重要
默认元存储提供了一个基本层 Azure SQL 数据库,只有 5 DTU 和 2 GB 数据最大大小(不可升级)! 请仅将其用于 QA 和测试目的。 对于生产或大型工作负载,建议迁移到外部元存储!
HDInsight 允许通过外部数据存储来控制数据和元数据。 此功能可用于 Apache Hive 元存储、Apache Oozie 元存储和 Apache Ambari 数据库。
HDInsight 中的 Apache Hive 元存储是 Apache Hadoop 体系结构的必备部分。 元存储是中心架构存储库。 其他大型数据访问工具(例如 Apache Spark、Interactive Query [LLAP]、Presto 或 Apache Pig)使用元存储。 HDInsight 使用 Azure SQL 数据库作为 Hive 元存储。
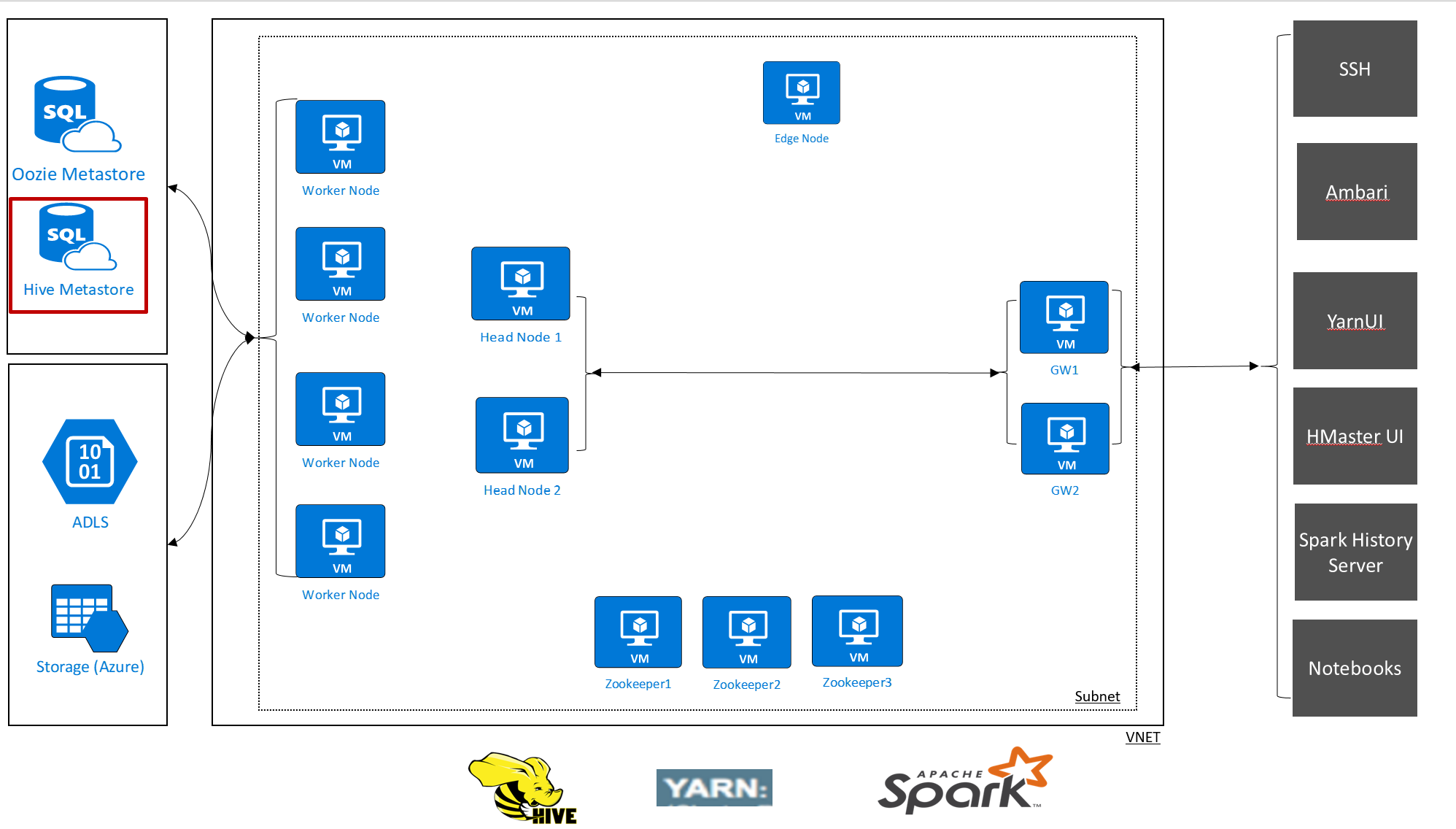
可使用以下两种方式为 HDInsight 存储设置元存储:
默认元存储
默认情况下,HDInsight 为每一种群集类型创建一个元存储。 转而可指定自定义元存储。 默认元存储包括以下注意事项:
有限的资源。 请参阅页面顶部的通知。
无需更多成本。 HDInsight 会为每个群集类型创建一个元存储,而不会向你收取任何额外费用。
默认元存储是群集生命周期的一部分。 删除群集时,也会删除相应的该元存储和元数据。
建议将默认元存储仅用于简单工作负载。 即不需要多个群集且不需要在群集生命周期之外保留的元数据的工作负荷。
不可与其他群集共享默认元存储。
自定义元存储
HDInsight 还支持自定义元存储,建议对生产群集使用此项:
将自己的 Azure SQL 数据库指定为元存储。
元存储的生命周期不与群集生命周期相关联,因此可创建和删除群集,而不会丢失元数据。 即使删除和重新创建 HDInsight 群集之后,系统仍然保留 Hive 架构等元数据。
通过自定义元存储,可将多个群集和群集类型附加到元存储。 例如,可跨交互式查询、Hive 和 HDInsight 中的群集的 Spark 共享单个元存储。
根据所选的性能级别支付元存储(Azure SQL 数据库)的费用。
可按需增加元存储。
群集和外部元存储必须托管在同一区域中。
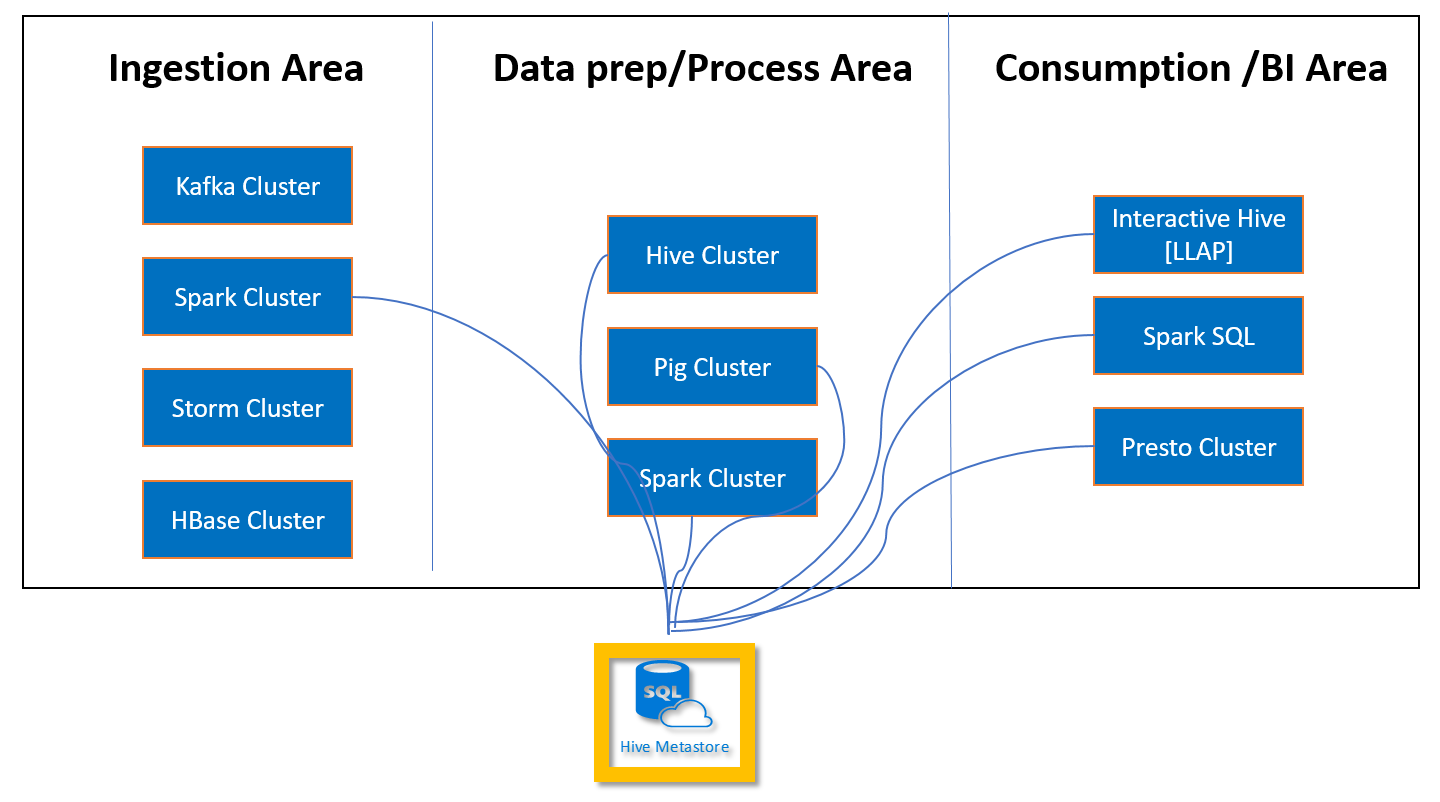
针对自定义元存储创建并配置 Azure SQL 数据库
在为 HDInsight 群集设置自定义 Hive 元存储之前创建或拥有现有的 Azure SQL 数据库。 有关详细信息,请参阅快速入门:在 Azure SQL 数据库中创建单一数据库。
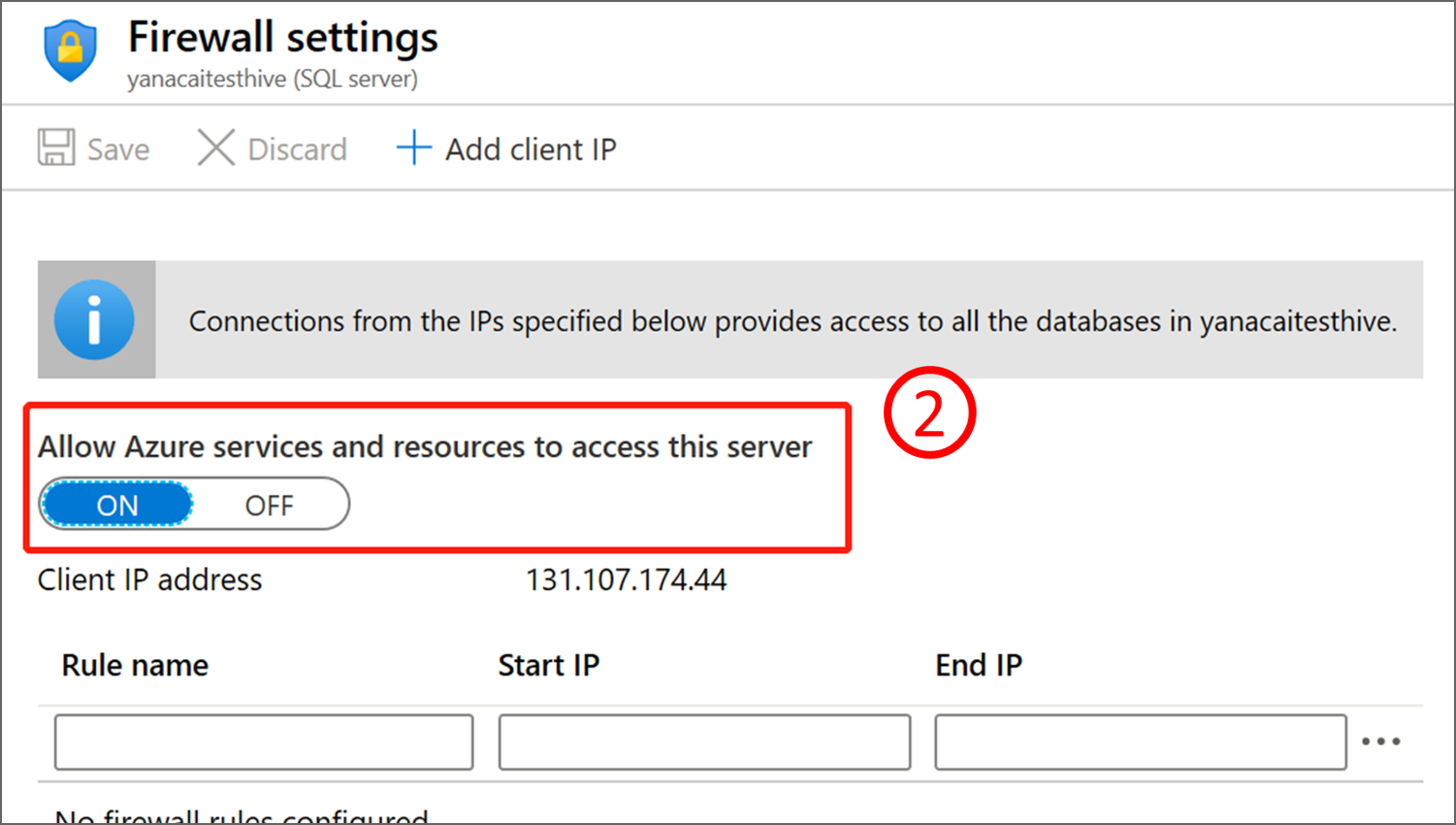
创建群集时,HDInsight 服务需要连接到外部元存储并验证你的凭据。 配置 Azure SQL 数据库防火墙规则以允许 Azure 服务和资源访问服务器。 通过选择“设置服务器防火墙”来在 Azure 门户中启用此选项。 然后针对 Azure SQL 数据库在“拒绝公用网络访问”下选择“否”,在“允许 Azure 服务和资源访问此服务器”下选择“是”。 有关详细信息,请参阅创建和管理 IP 防火墙规则
仅在使用 outbound ResourceProviderConnection 创建的群集上支持 SQL 存储的专用终结点。 若要了解详细信息,请参阅此文档。

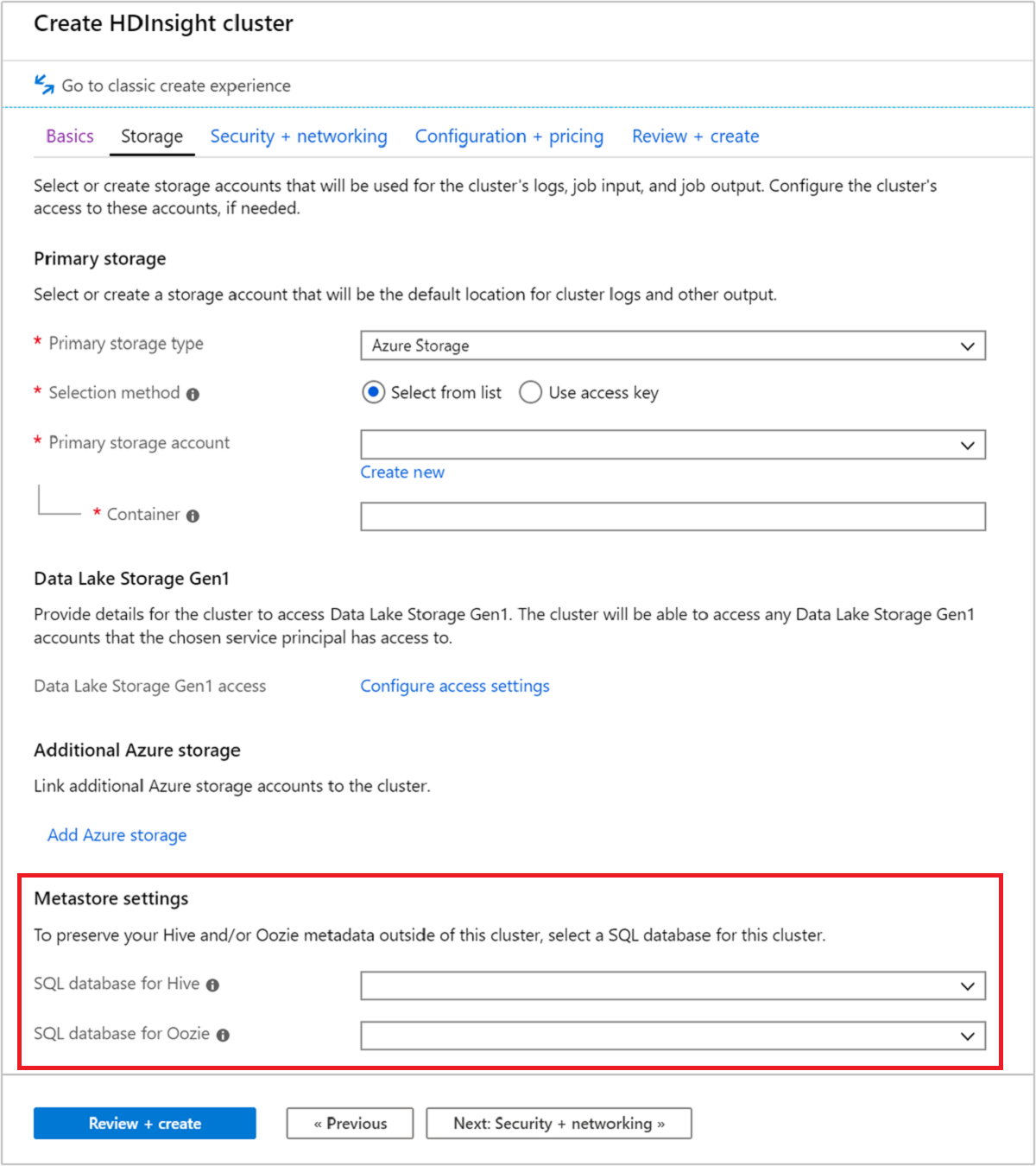
在群集创建期间选择自定义元存储
可以随时将群集指向之前创建的 Azure SQL 数据库。 若要通过门户创建群集,请从“存储”>“元存储设置”指定该选项。
Apache Hive 元存储指南
注意
尽可能使用自定义元存储来帮助分离计算资源(正在运行的群集)和元数据(存储在元存储中)。 首先使用 S2 层,它提供 50 DTU 和 250 GB 的存储。 如果空间不够,可扩大数据库。
如果你希望多个 HDInsight 群集访问单独的数据,请对每个群集上的元存储使用单独的数据库。 如果在多个 HDInsight 群集之间共享元存储,则意味着这些群集将使用相同的元数据和底层用户数据文件。
请定期备份自定义元存储。 Azure SQL 数据库会自动生成备份,但备份保留时间范围会有所不同。 有关详细信息,请参阅了解 SQL 数据库自动备份。
将元存储和 HDInsight 群集放在同一区域。 此配置可实现最高的性能和最低的网络流出费用。
使用 Azure SQL 数据库监视工具或 Azure Monitor 日志监视元存储库的性能和可用性。
针对现有的自定义元存储数据库创建更高版本的新 Azure HDInsight 时,系统将升级元存储的架构。 如果不从备份还原数据库,则升级不可逆。
如果在多个群集之间共享元存储,请确保所有群集都具有相同的 HDInsight 版本。 不同的 Hive 版本使用不同的元存储数据库架构。 例如,不能在具有 Hive 版本 2.1 的群集和具有 Hive 版本 3.1 的群集之间共享元存储。
在 HDInsight 4.0 中,Spark 和 Hive 使用独立目录来访问 SparkSQL 或 Hive 表。 Spark 创建的表位于 Spark 目录中。 Hive 创建的表位于 Hive 目录中。 这与 HDInsight 3.6 不同,在 HDInsight 3.6 中,Hive 和 Spark 共享公共目录。 HDInsight 4.0 中的 Hive 和 Spark 集成依赖于 Hive 仓库连接器 (HWC)。 HWC 在 Spark 和 Hive 之间起到桥梁作用。 了解 Hive 仓库连接器。
在 HDInsight 4.0 中,如果想在 Hive 和 Spark 之间共享元存储,可以通过在 Spark 群集中将 metastore.catalog.default 属性更改为 hive 来实现。 可在 Ambari Advanced spark2-hive-site-override 中找到此属性。 请务必了解,元存储共享功能仅适用于外部 Hive 表,但此功能将不起作用于内部/托管 Hive 表或 ACID 表。
更新自定义 Hive 元存储密码
使用自定义 Hive 元存储数据库时,可以更改 SQL DB 密码。 如果更改自定义元存储的密码,则在更新 HDInsight 群集中的密码之前,Hive 服务将不起作用。
更新 Hive 元存储密码:
- 打开 Ambari UI。
- 单击“服务”-->“Hive”-->“配置”-->“数据库”。
- 将“数据库密码”字段更新为新的 SQL Server 数据库密码。
- 单击“测试连接”按钮以确保新密码有效。
- 单击“保存”按钮 。
- 按照 Ambari 提示保存配置并重启所需的服务。
Apache Oozie 元存储
Apache Oozie 是一个管理 Hadoop 作业的工作流协调系统。 Oozie 支持对 Apache MapReduce、Pig 和 Hive 等模型执行 Hadoop 作业。 Oozie 使用元存储来存储有关工作流的详细信息。 可使用 Azure SQL 数据库作为自定义元存储,提高使用 Oozie 时的性能。 删除群集后,可通过元存储访问 Oozie 作业数据。
若要了解如何使用 Azure SQL 数据库创建 Oozie 元存储,请参阅使用 Apache Oozie 处理工作流。
更新自定义 Oozie 元存储密码
使用自定义 Oozie 元存储数据库时,可以更改 SQL DB 密码。 如果更改自定义元存储的密码,则在更新 HDInsight 群集中的密码之前,Oozie 服务将不起作用。
更新 Oozie 元存储密码:
- 打开 Ambari UI。
- 单击“服务”-->“Oozie”-->“配置”-->“数据库”。
- 将“数据库密码”字段更新为新的 SQL Server 数据库密码。
- 单击“测试连接”按钮以确保新密码有效。
- 单击“保存”按钮 。
- 按照 Ambari 提示保存配置并重启所需的服务。
自定义 Ambari DB
若要在 Apache Ambari on HDInsight 上使用自己的外部数据库,请参阅自定义 Apache Ambari 数据库。