了解如何将 Apache Oozie 与 Azure HDInsight 上的 Apache Hadoop 配合使用。 Oozie 是一个管理 Hadoop 作业的工作流和协调系统。 Oozie 与 Hadoop 堆栈集成,并支持以下作业:
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
还可以使用 Oozie 来计划特定于某系统的作业,例如 Java 程序或 shell 脚本
注意
用于定义与 HDInsight 配合运行的工作流的另一个选项是 Azure 数据工厂。 若要详细了解数据工厂,请参阅将 Apache Pig 和 Apache Hive 用于数据工厂。 若要在具有企业安全性套餐的群集上使用 Oozie,请参阅在具有企业安全性套餐的 HDInsight Hadoop 群集中运行 Apache Oozie。
先决条件
HDInsight 上的 Hadoop 群集。 请参阅 Linux 上的 HDInsight 入门。
SSH 客户端。 请参阅使用 SSH 连接到 HDInsight (Apache Hadoop)。
Azure SQL 数据库。 请参阅使用 Azure 门户在 Azure SQL 数据库中创建数据库。 本文使用名为“oozietest”的数据库。
群集主存储的 URI 方案。 对于 Azure 存储,方案为
wasb://;对于 Azure Data Lake Storage Gen2,方案为abfs://。 如果为 Azure 存储启用安全传输,则 URI 将为wasbs://。 另请参阅安全传输。
示例工作流
本文档中使用的工作流包含两个操作。 操作是任务的定义,例如运行 Hive、Sqoop、MapReduce 或其他进程:
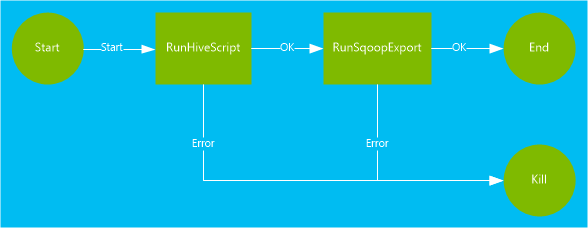
Hive 操作运行 HiveQL 脚本,从 HDInsight 包含的
hivesampletable中提取记录。 每个数据行描述特定移动设备的访问。 显示的记录格式如下文所示:8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1本文档中使用的 Hive 脚本将统计每个平台(例如 Android 或 iPhone)的总访问次数,并将计数存储到新的 Hive 表中。
有关 Hive 的详细信息,请参阅[将 Apache Hive 与 HDInsight 配合使用][hdinsight-use-hive]。
Sqoop 操作将新 Hive 表的内容导出到在 Azure SQL 数据库中创建的表。 有关 Sqoop 的详细信息,请参阅将 Apache Sqoop 与 HDInsight 配合使用。
注意
有关在 HDInsight 群集上支持的 Oozie 版本,请参阅 HDInsight 提供的 Hadoop 群集版本有哪些新增功能?。
创建工作目录
Oozie 希望将作业所需的所有资源存储在同一个目录中。 本示例使用 wasbs:///tutorials/useoozie。 若要创建此目录,请完成以下步骤:
编辑以下代码,将
sshuser替换为群集的 SSH 用户名,将CLUSTERNAME替换为群集名称。 然后输入相应的代码,以使用 SSH 连接到 HDInsight 群集。ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.cn若要创建此目录,请使用以下命令:
hdfs dfs -mkdir -p /tutorials/useoozie/data注意
-p参数用于在路径中创建所有目录。data目录用于保存useooziewf.hql脚本使用的数据。编辑以下代码,将
sshuser替换为你的 SSH 用户名。 若要确保 Oozie 可以模拟用户帐户,请使用以下命令:sudo adduser sshuser users注意
可以忽略指出用户已是
users组的成员的错误。
添加数据库驱动程序
此工作流使用 Sqoop 将数据导出到 SQL 数据库。 因此必须提供用于与 SQL 数据库进行交互的 JDBC 驱动程序的副本。 若要将 JDBC 驱动程序复制到工作目录,请在 SSH 会话中使用以下命令:
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
重要
验证 /usr/share/java/ 中是否实际存在 JDBC 驱动程序。
如果工作流使用了其他资源,例如包含 MapReduce 应用程序的 jar,则还需要添加这些资源。
定义 Hive 查询
使用以下步骤创建用于定义查询的 Hive 查询语言 (HiveQL) 脚本。 在本文档稍后的 Oozie 工作流中要使用此查询。
在 SSH 连接中,使用以下命令创建名为
useooziewf.hql的文件:nano useooziewf.hql打开 GNU nano 编辑器后,使用以下查询作为该文件的内容:
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;脚本中使用了两个变量:
${hiveTableName}:包含要创建的表的名称。${hiveDataFolder}:包含存储表数据文件的位置。工作流定义文件(本文中的 workflow.xml)在运行时会将这些值传递到此 HiveQL 脚本。
若要保存文件,请按 Ctrl+X,输入 Y,再按 Enter。
使用以下命令将
useooziewf.hql复制到wasbs:///tutorials/useoozie/useooziewf.hql:hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hql此命令将
useooziewf.hql文件存储在群集的 HDFS 兼容存储上。
定义工作流
Oozie 工作流定义以 Hadoop 过程定义语言(缩写为 hPDL,一种 XML 过程定义语言)编写。 使用以下步骤定义工作流:
使用以下语句创建并编辑新文件:
nano workflow.xml打开 nano 编辑器后,输入以下 XML 作为文件内容:
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>该工作流中定义了两个操作:
RunHiveScript:此操作是启动操作,它运行useooziewf.hqlHive 脚本。RunSqoopExport:此操作使用 Sqoop 将创建的数据从 Hive 脚本导出到 SQL 数据库。 仅当RunHiveScript操作成功时才运行此操作。工作流包含多个条目,例如
${jobTracker}。 将这些条目替换为在作业定义中使用的值。 本文档稍后会创建作业定义。另请注意 Sqoop 节中的
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>条目。 该条目指示在运行此操作时 Oozie 要将此存档提供给 Sqoop 使用。
若要保存文件,请按 Ctrl+X,输入 Y,再按 Enter。
使用以下命令将
workflow.xml文件复制到/tutorials/useoozie/workflow.xml:hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
创建表
注意
有多种方法可连接到 SQL 数据库以创建表。 以下步骤从 HDInsight 群集使用 FreeTDS 。
使用以下命令在 HDInsight 群集上安装 FreeTDS:
sudo apt-get --assume-yes install freetds-dev freetds-bin编辑以下代码,将
<serverName>替换为逻辑 SQL 服务器名称,将<sqlLogin>替换为服务器登录名。 输入相应的命令以连接到必备的 SQL 数据库。 在提示符下输入密码。TDSVER=8.0 tsql -H <serverName>.database.chinacloudapi.cn -U <sqlLogin> -p 1433 -D oozietest会收到类似于以下文本的输出:
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>在
1>提示符下,输入以下行:CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GO输入
GO语句后,会评估前面的语句。 这些语句创建一个名为mobiledata的表,供工作流使用。若要验证是否已创建该表,请使用以下命令:
SELECT * FROM information_schema.tables GO会看到类似于以下文本的输出:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLE在
exit提示符下输入1>以退出 tsql 实用工具。
创建作业定义
作业定义说明了可在何处找到 workflow.xml。 它还说明可在何处找到工作流使用的其他文件(例如 useooziewf.hql)。 此外,它还定义工作流中使用的属性值以及关联的文件。
若要获取默认存储的完整地址,请使用以下命令。 在下一步骤中创建的配置文件中会使用此地址。
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xml此命令将返回类似以下 XML 的信息:
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.chinacloudapi.cn</value>注意
如果 HDInsight 群集使用 Azure 存储作为默认存储,则
<value>元素内容以wasbs://开头。 如果使用 Azure Data Lake Storage Gen2,则以abfs://开头。保存
<value>元素的内容,因为下一个步骤中将使用该内容。按如下所示编辑以下 xml:
占位符值 替换的值 wasbs://mycontainer@mystorageaccount.blob.core.chinacloudapi.cn 从步骤 1 获取的值。 管理员 HDInsight 群集的登录名(如果不是 admin)。 serverName Azure SQL 数据库服务器名称。 sqlLogin Azure SQL 数据库服务器登录名。 sqlPassword Azure SQL 数据库服务器登录密码。 <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.chinacloudapi.cn</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.chinacloudapi.cn/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.chinacloudapi.cn/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.chinacloudapi.cn;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.chinacloudapi.cn/tutorials/useoozie</value> </property> </configuration>此文件中的大多数信息用于填充 workflow.xml 或 ooziewf.hql 文件中使用的值(例如
${nameNode})。 如果该路径是wasbs路径,则必须使用完整路径。 不要将其缩短为wasbs:///。oozie.wf.application.path条目定义查找 workflow.xml 文件的位置。 此文件包含此作业运行的工作流。若要创建 Oozie 作业定义配置,请使用以下命令:
nano job.xml打开 nano 编辑器后,粘贴编辑后的 XML 作为文件内容。
若要保存文件,请按 Ctrl+X,输入 Y,再按 Enter。
提交和管理作业
以下步骤使用 Oozie 命令提交和管理群集上的 Oozie 工作流。 Oozie 命令是基于 Oozie REST API的友好界面。
重要
使用 Oozie 命令时,必须使用 HDInsight 头节点的 FQDN。 只能从群集访问此 FQDN,如果群集位于 Azure 虚拟网络中,则必须从同一个网络中的其他计算机来访问它。
若要获取 Oozie 服务的 URL,请使用以下命令:
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xml此命令返回类似以下 XML 的信息:
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.chinacloudapp.cn:11000/oozie</value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.chinacloudapp.cn:11000/oozie部分是要配合 Oozie 命令使用的 URL。编辑代码,将 URL 替换为前面收到的 URL。 若要创建 URL 的环境变量,请使用以下命令,这样就不需要为每个命令输入该 URL:
export OOZIE_URL=http://HOSTNAMEt:11000/oozie若要提交作业,请使用以下代码:
oozie job -config job.xml -submit此命令从
job.xml加载作业信息,并将作业信息提交到 Oozie,但不运行该作业。命令完成后,应返回作业的 ID,例如
0000005-150622124850154-oozie-oozi-W。 此 ID 用于管理作业。编辑以下代码,将
<JOBID>替换为上一步骤返回的 ID。 若要查看作业的状态,请使用以下命令:oozie job -info <JOBID>此命令返回类似于以下文本的信息:
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------此作业的状态为
PREP。 此状态指示作业已创建,但是未启动。编辑以下代码,将
<JOBID>替换为前面返回的 ID。 若要启动作业,请使用以下命令:oozie job -start <JOBID>如果在运行此命令后检查状态,会发现作业处于正在运行状态,并且返回了作业中操作的信息。 该作业可能需要几分钟时间才能完成。
编辑以下代码,将
<serverName>替换为服务器名称,将<sqlLogin>替换为服务器登录名。 任务成功完成后,可以使用以下命令验证是否已生成数据并已将其导出到 SQL 数据库表。 在提示符下输入密码。TDSVER=8.0 tsql -H <serverName>.database.chinacloudapi.cn -U <sqlLogin> -p 1433 -D oozietest在
1>提示符下,输入以下查询:SELECT * FROM mobiledata GO返回的信息类似于以下文本:
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
有关 Oozie 命令的详细信息,请参阅 Apache Oozie 命令行工具。
Oozie REST API
借助 Oozie REST API 可以构建自己的工具来使用 Oozie。 下面是有关在 HDInsight 中使用 Oozie REST API 的具体信息:
URI:可从群集(位于
https://CLUSTERNAME.azurehdinsight.cn/oozie)外部访问 REST API。身份验证:若要进行身份验证,请结合群集 HTTP 帐户(管理员)和密码使用该 API。 例如:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.cn/oozie/versions
有关如何使用 Oozie REST API 的详细信息,请参阅 Apache Oozie Web 服务 API。
Oozie Web UI
Oozie Web UI 提供基于 Web 的视图来显示群集上 Oozie 作业的状态。 使用 Web UI 可查看以下信息:
- 作业状态
- 作业定义
- 配置
- 作业中操作的关系图
- 作业的日志
还可以查看作业中操作的详细信息。
若要访问 Oozie Web UI,请完成以下步骤:
与 HDInsight 群集建立 SSH 隧道。 有关详细信息,请参阅将 SSH 隧道与 HDInsight 配合使用。
创建隧道后,在 Web 浏览器中使用 URI
http://headnodehost:8080打开 Ambari Web UI。在页面左侧,选择“Oozie”“快速链接”>“Oozie Web UI”。>
Oozie Web UI 默认显示正在运行的工作流作业。 若要查看所有工作流作业,请选择“所有作业”。
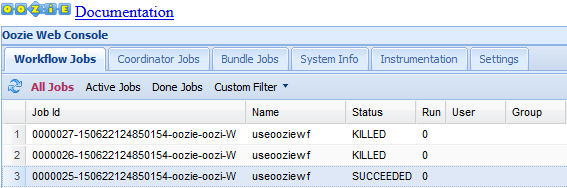
若要查看有关某个作业的详细信息,请选择该作业。
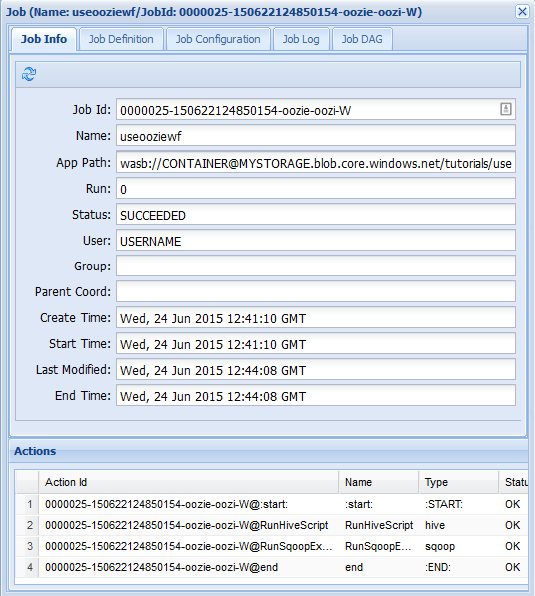
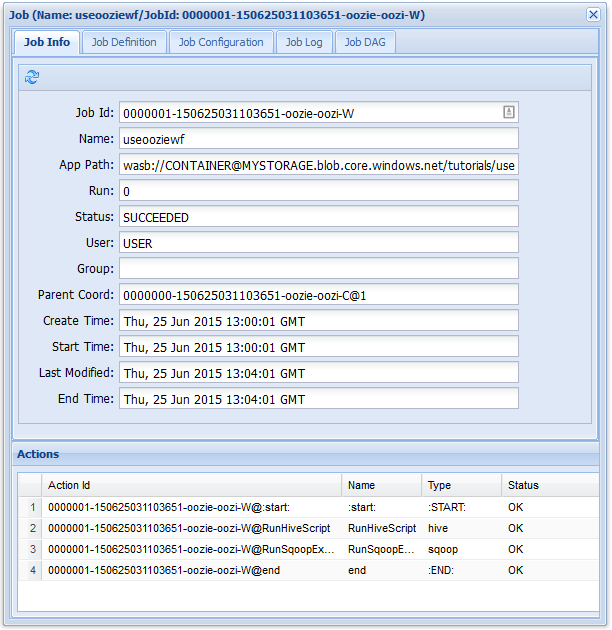
可以在“作业信息”选项卡中查看基本作业信息,以及作业中的各个操作。 可以使用顶部的选项卡查看“作业定义”和“作业配置”,访问“作业日志”,或者在“作业 DAG”下查看作业的有向无环图 (DAG)。
作业日志:选择“获取日志”按钮以获取作业的所有日志,或使用
Enter Search Filter字段来筛选日志。
作业 DAG:DAG 是整个工作流中使用的数据路径的图形概览。
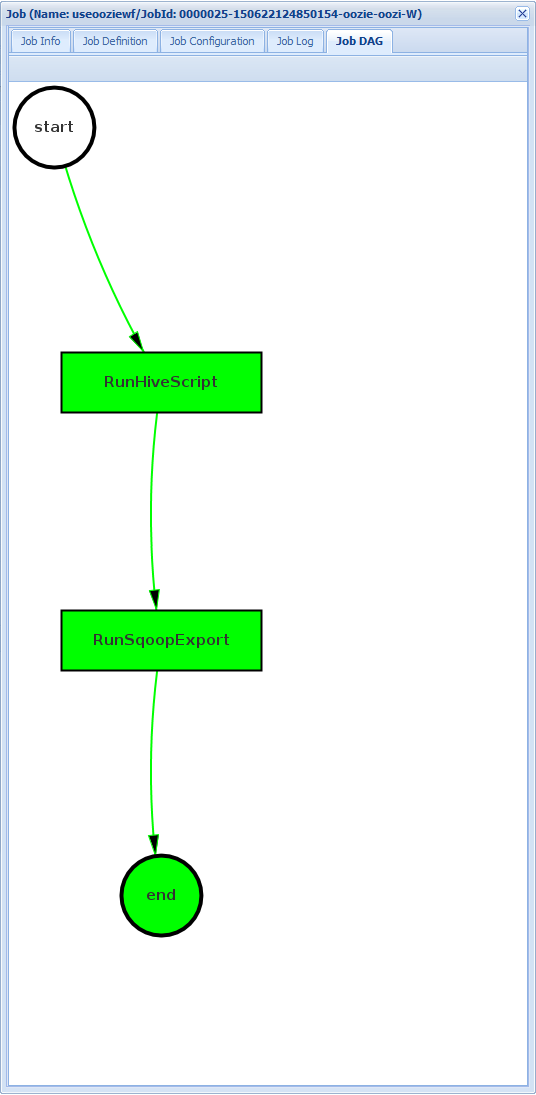
如果在“作业信息”选项卡中选择一个操作,会显示有关该操作的信息。 例如,选择 RunSqoopExport 操作。
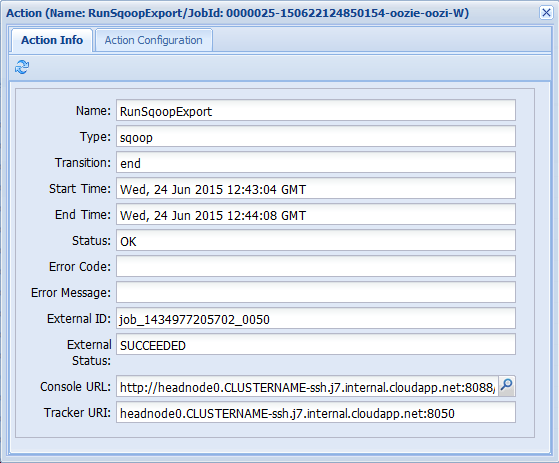
可以看到操作的详细信息,例如控制台 URL 的链接。 使用此链接可查看作业的作业跟踪器信息。
计划作业
可以使用协调器指定作业的开始时间、结束时间和发生频率。 若要定义工作流的计划,请完成以下步骤:
使用以下命令创建名为 coordinator.xml 的文件:
nano coordinator.xml将以下 XML 用作该文件的内容:
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>注意
${...}变量在运行时会替换为作业定义中的值。 变量包括:-
${coordFrequency}:运行作业实例的间隔时间。 -
${coordStart}:作业开始时间。 -
${coordEnd}:作业结束时间。 -
${coordTimezone}:在没有夏时制的固定时区(通常用 UTC 表示)处理协调器作业。 此时区被称为“Oozie 处理时区”。 -
${wfPath}:workflow.xml 的路径。
-
若要保存文件,请按 Ctrl+X,输入 Y,再按 Enter。
若要将该文件复制到此作业的工作目录,请使用以下命令:
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xml若要修改前面创建的
job.xml文件,请使用以下命令:nano job.xml进行以下更改:
若要指示 Oozie 运行协调器文件而不是工作流,请将
<name>oozie.wf.application.path</name>更改为<name>oozie.coord.application.path</name>。若要设置协调器使用的
workflowPath变量,请添加以下 XML:<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.chinacloudapi.cn/tutorials/useoozie</value> </property>将
wasbs://mycontainer@mystorageaccount.blob.core.windows文本替换为 job.xml 文件中的其他条目使用的值。若要定义协调器的开始时间、结束时间和频率,请添加以下 XML:
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>这些值将开始时间设置为 2018 年 5 月 10 日中午 12:00,将结束时间设置为 2018 年 5 月 12 日。 此作业的运行时间间隔已设置为“每日”。 频率以分钟为单位,因此 24 小时 x 60 分钟 = 1440 分钟。 最后,将时区设置为 UTC。
若要保存文件,请按 Ctrl+X,输入 Y,再按 Enter。
若要提交并启动该作业,请使用以下命令:
oozie job -config job.xml -run如果转到 Oozie Web UI 并选择“协调器作业”选项卡,会看到下图所示的信息:

“下一次具体化”条目包含下次运行作业的时间。
与前面的工作流作业一样,在 Web UI 中选择作业条目会显示有关该作业的信息:
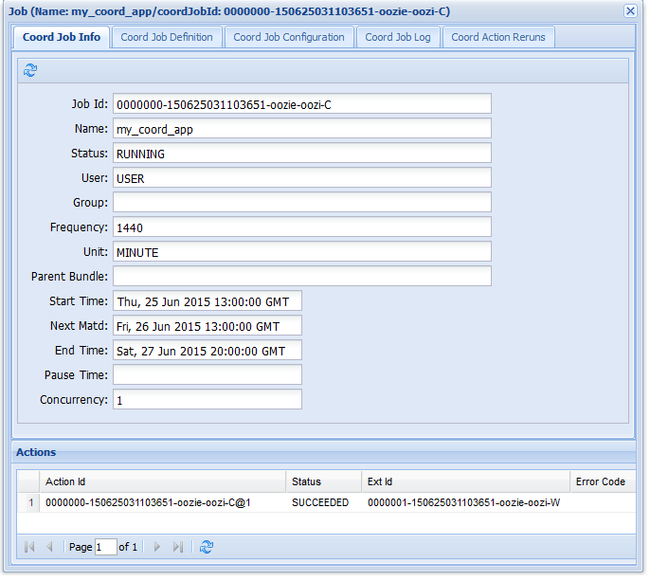
注意
此图像只显示了作业的成功运行结果,而未显示计划工作流中的单个操作。 若要查看单个操作,请选择某个“操作”条目。
后续步骤
本文介绍了如何定义 Oozie 工作流,以及如何运行 Oozie 作业。 若要详细了解如何使用 HDInsight,请参阅以下文章: