了解如何在 HDInsight 上的 Apache Spark 群集中配置 Jupyter Notebook,以使用未现成包含在群集中的、由社区贡献的外部 Apache maven 包。
可以搜索 Maven 存储库获取可用包的完整列表。 也可以从其他源获取可用包的列表。 例如, Spark 包中提供了社区贡献包的完整列表。
本文介绍如何将 spark-csv 包与 Jupyter Notebook 配合使用。
先决条件
HDInsight 上的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。
熟悉 Jupyter Notebook 和 Spark on HDInsight 的结合使用。 有关详细信息,请参阅使用 Apache Spark on HDInsight 加载数据并运行查询。
群集主存储的 URI 方案。 对于 Azure 存储,此值为
wasb://;对于 Azure Data Lake Storage Gen2,此值为abfs://。 如果为 Azure 存储或 Data Lake Storage Gen2 启用了安全传输,则 URI 将是wasbs://或abfss://。另请参阅安全传输。
将外部包与 Jupyter Notebook 配合使用
导航至
https://CLUSTERNAME.azurehdinsight.cn/jupyter,其中CLUSTERNAME是 Spark 群集的名称。创建新的笔记本。 选择“新建”,然后选择“Spark”。
新笔记本随即已创建,并以 Untitled.pynb 名称打开。 选择顶部的笔记本名称,并输入一个友好名称。
我们将使用
%%configuremagic 将笔记本配置为使用外部包。 在使用外部包的笔记本中,确保在第一个代码单元中调用%%configuremagic。 这可以确保将内核配置为在启动会话之前使用该包。重要
如果忘记了在第一个单元中配置内核,可以结合
-f参数使用%%configure,但这会重新启动会话,导致所有进度都会丢失。HDInsight 版本 命令 对于 HDInsight 3.5 和 HDInsight 3.6 %%configure{ "conf": {"spark.jars.packages": "com.databricks:spark-csv_2.11:1.5.0" }}对于 HDInsight 3.3 和 HDInsight 3.4 %%configure{ "packages":["com.databricks:spark-csv_2.10:1.4.0"] }上述代码段需要 Maven 中心存储库中外部包的 maven 坐标。 在此代码片段中,
com.databricks:spark-csv_2.11:1.5.0是 spark-csv 包的 maven 坐标。 下面说明了如何构造包的坐标。a. 在 Maven 存储库中找出该包。 在本文中,我们使用 spark-csv。
b. 从存储库中收集 GroupId、ArtifactId 和 Version 的值。 确保收集的值与群集相匹配。 本示例中,我们将使用 Scala 2.11 和 Spark 1.5.0 包,但可能需要选择群集中相应的 Scala 或 Spark 版本的不同版本。 通过在 Spark Jupyter 内核或 Spark 提交上运行
scala.util.Properties.versionString,可以找出群集上的 Scala 版本。 通过在 Jupyter Notebook 上运行sc.version,可以找出群集上的 Spark 版本。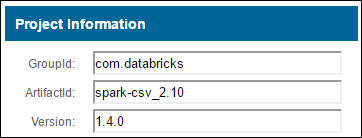
c. 串连这三个值并以冒号分隔 ( : )。
com.databricks:spark-csv_2.11:1.5.0结合
%%configuremagic 运行代码单元。 这会将基础 Livy 会话配置为使用提供的包。 现在,可以在笔记本的后续单元中使用该包,如下所示。val df = spark.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")对于 HDInsight 3.4 及更低版本,应使用以下代码片段。
val df = sqlContext.read.format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")然后,可以运行代码片段(如下所示)以查看上一步创建的数据帧中的数据。
df.show() df.select("Time").count()
另请参阅
方案
- Apache Spark 和 BI:使用 HDInsight 中的 Spark 和 BI 工具执行交互式数据分析
- Apache Spark 和机器学习:使用 HDInsight 中的 Spark 结合 HVAC 数据分析建筑物温度
- Apache Spark 与机器学习:使用 HDInsight 中的 Spark 预测食品检查结果
- 使用 HDInsight 中的 Apache Spark 分析网站日志
创建和运行应用程序
工具和扩展
- 在 HDInsight Linux 上的 Apache Spark 群集中将外部 Python 包与 Jupyter 笔记本配合使用
- 使用适用于 IntelliJ IDEA 的 HDInsight 工具插件创建和提交 Spark Scala 应用程序
- 使用适用于 IntelliJ IDEA 的 HDInsight 工具插件远程调试 Apache Spark 应用程序
- 在 HDInsight 上的 Apache Spark 群集中使用 Apache Zeppelin 笔记本
- 在 HDInsight 的 Apache Spark 群集中可用于 Jupyter Notebook 的内核
- Install Jupyter on your computer and connect to an HDInsight Spark cluster(在计算机上安装 Jupyter 并连接到 HDInsight Spark 群集)