使用 Apache Spark 流式处理可以实现可缩放、高吞吐量、容错的应用程序进行数据流处理。 可将 HDInsight Spark 群集上的 Spark 流式处理应用程序连接到各种数据源,例如 Azure 事件中心、Azure IoT 中心、Apache Kafka、Apache Flume、X、ZeroMQ、原始 TCP 套接字,或者通过这些应用程序监视 Apache Hadoop HDFS 文件系统中发生的更改。 Spark 流支持容错,可保证只会处理任意给定的事件一次,即使某个节点发生故障。
Spark 流式处理创建长时间运行的作业,在此期间,可以对数据应用转换,然后将结果推送到文件系统、数据库、仪表板和控制台。 Spark 流处理微批数据,它首先收集定义的时间间隔内的一批事件。 接下来,发送该批进行处理和输出。 批时间间隔通常以几分之一秒定义。

DStreams
Spark 流使用离散流 (DStream) 表示连续的数据流。 可以从事件中心或 Kafka 等输入源,或通过将转换应用到另一个 DStream,来创建此 DStream。 事件抵达 Spark 流应用程序后,将以可靠的方式存储该事件。 也就是说,会复制事件数据,使多个节点获取它的副本。 这可以确保任一节点发生故障不会导致事件丢失。
Spark 核心使用弹性分布式数据集 (RDD)。 RDD 将数据分布到群集中的多个节点,其中每个节点通常完全在内存中维护其自身的数据,以实现最佳性能。 每个 RDD 表示在某个批间隔内收集的事件。 批间隔时间过后,Spark 流会生成新的 RDD,其中包含该间隔内的所有数据。 此连续 RDD 集将收集到 DStream 中。 Spark 流应用程序处理每个批的 RDD 中存储的数据。

Spark 结构化流作业
Spark 结构化流在 Spark 2.0 中引入,在流式处理结构化数据时用作分析引擎。 Spark 结构化流使用 SparkSQL 批处理引擎 API。 与 Spark 流式处理一样,Spark 结构化流式处理针对连续抵达的数据微批运行自身的计算。 Spark 结构化流以包含无限行的输入表形式表示数据流。 也就是说,随着新数据的抵达,输入表会不断增大。 此输入表由一个长时间运行的查询持续处理,结果将写出到输出表。
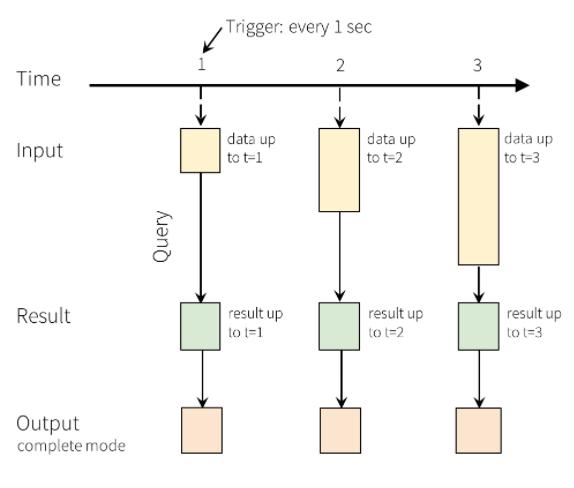
在结构化流中,数据抵达系统后立即被引入输入表中。 可以编写针对此输入表执行操作的查询。 查询输出将生成名为“结果表”的另一个表。 结果表包含查询的结果,从中可以抽取要发送到外部数据存储(例如关系数据库)的数据。 触发器间隔用于设置处理输入表中的数据的时间。 默认情况下,结构化流会在数据抵达时尽快处理数据。 但是,也可以将触发器配置为根据更长的间隔运行,以便在基于时间的批中处理流数据。 每当生成新数据时,可以刷新结果表中的数据,使之包含自开始执行流查询以来生成的所有输出数据(完整模式),或者只包含自上次处理查询以来生成的新数据(追加模式)。
创建容错的 Spark 流作业
若要为 Spark 流式处理作业创建高可用性环境,请先编写单个作业的代码,以便在发生故障时能够恢复。 此类自我恢复作业是容错的。
RDD 包含多个属性,可帮助创建高可用性且容错的 Spark 流式处理作业:
- 在 RDD 中作为 DStream 存储的输入数据批将自动复制到内存中以实现容错。
- 工作节点故障导致数据丢失后,可以基于其他工作节点中复制的输入数据重新计算这些数据(前提是这些工作器节点可用)。
- 在一秒钟即可实现快速故障恢复,因为故障/延迟后的恢复是通过内存中计算发生的。
Spark 流式处理的“恰好一次”语义
若要创建一个处理每个事件一次(且仅一次)的应用程序,请考虑所有系统故障点在出现问题后如何重启,以及如何避免数据丢失。 “恰好一次”语义要求数据在任何时间点都不会丢失,并且不管故障发生在哪个位置,消息处理都可重启。 请参阅创建支持“恰好一次”事件处理的 Spark 流式处理作业。
Spark 流式处理和 Apache Hadoop YARN
在 HDInsight 中,群集工作由 Yet Another Resource Negotiator (YARN) 协调。 设计 Spark 流的高可用性涉及到 Spark 流和 YARN 组件方面的技术。 下面显示了使用 YARN 的示例配置。
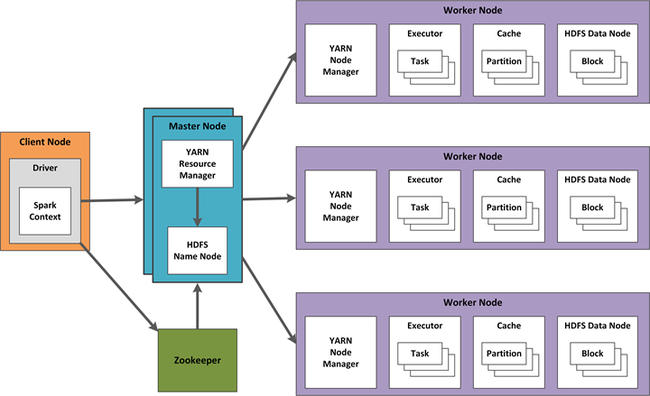
以下部分描述此配置的设计注意事项。
故障规划
若要创建高可用性的 YARN 配置,应该针对可能发生的执行器或驱动程序故障做好规划。 某些 Spark 流作业还包括数据保障要求,需要对此进行额外的配置和设置。 例如,流应用程序可能存在零数据丢失业务保障要求,且不能出现宿主流系统或 HDInsight 群集中发生的任何错误。
如果“执行程序”发生故障,其任务和接收器将由 Spark 自动重启,因此无需进行配置更改。
但是,如果驱动程序发生故障,则其所有关联的执行器都会发生故障,并且所有已收到的块和计算结果都会丢失。 若要在发生驱动程序故障后进行恢复,可以根据创建支持“恰好一次”事件处理的 Spark 流式处理作业使用“DStream 检查点”。 DStream 检查点会定期将 DStreams 的有向无环图 (DAG) 保存到 Azure 存储等容错存储中。 检查点可让 Spark 结构化流根据检查点信息重启有故障的驱动程序。 重启此驱动程序会启动新的执行器,同时重启接收器。
使用 DStream 检查点恢复驱动程序:
使用配置设置
yarn.resourcemanager.am.max-attempts在 YARN 上配置自动驱动程序重启。使用
streamingContext.checkpoint(hdfsDirectory)在 HDFS 兼容的文件系统中设置检查点目录。重构源代码以使用检查点进行恢复,例如:
def creatingFunc() : StreamingContext = { val context = new StreamingContext(...) val lines = KafkaUtils.createStream(...) val words = lines.flatMap(...) ... context.checkpoint(hdfsDir) } val context = StreamingContext.getOrCreate(hdfsDir, creatingFunc) context.start()通过使用
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable","true")启用预写日志 (WAL) 来配置丢失数据的恢复,并使用StorageLevel.MEMORY_AND_DISK_SER针对输入 DStreams 禁用内存中复制。
总之,使用检查点、WAL 和可靠的接收器,可以实现“至少一次”数据恢复:
- 只要收到的数据没有丢失,并且输出是幂等的或事务性的,就会恰好处理数据一次。
- 结合新的 Kafka Direct 方法,使用 Kafka 作为复制的日志,而不是使用接收器或 WAL,可以恰好处理数据一次。
高可用性的一般考虑因素
与批处理作业相比,流式处理作业的监视更困难。 Spark 流作业通常要运行很长时间,而 YARN 只会在作业完成后才聚合日志。 在应用程序或 Spark 升级期间,Spark 检查点会丢失,因此,在升级期间需要清除检查点目录。
将 YARN 群集模式配置为即使客户端发生故障也要运行驱动程序。 设置驱动程序自动重启:
spark.yarn.maxAppAttempts = 2 spark.yarn.am.attemptFailuresValidityInterval=1hSpark 和 Spark 流 UI 提供一个可配置的指标系统。 还可以使用 Graphite/Grafana 等其他库来下载仪表板指标,例如“处理的记录数”、“驱动程序和执行程序上的内存/GC 使用率”、“总延迟时间”、“群集利用率”等等。 在结构化流 2.1 或更高版本中,可以使用
StreamingQueryListener来收集其他指标。应将长时间运行的作业分段。 将 Spark 流应用程序提交到群集后,必须定义运行作业的 YARN 队列。 可以使用 YARN 容量计划程序将长时间运行的作业提交到单独的队列。
正常关闭流应用程序。 如果偏移量是已知的,并且所有应用程序状态存储在外部,则可以在适当的位置以编程方式停止流应用程序。 一种方法是通过每隔 n 秒检查一次外部标志,来使用 Spark 中的“线程挂钩”。 也可以在启动应用程序时使用 HDFS 中创建的标记文件,然后在想要停止应用程序时删除该文件。 对于标记文件方法,可以在 Spark 应用程序中使用一个单独的线程,用于调用如下所示的代码:
streamingContext.stop(stopSparkContext = true, stopGracefully = true) // to be able to recover on restart, store all offsets in an external database