这些功能和Azure Databricks平台改进于 2025 年 1 月发布。
注释
在大多数情况下,下面列出的发布日期和内容仅对应于Azure公有云的实际部署。
本文提供 Azure 公有云上的 Azure Databricks 服务演进历程供您参考,其内容可能与由世纪互联运营的 Azure 中的实际部署不一致。
注释
发布过程分阶段进行。 Azure Databricks帐户在初始发布日期后的一周或更多时间后可能不会更新。
Azure Databricks的其他端口
2025 年 1 月 31 日
网络安全组现在需要端口 3306 和 8443-8451 才能从启用了 vnet 注入的工作区对Azure Databricks服务进行出站访问。 请参阅在您的 Azure 虚拟网络中部署 Azure Databricks(VNet 注入)。
状态存储读取器现已正式发布
2025 年 1 月 31 日
就专用的和非隔离的访问模式来说,对查询结构化流式处理状态数据和元数据功能的支持现已在 Databricks Runtime 14.3 LTS 及更高版本中正式发布。 请参阅读取结构化流式处理状态信息。
现在可以在目录或架构级别启用预测优化
2025 年 1 月 31 日
现在可以在目录或架构级别启用预测优化,而无需先在帐户级别启用预测优化。
现在支持对大型表的完整数据集进行筛选
2025 年 1 月 30 日
筛选大表中截断的数据(输出大于 2MB 或包含超过 10,000 行),现在可以选择将筛选器应用于整个数据集。 请参阅筛选结果。
Meta Llama 3.1 405B 模型系列已停止对基础模型微调的支持
2025 年 1 月 30 日
Meta Llama 3.1 405B 模型系列已停止对基础模型微调的支持。
将 AI 代理工具连接到外部服务(公共预览版)
2025 年 1 月 29 日
AI 代理工具现在可以使用 HTTP 请求连接到 Slack、Google Calendar 或任何具有 API 的服务的外部应用程序。 代理可以使用外部连接的工具自动执行任务、发送消息以及从第三方平台检索数据。
DLT 现在支持将内容发布到多个架构和目录中的表格
2025 年 1 月 27 日 - 2025 年 2 月 5 日
默认情况下,在 DLT 中创建的新管道现在支持在多个目录和架构中创建和更新具体化视图和流式处理表。
管道配置的新默认行为要求用户指定目标架构,该架构将成为管道的默认架构。 不再需要 LIVE 虚拟架构和关联的语法。 有关更多详细信息,请参阅以下内容:
Databricks Runtime 16.2 (Beta)
2025 年 1 月 27 日
Databricks Runtime 16.2 和 Databricks Runtime 16.2 ML 现已作为 Beta 版本提供。
请参阅 Databricks Runtime 16.2 (EoS) 和 Databricks Runtime 16.2 for 机器学习 (EoS)。
评论现在支持电子邮件通知和 @ 提及功能
2025 年 1 月 25 日
现在,您可以直接在评论中通过键入“@”并输入用户名来提及用户。 用户将收到有关评论活动的电子邮件通知。 请参阅 代码注释。
调整字号的快捷方式
2025 年 1 月 25 日
现在可以使用快捷方式快速调整笔记本、文件和 SQL 编辑器中的字号。 将 Alt + 和 Alt - 用于 Windows/Linux,或者将 Opt + 和 Opt - 用于 macOS。
还有一个用于控制编辑器字号的开发人员设置。 导航到 设置 > 开发者选项 > 编辑器字体大小 并选择字体大小。
OAuth 令牌联合身份验证现以公共预览版提供
2025 年 1 月 24 日
现在,OAuth 令牌联合功能已在公共预览版中向帐户管理员开放。
Databricks OAuth 令牌联盟允许您使用来自标识提供者(IdP)的令牌安全地访问 Databricks API。 OAuth 令牌联合机制消除了管理 Databricks 机密的需求,例如个人访问令牌和 Databricks OAuth 客户端机密。
除非 Databricks 帐户管理员对策略进行了修改,否则不会对当前标识配置和权限进行更改。 此功能可应用于整个帐户或特定服务主体,这为管理员管理对 Databricks 工作区资源的访问权限提供了灵活性。
有关使用 Databricks OAuth 令牌联合来授权访问工作区资源的更多详细信息,请参阅 使用 OAuth 令牌联合验证对 Azure Databricks 的访问权限。
注释
Microsoft Azure用户还可以使用 MS Entra 令牌安全地使用 Azure Databricks CLI 命令和 API 调用。
使用拖放导入工作区文件
2025 年 1 月 24 日
现在可以拖放文件和文件夹,将其导入工作区。 拖放适用于主文件浏览器页面和工作区文件浏览器端面板,可在笔记本、查询和文件编辑器中使用。 请参阅导入文件。
Meta Llama 3.3 现在支持使用基础模型 API 的 AI 函数
2025 年 1 月 24 日
使用基础模型 API 的 AI 函数现在由 Meta Llama 3.3 70B Instruct 提供支持,用于聊天任务。
笔记本输出改进
2025 年 1 月 23 日
对笔记本输出体验进行了以下改进:
- Is one of 筛选:在结果表中,现在可以使用 Is one of 来筛选列,然后选择要针对其进行筛选的值。 为此,请单击列旁边的菜单,然后单击“筛选器”。 将打开筛选器模式,以便添加要筛选的条件。 若要了解有关筛选结果的详细信息,请参阅 筛选结果。
- 结果表复制为: 现在可以将结果表复制为 CSV、TSV 或 Markdown。 选择要复制的数据,然后右键单击,选择 “复制方式”,然后选择所需的格式。 结果复制到剪贴板。 请参阅将数据复制到剪贴板。
- 下载命名:下载单元格的结果时,下载名称现在与笔记本名称一致。 请参阅下载结果。
更快的笔记本加载时间
2025 年 1 月 23 日
首次打开笔记本时,99 单元格笔记本的初始加载速度现在最多快 26%,10 单元笔记本最多快 6%。
现在支持将笔记本作为工作区文件
2025 年 1 月 23 日
现在,Databricks Runtime 16.2 及更高版本以及无服务器环境 2 及更高版本支持笔记本作为工作区文件。 现在可以像编写、读取和删除任何其他文件一样以编程方式写入、读取和删除笔记本。 这允许从工作区文件系统的任何位置与笔记本进行编程交互。 有关详细信息,请参阅 以编程方式创建、更新和删除文件和目录。
连续作业中的失败任务现在会自动重试
2025 年 1 月 22 日
此版本包含对 Databricks 工作的更新,改进了对连续作业失败的处理。 进行此更改后,任务会以连续作业的方式运行,在运行失败时会自动重试。 任务运行会重试,延迟呈指数级增加,直到达到允许的最大重试次数。 请参阅 连续作业的失败处理。
笔记本:Databricks Assistant 聊天历史记录仅对发起对话的用户可见
2025 年 1 月 22 日
在笔记本中,Databricks 助手聊天历史记录仅适用于启动聊天的用户。
统计信息收集现在通过预测优化实现自动化
2025 年 1 月 22 日至 4 月 30 日
预测优化现在会在写入托管表和完成自动维护作业期间自动计算 Unity Catalog 托管表的统计信息。
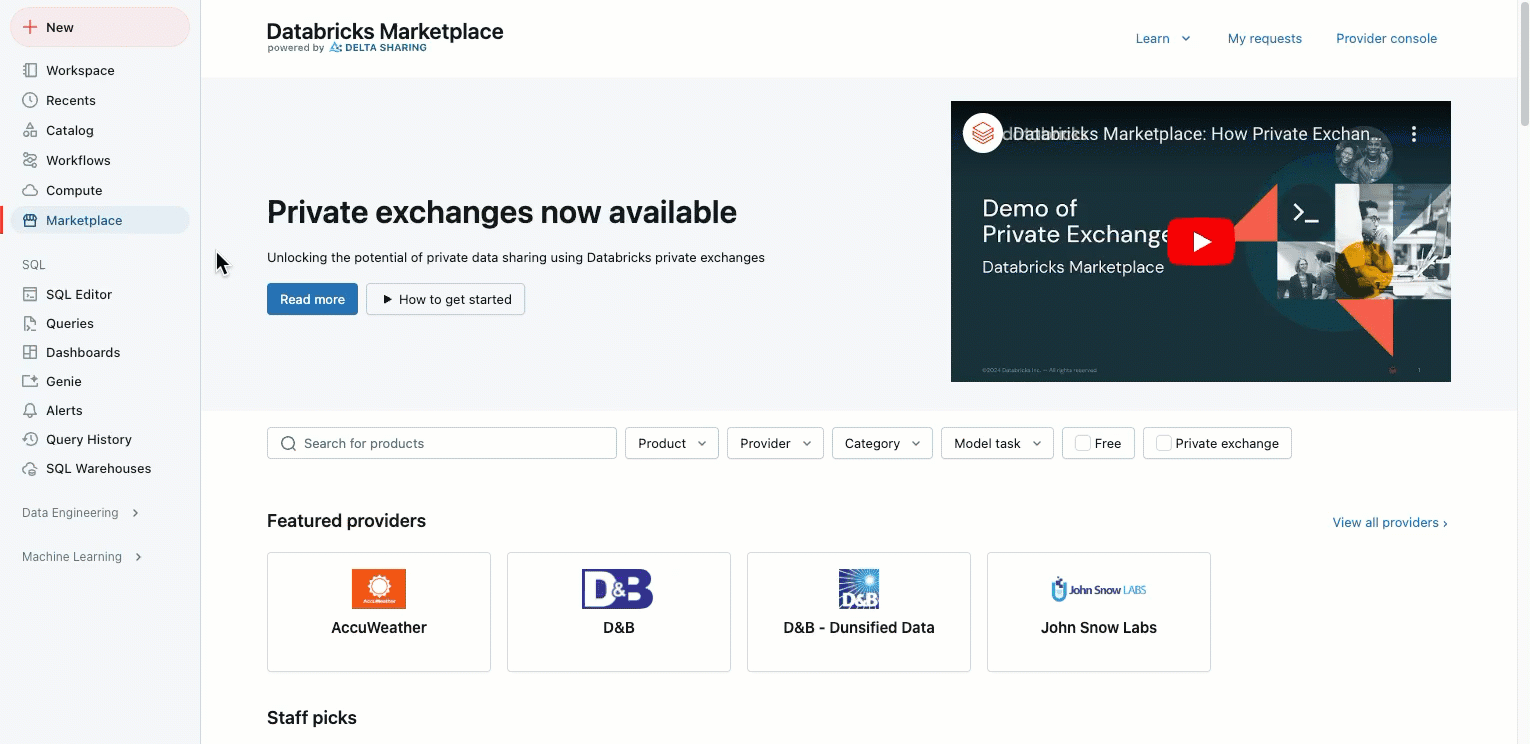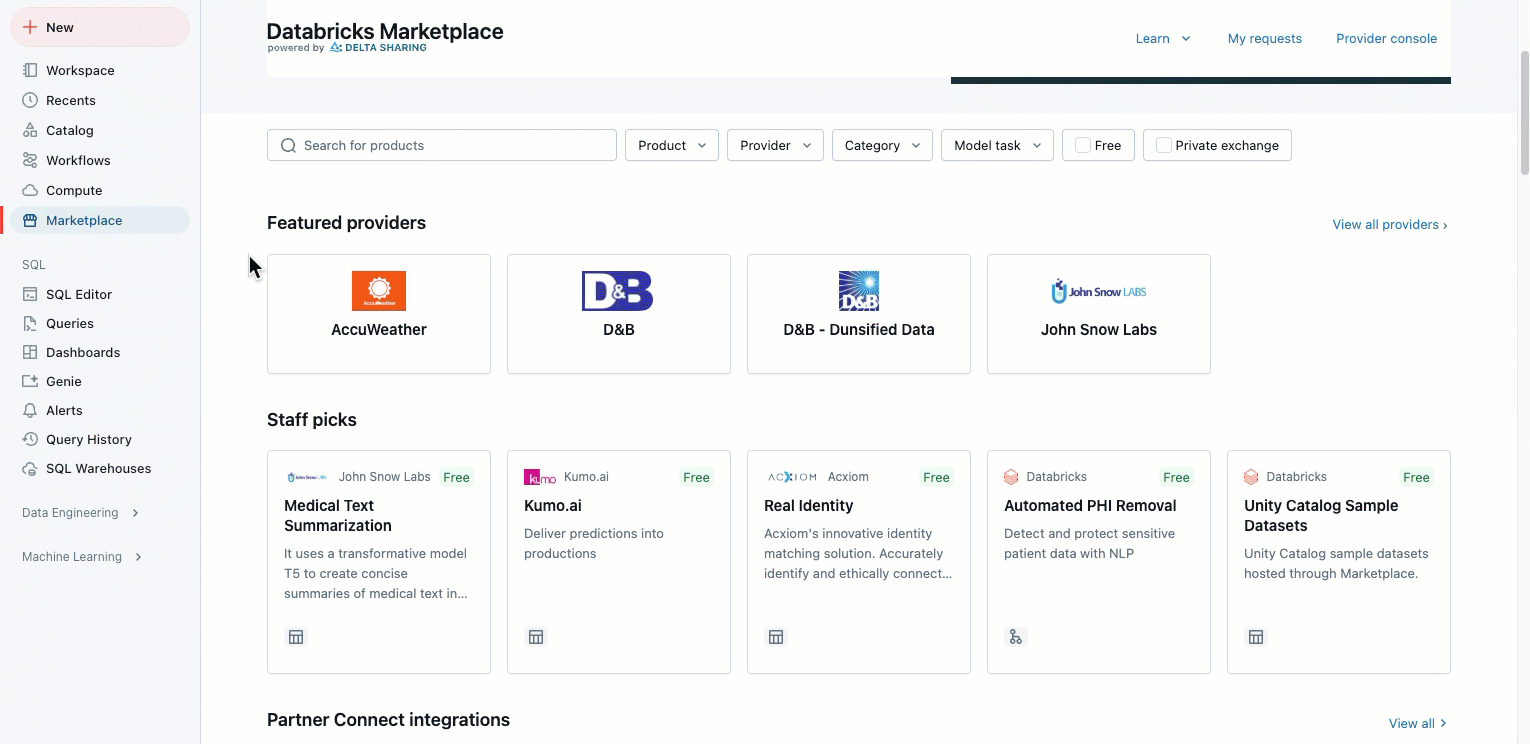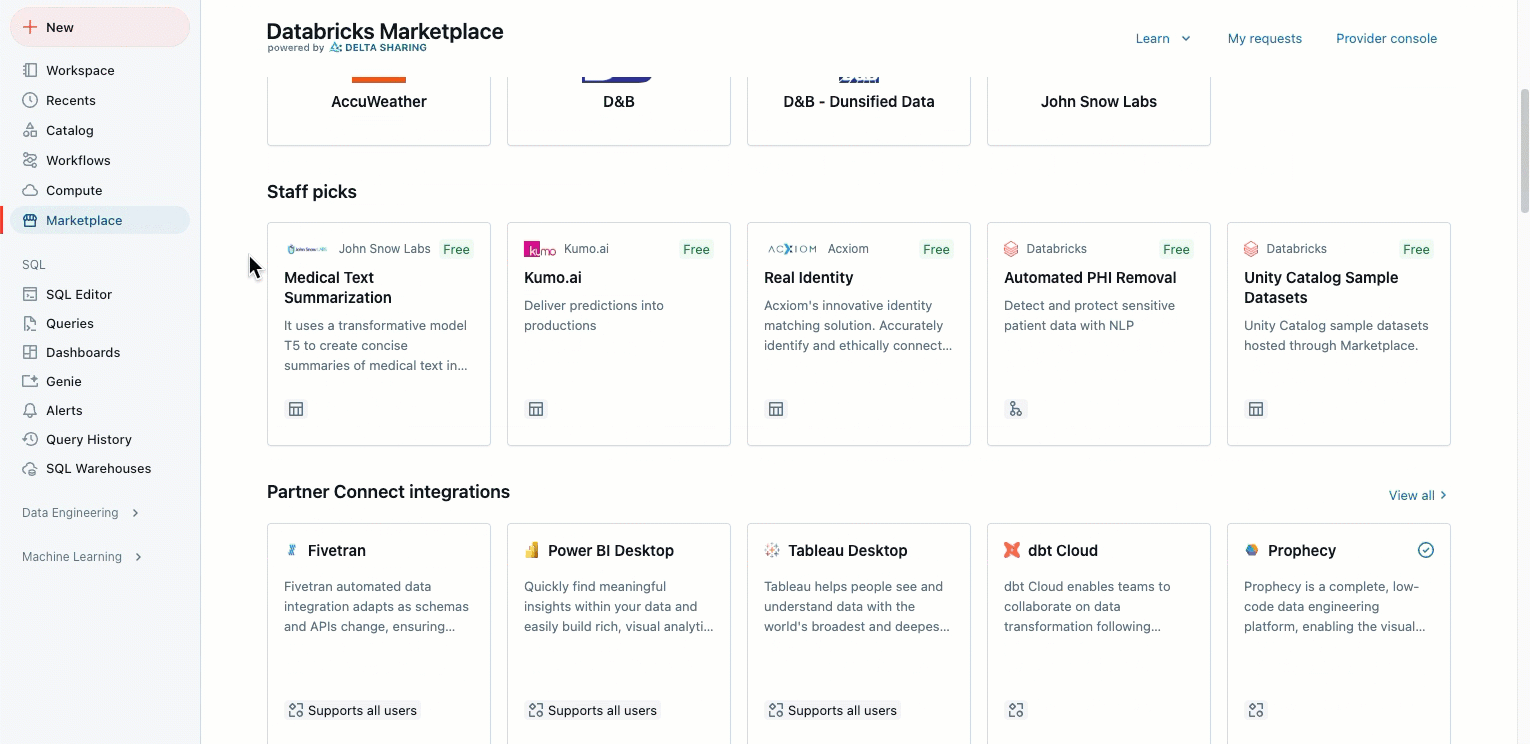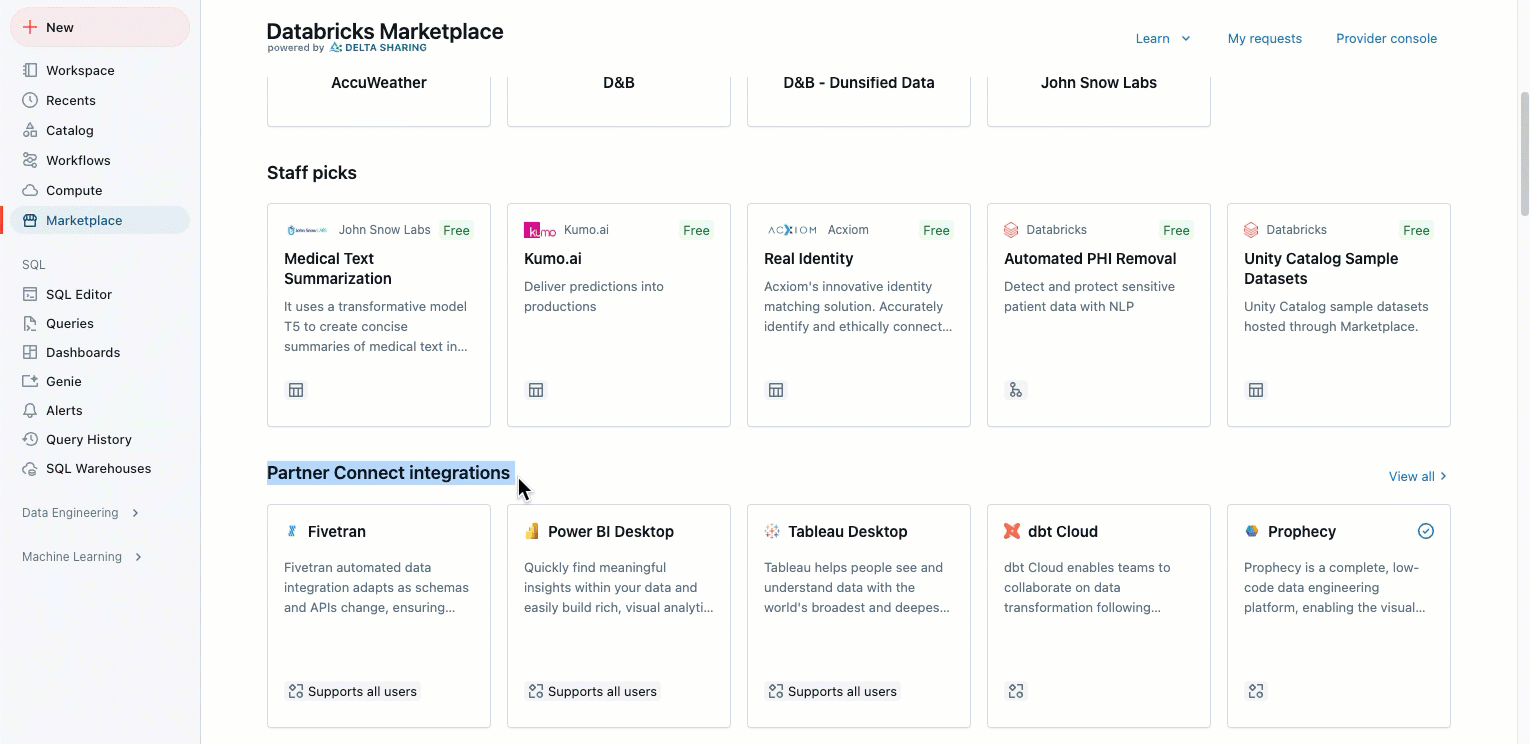
Databricks 市场和 Partner Connect UI 更新
2025 年 1 月 21 日
通过将 Partner Connect 和 Marketplace 合并到一个单独的 Marketplace 链接中,我们简化了侧边栏。 新的“市场”链接位于边栏上,便于访问。
EXPLAIN 现在显示查询规划中使用的统计信息
2025 年 1 月 20 日
在 Databricks Runtime 16.0 及更高版本中,EXPLAIN 命令的输出列出了缺少、部分和完整统计信息的引用表。请参阅 EXPLAIN 命令。
Databricks JDBC 驱动程序 2.7.1
2025 年 1 月 16 日
Databricks JDBC 驱动程序 版本 2.7.1 现在可从 JDBC 驱动程序下载页下载。
此版本包括以下增强功能和新功能:
- 添加了一个新的
OAuthEnabledIPAddressRanges属性,允许客户端重写默认的 OAuth 回调端口,从而在具有网络端口限制的环境中促进 OAuth 令牌获取。 - 刷新令牌的支持功能现已推出。 这使驱动程序能够使用
Auth_RefreshToken属性自动刷新身份验证令牌。 - 添加了对将系统受信任的存储与新的
UseSystemTrustStore属性配合使用的支持。 启用时(UseSystemTrustStore=1)驱动程序使用来自系统受信任存储的证书验证连接。 - 添加了
UseServerSSLConfigsForOAuthEndPoint属性,当它被启用时,允许客户端共享驱动程序的 OAuth 终结点 SSL 配置。 - BASIC 身份验证现在默认处于禁用状态。 若要重新启用它,请将
allowBasicAuthentication属性设置为 1。
此版本解决了以下问题:
- 将 IBM JRE 与箭头结果集序列化功能结合使用时,Unicode 字符现已得到正确处理。
- 现在返回错误代码 401 的完整错误消息和原因。
- 云提取下载处理程序现在在完成后发布。
- 使用 DataSource 类创建连接时,心跳线程不再发生泄漏。
- 已解决驱动程序日志中潜在的
OAuth2Secret泄漏问题。 - 驱动程序日志中的查询 ID 不再缺失。
- 使用 OAuth 令牌缓存不再出现标记不匹配问题。
此版本包括升级到多个第三方库以解决漏洞:
- arrow-memory-core 17.0.0(以前为 14.0.2)
- arrow-vector 17.0.0 (以前为 14.0.2)
- arrow-format 17.0.0(之前的版本为 14.0.2)
- arrow-memory-netty 17.0.0 (以前为 14.0.2)
- arrow-memory-unsafe 17.0.0(以前为 14.0.2)
- commons-codec 1.17.0 (以前为 1.15)
- flatbuffers-java 24.3.25 (以前为 23.5.26)
- jackson-annotations-2.17.1 (以前为 2.16.0)
- jackson-core-2.17.1 (以前为 2.16.0)
- jackson-databind-2.17.1 (以前为 2.16.0)
- jackson-datatype-jsr310-2.17.1 (以前为 2.16.0)
- netty-buffer 4.1.115 (以前为 4.1.100)
- netty-common 4.1.115 (以前为 4.1.100)
有关完整配置信息,请参阅随驱动程序下载包一起安装的 Databricks JDBC 驱动程序指南 。
Lakehouse Federation 支持 Teradata(公共预览版)
2025 年 1 月 15 日
现在可以对 Teradata 管理的数据运行联合查询。 请参阅在 Teradata上运行联合查询。
databricks-agents SDK 0.14.0 版本:自定义评估指标
2025 年 1 月 14 日
借助 databricks-agents==0.14.0,马赛克 AI 代理评估现在支持自定义指标,允许用户定义根据特定生成 AI 业务用例定制的评估指标。
此版本还添加了对以下项的支持:
-
ChatAgentharness 中的ChatModel和mlflow.evaluate(model_type='databricks-agent')。 - 通过
mlflow.evaluate(model_type='databricks-agent')CLI 进行身份验证后,在 Databricks 笔记本外部使用databricks。 - 支持代理跟踪中的嵌套
RETRIEVAL范围。 - 支持将简单字典数组用作
data的mlflow.evaluate()参数。 - 运行
mlflow.evaluate()时,StdOut 更简单。
AI 网关现在支持预配的吞吐量(公共预览版)
2025 年 1 月 10 日
Mosaic AI Gateway 现在支持在模型服务终结点上预配吞吐量工作负载的基础模型 API。
现在,您可以在使用预定义吞吐量的模型服务终结点上启用以下治理和监视功能:
- 权限和速率限制,用于控制谁有访问权限以及有多少访问权限。
- 载荷日志记录用于使用推理表监视和审核发送到模型 API 的数据。
- 使用情况跟踪,以使用系统表监视终结点上的操作使用情况和相关成本。
- AI 护栏,防止请求和响应中出现不必要的数据和有风险的数据。
- 流量路由,以最大程度地减少部署期间和之后的生产中断。
Databricks Runtime 15.2 系列支持结束
2025 年 1 月 7 日
对 Databricks Runtime 15.2 和适用于 机器学习 的 Databricks Runtime 15.2 的支持已于 1 月 7 日结束。 请参阅 Databricks 支持生命周期。
Databricks Runtime 15.3 系列支持结束
2025 年 1 月 7 日
对 Databricks Runtime 15.3 和 Databricks Runtime 15.3 for 机器学习 的支持已于 1 月 7 日结束。 请参阅 Databricks 支持生命周期。
Meta Llama 2、3 和 Code Llama 模型系列停止对基础模型微调的支持
2025 年 1 月 7 日
以下模型系列已停用,在基础模型微调上不再受支持。
- Meta-Llama-3
- Meta-拉玛-2
- Code Llama