了解如何使用 Apache Spark 结构化流式处理从 Apache Kafka on Azure HDInsight 读取数据,然后将数据存储到 Azure Cosmos DB 中。
Azure Cosmos DB 是一种全球分布式多模型数据库。 此示例使用 Azure Cosmos DB for NoSQL 数据库模型。 有关详细信息,请参阅欢迎使用 Azure Cosmos DB 文档。
Spark 结构化流式处理是建立在 Spark SQL 上的流处理引擎。 这允许以与批量计算相同的方式表达针对静态数据的流式计算。 有关结构化流式处理的详细信息,请参阅 Apache.org 上的 Structured Streaming Programming Guide(结构化流式处理编程指南)。
重要
此示例使用 Spark 2.4 on HDInsight 4.0。
本文档中的步骤创建了一个包含 Spark on HDInsight 和 Kafka on HDInsight 群集的 Azure 资源组。 这些群集都位于一个 Azure 虚拟网络中,这样 Spark 群集便可与 Kafka 群集直接通信。
完成本文档中的步骤后,请记得删除这些群集,避免产生额外费用。
创建群集
Apache Kafka on HDInsight 不提供通过公共 Internet 访问 Kafka 中转站的权限。 与 Kafka 对话的任何内容都必须与 Kafka 群集中的节点位于同一 Azure 虚拟网络中。 对于此示例,Kafka 和 Spark 群集都位于 Azure 虚拟网络中。 下图显示通信在群集之间的流动方式:
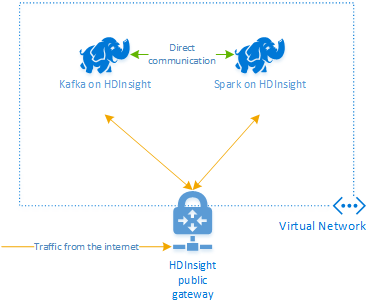
注意
Kafka 服务仅限于虚拟网络内的通信。 通过 Internet 可访问群集上的其他服务,例如 SSH 和 Ambari。 有关可用于 HDInsight 的公共端口的详细信息,请参阅 HDInsight 使用的端口和 URI。
尽管可手动创建 Azure 虚拟网络、Kafka 和 Spark 群集,但使用 Azure 资源管理器模板更简单。 使用以下步骤将 Azure 虚拟网络、Kafka 和 Spark 群集部署到 Azure 订阅。
使用以下按钮登录到 Azure,并在 Azure 门户中打开模板。

Azure 资源管理器模板位于此项目的 GitHub 存储库中 (https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb)。
此模板可创建以下资源:
Kafka on HDInsight 4.0 群集。
Spark on HDInsight 4.0 群集。
包含 HDInsight 群集的 Azure 虚拟网络。 通过模板创建的虚拟网络使用 10.0.0.0/16 地址空间。
Azure Cosmos DB for NoSQL 数据库。
重要
本示例使用的结构化流式处理笔记本需要 Spark on HDInsight 4.0。 如果使用早期版本的 Spark on HDInsight,则使用笔记本时会收到错误消息。
使用以下信息填充“自定义部署”部分中的条目:
属性 值 订阅 选择 Azure 订阅。 资源组 创建一个组或选择有个现有的组。 此组包含 HDInsight 群集。 Azure Cosmos DB 帐户名称 此值用作 Azure Cosmos DB 帐户的名称。 名称只能包含小写字母、数字和连字符 (-)。 它的长度必须介于 3 到 31 个字符之间。 基群集名称 此值将用作 Spark 和 Kafka 群集的基名称。 例如,输入 myhdi 将创建名为 spark-myhdi 的 Spark 群集和名为 kafka-myhdi 的 Kafka 群集。 群集版本 HDInsight 群集版本。 此示例使用 HDInsight 4.0 进行测试,可能不适用于其他群集类型。 群集登录用户名 Spark 和 Kafka 群集的管理员用户名。 群集登录密码 Spark 和 Kafka 群集的管理员用户密码。 SSH 用户名 创建 Spark 和 Kafka 群集的 SSH 用户。 SSH 密码 Spark 和 Kafka 群集的 SSH 用户的密码。 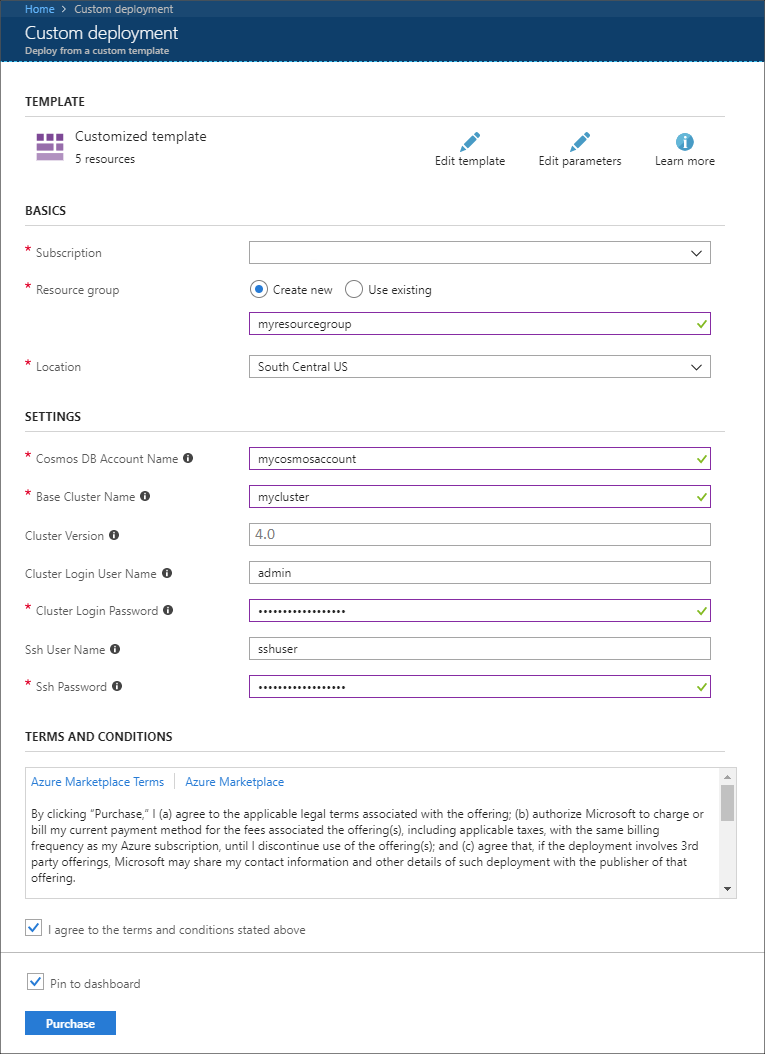
阅读“条款和条件”,并选择“我同意上述条款和条件”。
最后,选择“购买”。 创建群集、虚拟网络和 Azure Cosmos DB 帐户最多可能需要 45 分钟时间。
创建 Azure Cosmos DB 数据库和集合
本文档使用的项目将数据存储在 Azure Cosmos DB 中。 运行代码之前,必须首先在 Azure Cosmos DB 实例中创建数据库和集合。 还必须检索文档终结点,以及用于对 Azure Cosmos DB 的请求进行身份验证的密钥。
可使用 Azure CLI 执行此操作。 以下脚本将创建名为 kafkadata 的数据库和名为 kafkacollection 的集合。 然后,将返回主键。
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
文档终结点和主键信息与以下文本类似:
# endpoint
"https://mycosmosaccount.documents.azure.cn:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
重要
保存终结点和键值,以便用于 Jupyter 笔记本。
获取笔记本
可在 https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb 处查看本文档所描述示例的代码。
上传笔记本
使用下列步骤,将项目中的笔记本上传到 Spark on HDInsight 群集:
在 Web 浏览器中,连接到 Spark 群集上的 Jupyter Notebook。 在下列 URL 中,将
CLUSTERNAME替换为你的 Spark 群集名:https://CLUSTERNAME.azurehdinsight.cn/jupyter出现提示时,输入创建群集时使用的群集登录名(管理员)和密码。
在页面右上角,使用“上传”按钮将“Stream-taxi-data-to-kafka.ipynb”文件上传到群集。 选择“打开”开始上传。
在笔记本列表中找到“Stream-taxi-data-to-kafka.ipynb”项,然后选择其旁边的“上传”按钮。
重复步骤 1-3 加载 Stream-data-from-Kafka-to-Cosmos-DB.ipynb 笔记本。
将出租车数据加载到 Kafka 中
上传文件后,选择“Stream-taxi-data-to-kafka.ipynb”项打开笔记本。 按照笔记本中的步骤将数据加载到 Kafka 中。
使用 Spark 结构化流式处理来处理出租车数据
在 Jupyter Notebook 主页上,选择 Stream-data-from-Kafka-to-Cosmos-DB.ipynb 项。 按照笔记本中的步骤使用 Spark 结构化流式处理将 Kafka 中的数据流式传输到 Azure Cosmos DB。
后续步骤
至此,你已了解如何使用 Apache Spark 结构化流式处理;请参阅下列文档,详细了解如何使用 Apache Spark、Apache Kafka 和 Azure Cosmos DB: