Azure HDInsight 的免费“自动缩放”功能可根据客户采用的群集指标和缩放策略自动增加或减少群集中的工作器节点数。 自动缩放功能的工作原理是根据性能指标或纵向扩展和纵向缩减操作定义的计划在预设限制内缩放节点数。
工作原理
自动缩放功能使用两种类型的条件来触发缩放事件:各种群集性能指标的阈值(称为“基于负载的缩放”)和基于时间的触发器(称为“基于计划的缩放”)。 基于负载的缩放会在设置的范围内更改群集中的节点数,以确保获得最佳的 CPU 使用率并尽量降低运行成本。 基于计划的缩放会根据纵向扩展和纵向缩减操作计划更改群集中的节点数。
以下视频概述了自动缩放解决的难题,以及它如何帮助你使用 HDInsight 控制成本。
选择基于负载或基于计划的缩放
可以使用基于计划的缩放:
- 当作业预计按固定计划运行且在可预测的持续时间内运行时,或者当预计在一天中的特定时间内使用率较低时。 例如,在工作时间后、一天工作结束时的测试和开发环境。
可以使用基于负载的缩放:
- 当负载模式全天波动较大且不可预测时。 例如,使用负载模式中的随机波动处理订单数据会根据各种因素而变化。
群集指标
自动缩放会持续监视群集并收集以下指标:
| 指标 | 说明 |
|---|---|
| 总待处理 CPU | 开始执行所有待处理容器所需的核心总数。 |
| 总待处理内存 | 开始执行所有待处理容器所需的总内存(以 MB 为单位)。 |
| 总可用 CPU | 活动工作节点上所有未使用核心的总和。 |
| 总可用内存 | 活动工作节点上未使用内存的总和(以 MB 为单位)。 |
| 每个节点的已使用内存 | 工作节点上的负载。 使用了 10 GB 内存的工作节点的负载被认为比使用了 2 GB 内存的工作节点的负载更大。 |
| 每个节点的应用程序主机数 | 在工作节点上运行的应用程序主机 (AM) 容器的数量。 托管两个 AM 容器的工作节点被认为比托管零个 AM 容器的工作节点更重要。 |
每 60 秒检查一次上述指标。 自动缩放将根据这些指标做出纵向扩展和纵向缩减决策。
有关群集指标的完整列表,请参阅 Microsoft.HDInsight/clusters 支持的指标。
基于负载的缩放条件
检测到以下情况时,自动缩放将发出缩放请求:
| 纵向扩展 | 纵向缩减 |
|---|---|
| 总待处理 CPU 大于总可用 CPU 的时间超过 3-5 分钟。 | 总待处理 CPU 小于总可用 CPU 的时间超过 3-5 分钟。 |
| 总待处理内存大于总可用内存的时间超过 3-5 分钟。 | 总待处理内存小于总可用内存的时间超过 3-5 分钟。 |
对于纵向扩展,自动缩放会发出纵向扩展请求来添加所需数量的节点。 纵向扩展基于的条件是:需要多少新的工作器节点才能满足当前的 CPU 和内存要求。
对于纵向缩减,自动缩放会发出请求来删除一些节点。 纵向缩减基于的条件是:每个节点的应用程序主机 (AM) 容器数。 当前的 CPU 和内存要求。 此服务还会根据当前作业执行情况,检测待删除的节点。 纵向缩减操作首先关闭节点,然后将其从群集中删除。
针对自动缩放的 Ambari DB 大小调整注意事项
建议正确调整 Ambari DB 的大小,以充分利用自动缩放的优势。 客户应使用正确的 DB 层,并将自定义 Ambari DB 用于大型群集。 请参阅数据库和头节点大小调整建议。
群集兼容性
重要
Azure HDInsight 自动缩放功能于 2019 年 11 月 7 日正式发布,适用于 Spark 和 Hadoop 群集,并包含了该功能预览版本中未提供的改进。 如果你在 2019 年 11 月 7 日之前创建了 Spark 群集,并希望在群集上使用自动缩放功能,我们建议创建新群集,并在新群集上enable Autoscale。
用于 HDI 4.0 的 Interactive Query 自动缩放 (LLAP) 于 2020 年 8 月 27 日正式发布。 自动缩放仅适用于 Spark、Hadoop 和 Interactive Query 群集
下表描述了与自动缩放功能兼容的群集类型和版本。
| 版本 | Spark | Hive | Interactive Query | HBase | Kafka |
|---|---|---|---|---|---|
| 没有 ESP 的 HDInsight 5.1 | 是 | 是 | 是* | 否 | 否 |
| 具有 ESP 的 HDInsight 5.1 | 是 | 是 | 是* | 否 | 否 |
注意
只能为基于计划的缩放配置交互式查询群集。 不支持基于负载的自动缩放。
开始
使用基于负载的自动缩放创建群集
若要结合基于负载的缩放启用自动缩放功能,请在创建普通群集的过程中完成以下步骤:
在“配置 + 定价”选项卡上,选中“”复选框。
Enable autoscale在“自动缩放类型”下选择“基于负载”。
为以下属性输入所需的值:
- 适用于工作器节点的初始工作节点数。
- 工作器节点最小数目。
- 工作器节点最大数目。
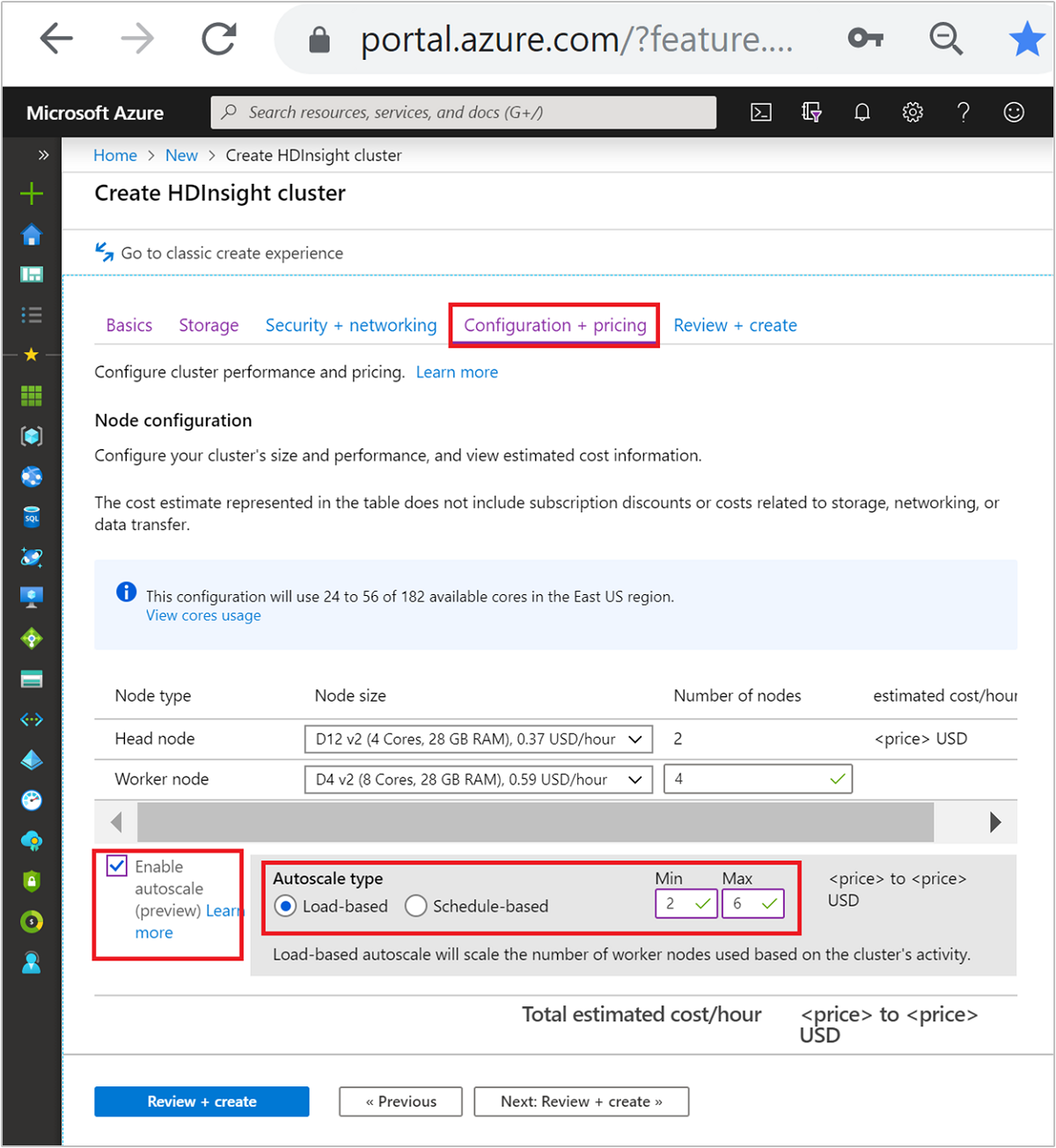
工作节点的初始数量必须介于最小值和最大值之间(含最大值和最小值)。 此值定义创建群集时的群集初始大小。 工作器节点最小数目至少应设置为 3。 将群集缩放成少于三个节点可能导致系统停滞在安全模式下,因为没有进行充分的文件复制。 有关详细信息,请参阅停滞在安全模式下。
使用基于计划的自动缩放创建群集
若要结合基于计划的缩放启用自动缩放功能,请在创建普通群集的过程中完成以下步骤:
在“配置 + 定价”选项卡上,勾选“”复选框。
Enable autoscale输入工作器节点的节点数,以控制纵向扩展群集的限制。
在“自动缩放类型”下选择“基于计划”选项。
选择“配置”以打开“自动缩放配置”窗口。
选择时区,然后单击“+ 添加条件”
选择新条件要应用到的星期日期。
编辑该条件生效的时间,以及群集要缩放到的节点数。
根据需要添加更多条件。
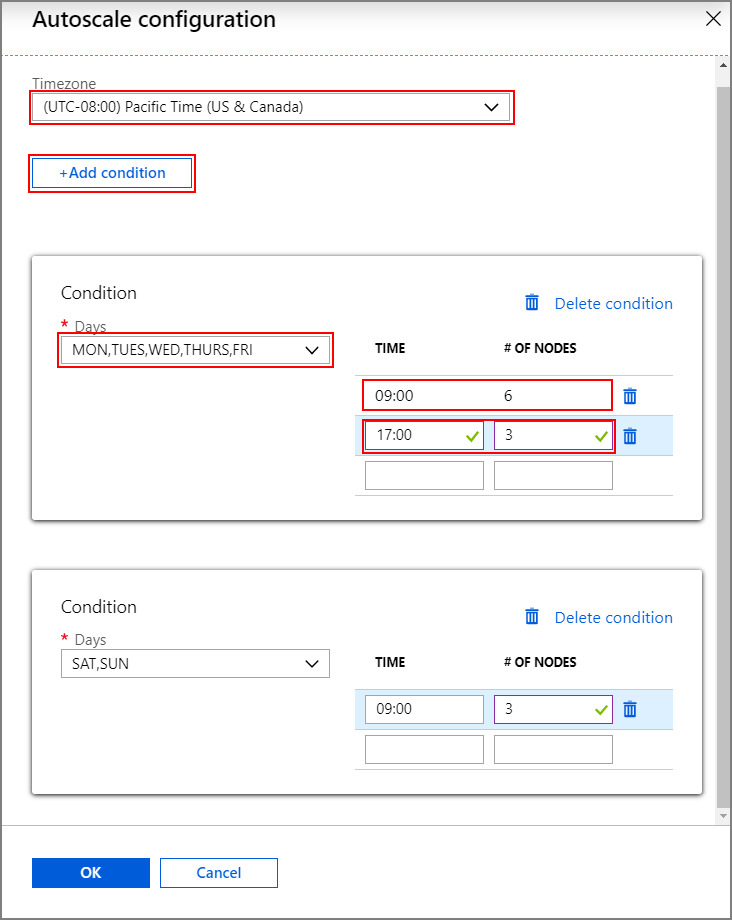
节点数最小为 3,最大为添加条件之前输入的最大工作器节点数。
最终创建步骤
请在“节点大小”下的下拉列表中选择一个 VM,通过这种方式选择工作器节点的 VM 类型。 为每个节点类型选择 VM 类型后,可以看到整个群集的估算成本范围。 请根据预算调整 VM 类型。
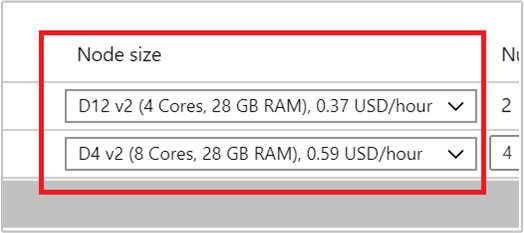
你的订阅具有针对每个区域的容量配额。 头节点核心总数加最大工作器节点数不能超过容量配额。 但是,此配额是软性限制;始终可创建支持票证来轻松地增加此配额。
注意
如果超出总核心配额限制,将收到一条错误消息,指出“最大节点数超出此区域中的可用核心数,请选择其他区域或联系客户支持以增加配额”。
有关使用 Azure 门户创建 HDInsight 群集的详细信息,请参阅使用 Azure 门户在 HDInsight 中创建基于 Linux 的群集。
使用资源管理器模板创建群集
基于负载的自动缩放
可以使用 Azure 资源管理器模板创建支持基于负载的自动缩放的 HDInsight 群集,方法是将 autoscale 节点添加到包含属性 computeProfile 和 > 的 workernodeminInstanceCountmaxInstanceCount 节,如以下 JSON 代码片段所示。 有关完整的资源管理器模板,请参阅快速启动模板:在启用基于负载的自动缩放的情况下部署 Spark 群集。
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
基于计划的自动缩放
可以使用 Azure 资源管理器模板创建支持基于计划的自动缩放的 HDInsight 群集,方法是将 autoscale 节点添加到 computeProfile>workernode 节。
autoscale 节点包含 recurrence,其中的 timezone 和 schedule 描述了更改生效的时间。 有关完整的资源管理器模板,请参阅在启用基于计划的自动缩放的情况下部署 Spark 群集。
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
为正在运行的群集启用和禁用自动缩放
使用 Azure 门户
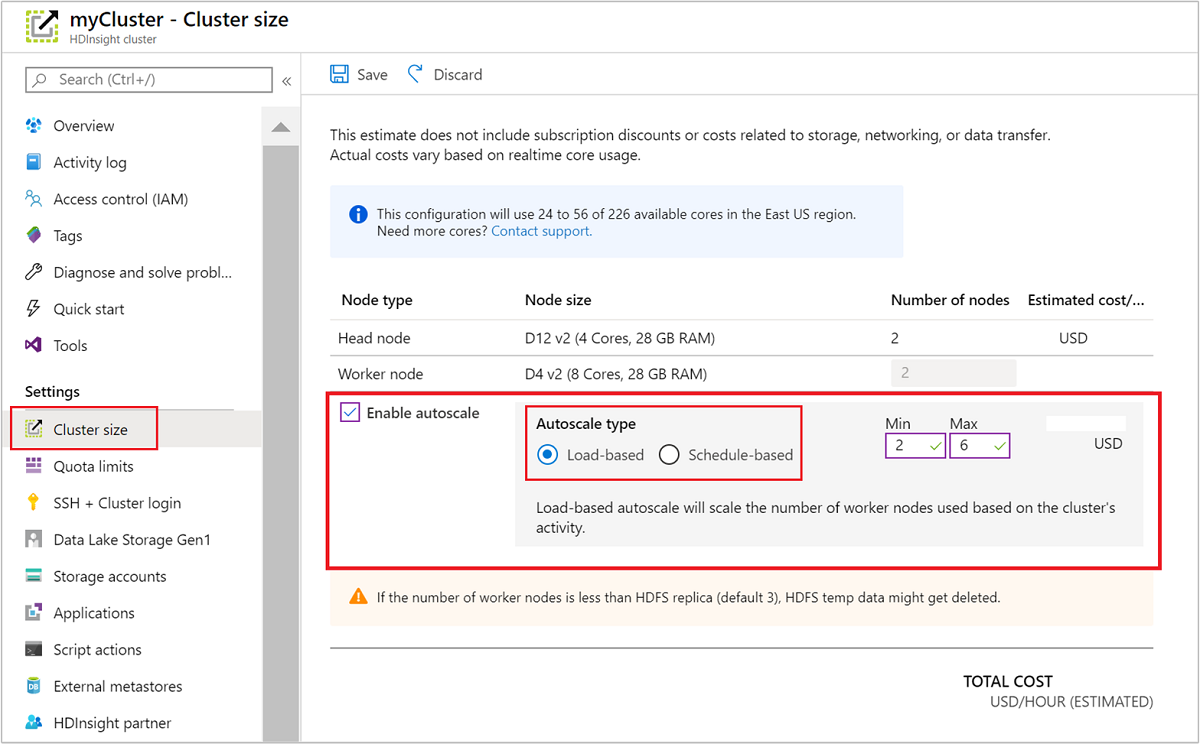
若要在运行中的群集上启用自动缩放,请选择“设置”下的“群集大小”。 然后选择 Enable autoscale。 选择所需的自动缩放类型,然后输入基于负载或基于计划的缩放选项。 最后,选择“保存”。
使用 REST API
若要使用 REST API 在运行中的群集上启用或禁用自动缩放,请向自动缩放终结点发出 POST 请求:
https://management.chinacloudapi.cn/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
请在请求有效负载中使用适当的参数。 下面的 json 有效负载可以用来enable Autoscale。 使用有效负载 {autoscale: null} 禁用自动缩放。
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
请参阅介绍如何启用基于负载的自动缩放的上一部分,详尽了解所有的有效负载参数。 不建议为正在运行的群集强制禁用自动缩放服务。
监视自动缩放活动
群集状态
Azure 门户中列出的群集状态可帮助你监视自动缩放活动。
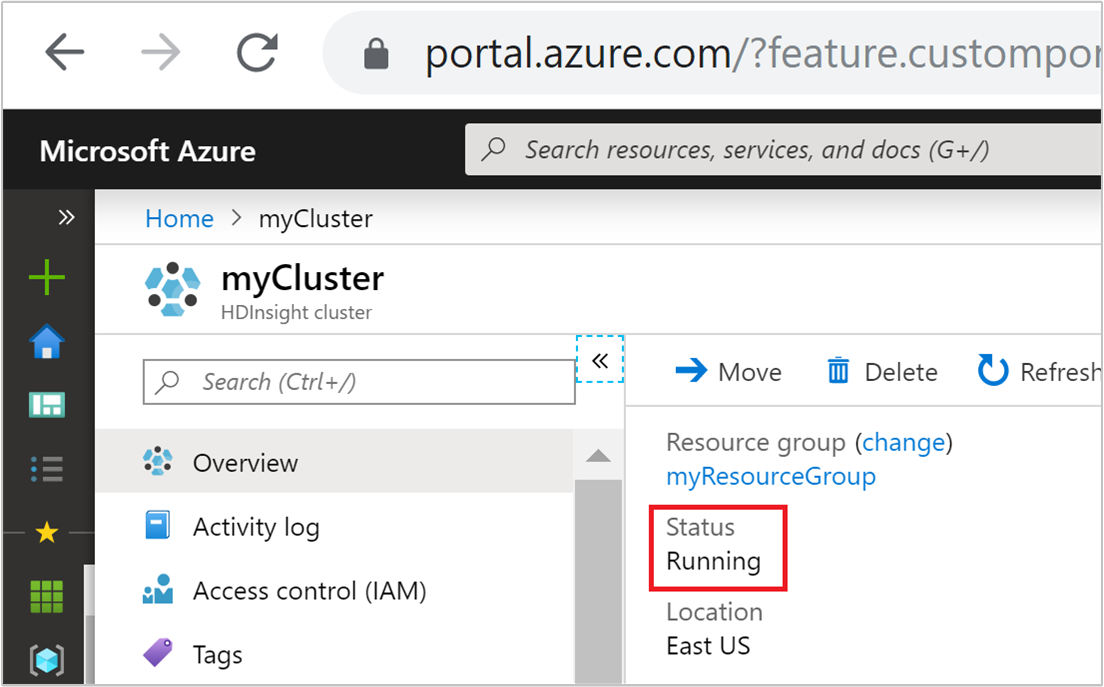
以下列表解释了你可能会看到的所有群集状态消息。
| 群集状态 | 说明 |
|---|---|
| 正在运行 | 群集在正常运行。 所有以前的自动缩放活动已成功完成。 |
| 更新 | 正在更新群集自动缩放配置。 |
| HDInsight 配置 | 某个群集纵向扩展或缩减操作正在进行。 |
| 更新时出错 | 更新自动缩放配置期间 HDInsight 遇到问题。 客户可以选择重试更新或禁用自动缩放。 |
| 错误 | 群集发生错误且不可用。 请删除此群集,然后新建一个。 |
若要查看群集中当前的节点数,请转到群集“概览”页上的“群集大小”图表。 或者在“设置”下选择“群集大小”。
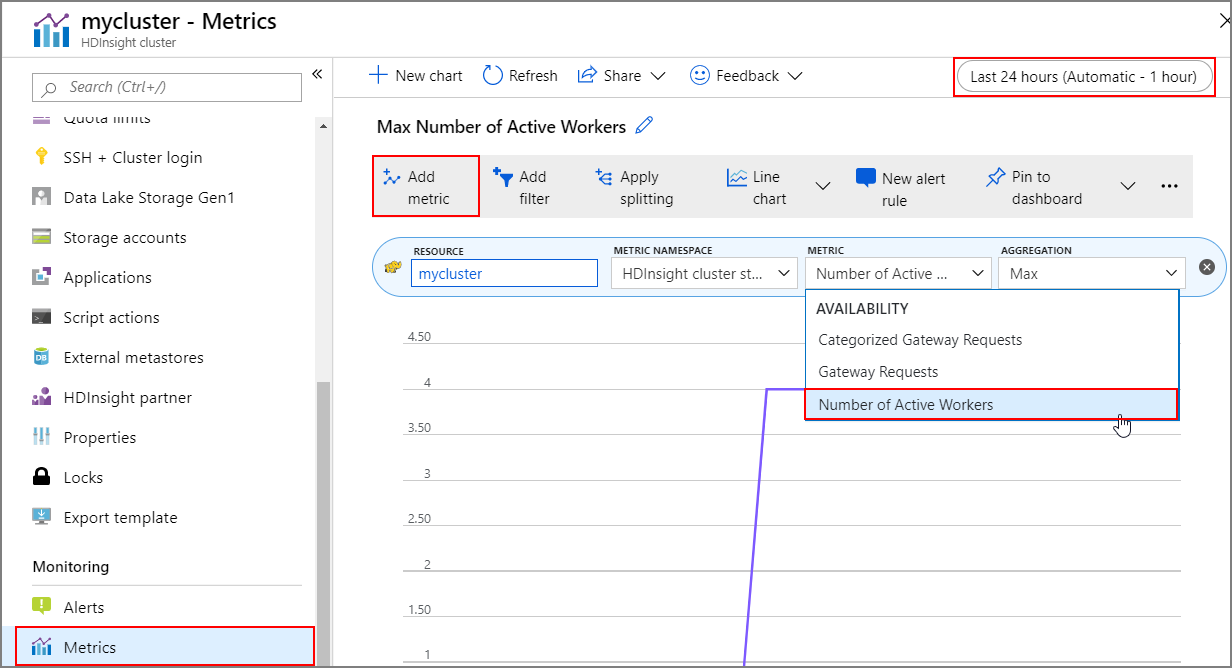
操作历史记录
可查看群集指标中包含的群集增加和减少历史记录。 还可以列出过去一天、过去一周或其他时间段的所有缩放操作。
在“监视”下选择“指标”。 然后选择“添加指标”,并从“指标”下拉框中选择“活动辅助角色数”。 选择右上角的按钮来更改时间范围。
最佳做法
请考虑纵向扩展操作和纵向缩减操作的延迟
完成整个缩放操作可能需要 10 到 20 分钟。 设置自定义计划时,请将此延迟计划在内。 例如,如果需要在早晨 9:00 将群集大小设置为 20,请将计划触发器设置为更早的某个时间(例如早晨 8:30 或更早),这样缩放操作就可以在早晨 9:00 之前完成。
准备进行纵向缩减
在群集纵向缩减过程中,自动缩放会根据目标大小解除节点的授权。 使用基于负载的自动缩放时,如果任务正在这些节点上运行,自动缩放会等待 Spark 和 Hadoop 群集的任务完成。 由于每个工作器节点也充当 HDFS 中的某个角色,因此会将临时数据转移到剩余工作器节点中。 请确保剩余节点上有足够的空间来托管所有临时数据。
注意
使用基于计划的自动缩放纵向缩减时,不支持正常取消。 这可能会在纵向缩减操作期间导致作业失败,建议根据预期的作业计划模式来规划计划,以便有充足的时间来结束正在进行的作业。 可以根据完成时间的历史分布来设置计划,以避免作业失败。
根据使用模式配置基于计划的自动缩放
配置基于计划的自动缩放时,需了解群集使用模式。 Grafana 仪表板可帮助了解查询负载和执行槽。 可以从仪表板获取可用的执行程序槽和总执行程序槽。
可以通过以下方式估计所需的工作器节点数。 建议提供额外 10% 的缓冲区来应对工作负载的变化。
使用的执行程序槽数 = 执行程序槽总数 - 可用执行程序槽总数。
所需的工作器节点数 = 实际使用的执行程序槽数/(hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size)。
*hive.llap.daemon.num.executors 可配置,且默认值为 4。
*hive.llap.daemon.task.scheduler.wait.queue.size 可配置,且默认值为 10。
自定义脚本操作
自定义脚本操作主要用于自定义节点(例如头节点/工作器节点),这使我们的客户可以配置他们正在使用的特定库和工具。 一个常见用例是,在群集上运行的作业可能对客户拥有的第三方库有一些依赖性,为了使作业成功,它应该在节点上可用。 对于自动缩放,目前支持持久性的自定义脚本操作,因此,每次在纵向扩展操作过程中新节点被添加到群集时,都将执行这些持久性的脚本操作,并在这些操作中分配容器或作业。 尽管自定义脚本操作有助于启动新节点,但建议保持最小,因为它将增加总体纵向扩展延迟,并且可能会影响计划的作业。
了解最小的群集大小
请勿将群集缩减到三个节点以下。 将群集缩放成少于三个节点可能导致系统停滞在安全模式下,因为没有进行充分的文件复制。 有关详细信息,请参阅停滞在安全模式下。
Microsoft Entra 域服务与缩放操作
如果结合使用 HDInsight 群集和已加入 Microsoft Entra 域服务托管域的企业安全性套餐 (ESP),建议在 Microsoft Entra 域服务上限制负载。 如果是复杂的目录结构范围内的同步,建议避免对缩放操作造成影响。
针对峰值使用方案设置名为“最大并发查询总数”的 Hive 配置
自动缩放事件不会更改 Ambari 中名为“最大并发查询总数”的 Hive 配置。 这意味着,即使 Interactive Query 守护程序计数根据负载和计划进行纵向扩展和纵向缩减,Hive Server 2 交互式服务在任意时间点也只能处理给定数量的并发查询。 通常建议针对峰值使用方案设置此配置,以避免手动干预。
但是,如果只有少量的工作器节点,并且最大并发查询总数的值配置过高,则可能会出现 Hive Server 2 重启失败的情况。 至少需要可容纳给定数量的 Tez Ams 的最小工作器节点数(等于最大并发查询配置总数)。
限制
Interactive Query 守护程序计数
如果 Interactive Query 群集启用了自动缩放,则自动纵向扩展/纵向缩减事件还会将 Interactive Query 守护程序的数量纵向扩展/纵向缩减为活动工作器节点的数量。 守护进程数量的变化不会保存在 Ambari 的 num_llap_nodes 配置中。 如果手动重启 Hive 服务,则 Interactive Query 守护程序的数量将根据 Ambari 中的配置进行重置。
如果手动重启 Interactive Query 服务,则需要手动更改“高级 hive-interactive-env”下的 num_llap_node 配置(运行 Hive Interactive Query 守护程序所需的节点数),使其与当前的活动工作器节点计数一致。 Interactive Query 群集仅支持基于计划的自动缩放。
替代方案
- 使用基于计划的自动缩放工作流,以便开发人员有机会在纵向缩减群集之前调试任何作业失败。
- 在 Azure CLI 中使用“yarn logs”命令。
- 使用开源转换器将 Azure 存储帐户中的 Tfile 格式日志转换为纯文本。
后续步骤
阅读缩放准则,了解有关手动缩放群集的准则。