实时大数据解决方案可以处理动态数据。 通常,这些数据在抵达时的作用最大。 如果传入的数据流比当时可处理的大小更大,则可能需要限制资源。 或者,可以通过按需添加节点来纵向扩展 HDInsight 群集以满足流式处理解决方案的需要。
在流式处理应用程序中,一个或多个数据源会生成事件(有时达到每秒几百万个事件),此时,需要在不丢弃任何有用信息的情况下快速引入这些事件。 Apache Kafka 或事件中心等服务使用流缓冲(也称为事件队列)来处理传入的事件。 收集事件后,可以使用流处理层中的实时分析系统(例如 Apache Spark Streaming)来分析数据。 处理的数据可存储在长期存储系统中,并实时显示在商业智能仪表板(例如 Power BI、Tableau)或自定义的网页上。
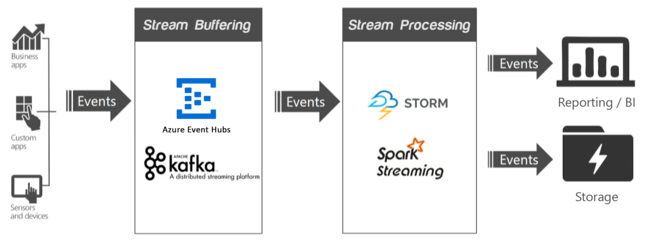
Apache Kafka
Apache Kafka 提供高吞吐量、低延迟的消息队列服务,并且现已包含在 Apache 开源软件 (OSS) 套件中。 Kafka 使用发布-订阅消息传送模型,将分区数据流安全存储在分布式的复制群集中。 吞吐量增大时,Kafka 会线性扩展。
有关详细信息,请参阅 HDInsight 上的 Apache Kafka 简介。
Spark 流式处理
Spark Streaming 是 Spark 的一个扩展,可让你重复使用执行批处理时所用的相同代码。 可以在同一个应用程序中结合使用批处理和交互式查询。 与 Spark 不同的是,流式处理提供有状态的“恰好一次”处理语义。 与 Kafka Direct API(确保 Spark Streaming 接收所有 Kafka 数据恰好一次)结合使用时,可以实现端到端的“恰好一次”处理保证。 Spark Streaming 的优点之一体现在其容错功能。在群集中使用多个节点时,它可以快速恢复有故障的节点。
有关详细信息,请参阅什么是 Apache Spark Streaming?。
缩放群集
尽管可以在创建过程中指定群集中的节点数,但可能需要扩展或缩减群集才能匹配工作负荷。 所有 HDInsight 群集允许更改群集中的节点数。 由于所有数据都存储在 Azure 存储或 Data Lake Storage 中,因此可以在不丢失数据的情况下删除 Spark 群集。
分离技术可以带来优势。 例如,Kafka 是一种事件缓冲技术,因此它的 IO 开销极高,但不需要大量的处理能力。 相比之下,Spark Streaming 等流处理器是计算密集型的,需要更强大的 VM。 将这些技术分离到不同的群集后,可以单独缩放每个群集,同时充分利用 VM。
缩放流缓冲层
事件中心和 Kafka 流缓冲技术都使用分区,使用者从这些分区读取数据。 缩放输入吞吐量需要增大分区数目,而添加分区又能提供更高的并行度。 在事件中心,部署后无法更改分区计数,因此,必须一开始就有目标缩放的意识。 即使 Kafka 正在处理数据,也能使用 Kafka 添加分区。 Kafka 提供 kafka-reassign-partitions.sh 工具用于重新分配分区。 HDInsight 提供分区副本重新均衡工具rebalance_rackaware.py。 此重新均衡工具在调用 kafka-reassign-partitions.sh 工具时,可让每个副本位于不同的容错域和更新域,以便可以识别 Kafka 机架,并提高容错能力。
缩放流处理层
Apache Spark Streaming 支持将工作器节点添加到其群集,即使正在处理数据。
Apache Spark 根据应用程序的要求使用三个关键参数来配置其环境:spark.executor.instances、spark.executor.cores 和 spark.executor.memory。 执行器是针对 Spark 应用程序启动的进程。 执行器在工作节点上运行,负责执行应用程序的任务。 执行器的默认数目和每个群集的执行器大小是根据工作节点数目和工作节点大小计算的。 这些数字存储在每个群集头节点上的 spark-defaults.conf 文件中。
这三个参数可在群集级别进行配置(适用于群集上运行的所有应用程序),也可以针对每个应用程序指定。 有关详细信息,请参阅管理 Apache Spark 群集的资源。