本文介绍如何使用 Spark magic 安装具有自定义 PySpark(适用于 Python)和 Apache Spark(适用于 Scala)内核的 Jupyter Notebook。 然后将笔记本连接到 HDInsight 群集。
安装 Jupyter 并连接到 HDInsight 上的 Apache Spark 涉及到四个重要步骤。
- 配置 Spark 群集。
- 安装 Jupyter Notebook。
- 安装 PySpark 和具有 Spark magic 的 Spark 内核。
- 配置 Spark magic 以访问 HDInsight 上的 Spark 群集。
有关自定义内核和 Spark magic 的详细信息,请参阅适用于装有 HDInsight 上的 Apache Spark Linux 群集的 Jupyter Notebook 的内核。
先决条件
HDInsight 上的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。 本地笔记本会连接到 HDInsight 群集。
熟悉 Jupyter Notebook 和 Spark on HDInsight 的结合使用。
在计算机上安装 Jupyter Notebook
先安装 Python,然后再安装 Jupyter Notebook。 Anaconda 分发版将安装 Python 和 Jupyter Notebook。
下载适用于用户的平台的 Anaconda 安装程序 ,并运行安装。 运行安装向导时,请确保选择将 Anaconda 添加到 PATH 变量的选项。 另请参阅使用 Anaconda 安装 Jupyter。
安装 Spark magic
输入
pip install sparkmagic==0.13.1命令以安装适用于 HDInsight 群集 3.6 版和 4.0 版的 Spark magic。 另请参阅 sparkmagic 文档。确保通过运行以下命令正确安装了
ipywidgets:jupyter nbextension enable --py --sys-prefix widgetsnbextension
安装 PySpark 和 Spark 内核
通过输入以下命令确定
sparkmagic的安装位置:pip show sparkmagic然后,将工作目录更改为使用上述命令确定的位置。
从新的工作目录输入下面的一个或多个命令,以安装所需的内核:
内核 命令 Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel可选。 输入以下命令以启用服务器扩展:
jupyter serverextension enable --py sparkmagic
配置 Spark magic 以连接到 HDInsight Spark 群集
在本部分中,将之前安装的 Spark magic 配置为连接到 Apache Spark 群集。
使用以下命令启动 Python shell:
pythonJupyter 配置信息通常存储在用户主目录中。 输入以下命令来标识主目录,并创建一个名为 .sparkmagic 的文件夹。 将输出完整路径。
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()在文件夹
.sparkmagic中,创建名为 config.json 的文件,并在该文件中添加以下 JSON 代码片段。{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.cn/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.cn/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }对该文件进行以下编辑:
模板值 新值 {USERNAME} 群集登录名,默认为 admin。{CLUSTERDNSNAME} 群集名称 {BASE64ENCODEDPASSWORD} 实际密码的 base64 编码密码。 可在 https://www.url-encode-decode.com/base64-encode-decode/ 中生成 base64 密码。 "livy_server_heartbeat_timeout_seconds": 60如果使用 sparkmagic 0.12.7(群集 v3.5 和 v3.6),请保留此值。 如果使用sparkmagic 0.2.3(群集 v3.4),请替换为"should_heartbeat": true。可在示例 config.json 中查看完整的示例文件。
提示
发送检测信号,以确保会话不会泄漏。 当计算机转到睡眠或关闭状态时,将不会发送检测信号,从而导致会话被清除。 对于群集 v3.4,如果要禁用此行为,可以从 Ambari UI 将 Livy 配置
livy.server.interactive.heartbeat.timeout设置为0。 对于群集 v3.5,如果未设置上述 3.5 配置,会话不会删除。启动 Jupyter。 从命令提示符使用以下命令。
jupyter notebook验证是否可以使用内核随附的 Spark magic。 完成以下步骤。
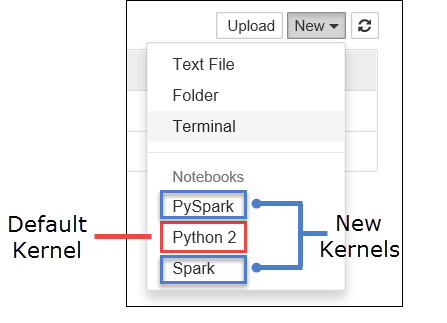
a. 创建新的笔记本。 在右侧一角选择“新建”。 应会看到默认内核 Python 2 和 Python 3,以及安装的内核。 实际值根据安装时所做的选择而有所不同。 选择“PySpark”。
重要
选择“新建”后,检查 shell 中是否出现任何错误。 如果看到错误
TypeError: __init__() got an unexpected keyword argument 'io_loop',原因可能是遇到了某些 Tornado 版本中的已知问题。 如果出现此情况,请停止内核,然后使用以下命令降级 Tornado 安装:pip install tornado==4.5.3。b. 运行以下代码片段。
%%sql SELECT * FROM hivesampletable LIMIT 5如果可以成功检索输出,则表示与 HDInsight 群集的连接已经过测试。
若要更新笔记本配置以连接到不同的群集,请使用一组新值更新 config.json,如上述步骤 3 中所示。
为何要在计算机上安装 Jupyter?
在计算机上安装 Jupyter 并将其连接到 HDInsight 上的 Apache Spark 群集的原因:
- 提供了此选项:在本地创建笔记本,针对正在运行的群集测试应用程序,然后将笔记本上传到群集。 若要将笔记本上传到群集,可以使用在群集上运行的 Jupyter Notebook 上传它们,或者将它们保存到与群集关联的存储帐户中的
/HdiNotebooks文件夹。 有关如何在群集上存储笔记本的详细信息,请参阅 Jupyter Notebook 存储在何处? - 使用本地提供的笔记本可以根据应用程序要求连接到不同的 Spark 群集。
- 可以使用 GitHub 实施源代码管理系统,并对笔记本进行版本控制。 此外,还可以建立一个协作环境,其中的多个用户可以使用同一个笔记本。
- 甚至不需要启动群集就能在本地使用笔记本。 只需创建一个群集以根据它来测试笔记本,而不需要手动管理笔记本或开发环境。
- 配置自己的本地开发环境比在群集上配置 Jupyter 安装更容易。 可以利用本地安装的所有软件,而不需要配置一个或多个远程群集。
警告
在本地计算机上安装 Jupyter 后,多个用户可以同时在同一个 Spark 群集上运行同一个笔记本。 在这种情况下,会创建多个 Livy 会话。 如果遇到问题并想要调试,则跟踪哪个 Livy 会话属于哪个用户将是一项复杂的任务。