本快速入门将使用 Azure 资源管理器模板(ARM 模板)在 Azure HDInsight 中创建 Apache Hadoop 群集。 Hadoop 是原始的开源框架,适用于对群集上的大数据集进行分布式处理和分析。 Hadoop 生态系统包括相关的软件和实用程序,例如 Apache Hive、Apache HBase、Spark、Kafka 等等。
Azure 资源管理器模板是定义项目基础结构和配置的 JavaScript 对象表示法 (JSON) 文件。 模板使用声明性语法。 你可以在不编写用于创建部署的编程命令序列的情况下,描述预期部署。
目前,HDInsight 附带七个不同的群集类型。 每个群集类型都支持一组不同的组件。 所有群集类型都支持 Hive。 有关 HDInsight 中受支持组件的列表,请参阅 HDInsight 提供的 Hadoop 群集版本中有哪些新功能?
如果你的环境满足先决条件,并且你熟悉如何使用 ARM 模板,请选择“部署到 Azure”按钮。 Azure 门户中会打开模板。

先决条件
如果没有 Azure 订阅,可在开始前创建一个试用帐户。
查看模板
本快速入门中使用的模板来自 Azure 快速启动模板。
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.4.1318.3566",
"templateHash": "4043559473193950792"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterType": {
"type": "string",
"allowedValues": [
"hadoop",
"intractivehive",
"hbase",
"storm",
"spark"
],
"metadata": {
"description": "The type of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The username cannot be admin."
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"HeadNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"WorkerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workdernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"variables": {
"defaultStorageAccount": {
"name": "[uniqueString(resourceGroup().id)]",
"type": "Standard_LRS"
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[variables('defaultStorageAccount').name]",
"location": "[parameters('location')]",
"sku": {
"name": "[variables('defaultStorageAccount').type]"
},
"kind": "StorageV2",
"properties": {}
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"clusterDefinition": {
"kind": "[parameters('clusterType')]",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(concat(reference(resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name)).primaryEndpoints.blob), 'https:', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('HeadNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('WorkerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name)]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
该模板中定义了两个 Azure 资源:
- Microsoft.Storage/storageAccounts:创建 Azure 存储帐户。
- Microsoft.HDInsight/cluster:创建 HDInsight 群集。
部署模板
选择下面的“部署到 Azure”按钮登录到 Azure,并打开 ARM 模板。
输入或选择下列值:
属性 说明 订阅 从下拉列表中选择用于此群集的 Azure 订阅。 资源组 从下拉列表中选择现有资源组,或选择“新建” 。 位置 将使用用于资源组的位置自动填充此值。 群集名称 输入任何全局唯一的名称。 对于此模板,请只使用小写字母和数字。 群集类型 选择“hadoop”。 群集登录用户名 提供用户名,默认值为 admin。群集登录密码 提供密码。 密码长度不得少于 10 个字符,且至少必须包含一个数字、一个大写字母和一个小写字母、一个非字母数字字符( ' ` "字符除外)。SSH 用户名 提供用户名,默认为 sshuser。SSH 密码 提供密码。 某些属性已在模板中硬编码。 可以通过模板配置这些值。 有关这些属性的详细说明,请参阅在 HDInsight 中创建 Apache Hadoop 群集。
注意
提供的值必须唯一,并应遵循命名指南。 模板不会执行验证检查。 如果提供的值已被使用,或不遵循指南,则提交模板后可能会出错。
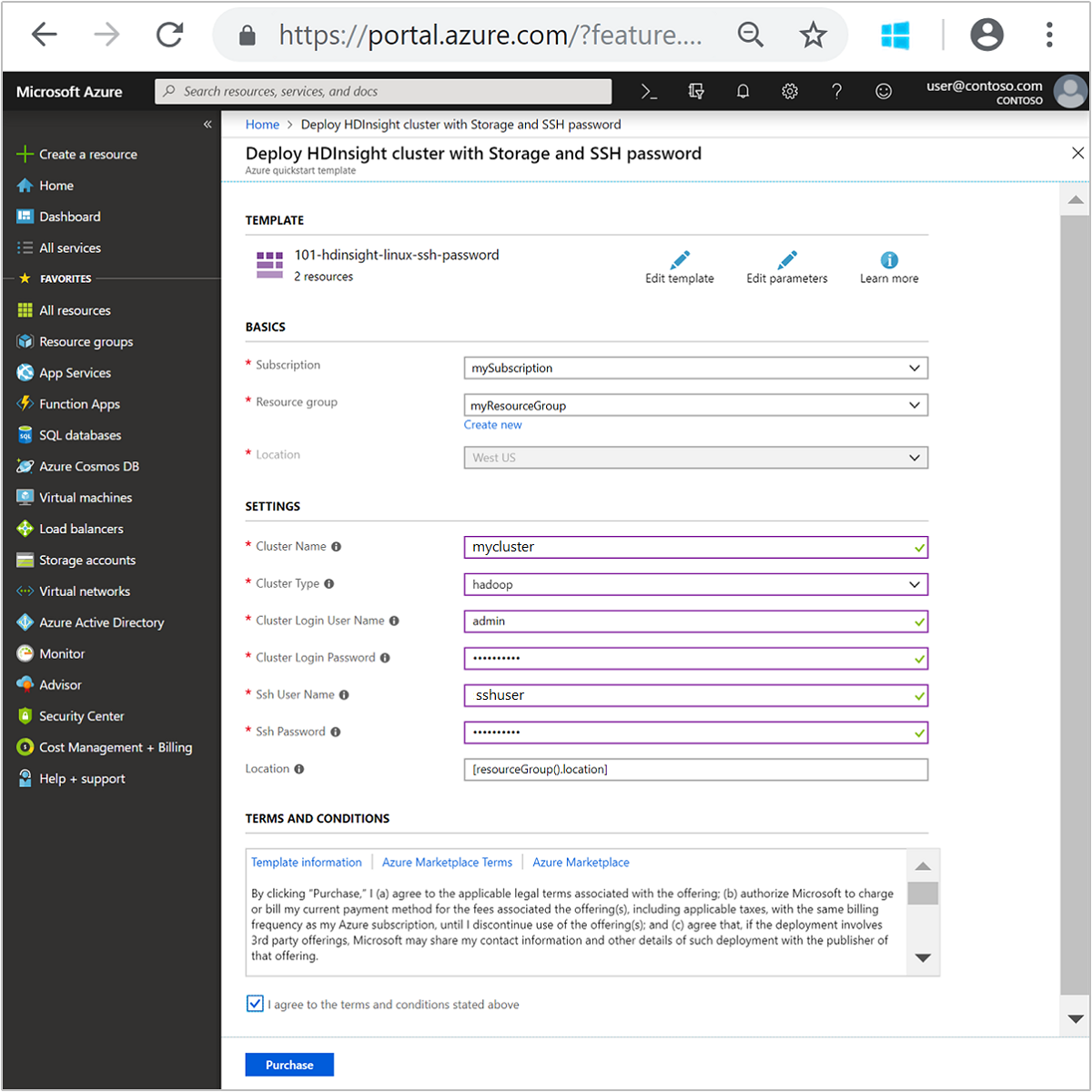
查看“条款和条件”。 接着选择“我同意上述条款和条件”,然后选择“购买” 。 你会收到一则通知,说明正在进行部署。 创建群集大约需要 20 分钟时间。
查看已部署的资源
创建群集后,你会收到“部署成功”通知,通知中附有“转到资源”链接 。 “资源组”页会列出新的 HDInsight 群集以及与该群集关联的默认存储。 每个群集都有一个 Azure Blob 存储帐户和一个 Azure Data Lake Storage Gen2 依赖项。 该帐户称为默认存储帐户。 HDInsight 群集及其默认存储帐户必须共存于同一个 Azure 区域中。 删除群集不会删除存储帐户。
注意
如需其他群集创建方法或要了解本快速入门中使用的属性,请参阅创建 HDInsight 群集。
清理资源
完成本快速入门后,可以删除群集。 有了 HDInsight,便可以将数据存储在 Azure 存储中,因此可以在群集不用时安全地删除群集。 此外,还需要为 HDInsight 群集付费,即使不用也是如此。 由于群集费用数倍于存储空间费用,因此在群集不用时删除群集可以节省费用。
注意
如果立即进行下一教程,了解如何使用 Hadoop on HDInsight 运行 ETL 操作,建议保持群集运行。 这是因为该教程中必须再次创建 Hadoop 群集。 但是,如果不立即学习下一教程,则必须立即删除该群集。
从 Azure 门户导航到群集,然后选择“删除”。
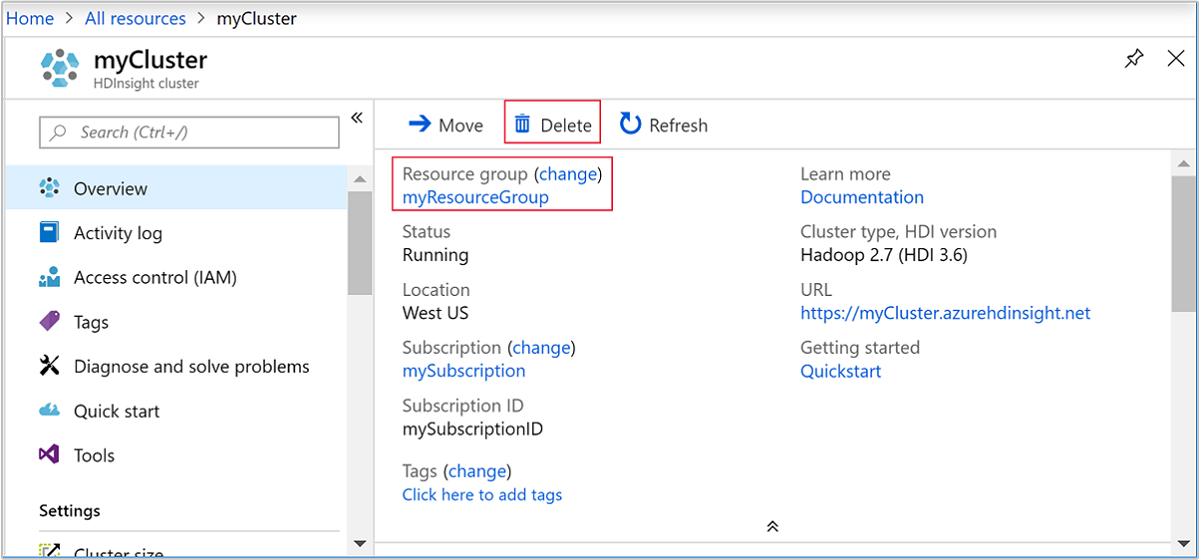
还可以选择资源组名称来打开“资源组”页,然后选择“删除资源组”。 通过删除资源组,可以删除 HDInsight 群集和默认存储帐户。
后续步骤
在本快速入门中,你已了解了如何使用 ARM 模板在 HDInsight 中创建 Apache Hadoop 群集。 下一篇文章将介绍如何使用 Hadoop on HDInsight 执行提取、转换和加载 (ETL) 操作。