Azure 事件中心的捕获功能会自动捕捉流经事件中心的流式数据,并将其捕获到 Azure Blob 存储 或 Azure Data Lake Storage 帐户中。 若要控制事件中心何时存储数据,可以指定时间或大小间隔。 可以快速启用或设置事件中心捕获功能。 无需管理费用即可运行,并且随 Event Hubs 容量自动扩展。
标准层使用 吞吐量单位,高级层使用 处理单元。 事件中心捕获简化了将数据加载到 Azure 的过程,使你能够专注于数据处理而不是数据捕获。
使用 Event Hubs Capture 在同一数据流上处理实时和批处理管道。 此方法可帮助你构建随着时间推移而增长的解决方案。 如果使用基于批处理的系统并计划稍后添加实时处理,或者想要向现有实时解决方案添加有效的冷路径,事件中心捕获可简化处理流数据的过程。
考虑的要点
不使用托管标识进行身份验证时,目标存储帐户(Blob 存储或 Data Lake Storage)必须与事件中心位于同一订阅中。
事件中心不支持捕获高级 Azure 存储帐户中的事件。
事件中心捕获支持允许块 Blob 的非高级存储帐户。
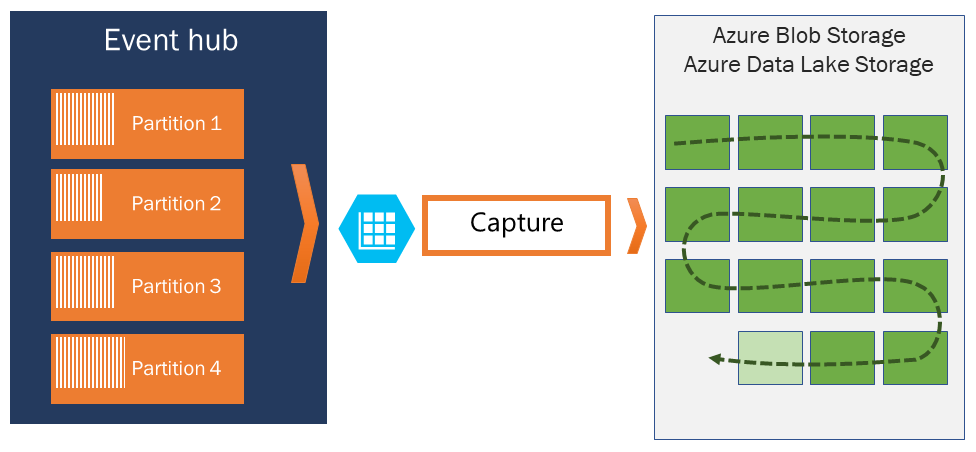
Azure 事件中心捕获的工作原理
事件中心充当遥测入口的时间保留持久缓冲区,类似于分布式日志。 已分区使用者模型可实现可伸缩性。 每个分区是独立的数据段,并单独使用。 此数据在可配置的保留期后被删除,因此事件中心永远不会 太满。
使用事件中心捕获可以指定 Blob 存储帐户和容器或 Data Lake Storage 帐户来存储捕获的数据。 这些帐户可以驻留在事件中心所在的同一区域或另一个区域,这增加了灵活性。
事件中心捕获以 Apache Avro 格式写入捕获的数据,这是一种紧凑、快速的二进制格式,它为丰富的数据结构提供内联架构。 Hadoop 生态系统、Azure 流分析和 Azure 数据工厂使用此格式。 本文后面的部分提供有关使用 Avro 的详细信息。
注意
在 Azure 门户中使用无代码编辑器时,可以使用 Parquet 格式将事件中心中的流数据捕获到 Data Lake Storage 帐户。
若要配置 Data Lake Storage 的事件中心捕获,请遵循与使用 Blob 存储配置事件中心捕获相同的步骤。 有关详细信息,请参阅 配置事件中心数据捕获。
捕获窗口
若要控制捕获,请使用 Event Hubs Capture 设置一个窗口,该窗口采用最小大小和时间配置。 系统应用先到先得策略,这意味着第一个满足的条件(大小或时间)会触发捕获。 例如,如果有 15 分钟、100 兆字节(MB)捕获窗口并每秒发送 1 MB,则大小窗口在时间窗口之前触发。
每个分区独立捕获数据,并在捕获时写入完整的块 Blob。 Blob 名称反映了捕获间隔发生的时间。
存储命名约定遵循以下结构:
{Namespace}/{EventHub}/{PartitionId}/{Year}/{Month}/{Day}/{Hour}/{Minute}/{Second}
日期值用零填充。 以下文件名显示了一个示例:
https://mystorageaccount.blob.core.chinacloudapi.cn/mycontainer/mynamespace/myeventhub/0/2017/12/08/03/03/17.avro
如果 Azure 存储 Blob 暂时不可用,事件中心捕获功能会在事件中心配置的数据保留期内保留您的数据。 存储帐户再次可用后,事件中心捕获会回填数据。
缩放吞吐量单位或处理单位
在事件中心的标准层中, 吞吐量单位 控制流量。 在高级层中, 处理单元 控制流量。 事件中心捕获会直接从内部事件中心存储复制数据,绕过吞吐量单元或处理单元的出口配额,从而为其他处理读取器(如 Stream Analytics 或 Apache Spark)保留出口容量。
配置事件中心捕获后,当您发送第一个事件时,它会自动启动并持续运行。 为了帮助下游系统确认该过程有效,事件中心在无数据可用时写入空文件。 此进程提供了可预测的频率以及可以供给批处理处理器的标记。
设置事件中心捕获
若要在创建事件中心时配置捕获,请使用 Azure 门户或 Azure 资源管理器模板(ARM 模板)。 有关详细信息,请参阅以下文章:
注意
如果为现有事件中心启用捕获功能,该功能将仅捕获打开 后 到达的事件。 它不会捕获激活前存在的事件。
事件中心捕获计费
事件中心高级层包括捕获功能。 对于标准层,Azure 根据命名空间的吞吐量单位数每月对捕获收费。 纵向扩展或缩减吞吐量单位时,事件中心捕获会调整其计数以匹配性能。 这些仪表同步缩放。
Azure 的捕获功能不会消耗出口配额,因为 Azure 将其单独计费。
有关详细信息,请参阅事件中心定价。
与 Azure 事件网格集成
可以创建 Azure 事件网格订阅,其中事件中心命名空间作为其源。 有关如何使用事件中心作为源创建事件网格订阅以及将 Azure Functions 应用作为接收器创建事件网格订阅的详细信息,请参阅 将捕获的事件中心数据迁移到 Azure Synapse Analytics。
浏览捕获的文件
若要了解如何浏览捕获的 Avro 文件,请参阅浏览捕获的 Avro 文件。
作为目标的 Azure 存储帐户
若要在将存储用作捕获目标的事件中心上启用捕获,或更新将存储用作捕获目标的事件中心的属性,用户或服务主体必须具有基于角色的访问控制(RBAC)角色,其中包括在存储帐户范围内分配的以下权限:
Microsoft.Storage/storageAccounts/blobServices/containers/write
Microsoft.Storage/storageAccounts/blobServices/containers/blobs/write
如果没有此权限,将显示以下错误:
Generic: Linked access check failed for capture storage destination <StorageAccount Arm Id>.
User or the application with object id <Object Id> making the request doesn't have the required data plane write permissions.
Please enable Microsoft.Storage/storageAccounts/blobServices/containers/write, Microsoft.Storage/storageAccounts/blobServices/containers/blobs/write permission(s) on above resource for the user or the application and retry.
TrackingId:<ID>, SystemTracker:mynamespace.servicebus.chinacloudapi.cn:myhub, Timestamp:<TimeStamp>
若要解决此问题,请将用户帐户或服务主体添加到 存储 Blob 数据所有者 内置角色,其中包括所需的权限。
相关内容
事件中心捕获提供了将数据引入 Azure 的简单方法。 借助 Data Lake Storage、Azure 数据工厂和 Azure HDInsight,可以使用任何规模的熟悉工具和平台执行批处理和分析。
若要启用此功能,请使用 Azure 门户或 ARM 模板:
有关捕获目标存储帐户的数据冗余选项的详细信息,请参阅 Blob 存储中的可靠性。