此笔记本演示如何将自定义库与 HDInsight 上的 Apache Spark 配合使用来分析日志数据。 我们使用的自定义库是一个名为 iislogparser.py 的 Python 库。
先决条件
HDInsight 上的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。
将原始数据另存为 RDD
在本部分,我们使用与 HDInsight 中的 Apache Spark 群集关联的 Jupyter Notebook 来运行用于处理原始示例数据并将其保存为 Hive 表的作业。 示例数据是所有群集在默认情况下均会提供的 .csv 文件 (hvac.csv)。
将数据保存为 Apache Hive 表之后,下一部分我们将使用 Power BI 和 Tableau 等 BI 工具来连接该 Hive 表。
在 Web 浏览器中,导航到
https://CLUSTERNAME.azurehdinsight.cn/jupyter,其中CLUSTERNAME是群集的名称。创建新的笔记本。 依次选择“新建”、“PySpark”。
 Notebook" border="true":::
Notebook" border="true":::新笔记本随即已创建,并以 Untitled.pynb 名称打开。 选择顶部的笔记本名称,并输入一个友好名称。
由于笔记本是使用 PySpark 内核创建的,因此无需显式创建任何上下文。 运行第一个代码单元格时,系统会自动创建 Spark 和 Hive 上下文。 首先可以导入此方案所需的类型。 将以下代码片段粘贴到空白单元格中,然后按“Shift + Enter”。
from pyspark.sql import Row from pyspark.sql.types import *使用群集上已可用的示例日志数据创建 RDD。 可以在
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log中访问与群集关联的默认存储帐户中的数据。 执行以下代码:logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')检索示例日志集以验证上一步是否成功完成。
logs.take(5)应该会看到与以下文本类似的输出:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
使用自定义 Python 库分析日志数据
在上面的输出中,前几行包括标头信息,其余的每一行均与此标头中描述的架构相匹配。 分析此类日志可能很复杂。 因此,可使用自定义 Python 库 (iislogparser.py),它能使分析这类日志变得容易得多。 默认情况下,此库包含在 HDInsight 上的 Spark 群集的
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py中。但是,此库不在
PYTHONPATH中,因此不能通过import iislogparser之类的导入语句来使用它。 要使用此库,必须将其分发给所有从节点。 运行以下代码段。sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')如果日志行是标题行,并且在遇到日志行时返回
LogLine类的实例,则iislogparser提供返回None的函数parse_log_line。 使用LogLine类从 RDD 中仅提取日志行:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()检索一些提取的日志行,以验证该步骤是否成功完成。
logLines.take(2)输出应类似于以下文本:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]反过来,
LogLine类具有一些有用的方法,如is_error(),可返回日志条目是否具有错误代码。 使用此类来计算提取的日志行中的错误数,然后将所有错误记录到另一个文件中。errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')输出应指示
There are 30 errors and 646 log entries。还可以使用 Matplotlib 构造数据的可视化效果。 例如,如果要找出请求长时间运行的原因,可能需要查找平均执行时间最长的文件。 下面的代码段检索执行请求花费时间最长的前 25 个资源。
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])应该看到输出类似于以下文本:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]还可以在此绘图窗体中显示此信息。 创建绘图的第一步是创建一个临时表 AverageTime。 该表按照时间对日志进行分组,以查看在任何特定时间是否有任何异常延迟峰值。
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')接下来可以运行以下 SQL 查询以获取 AverageTime 表中的所有记录。
%%sql -o averagetime SELECT * FROM AverageTime后接
-o averagetime的%%sqlmagic 可确保查询输出本地保存在 Jupyter 服务器上(通常在群集的头节点)。 输出将作为 Pandas 数据帧进行保存,指定名称为“averagetime”。应看到如下图所示的输出:
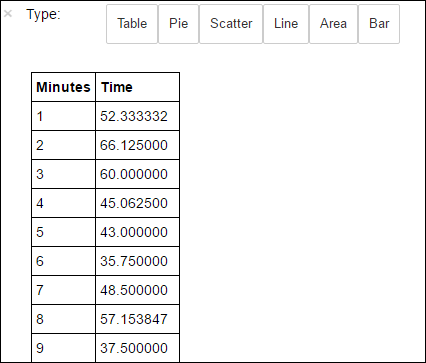 yter sql query output" border="true":::
yter sql query output" border="true":::有关
%%sqlmagic 的详细信息,请参阅 %%sql magic 支持的参数。现在可以使用 Matplotlib(用于构造数据可视化的库)来创建绘图。 因为必须从本地保存的 averagetime 数据帧中创建绘图,所以代码片段必须以
%%localmagic 开头。 这可确保代码在 Jupyter 服务器上本地运行。%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')应看到如下图所示的输出:
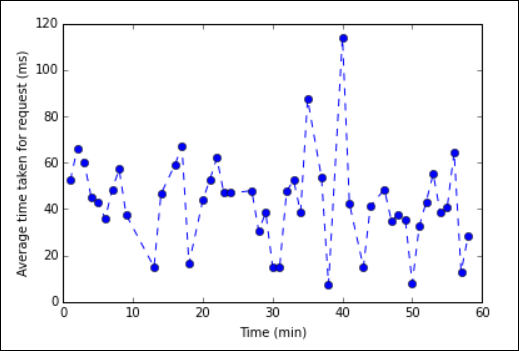 eb log analysis plot" border="true":::
eb log analysis plot" border="true":::完成运行应用程序之后,应该要关闭 Notebook 以释放资源。 为此,请在 Notebook 的“文件”菜单中选择“关闭并停止” 。 此操作会关闭笔记本。
后续步骤
浏览以下文章: