了解如何访问与 Apache Spark 群集关联的界面(如 Apache Ambari UI、Apache Hadoop YARN UI 和 Spark History Server),以及如何优化群集配置以达到最佳性能。
打开 Spark History Server
Spark History Server 是已完成和正在运行的 Spark 应用程序的 Web UI。 它是 Spark Web UI 的扩展。 有关完整信息,请参阅 Spark History Server。
打开 YARN UI
可以使用 YARN UI 来监视 Spark 群集上当前运行的应用程序。
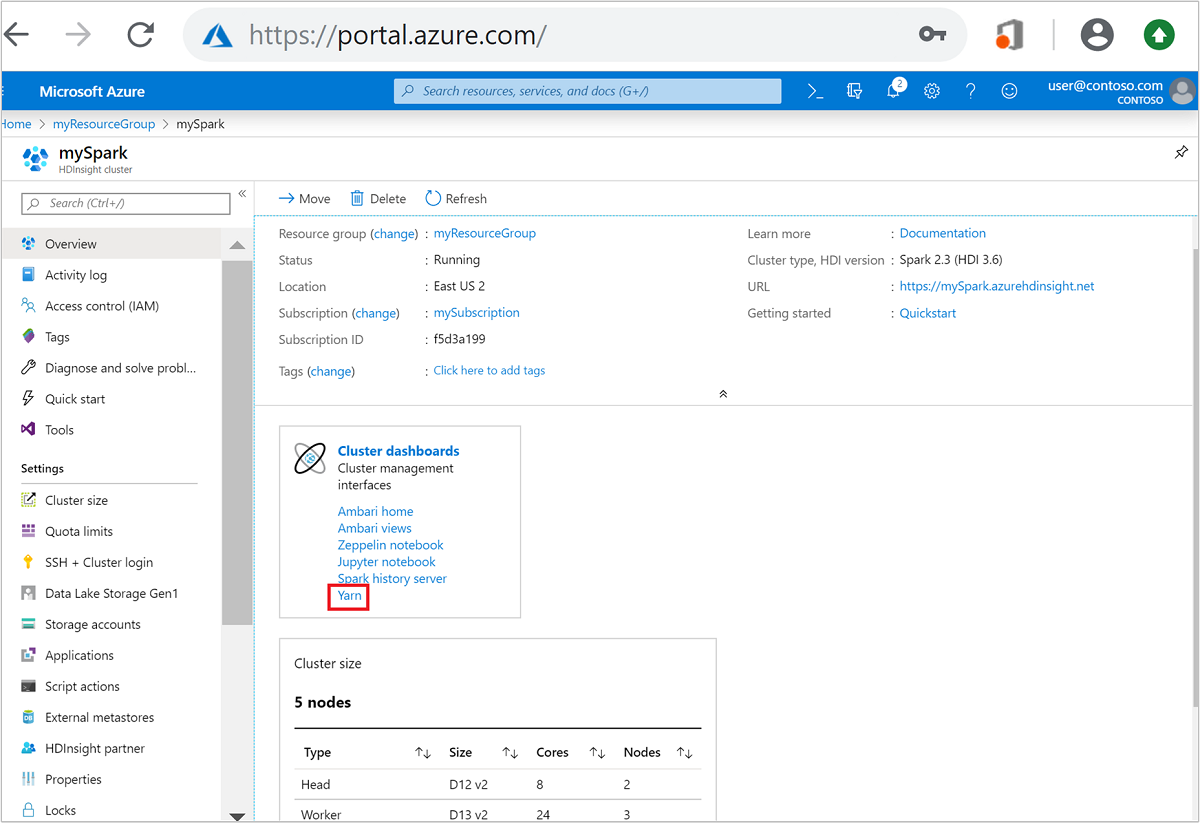
从“群集仪表板” 中,选择“Yarn” 。 出现提示时,输入 Spark 群集的管理员凭据。
提示
或者,也可以从 Ambari UI 启动 YARN UI。 在 Ambari UI 中,导航到“YARN” >“快速链接” >“活动” > “资源管理器 UI”。
针对 Spark 应用程序优化群集
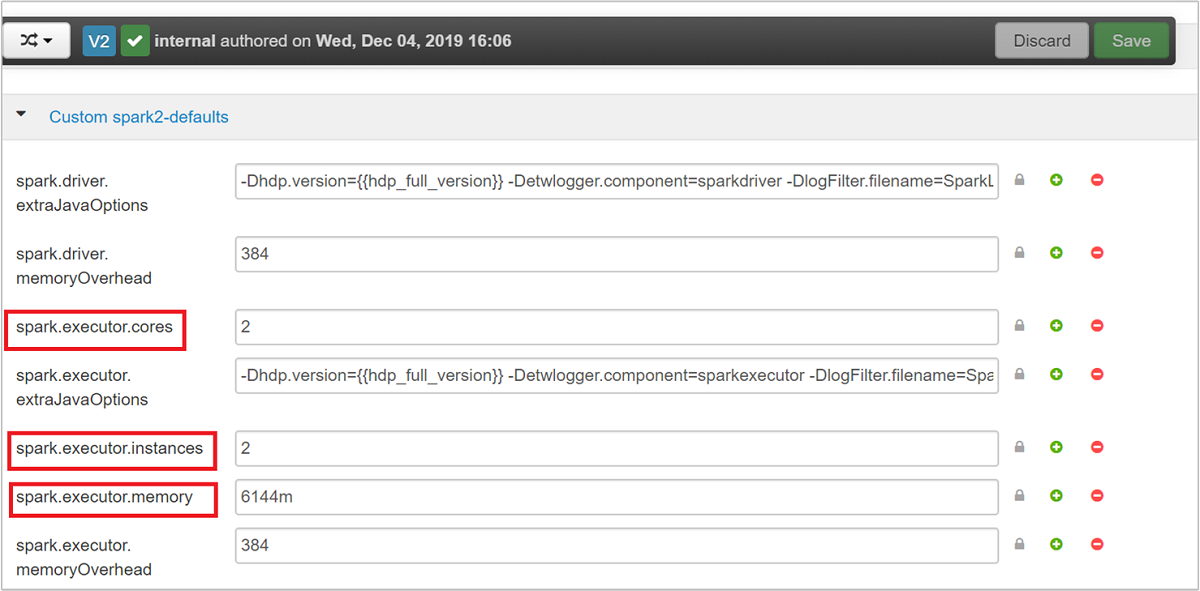
根据应用程序的要求,可用于 Spark 配置的三个关键参数为 spark.executor.instances、spark.executor.cores 和 spark.executor.memory。 执行器是针对 Spark 应用程序启动的进程。 它在辅助角色节点上运行,负责执行应用程序的任务。 执行器的默认数目和每个群集的执行器大小是根据辅助角色节点数目和辅助角色节点大小计算的。 这些信息存储在群集头节点上的 spark-defaults.conf 中。
这三个配置参数可在群集级别配置(适用于群集上运行的所有应用程序),也可以针对每个应用程序指定。
使用 Ambari UI 更改参数
在 Ambari UI 中,导航到“Spark 2”>“配置”>“自定义 spark2-defaults”。
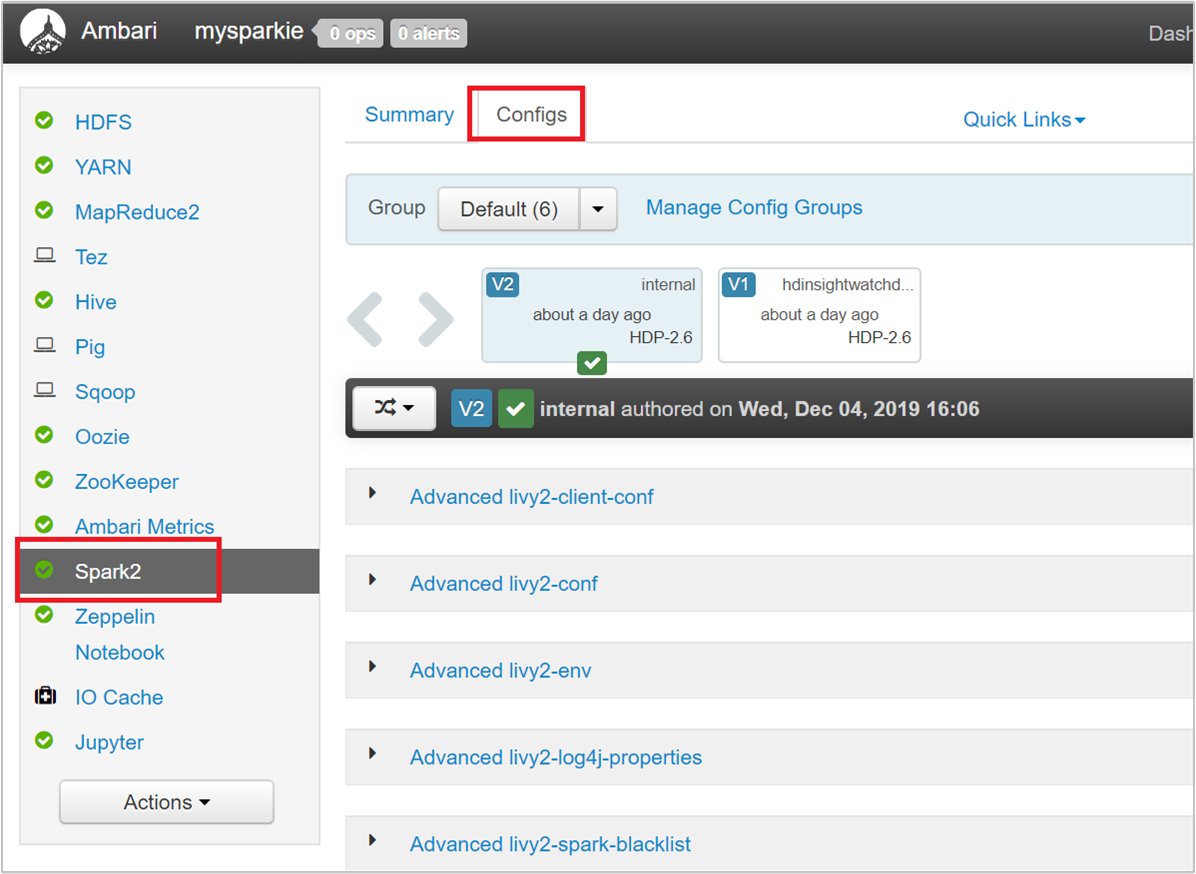
默认值(在群集上并发运行 4 个 Spark 应用程序)是合理的。 可以从用户界面更改这些值,如以下屏幕截图所示:
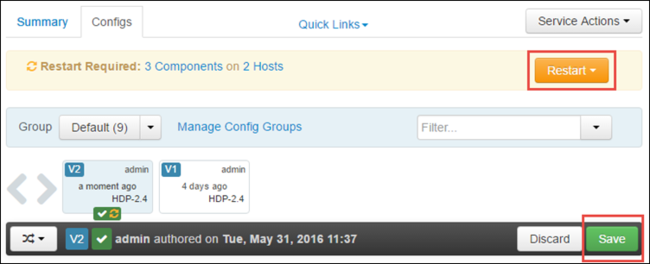
选择“保存”, 保存配置更改。 在页面顶部,系统会提示是否重启所有受影响的服务。 选择“重启”。
更改 Jupyter Notebook 中运行的应用程序的参数
对于在 Jupyter Notebook 中运行的应用程序,可以使用 %%configure magic 进行配置更改。 理想情况下,必须先在应用程序开头进行此类更改,再运行第一个代码单元。 这可以确保在创建 Livy 会话时会配置应用到该会话。 如果想要更改处于应用程序中后面某个阶段的配置,必须使用 -f 参数。 但是,这样做会使应用程序中的所有进度丢失。
以下代码片段演示如何更改 Jupyter 中运行的应用程序的配置。
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
配置参数必须以 JSON 字符串传入,并且必须位于 magic 后面的下一行,如示例列中所示。
使用 spark-submit 更改已提交应用程序的参数
以下命令示范了如何更改使用 spark-submit 提交的批处理应用程序的配置参数。
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 --num-executors 10 <location of application jar file> <application parameters>
使用 cURL 更改已提交应用程序的参数
以下命令示范了如何更改使用 cURL 提交的批处理应用程序的配置参数。
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
注意
将 JAR 文件复制到群集存储帐户。 不要将 JAR 文件直接复制到头节点。
在 Spark Thrift 服务器上更改这些参数
Spark Thrift 服务器提供对 Spark 群集的 JDBC/ODBC 访问,用来为 Spark SQL 查询提供服务。 Power BI、Tableau 之类的工具使用 ODBC 协议与 Spark Thrift 服务器通信,以便将 Spark SQL 查询作为 Spark 应用程序执行。 创建 Spark 群集时,将启动 Spark Thrift 服务器的两个实例(每个头节点上各有一个实例)。 在 YARN UI 中,每个 Spark Thrift 服务器显示为一个 Spark 应用程序。
Spark Thrift 服务器使用 Spark 动态执行器分配,因此未使用 spark.executor.instances。 相反,Spark Thrift 服务器使用 spark.dynamicAllocation.maxExecutors 和 spark.dynamicAllocation.minExecutors 来指定执行器计数。 使用配置参数 spark.executor.cores 和 spark.executor.memory 可以修改执行器大小。 可按以下步骤所示更改这些参数:
展开“高级 spark2-thrift-sparkconf” 类别可更新参数
spark.dynamicAllocation.maxExecutors和spark.dynamicAllocation.minExecutors。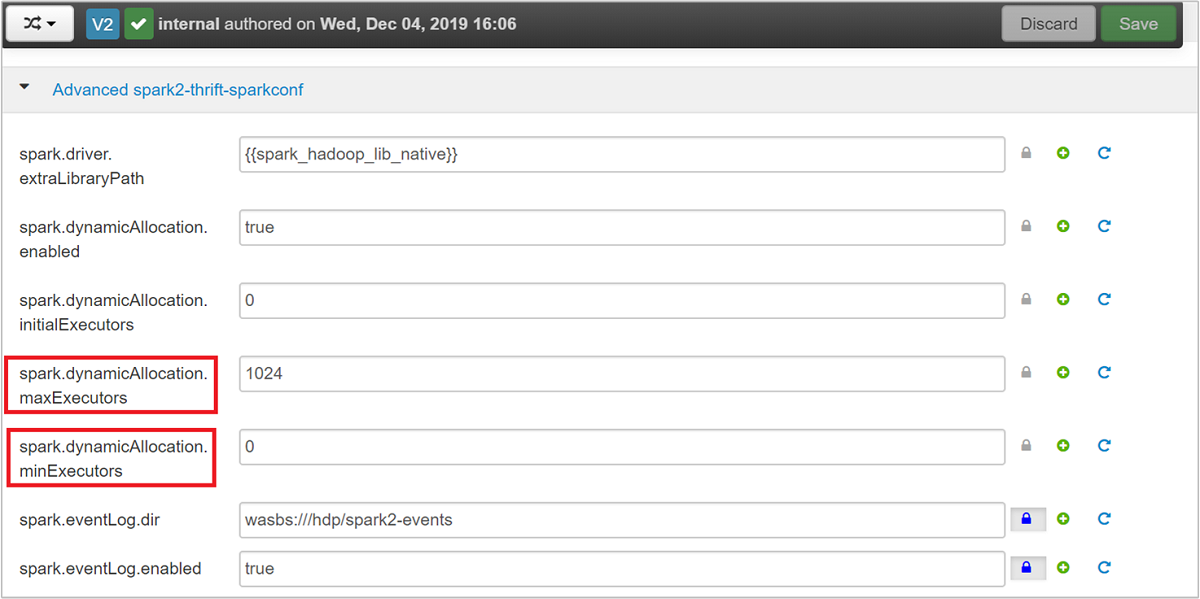
展开“自定义 spark2-thrift-sparkconf” 类别可更新参数
spark.executor.cores和spark.executor.memory。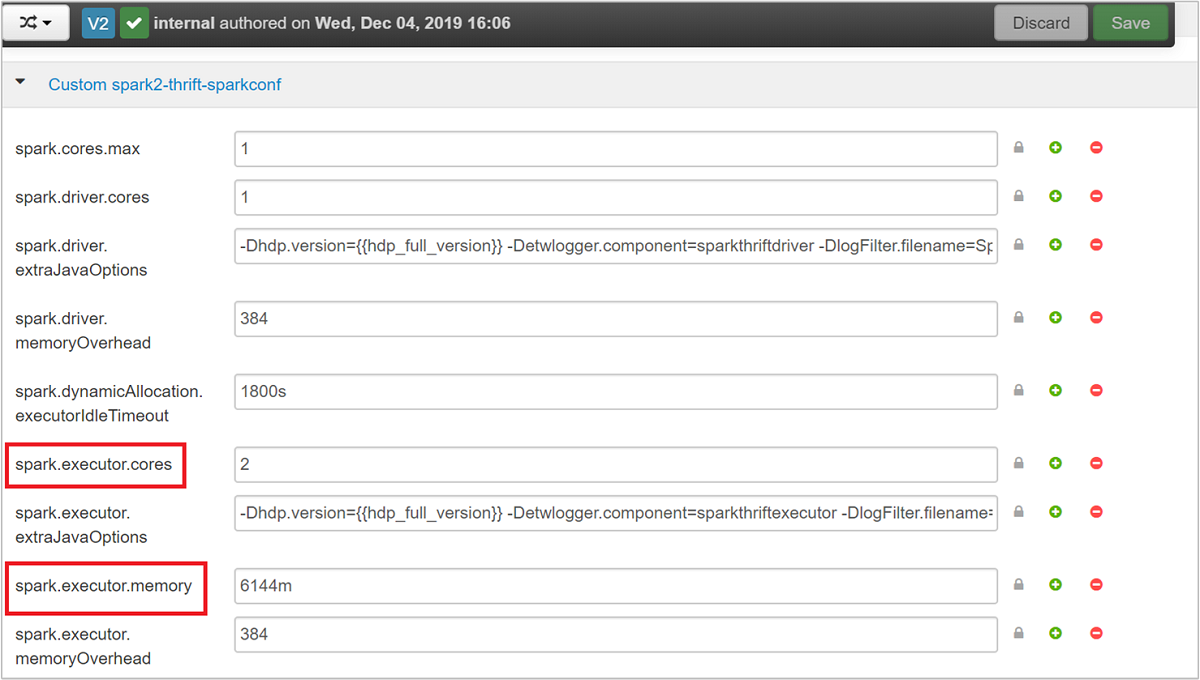
更改 Spark Thrift 服务器的驱动程序内存
Spark Thrift 服务器驱动程序内存配置为头节点 RAM 大小的 25%,前提是头节点的 RAM 总大小大于 14 GB。 可以使用 Ambari UI 更改驱动程序内存配置,如以下屏幕截图所示:
在 Ambari UI 中,导航到“Spark2”>“配置”>“高级 spark2-env”。 然后提供 spark_thrift_cmd_opts 的值。
回收 Spark 群集资源
由于 Spark 动态分配,因此 Thrift 服务器使用的唯一资源是两个应用程序主机的资源。 若要回收这些资源,必须停止群集上运行的 Thrift 服务器服务。
在 Ambari UI 的左侧窗格中,选择“Spark2” 。
在下一页中,选择“Spark 2 Thrift 服务器”。
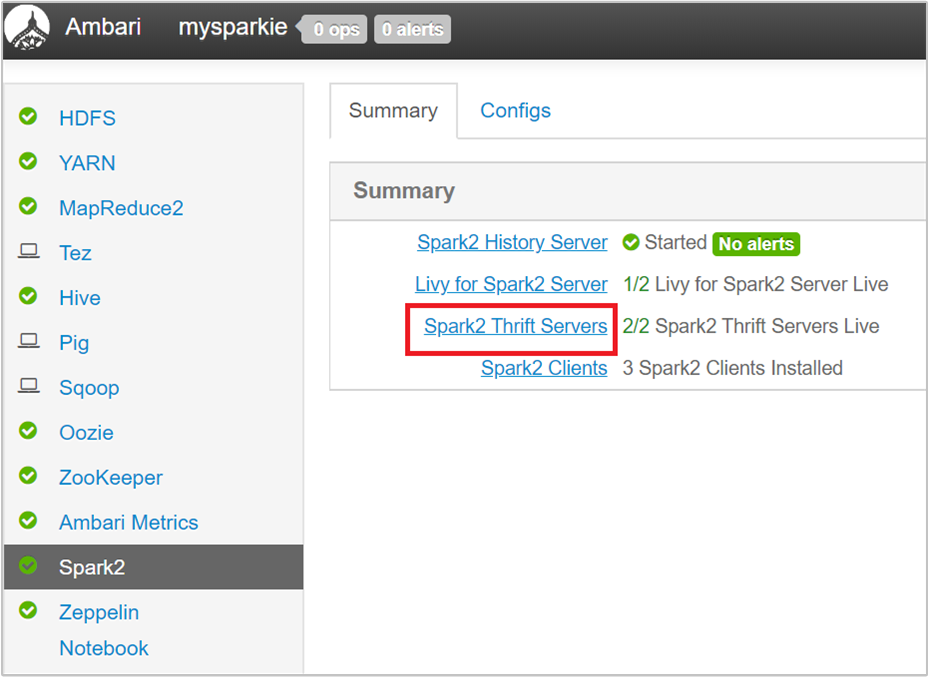
应会看到正在运行 Spark 2 Thrift 服务器的两个头节点。 选择其中一个头节点。
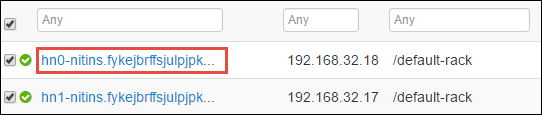
下一页将列出该头节点上运行的所有服务。 在该列表中,选择 Spark 2 Thrift 服务器旁边的下拉按钮,并选择“停止”。
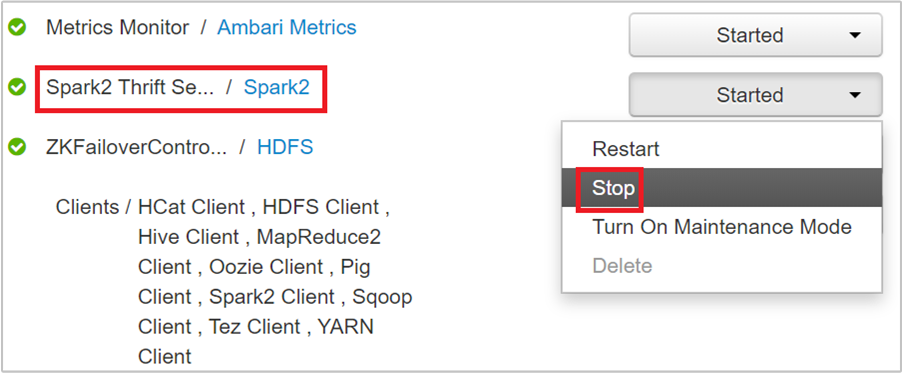
对其他头节点重复上述步骤。
重新启动 Jupyter 服务
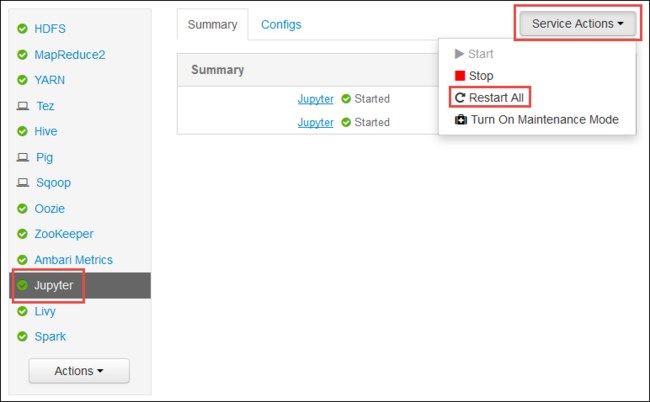
启动 Ambari Web UI,如本文开头所示。 在左侧导航窗格中,依次选择“Jupyter” 、“服务操作” 和“全部重启” 。 这会在所有头节点上启动 Jupyter 服务。
监视资源
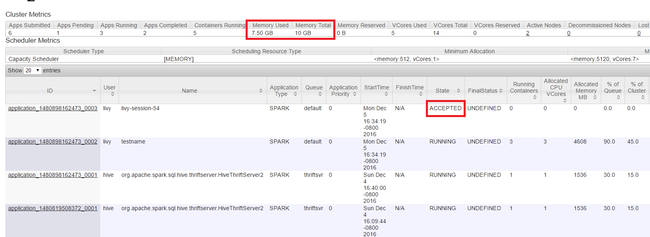
启动 Yarn UI,如本文开头所示。 在屏幕顶部的“群集指标”表中,选中“已用内存” 和“内存总计” 列的值。 如果这 2 个值很接近,则可能资源不足,无法启动下一个应用程序。 这同样适用于“已用 VCore” 和“VCore 总计” 列。 此外,在主视图中,如果有应用程序保持“已接受” 状态,而不转换为“正在运行” 或“失败” 状态,这也可能指示该应用程序未获得足够的资源来启动。
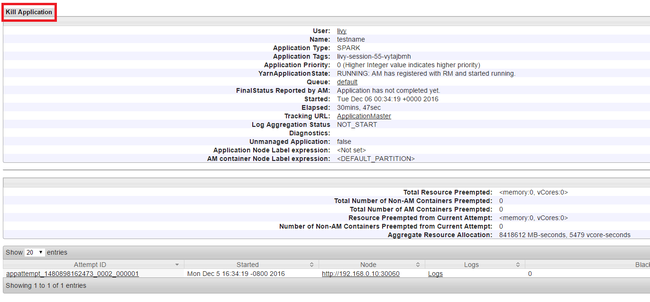
终止正在运行的应用程序
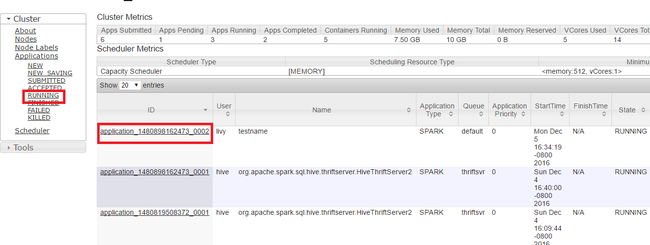
在 Yarn UI 中,从左侧面板中,选择“正在运行” 。 在正在运行的应用程序的列表中,确定要终止的应用程序,并选择“ID” 。
选择右上角的“终止应用程序” ,然后选择“确定” 。
另请参阅
适用于数据分析师
- Apache Spark 和机器学习:使用 HDInsight 中的 Spark 结合 HVAC 数据分析建筑物温度
- Apache Spark 与机器学习:使用 HDInsight 中的 Spark 预测食品检查结果
- 使用 HDInsight 中的 Apache Spark 分析网站日志
- 使用 HDInsight 中的 Apache Spark 执行 Application Insight 遥测数据分析
适用于 Apache Spark 开发人员
- 使用 Scala 创建独立的应用程序
- 使用 Apache Livy 在 Apache Spark 群集中远程运行作业
- 使用适用于 IntelliJ IDEA 的 HDInsight 工具插件创建和提交 Spark Scala 应用程序
- 使用适用于 IntelliJ IDEA 的 HDInsight 工具插件远程调试 Apache Spark 应用程序
- 在 HDInsight 上的 Apache Spark 群集中使用 Apache Zeppelin 笔记本
- 在 HDInsight 的 Apache Spark 群集中可用于 Jupyter Notebook 的内核
- 将外部包与 Jupyter Notebook 配合使用
- Install Jupyter on your computer and connect to an HDInsight Spark cluster(在计算机上安装 Jupyter 并连接到 HDInsight Spark 群集)