表实体笔记本
在 UI 中查看模型
已注册模型页
在边栏中点击![]() ,将显示模型的已注册模型页面。 此页显示注册表中的所有模型。
,将显示模型的已注册模型页面。 此页显示注册表中的所有模型。
可在此页中创建新模型。
此外,工作区管理员还可以在此页中设置工作区模型注册表中所有模型的权限。

已注册模型页
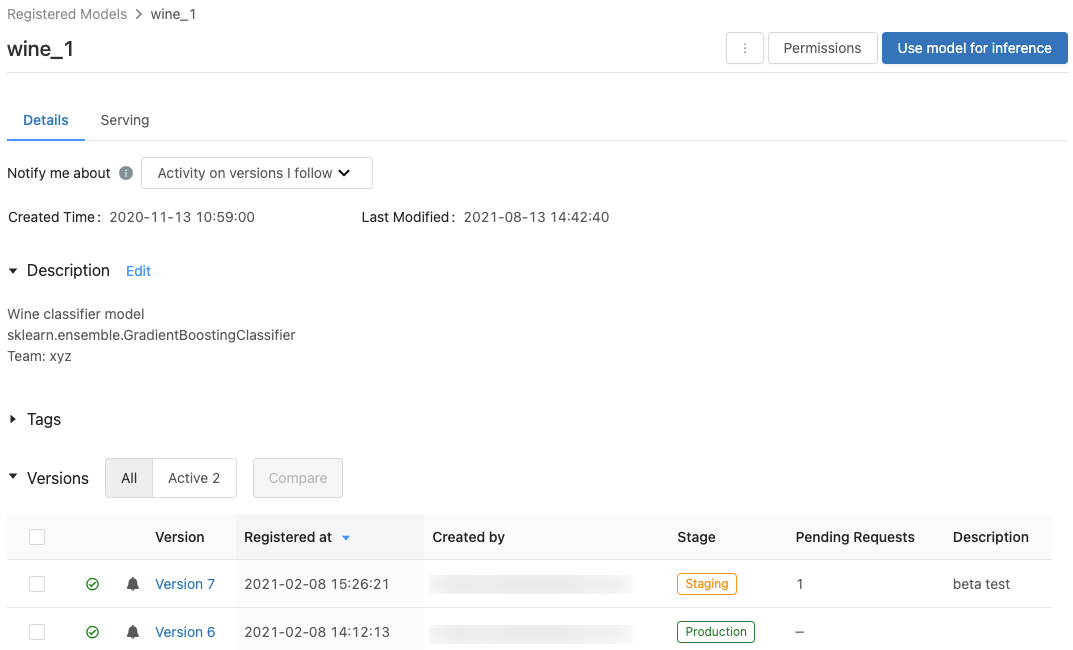
若要显示某个模型的已注册模型页,请在已注册模型页中单击相应的模型名称。 已注册模型页显示有关所选模型的信息,以及一个列出了有关每个模型版本的信息的表格。 在此页面上,你还可以:
模型版本页面
若要查看模型版本页,请执行以下操作之一:
- 单击已注册模型页上的“最新版本”列中的版本名称。
- 在已注册模型页面的“版本”列中单击版本名称。
此页显示有关特定已注册模型版本的信息,并提供指向源运行(为创建该模型而运行的笔记本版本)的链接。 在此页面上,你还可以:
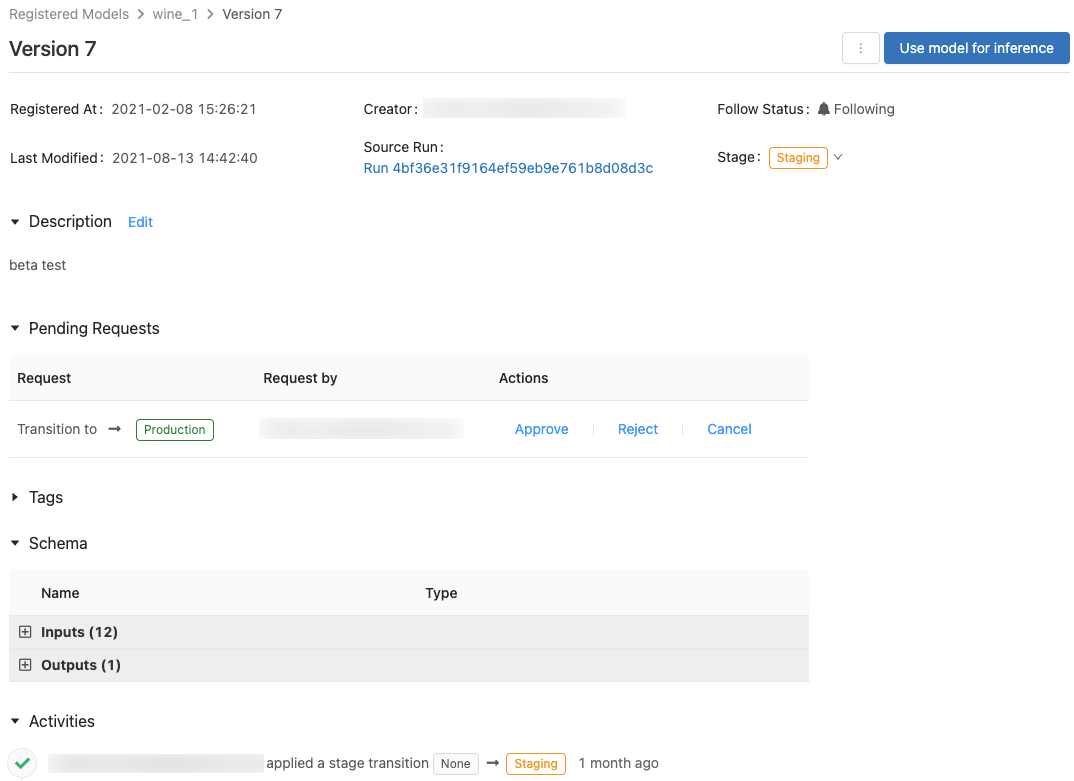
控制对模型的访问
你必须至少具有 CAN MANAGE 权限才能配置模型的权限。 有关模型权限级别的信息,请参阅 MLflow 模型 ACL。 模型版本从其父模型继承权限。 不能为模型版本设置权限。
在边栏中,单击
模型。选择模型名称。
单击“权限”。 此时会打开“权限设置”对话框

在对话框中,选择“选择用户、组或服务主体...”下拉列表,然后选择用户、组或服务主体。
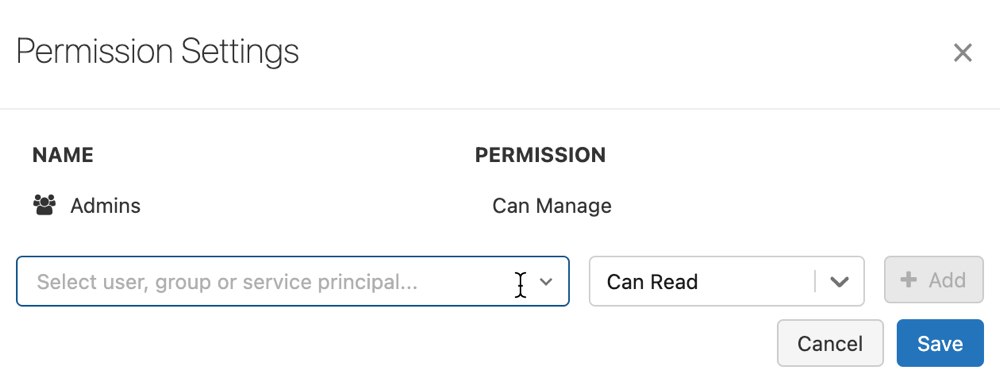
从权限下拉菜单中选择权限。
依次点击“添加”、“保存”。
在注册表范围内具有 CAN MANAGE 权限的工作区管理员和用户可以通过单击“模型”页中的“权限”来设置工作区中所有模型的权限级别。
模型阶段过渡
模型版本具有以下阶段之一:“无”、“暂存”、“生产”或“已存档” 。 “暂存”阶段指模型处于测试和验证阶段,“生产”阶段指模型版本已完成测试或审核流程,并已部署到应用程序,正在获取实时评分 。 “已存档的模型版本视为非活动状态,可以考虑将其删除。” 不同的模型版本可以处于不同的阶段。
具有适当权限的用户可以在不同阶段之间转换模型版本。 如果你有权将模型版本转换到某个特定阶段,可以直接进行转换。 如果你没有相应权限,可以请求阶段转换,有权转换模型版本的用户可以批准、拒绝或取消该请求。
可以使用 UI 或使用 API 转换模型阶段。
使用 UI 转换模型阶段
请按照这些说明转换模型的阶段。
若要显示可用模型阶段和可用选项的列表,请在“模型版本”页中单击“阶段:”旁的下拉菜单,然后请求或选择转换到另一阶段。
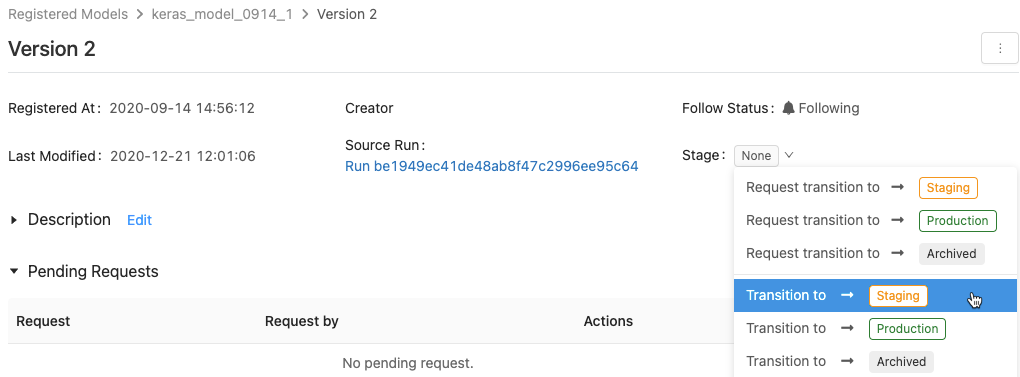
输入可选的注释并单击“确定”。
将模型版本过渡到“生产”阶段
完成测试和验证流程后,可以转换或者请求转换至“生产”阶段。
工作区模型注册表允许每个阶段中存在已注册模型的多个版本。 若希望“生产”阶段中只有一个版本,请单击“将现有‘生产’模型版本转换至‘已存档’阶段”,这样即可将当前处于“生产”阶段的所有模型版本都转换至“已存档”阶段。
批准、拒绝或取消模型版本阶段转换请求
无权转换阶段的用户可以发起阶段转换请求。 请求显示在模型版本页的“待定的请求”部分中:

若要批准、拒绝或取消阶段转换请求,请单击“批准”、“拒绝”或“取消”链接 。
转换请求的创建者也可以取消请求。
查看模型版本活动
若要查看请求、批准、待定和应用于模型版本的所有转换,请转到“活动”部分。 此活动记录提供了模型生命周期的过程信息,供审核或检查使用。
使用 API 转换模型阶段
具有适当权限的用户可以将模型版本转换至新的阶段。
若要将模型版本阶段更新至新阶段,请使用 MLflow 客户端 API transition_model_version_stage() 方法:
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
<stage> 可以为以下值:"Staging"|"staging"、"Archived"|"archived"、"Production"|"production" 和 "None"|"none"。
使用模型进行推理
重要
此功能目前以公共预览版提供。
在工作区模型注册表中注册模型后,可以自动生成笔记本,以使用模型进行批处理推理或流式处理推理。
在已注册的模型页或模型版本页的右上角,单击  。 此时将显示“配置模型推理”对话框,可在其中配置批处理推理、流式处理推理或实时推理。
。 此时将显示“配置模型推理”对话框,可在其中配置批处理推理、流式处理推理或实时推理。
重要
Anaconda Inc. 为 anaconda.org 通道更新了其服务条款。 根据新的服务条款,如果依赖 Anaconda 的打包和分发,则可能需要商业许可证。 有关详细信息,请参阅 Anaconda Commercial Edition 常见问题解答。 您对任何 Anaconda 通道的使用都受其服务条款的约束。
在 v1.18(Databricks Runtime 8.3 ML 或更低版本)之前记录的 MLflow 模型默认以 conda defaults 通道 (https://repo.anaconda.com/pkgs/) 作为依赖项进行记录。 由于此许可证更改,Databricks 已停止使用 defaults 通道来记录使用 MLflow v1.18 或更高版本的模型。 记录的默认通道现在为 conda-forge,它指向社区管理的 https://conda-forge.org/。
如果在 MLflow v1.18 之前记录了一个模型,但没有从模型的 conda 环境中排除 defaults 通道,则该模型可能依赖于你可能没有预期到的 defaults 通道。
若要手动确认模型是否具有此依赖项,可以检查与记录的模型一起打包的 channel 文件中的 conda.yaml 值。 例如,具有 conda.yaml 通道依赖项的模型 defaults 可能如下所示:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
由于 Databricks 无法确定是否允许你根据你与 Anaconda 的关系使用 Anaconda 存储库来与模型交互,因此 Databricks 不会强制要求其客户进行任何更改。 如果允许你根据 Anaconda 的条款通过 Databricks 使用 Anaconda.com 存储库,则你不需要采取任何措施。
若要更改模型环境中使用的通道,可以使用新的 conda.yaml 将模型重新注册到工作区模型注册表。 为此,可以在 conda_env 的 log_model() 参数中指定该通道。
有关 log_model() API 的详细信息,请参阅所用模型风格的 MLflow 文档,例如用于 scikit-learn 的 log_model。
有关 conda.yaml 文件的详细信息,请参阅 MLflow 文档。
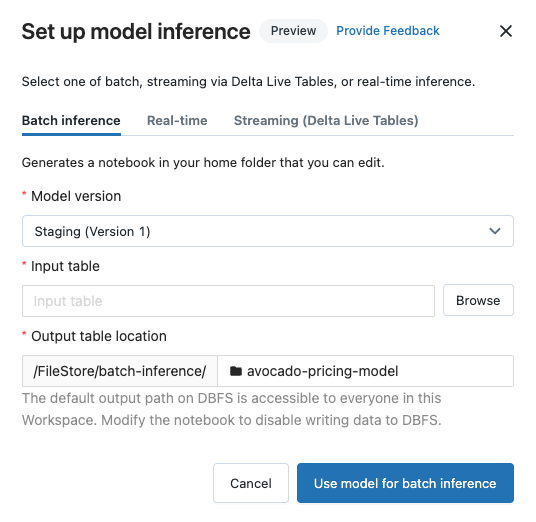
配置批处理推理
按照这些步骤来创建批处理推理笔记本时,笔记本将保存在用户文件夹中,该文件夹位于与模型名称相同的文件夹的 Batch-Inference 文件夹下。 可以根据需要编辑笔记本。
单击“批处理推理”选项卡。
从“模型版本”下拉菜单中,选择要使用的模型版本。 下拉菜单中的前两项是模型的当前生产和暂存版本(如果存在)。 选择这些选项之一时,笔记本会在运行时自动使用生产或暂存版本。 继续开发模型时,无需更新笔记本。
单击“输入表”旁边的“浏览”按钮 。 此时将显示“选择输入数据”对话框。 如有必要,可以在“计算”下拉菜单中更改群集。
注意
对于已启用 Unity Catalog 的工作区,通过“选择输入数据”对话框可从三个级别 中进行选择。
选择包含模型的输入数据的表,然后单击“选择”。 生成的笔记本自动导入此数据并将其发送到模型。 如果数据在输入到模型之前需要进行任何转换,则可以编辑生成的笔记本。
将预测保存在目录
dbfs:/FileStore/batch-inference的文件夹中。 默认情况下,将预测保存在与模型同名的文件夹中。 每次运行生成的笔记本时,会将新文件写入此目录,并将时间戳追加到该名称。 您还可以选择不包含时间戳,并在之后运行笔记本时覆盖该文件。在生成的笔记本中提供了相关说明。可以通过在“输出表位置”字段中键入新的文件夹名称或者单击文件夹图标并浏览目录来更改用于保存预测内容的文件夹,也可以选择其他文件夹。
若要将预测保存到 Unity Catalog 中的位置,则必须编辑笔记本。 有关演示如何训练使用 Unity Catalog 中的数据的机器学习模型并将结果写回 Unity Catalog 的示例笔记本,请参阅机器学习教程。
使用 Lakeflow Spark 声明性管道配置流式推理
按照这些步骤来创建流式处理推理笔记本时,笔记本将保存在用户文件夹中,该文件夹位于与模型名称相同的文件夹的 DLT-Inference 文件夹下。 可以根据需要编辑笔记本。
单击 “流式处理”(Lakeflow Spark 声明性管道) 选项卡。
从“模型版本”下拉菜单中,选择要使用的模型版本。 下拉菜单中的前两项是模型的当前生产和暂存版本(如果存在)。 选择这些选项之一时,笔记本会在运行时自动使用生产或暂存版本。 继续开发模型时,无需更新笔记本。
单击“输入表”旁边的“浏览”按钮 。 此时将显示“选择输入数据”对话框。 如有必要,可以在“计算”下拉菜单中更改群集。
注意
对于已启用 Unity Catalog 的工作区,通过“选择输入数据”对话框可从三个级别 中进行选择。
选择包含模型的输入数据的表,然后单击“选择”。 生成的笔记本将创建一个数据转换,该转换使用输入表作为源,并集成 MLflow PySpark 推理 UDF 来执行模型预测。 如果在应用模型之前或之后数据需要进行任何其他转换,你可以编辑生成的笔记本。
提供 Lakeflow Spark 声明性管道的输出名称。 该笔记本将创建具有给定名称的实时表,并使用它来存储模型预测。 可以根据需要修改生成的笔记本以自定义目标数据集 - 例如:将流式处理实时表定义为输出,添加架构信息或数据质量约束。
然后,可以使用此笔记本创建新管道,或者将其作为其他笔记本库添加到现有管道。
提供反馈
此功能处于预览阶段,我们很乐意收到你的反馈。 若要提供反馈,请单击“配置模型推理”对话框中的 Provide Feedback。
比较模型版本
可以比较工作区模型注册表中的模型版本。
在已注册的模型页上,通过单击模型版本左侧的复选框来选择两个或更多个模型版本。
单击“比较”。
此时将出现“比较
<N>个版本”屏幕,其中显示了所选模型版本的参数、架构和指标的比较表格。 在屏幕底部,可以选择绘图类型(散点图、等高线图或平行坐标图)以及要绘制的参数或指标。
控制通知首选项
你可配置工作区模型注册表,使其就已注册的模型和你指定的模型版本上的活动向你发送电子邮件通知。
在已注册的模型页面上,“通知内容”菜单显示 3 个选项:
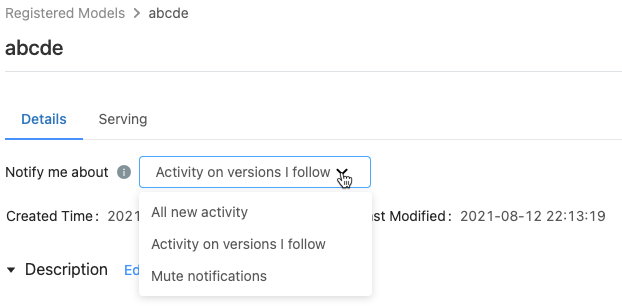
- 所有新活动:就此模型的所有模型版本上的活动发送电子邮件通知。 如果你创建了已注册的模型,那么则默认采用此设置。
- 我关注的版本上的活动:仅就你关注的模型版本发送电子邮件通知。 如果选择此设置,你将就你关注的所有模型版本接收通知;你无法针对特定模型版本关闭通知。
- 将通知静音:不就此注册的模型上的活动发送电子邮件通知。
以下事件会触发电子邮件通知:
- 创建新的模型版本
- 请求阶段转换
- 阶段转换
- 新注释
执行以下任一操作时,你会自动订阅模型通知:
- 对该模型版本进行注释
- 转换模型版本的阶段
- 发出模型阶段转换请求
若要查看你是否在关注某一模型版本,请查看模型版本页上的“关注状态”字段,或者查看已注册的模型页面上的模型版本表格。
关闭所有电子邮件通知
可在“用户设置”菜单的“工作区模型注册表设置”选项卡中关闭电子邮件通知:
单击 Azure Databricks 工作区右上角的用户名,然后从下拉菜单中选择“设置”。
在“设置”边栏中,选择“通知”。
关闭“模型注册表电子邮件通知”。
帐户管理员可在管理员设置页中为整个组织关闭电子邮件通知。
发送的电子邮件数上限
工作区模型注册表限制了每天就每个活动发送给每位用户的电子邮件数量。 例如,如果你在某一天就为注册的模型创建的新模型版本收到了 20 封电子邮件,工作区模型注册表会发送一封电子邮件,指出已达到每日上限且要等待第二天才会发送其他关于该事件的电子邮件。
若要调高允许的电子邮件数上限,请联系你的 Azure Databricks 帐户团队。
Webhook
重要
此功能目前以公共预览版提供。
使用 Webhook 可以侦听工作区模型注册表事件,使集成能够自动触发操作。 可以使用 Webhook 自动执行机器学习管道并将其与现有 CI/CD 工具和工作流集成。 例如,可以在创建新的模型版本时触发 CI 生成,或者在每次请求将模型过渡到生产版本时通过 Slack 来通知团队成员。
对模型或模型版本进行批注
可以通过对模型或模型版本进行批注来提供与其相关的信息。 例如,你可能想提供有关所用方法和算法的相关问题或信息的概述性介绍。
使用 UI 对模型或模型版本进行批注
Azure Databricks UI 提供了用于批注模型和模型版本的多种方法。 可以使用说明或注释添加文本信息,还可以添加可搜索的键值标记。 说明和标记适用于模型和模型版本,注释仅适用于模型版本。
- 说明的目的是提供模型的相关信息。
- 注释使用户可就某模型版本上的活动进行持续讨论。
- 使用标记可以自定义模型元数据,以便更轻松地查找特定模型。
为模型或模型版本添加或更新说明
在编辑窗口中输入或编辑说明。
单击“保存”以保存更改,或单击“取消”以关闭窗口。
输入的模型版本说明将显示在已注册模型页上的表的“说明”列中。 该列最多可显示 32 个字符或一行文本,以较短者为准。
为模型版本添加注释
在模型版本页面向下滚动,然后单击“活动”旁边的向下箭头。
在编辑窗口键入你的注释,然后单击“添加注释”。
为模型或模型版本添加标记
 (如果尚未打开)。 此时将显示标记表。
(如果尚未打开)。 此时将显示标记表。
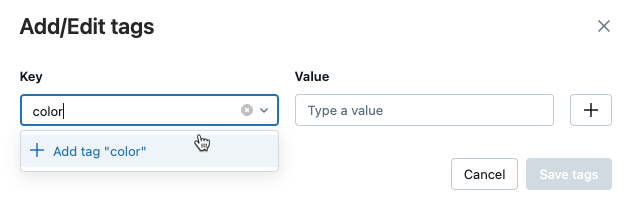
编辑或者删除模型或模型版本的标记
若要编辑或删除现有标记,请使用“操作”列中的图标。
使用 API 对模型版本进行批注
若要更新模型版本说明,请使用 MLflow 客户端 API update_model_version() 方法:
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
若要设置或更新已注册模型或模型版本的标记,请使用 MLflow 客户端 API set_registered_model_tag() 或 set_model_version_tag() 方法:
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
重命名模型(仅 API)
若要重命名已注册模型,请使用 MLflow 客户端 API rename_registered_model() 方法:
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
注意
仅当已注册模型没有任何版本或所有版本都处于“无”或“已存档”阶段时,才能重命名该模型。
搜索模型
可以使用 UI 或 API 搜索工作区模型注册表中的模型。
注意
搜索模型时,仅返回你至少具有“CAN READ”权限的模型。
使用 UI 搜索模型
若要显示已注册的模型,请单击边栏中的“![]() 模型”。
模型”。
若要搜索特定模型,请在搜索框中输入文本。 可以输入模型的名称或名称的任何部分:
还可以按标记进行搜索。 按以下格式输入标记:tags.<key>=<value>。 若要搜索多个标记,请使用 AND 运算符。
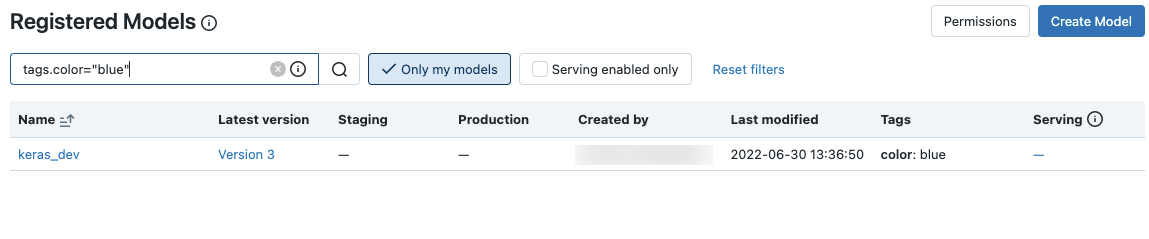
可以使用 MLflow 搜索语法搜索模型名称和标记。 例如:

使用 API 搜索模型
可以使用 MLflow search_registered_models() 方法在工作区模型注册表中搜索已注册的模型。
如果已在模型上设置标记,也可以使用 search_registered_models() 按这些标记进行搜索。
import mlflow
from pprint import pprint
print(f"Find registered models with a specific tag value")
for m in mlflow.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
还可以使用 MLflow search_model_versions() 方法搜索特定模型名称并列出其版本详细信息:
import mlflow
from pprint import pprint
[pprint(mv) for mv in mlflow.search_model_versions("name='<model-name>'")]
输出:
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
删除模型或模型版本
可以使用 UI 或 API 删除模型。
使用 UI 删除模型版本或模型
警告
不能撤消此操作。 可以将模型版本转换到“已存档”阶段,而无需在注册表中删除它。 删除某一模型时,将删除工作区模型注册表存储的所有模型项目以及与该已注册模型关联的所有元数据。
注意
只能删除处于“无”或“已存档”阶段的模型和模型版本。 如果某个已注册模型具有处于“暂存”或“生产”阶段的版本,需要将这些版本转换为“无”或“已存档”阶段,然后才能删除该模型。
删除模型版本:
在边栏中,单击
模型。单击模型名称。
单击模型版本。
单击烤肉串菜单
 在屏幕右上角,然后从下拉菜单中选择“ 删除 ”。
在屏幕右上角,然后从下拉菜单中选择“ 删除 ”。
删除模型:
在边栏中,单击
模型。单击模型名称。
单击烤肉串菜单
在屏幕右上角,然后从下拉菜单中选择“ 删除 ”。
使用 API 删除模型版本或模型
警告
不能撤消此操作。 可以将模型版本转换到“已存档”阶段,而无需在注册表中删除它。 删除某一模型时,将删除工作区模型注册表存储的所有模型项目以及与该已注册模型关联的所有元数据。
注意
只能删除处于“无”或“已存档”阶段的模型和模型版本。 如果某个已注册模型具有处于“暂存”或“生产”阶段的版本,需要将这些版本转换为“无”或“已存档”阶段,然后才能删除该模型。
删除模型版本
若要删除模型版本,请使用 MLflow 客户端 API delete_model_version() 方法:
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
删除模型
若要删除模型,请使用 MLflow 客户端 API delete_registered_model() 方法:
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
跨工作区共享模型
Databricks 建议使用 Unity Catalog 中的模型在不同工作区之间共享模型。 Unity Catalog 原生支持跨工作区模型访问、治理和审核日志记录。
不过,如果使用的是工作区模型注册表,则也可以进行一些设置,使用在多个工作区之间共享模型。 例如,你可以在自己的工作区中开发和记录一个模型,然后使用远程工作区模型注册表从另一个工作区访问该模型。 此特性非常适合多个团队共享模型访问权限的情况。 可以创建多个工作区,并在这些环境中使用和管理模型。
在工作区之间复制 MLflow 对象
若要将 MLflow 对象导入或导出 Azure Databricks 工作区,可以使用社区驱动的开源项目 MLflow Export-Import 在工作区之间迁移 MLflow 试验、模型和运行。
借助这些工具,你可以:
- 与同一或另一跟踪服务器中的其他数据科学家共享和协作。 例如,可以将另一个用户的试验克隆到你的工作区。
- 将模型从一个工作区复制到另一个工作区,例如从开发工作区复制到生产工作区。
- 将 MLflow 试验和运行从本地跟踪服务器复制到 Databricks 工作区。
- 将任务关键型试验和模型备份到另一个 Databricks 工作区。
示例
此示例演示如何使用工作区模型注册表生成机器学习应用程序。