本文介绍 Azure 机器学习设计器中的错误消息和异常代码,以帮助你对机器学习管道进行故障排除。
可以按照以下步骤在设计器中找到错误消息:
选择失败的组件,转到“输出+日志”选项卡,可以在 azureml-logs 类别下的 70_driver_log.txt 文件中找到详细的日志。
对于详细的组件错误,可以在 module_statistics 类别下的 error_info.json 中进行检查。
以下是设计器中组件的错误代码。
错误 0001
如果找不到数据集的一个或多个指定列,将出现异常。
如果为组件选择了列,但所选列不存在于输入数据集中,则将收到此错误。 如果你手动键入了列名或者列选择器提供了建议的列,但运行管道时该列不存在于数据集中,则可能出现此错误。
解决方法:重新访问引发此异常的组件,并验证一个或多个列名称是否正确,以及所有引用的列是否都存在。
| 异常消息 |
|---|
| 找不到一个或多个指定的列。 |
| 找不到名称或索引为“{column_id}”的列。 |
| “{arg_name_missing_column}”中不存在名称或索引为“{column_id}”的列。 |
| 名称或索引为“{column_id}”的列在“{arg_name_missing_column}”中不存在,但在“{arg_name_has_column}”中存在。 |
| 找不到名称或索引为“{column_names}”的列。 |
| 名称或索引为“{column_names}”的列在“{arg_name_missing_column}”中不存在。 |
| 名称或索引为“{column_names}”的列在“{arg_name_missing_column}”中不存在,但在“{arg_name_has_column}”中存在。 |
错误 0002
如果无法将一个或多个参数从指定类型分析或转换为目标方法所需的类型,将出现异常。
在将参数指定为输入且值类型不同于预期类型,并且无法执行隐式转换时,Azure 机器学习中会出现此错误。
解决方法:检查组件要求并确定需要哪种值类型(string、integer、double 等)
| 异常消息 |
|---|
| 无法分析参数。 |
| 无法分析“{arg_name_or_column}”参数。 |
| 无法将“{arg_name_or_column}”参数转换为“{to_type}”。 |
| 无法将“{arg_name_or_column}”参数从“{from_type}”转换为“{to_type}”。 |
| 无法将“{arg_name_or_column}”参数值从“{arg_value}”转换为“{to_type}”。 |
| 无法使用提供的“{fmt}”格式将列“{arg_name_or_column}”中的值“{arg_value}”从“{from_type}”转换为“{to_type}”。 |
错误 0003
如果一个或多个输入为 NULL 或为空,将出现异常。
如果组件的任何输入或参数为 null 或为空,则将在 Azure 机器学习中收到此错误。 例如,如果未键入参数的任何值,则可能会出现此错误。 如果选择了包含缺少的值的数据集或空数据集,也可能出现此错误。
解决方法:
- 打开生成该异常的组件,并验证是否已指定所有输入。 请确保指定了所有必需的输入。
- 请确保可以访问从 Azure 存储加载的数据,并且帐户名称或密钥未发生更改。
- 检查输入数据是否包含缺少的值或为 NULL。
- 如果对数据源使用查询,请验证数据是否以预期的格式返回。
- 检查拼写错误或者数据规范中的其他更改。
| 异常消息 |
|---|
| 一个或多个输入为 null 或为空。 |
| 输入“{name}”为 null 或为空。 |
错误 0004
如果参数小于或等于特定值,将出现异常。
如果消息中的参数小于组件处理数据所需的边界值,则将在 Azure 机器学习中收到此错误。
解决方法:重新访问引发该异常的组件,并将参数修改为大于指定值。
| 异常消息 |
|---|
| 参数应大于边界值。 |
| 参数“{arg_name}”的值应大于 {lower_boundary}。 |
| 参数“{arg_name}”的值“{actual_value}”应大于 {lower_boundary}。 |
错误 0005
如果参数小于特定值,将出现异常。
如果消息中的参数小于或等于组件处理数据所需的边界值,则将在 Azure 机器学习中收到此错误。
解决方法:重新访问引发该异常的组件,并将参数修改为大于指定值。
| 异常消息 |
|---|
| 参数应大于或等于边界值。 |
| 参数“{arg_name}”的值应大于或等于 {lower_boundary}。 |
| 参数“{arg_name}”的值“{value}”应大于或等于 {lower_boundary}。 |
错误 0006
如果参数大于或等于指定值,将出现异常。
如果消息中的参数大于或等于组件处理数据所需的边界值,则将在 Azure 机器学习中收到此错误。
解决方法:重新访问引发该异常的组件,并将参数修改为小于指定值。
| 异常消息 |
|---|
| 参数不匹配。 一个参数应小于另一个参数。 |
| 参数“{arg_name}”的值应小于参数“{upper_boundary_parameter_name}”的值。 |
| 参数“{arg_name}”的值“{value}”应小于 {upper_boundary_parameter_name}。 |
错误 0007
如果参数大于特定值,将出现异常。
如果在组件的属性中指定的值大于允许的值,则将在 Azure 机器学习中收到此错误。 例如,可能是指定受支持的日期范围之外的数据,也可能是在只有三列可用时指示使用五列。
如果指定的两个数据集需要以某种方式匹配,也可能会看到此错误。 例如,如果要重命名列,并按索引指定列,则提供的名称数量必须与列索引的数量匹配。 另一个示例可能是使用两列的数学运算,这两列必须具有相同的行数。
解决方法:
- 打开有问题的组件并查看所有数值属性设置。
- 确保所有参数值都在该属性支持的值范围内。
- 如果组件采用多个输入,请确保输入大小相同。
- 检查数据集或数据源是否已更改。 有时,在列数、列数据类型或数据大小发生更改后,以前版本的数据可使用的值将导致错误。
| 异常消息 |
|---|
| 参数不匹配。 一个参数应小于或等于另一个参数。 |
| 参数“{arg_name}”的值应小于或等于参数“{upper_boundary_parameter_name}”的值。 |
| 参数“{arg_name}”的值“{actual_value}”应小于或等于 {upper_boundary}。 |
| 参数“{arg_name}”的值 {actual_value} 应小于或等于参数“{upper_boundary_parameter_name}”的值 {upper_boundary}。 |
| 参数“{arg_name}”的值 {actual_value} 应小于或等于 {upper_boundary_meaning} 值 {upper_boundary}。 |
错误 0008
如果参数不在范围内,将出现异常。
如果消息中的参数在组件处理数据所需的边界值之外,则将在 Azure 机器学习中收到此错误。
例如,如果尝试使用添加行来合并列数不同的两个数据集,则会显示此错误。
解决方法:重新访问引发该异常的组件,并将参数修改为在指定范围内。
| 异常消息 |
|---|
| 参数值不在指定范围内。 |
| 参数“{arg_name}”的值不在范围内。 |
| 参数“{arg_name}”的值应在 [{lower_boundary}, {upper_boundary}] 范围内。 |
| 参数“{arg_name}”的值不在范围内。 {reason} |
错误 0009
如果错误地指定了 Azure 存储帐户名称或容器名称,将出现异常。
当你指定 Azure 存储帐户的参数,但无法解析名称或密码时,Azure 机器学习设计器中会出现此错误。 密码或帐户名称出错可能有多种原因:
- 帐户类型错误。 机器学习设计器不支持某些新的帐户类型。 请参阅导入数据以了解详细信息。
- 输入了不正确的帐户名称
- 帐户已不存在
- 存储帐户的密码错误或已更改
- 未指定容器名称,或者容器不存在
- 未指定完整的文件路径(指向 blob 的路径)
解决方法:
此类问题通常出现在你尝试手动输入帐户名称、密码或容器路径时。 建议对导入数据组件使用新向导,该向导可以帮助你查找和检查名称。
还需检查是否已删除帐户、容器或 blob。 使用另一种 Azure 存储实用工具验证是否已输入正确的帐户名称和密码以及容器是否存在。
Azure 机器学习不支持某些更新的帐户类型。 例如,新的“热”或“冷”存储类型不能用于机器学习。 经典存储帐户和创建为“常规用途”的存储帐户都可以正常工作。
如果已指定 blob 的完整路径,请验证是否将该路径指定为“container/blobname”,以及容器和 blob 是否存在于该帐户中。
该路径不应包含前导斜杠。 例如 /container/blob 是不正确的,应输入为 container/blob 。
| 异常消息 |
|---|
| Azure 存储帐户名称或容器名称不正确。 |
| Azure 存储帐户名称“{account_name}”或容器名称“{container_name}”不正确;应提供 container/blob 格式的容器名称。 |
错误 0010
如果输入数据集的列名应匹配但不匹配,将出现异常。
如果消息中的列索引在两个输入数据集中具有不同的列名称,则将在 Azure 机器学习中收到此错误。
解决方法: 使用编辑元数据或修改原始数据集,使指定的列索引具有相同的列名。
| 异常消息 |
|---|
| 输入数据集中具有相应索引的列具有不同的名称。 |
| 输入数据集(分别为 {dataset1} 和 {dataset2})的列 {col_index} (从零开始)的列名称不同。 |
错误 0011
如果传递的列集参数不适用于任何数据集列,将出现异常。
如果指定的列选择与给定数据集中的任何列都不匹配,则将在 Azure 机器学习中收到此错误。
如果尚未选择列,而组件至少需要一个列才能正常工作,则也可能收到此错误。
解决方法:修改组件中的列选择,以使其适用于数据集中的列。
如果组件要求选择特定列,例如标签列,请验证是否选择了正确的列。
如果选择了不适当的列,请将其删除,然后重新运行管道。
| 异常消息 |
|---|
| 指定的列集不适用于任何数据集列。 |
| 指定的列集“{column_set}”不适用于任何数据集列。 |
错误 0012
如果无法使用传递的参数集创建类实例,将出现异常。
解决方法:此错误对用户而言不可操作,会在将来的版本中弃用。
| 异常消息 |
|---|
| 未训练模型,请先训练模型。 |
| 未训练模型 ({arg_name}),请使用经过训练的模型。 |
错误 0013
如果传递到组件的学习器是无效类型,则会出现异常。
只要已训练的模型与连接的评分组件不兼容,就会发生此错误。
解决方法:
确定训练组件生成的学习器类型,并确定适合该学习器的评分组件。
如果使用任何专用训练组件对模型进行了训练,请仅将经过训练的模型连接到相应的专用评分组件。
| 模型类型 | 训练组件 | 评分组件 |
|---|---|---|
| 任何分类器 | 训练模型 | 评分模型 |
| 任何回归模型 | 训练模型 | 评分模型 |
| 异常消息 |
|---|
| 传递了无效类型的学习器。 |
| 学习器“{arg_name}”的类型无效。 |
| 学习器“{arg_name}”的类型“{learner_type}”无效。 |
| 传递了无效类型的学习器。 异常消息: {exception_message} |
错误 0014
如果列中唯一值计数大于允许值,将出现异常。
当列包含的唯一值(如 ID 列或文本列)过多时,将出现此错误。 如果你指定将某列作为分类数据进行处理,但由于列中的唯一值过多而难以完成处理,则可能会看到此错误。 如果两个输入中的唯一值数目不匹配,也可能会看到此错误。
如果同时满足以下条件,将出现唯一值大于允许值的错误:
- 一列中超过 97% 的实例是唯一值,这意味着几乎所有类别都互不相同。
- 一列有超过 1000 个唯一值。
解决方法:
打开生成该错误的组件,并标识用作输入的列。 对于某些组件,可以右键单击数据集输入,然后选择“可视化”来获取有关各个列的统计信息,包括唯一值的数量及其分布。
对于打算用于分组或分类的列,请采取措施来减少列中的唯一值数目。 根据列的数据类型,可以通过不同的方式减小唯一值数目。
对于在模型训练期间不具有有意义特征的 ID 列,可以使用编辑元数据将该列标记为“清除特征”,这样就不会在训练模型期间使用它。
对于文本列,可以使用“特征哈希”或“从文本中提取 N 元语法特征”组件来预处理文本列。
提示
找不到适合你的情况的解决方案? 可以提供有关此主题的反馈,包括生成该错误的组件的名称以及列的数据类型和基数。 我们将使用此信息提供更具针对性的常见方案的故障排除步骤。
| 异常消息 |
|---|
| 列的唯一值计数大于允许值。 |
| 列“{column_name}”中唯一值的数目大于允许值。 |
| 列“{column_name}”中唯一值的数目超过元组计数 {limitation}。 |
错误 0015
如果数据库连接失败,将出现异常。
如果输入的 SQL 帐户名称、密码、数据库服务器或数据库名称不正确,或者由于数据库或服务器出现问题而无法建立与数据库的连接,将收到此错误。
解决方法: 验证输入的帐户名称、密码、数据库服务器和数据库是否正确,以及指定的帐户是否具有正确的权限级别。 验证当前是否可访问数据库。
| 异常消息 |
|---|
| 建立数据库连接时出错。 |
| 建立数据库连接 {connection_str} 时出错。 |
错误 0016
如果传递给组件的输入数据集应该具有兼容的列类型,而实际没有,将出现异常。
如果在两个或更多个数据集中传递的列的类型不兼容,则将在 Azure 机器学习中收到此错误。
解决方法:使用编辑元数据或修改原始输入数据集 以确保列的类型兼容。
| 异常消息 |
|---|
| 输入数据集中具有相应索引的列具有的类型不兼容。 |
| 训练和测试数据之间的列“{first_col_names}”不兼容。 |
| 列“{first_col_names}”和“{second_col_names}”不兼容。 |
| 列元素类型与输入数据集(分别为 {first_dataset_names} 和 {second_dataset_names})的列“{first_col_names}”(从零开始)不兼容。 |
错误 0017
如果所选列使用的数据类型不受当前组件的支持,将出现异常。
例如,如果列选择包含的列具有组件无法处理的数据类型(例如用于数学运算的字符串列,或需要分类特征列的分数列),则可能会在 Azure 机器学习中收到此错误。
解决方法:
- 确定存在问题的列。
- 查看组件要求。
- 修改列以使其符合要求。 根据列和要进行的转换,可能需要使用以下几个组件来进行更改:
- 使用编辑元数据更改列的数据类型,或者将列用法从特征改为数值、从分类更改为非分类等。
- 万不得已,可能需要修改原始输入数据集。
提示
找不到适合你的情况的解决方案? 可以提供有关此主题的反馈,包括生成该错误的组件的名称以及列的数据类型和基数。 我们将使用此信息提供更具针对性的常见方案的故障排除步骤。
| 异常消息 |
|---|
| 无法处理当前类型的列。 组件不支持该类型。 |
| 无法处理 {col_type} 类型的列。 组件不支持该类型。 |
| 无法处理 {col_type} 类型的列“{col_name}”。 组件不支持该类型。 |
| 无法处理 {col_type} 类型的列“{col_name}”。 组件不支持该类型。 参数名:{arg_name}。 |
错误 0018
如果输入数据集无效,将出现异常。
解决方法:Azure 机器学习中的此错误可能会出现在多个上下文中,因此没有单一的解决方法。 通常,此错误表示作为输入向组件提供的数据的列数有误,或者数据类型不符合组件的要求。 例如:
该组件需要标签列,但没有标记为标签的列,或者尚未选择标签列。
组件要求数据是分类类型,但你的数据是数值类型。
数据格式错误。
导入的数据包含无效字符、错误的值或超出范围的值。
此列为空或包含过多的缺失的值。
若要确定要求和数据应有的格式,请查看将使用数据集作为输入的组件的帮助文章。
。| 异常消息 |
|---|
| 数据集无效。 |
| {dataset1} 包含无效数据。 |
| {dataset1} 和 {dataset2} 的应保持一致。 |
| {dataset1} 包含无效数据,{reason}。 |
| {dataset1} 包含 {invalid_data_category}。 {troubleshoot_hint} |
| {dataset1} 无效,{reason}。 {troubleshoot_hint} |
错误 0019
如果列应该包含已排序的值,但实际没有,将出现异常。
如果指定的列值不按顺序显示,则将在 Azure 机器学习中收到此错误。
解决方法:通过手动修改输入数据集对列值进行排序,然后重新运行组件。
| 异常消息 |
|---|
| 列中的值未排序。 |
| 列“{col_index}”中的值未排序。 |
| 数据集“{dataset}”的列“{col_index}”中的值未排序。 |
| 参数“{arg_name}”中的值未按“{sorting_order}”顺序排序。 |
错误 0020
如果传递到组件的某些数据集中的列数太少,则会发生异常。
如果没有为组件选择足够的列,则将在 Azure 机器学习中收到此错误。
解决方法:重新访问该组件,并确保列选择器选择了正确的列数。
| 异常消息 |
|---|
| 输入数据集中的列数小于允许的最小列数。 |
| 输入数据集“{arg_name}”中的列数小于允许的最小列数。 |
| 输入数据集中的列数小于允许的最小列数({required_columns_count} 列)。 |
| 输入数据集“{arg_name}”中的列数小于允许的最小值 {required_columns_count} 列。 |
错误 0021
如果传递到组件的某些数据集中的行数太少,则会发生异常。
如果数据集中的行不足以执行指定操作,则 Azure 机器学习中会出现此错误。 例如,如果输入数据集为空,或者你尝试执行的操作要求一定的最小有效行数,那么你可能会看到此错误。 此类操作可以包括(但不限于)基于统计方法的分组或分类、某些类型的分箱以及计数学习。
解决方法:
- 打开返回该错误的组件,然后检查输入数据集和组件属性。
- 验证输入数据集是否为空,以及是否有足够的数据行可满足组件帮助中所述的要求。
- 如果数据是从外部源加载的,请确保该数据源可用,并且数据定义中没有错误或更改(它们可能导致输入进程获取的行数减少)。
- 如果要对组件的上游数据执行操作(如清理、拆分或联接操作),而这些操作可能会影响数据类型或值的数量,请检查这些操作的输出以确定返回的行数。
| 异常消息 |
|---|
| 输入数据集中的行数小于允许的最小值。 |
| 输入数据集中的行数小于允许的最小值 {required_rows_count} 行。 |
| 输入数据集中的行数小于允许的最小值 {required_rows_count} 行。 {reason} |
| 输入数据集“{arg_name}”中的行数小于允许的最小值 {required_rows_count} 行。 |
| 输入数据集“{arg_name}”中的行数为 {actual_rows_count},小于允许的最小值 {required_rows_count} 行。 |
| 输入数据集“{arg_name}”中的“{row_type}”行的数量为 {actual_rows_count},小于允许的最小值 {required_rows_count} 行。 |
错误 0022
如果输入数据集中的选定列数不等于预期数量,将出现异常。
当下游组件或操作需要特定数量的列或输入,而你提供的列或输入太少或太多时,Azure 机器学习中可能会出现此错误。 例如:
你要指定单个标签列或键列,但不小心选择了多个列。
你要重命名列,但提供的名称数多于或少于现有的列数。
源或目标中的列数已更改或与组件使用的列数不匹配。
你为输入提供了以逗号分隔的值列表,但值的数量不匹配,或者不支持多个输入。
解决方法:重新访问该组件并检查列选择,以确保选择了正确的列数。 验证上游组件的输出以及下游操作的要求。
如果使用了可选择多个列(列索引、所有特性、所有数字等)的列选择选项,请验证所选内容返回的列数是否准确。
验证上游列的数量或类型是否未发生更改。
如果使用推荐数据集来训练模型,请记住,推荐系统需要有限数量的列,与用户项对或用户项排名相对应。 在训练模型或拆分推荐数据集之前,请删除其他列。 有关详细信息,请参阅拆分数据。
| 异常消息 |
|---|
| 在输入数据集中选择的列数不等于预期数量。 |
| 在输入数据集中选择的列数不等于 {expected_col_count}。 |
| 列选择模式“{selection_pattern_friendly_name}”提供的在输入数据集中选择的列数不等于 {expected_col_count}。 |
| 列选择模式“{selection_pattern_friendly_name}”应提供在输入数据集中选择的 {expected_col_count} 列,但实际上提供了 {selected_col_count} 列。 |
错误 0023
如果输入数据集的目标列不适用于当前训练组件,将出现异常。
如果(组件参数中所选的)目标列不是有效的数据类型、包含的值全部缺失或并非预期的分类数据,则 Azure 机器学习中会出现此错误。
解决方法:重新访问组件输入,以检查标签/目标列的内容。 确保它的值没有全部缺失。 如果组件要求目标列是分类列,请确保目标列中有多个非重复值。
| 异常消息 |
|---|
| 输入数据集包含不支持的目标列。 |
| 输入数据集包含不支持的目标列“{column_index}”。 |
| 输入数据集包含 {learner_type} 类型的学习器不支持的目标列“{column_index}”。 |
错误 0024
如果数据集不包含标签列,将出现异常。
当组件需要标签列而数据集没有标签列时,Azure 机器学习中会出现此错误。 例如,要评估已评分的数据集,通常需要存在标签列以计算准确度指标。
也有可能标签列存在于数据集中,但 Azure 机器学习未正确检测到它。
解决方法:
- 打开生成该错误的组件,确定是否存在标签列。 列的名称或数据类型并不重要,只要该列包含尝试预测的单个结果(或因变量)即可。 如果不确定哪个列具有标签,请查找“类”或“目标”等通用名称。
- 如果数据集不包含标签列,则可能是在上游显式或意外地删除了标签列。 也可能是该数据集不是上游评分组件的输出。
- 若要将列显式标记为标签列,请添加“编辑元数据”组件并连接数据集。 仅选择标签列,然后从“字段”下拉列表中选择“标签” 。
- 如果将错误的列选作了标签,可以从“字段”中选择“清除标签”以恢复该列的元数据 。
| 异常消息 |
|---|
| 数据集中没有标签列。 |
| “{dataset_name}”中没有标签列。 |
错误 0025
如果数据集不包含分数列,将出现异常。
如果评估模型的输入不包含有效的分数列,则 Azure 机器学习中会出现此错误。 例如,用户在使用经训练的适当模型对数据集进行评分之前尝试评估数据集,或者已将分数列显式置于上游。 如果两个数据集上的评分列不兼容,也会出现此异常。 例如,你可能想尝试比较线性回归量与二进制分类器的准确度。
解决方法:重新访问评估模型的输入,并检查它是否包含一个或多个分数列。 如果不是,则未对数据集进行评分,或在上游组件中删除了分数列。
| 异常消息 |
|---|
| 数据集中没有评分列。 |
| “{dataset_name}”中没有评分列。 |
| “{Learner_type}”生成的“{dataset_name}”中没有评分列。 请使用正确类型的学习器为数据集评分。 |
错误 0026
如果不允许使用具有相同名称的列,将出现异常。
如果多个列具有相同的名称,则 Azure 机器学习中会出现此错误。 如果数据集没有标题行,并且自动分配了 Col0、Col1 等列名,你可能会收到此错误。
解决方法:如果列的名称相同,则在输入数据集和组件之间插入“编辑元数据”组件。 使用编辑元数据中的列选择器来选择要重命名的列,并将新名称键入“新列名”文本框中。
| 异常消息 |
|---|
| 在参数中指定了相同的列名。 组件不允许使用相同的列名称。 |
| 不允许在参数“{arg_name_1}”和“{arg_name_2}”中使用相同的列名称。 请指定不同的名称。 |
错误 0027
如果两个对象的大小必须相同但实际不相同,将出现异常。
这是 Azure 机器学习中的常见错误,可能由多种情况引起。
解决方法:没有特定的解决方法。 不过,你可以检查以下情况:
如果要重命名列,请确保每个列表(输入列和新名称列表)具有相同数量的项。
如果要联接或串联两个数据集,请确保它们具有相同的架构。
如果要联接两个具有多个列的数据集,请确保键列具有相同的数据类型,并选择选项“允许重复项并保留选定内容中的列顺序”。
| 异常消息 |
|---|
| 传递的对象大小不一致。 |
| “{friendly_name1}”的大小与“{friendly_name2}”的大小不一致。 |
错误 0028
如果列集包含重复的列名,而这是不允许的,将出现异常。
如果列名重复,即列名不是唯一的,则 Azure 机器学习中会出现此错误。
解决方法:如果任何列具有相同的名称,请在输入数据集和引发该错误的组件之间添加“编辑元数据”的实例。 使用编辑元数据中的列选择器来选择要重命名的列,并将新名称键入“新列名”文本框中。 如果要重命名多个列,请确保在“新列名”中键入的值是唯一的。
| 异常消息 |
|---|
| 列集包含重复的列名。 |
| 名称“{duplicated_name}”是重复的。 |
| 名称“{duplicated_name}”在“{arg_name}”中是重复的。 |
| 名称“{duplicated_name}”是重复的。 详细信息:{details} |
错误 0029
如果传递的 URI 无效,将出现异常。
如果传递的 URI 无效,则 Azure 机器学习中会出现此错误。 如果符合以下任一情况,你将收到此错误:
为 Azure Blob 存储提供的用于读取或写入的公共或 SAS URI 包含错误。
SAS 的时间范围已过期。
通过 HTTP 的 Web URL 源表示文件或环回 URI。
通过 HTTP 的 Web URL 包含格式不正确的 URL。
远程源无法解析该 URL。
解决方法:重新访问该组件并验证 URI 的格式。 如果数据源是通过 HTTP 的 Web URL,请验证预期的源不是文件或环回 URI (localhost)。
| 异常消息 |
|---|
| 传递了无效的 URI。 |
| URI“{invalid_url}”无效。 |
错误 0030
无法下载文件时,会出现异常。
无法下载文件时,Azure 机器学习中会出现此异常。 如果尝试从 HTTP 源读取在重试三次 (3) 后仍然失败,你将收到此异常。
解决方法: 验证 HTTP 源的 URI 是否正确,以及当前是否可通过 Internet 访问该站点。
| 异常消息 |
|---|
| 无法下载文件。 |
| 下载文件 {file_url} 时出错。 |
错误 0031
如果列集中的列数小于所需列数,将出现异常。
如果选择的列数小于所需列数,则 Azure 机器学习中会出现此错误。 如果选择的列数未达到要求的最小值,你将收到此错误。
解决方法: 使用“列选择器”将其他列添加到列选择。
| 异常消息 |
|---|
| 列集中的列数小于所需列数。 |
| 至少需要为输入参数“{arg_name}”指定 {required_columns_count} 列。 |
| 至少需要为输入参数“{arg_name}”指定 {required_columns_count} 列。 指定的实际列数为 {input_columns_count} 列。 |
错误 0032
如果参数不是数字,将出现异常。
如果参数为双精度值或 NaN,你将在 Azure 机器学习中收到此错误。
解决方法: 修改指定的参数以使用有效值。
| 异常消息 |
|---|
| 参数不是数字。 |
| “{arg_name}”不是数字。 |
错误 0033
如果参数是无穷大,将出现异常。
如果参数是无穷大,则 Azure 机器学习中会出现此错误。 如果参数是 double.NegativeInfinity 或 double.PositiveInfinity,则会收到此错误。
解决方法: 将指定的参数修改为有效值。
| 异常消息 |
|---|
| 参数必须为有限数字。 |
| “{arg_name}”不是有限数字。 |
| 列“{column_name}”包含无限值。 |
错误 0034
如果给定的用户项对存在多个评分,将出现异常。
如果用户项对具有多个评分值,则 Azure 机器学习中可能会出现此错误。
解决方法: 确保用户项对只拥有一个评分值。
| 异常消息 |
|---|
| 数据集中的值存在多个评分。 |
| 评分预测数据表中的用户 {user} 和项 {item} 有多个评分。 |
| {dataset} 中的用户 {user} 和项 {item} 有多个评分。 |
错误 0035
如果没有提供给定用户或项的任何特征,将出现异常。
如果你尝试使用建议推荐进行评分,但找不到特征矢量,则 Azure 机器学习中会出现此错误。
解决方法:
使用项特征或用户特征时,必须满足 Matchbox 推荐器的某些要求。 此错误表示你作为输入提供的用户或项缺少特征矢量。 确保每个用户或项的数据中都有特征矢量。
例如,如果你使用用户年龄、位置或收入等特征来训练了推荐模型,但现在想要为训练过程中没有见过的新用户创建评分,则必须为新用户提供一组等效特征(即年龄、位置和收入值),以便为他们做出适当的预测。
如果没有这些用户的任何特征,请考虑使用特征工程来生成相应的特征。 例如,如果你没有单个用户的年龄或收入值,可以生成用于一组用户的近似值。
提示
解决方法不适用于你的情况? 欢迎发送有关本文的反馈,并提供有关你的情况的信息,包括组件和列中的行数。 我们将使用此信息在将来提供更详细的故障排除步骤。
| 异常消息 |
|---|
| 没有为所需的用户或项提供任何特征。 |
| {required_feature_name} 的特征是必需的,但未提供。 |
错误 0036
如果提供了给定用户或项的多种特征,将出现异常。
如果多次定义了特征矢量,则 Azure 机器学习中会出现此错误。
解决方法:确保未多次定义特征矢量。
| 异常消息 |
|---|
| 用户或项存在重复的特征定义。 |
错误 0037
如果指定了多个标签列,但只允许指定一个,将出现异常。
如果选择了多个列作为新标签列,则 Azure 机器学习中会出现此错误。 大多数监督式学习算法要求将单个列标记为目标或标签。
解决方法: 请确保选择单个列作为新标签列。
| 异常消息 |
|---|
| 指定了多个标签列。 |
| 在“{dataset_name}”中指定了多个标签列。 |
错误 0039
如果操作失败,将出现异常。
如果无法完成内部操作,则 Azure 机器学习中会出现此错误。
解决方法:此错误可由多种情况引起,因此没有特定的补救措施。
下表包含此错误的通用消息,后跟具体情况说明。
如果没有可用的详细信息,请访问 Microsoft 问答页以发送反馈,并提供有关生成该错误的组件和相关情况的信息。
| 异常消息 |
|---|
| 操作失败。 |
| 完成操作时出错:“{failed_operation}”。 |
| 完成操作时出错:“{failed_operation}”。 原因:“{reason}”。 |
错误 0042
无法将列转换为另一种类型时,会出现异常。
无法将列转换为指定类型时,Azure 机器学习中会出现此错误。 如果组件需要特定数据类型(例如日期/时间、文本、浮点数或整数),但不能将现有列转换为所需的类型,那么你将收到此错误。
例如,你可以选择一个列,然后尝试将其转换为数值数据类型以用于数学运算,如果该列包含无效数据,你会收到此错误。
如果你尝试将包含浮点数或多个唯一值的列用作分类列,也可能会收到此错误。
解决方法:
- 打开生成该错误的组件的帮助页面,并验证数据类型要求。
- 查看输入数据集中的列的数据类型。
- 检查来自所谓的无架构数据源的数据。
- 检查数据集是否包含缺失的值或特殊字符,它们可能会阻止转换为所需的数据类型。
- 数值数据类型应保持一致,例如,可检查整数列中是否存在浮点数。
- 查找数字列中是否存在文本字符串或 NA 值。
- 根据所需的数据类型,可以将布尔值转换为适当的表示形式。
- 检查文本列中的非 unicode 字符、制表符或控制字符
- 日期/时间数据应保持一致,以免出现建模错误,但清理可能会很复杂,因为存在多种格式。 考虑使用执行 Python 脚本组件执行清理。
- 如有必要,请修改输入数据集中的值,以便可以成功转换该列。 修改可能包括分箱、截断或舍入运算、清除离群值或补充缺少的值。 请参阅以下文章,了解机器学习中的一些常见数据转换方案:
提示
解决方法不明确或不适用于你的情况? 欢迎发送有关本文的反馈,并提供有关你的情况的信息,包括组件和列的数据类型。 我们将使用此信息在将来提供更详细的故障排除步骤。
| 异常消息 |
|---|
| 不允许转换。 |
| 无法将 {type1} 类型的列转换为 {type2} 类型的列。 |
| 无法将 {type1} 类型的列“{col_name1}”转换为 {type2} 类型的列。 |
| 无法将 {type1} 类型的列“{col_name1}”转换为 {type2} 类型的列“{col_name2}”。 |
错误 0044
无法从现有值派生列的元素类型时,会出现此异常。
如果无法推断数据集中的一个或多个列的类型,则 Azure 机器学习中会出现此错误。 这种情况通常发生在连接两个或更多具有不同元素类型的数据集时。 如果 Azure 机器学习无法确定能够在不丢失信息的情况下表示一列或多列中所有值的通用类型,它将生成此错误。
解决方法: 确保要合并的两个数据集中给定列的所有值都是相同的类型(数值、布尔、分类、字符串、日期等)或可以强制为相同类型。
| 异常消息 |
|---|
| 无法派生列的元素类型。 |
| 无法派生列“{column_name}”的元素类型 - 所有元素都是空引用。 |
| 无法派生数据集“{dataset_name}”的列“{column_name}”的元素类型 - 所有元素都是空引用。 |
错误 0045
由于源中存在混合的元素类型而无法创建列时,会出现异常。
如果要合并的两个数据集的元素类型不同,Azure 机器学习中会产生此错误。
解决方法: 确保要合并的两个数据集中给定列的所有值都是相同的类型(数值、布尔、分类、字符串、日期等)。
| 异常消息 |
|---|
| 无法创建具有混合元素类型的列。 |
| 无法创建 ID 为“{column_id}”的混合元素类型的列: 数据[{row_1}, {column_id}]的类型为“{type_1}”。 数据[{row_2}, {column_id}]的类型为“{type_2}”。 |
| 无法创建 ID 为“{column_id}”的混合元素类型的列: 区块 {chunk_id_1} 中的类型为“{type_1}”。 区块 {chunk_id_2} 中的类型为“{type_2}”,区块大小为 {chunk_size}。 |
错误 0046
无法在指定路径上创建目录时,会出现异常。
无法在指定路径上创建目录时,Azure 机器学习中会出现此错误。 如果 Hive 查询的输出目录的任何路径部分不正确或不可访问,你将收到此错误。
解决方法:重新访问该组件,并验证该目录路径的格式是否正确,以及是否可使用当前凭据访问该路径。
| 异常消息 |
|---|
| 请指定有效的输出目录。 |
| 无法创建目录 {path}。 请指定有效的路径。 |
错误 0047
如果传递到组件的某些数据集中的特征列数太少,则会发生异常。
如果要训练的输入数据集不包含算法所需的最小列数,则 Azure 机器学习中会出现此错误。 通常,数据集为空或仅包含训练列。
解决方法: 重新访问输入数据集,以确保除了标签列之外还有一个或多个其他列。
| 异常消息 |
|---|
| 输入数据集中的特征列数小于允许的最小值。 |
| 输入数据集中的特征列数小于允许的最小值 {required_columns_count} 列。 |
| 输入数据集“{arg_name}”中的特征列数小于允许的最小值 {required_columns_count} 列。 |
错误 0048
无法打开文件时,会出现异常。
无法打开文件以进行读取或写入时,Azure 机器学习中会出现此错误。 由于以下原因,你可能会收到此错误:
容器或文件 (blob) 不存在
文件或容器的访问级别不允许你访问该文件
文件过大,无法读取或格式错误
解决方法:重新访问要读取的组件和文件。
验证容器和文件的名称是否正确。
使用 Azure 经典门户或 Azure 存储工具验证你是否有权访问该文件。
| 异常消息 |
|---|
| 无法打开文件。 |
| 打开文件 {file_name} 时出错。 |
| 打开文件 {file_name} 时出错。 存储异常消息: {exception}。 |
错误 0049
无法分析文件时,会出现异常。
无法分析文件时,Azure 机器学习中会出现此错误。 如果在导入数据组件中选择的文件格式与文件的实际格式不匹配,或者文件包含无法识别的字符,则会收到此错误。
解决方法:如果该格式与文件格式不匹配,请重新访问组件并更正文件格式选择。 如果可能,请检查文件以确认它不包含任何非法字符。
| 异常消息 |
|---|
| 无法分析文件。 |
| 解析 {file_format} 文件时出错。 |
| 解析 {file_format} 文件 {file_name} 时出错。 |
| 解析 {file_format} 文件时出错。 原因:{failure_reason}。 |
| 解析 {file_format} 文件 {file_name} 时出错。 原因:{failure_reason}。 |
错误 0052
如果指定的 Azure 存储帐户密钥不正确,将出现异常。
如果用于访问 Azure 存储帐户的密钥不正确,则 Azure 机器学习中会出现此错误。 例如,如果在复制和粘贴 Azure 存储密钥时将其截断了,或者使用了错误的密钥,那么你可能会看到此错误。
有关如何获取 Azure 存储帐户的密钥的详细信息,请参阅查看、复制和重新生成存储访问密钥。
解决方法:重新访问该组件,并验证该帐户的 Azure 存储密钥是否正确;必要时,请从 Azure 经典门户重新复制密钥。
| 异常消息 |
|---|
| Azure 存储帐户密钥不正确。 |
错误 0053
当没有用户特征或项可用于 Matchbox 推荐时,会出现异常。
找不到特征矢量时,Azure 机器学习中会产生此错误。
解决方法: 确保输入数据集中存在特征矢量。
| 异常消息 |
|---|
| 需要用户特征或/和项,但未提供。 |
错误 0056
如果选择用于运算的列违反要求,会出现异常。
如果为要求列为特定数据类型的运算选择列,Azure 机器学习中会出现此错误。
如果该列的数据类型正确,但使用的组件要求同时将该列标记为特征列、标签列或分类列,那么也可能发生此错误。
解决方法:
查看当前选择的列的数据类型。
确定所选列是否为分类列、标签列或特征列。
查看在其中进行列选择的组件的帮助主题,以确定是否对数据类型或列用法有特定要求。
使用编辑元数据在此操作持续期间更改列类型。 如果需要将列用于下游操作,请确保使用编辑元数据的另一个实例,将列类型改回其原始值。
| 异常消息 |
|---|
| 所选的一个或多个列不是允许的类别。 |
| 名称为“{col_name}”的列不是允许的类别。 |
错误 0057
尝试创建已存在的文件或 blob 时,会出现异常。
组件如果使用导出数据组件或其他组件将 Azure 机器学习中的管道结果保存到 Azure blob 存储,但尝试创建已存在的文件或 blob,将出现异常。
解决方法:
只有在之前将属性“Azure blob 存储写入模式”设置为“错误”时,才会收到此错误。 按照设计,如果尝试将数据集写入已存在的 blob,此组件将引发错误。
- 打开组件属性,将“Azure blob 存储写入模式”属性更改为”覆盖”。
- 或者,你可以键入其他目标 blob 或文件的名称,并确保指定尚不存在的 blob。
| 异常消息 |
|---|
| 文件或 Blob 已存在。 |
| 文件或 Blob“{file_path}”已存在。 |
错误 0058
如果数据集不包含所需的标签列,则 Azure 机器学习中会出现此错误。
如果提供的标签列与学习器所需的数据或数据类型不匹配,或具有错误的值,也会发生此异常。 例如,如果在训练二进制分类器时使用实值标签列,则会产生此异常。
解决方法:解决方法取决于所使用的学习器或训练程序,以及数据集中的列的数据类型。 首先,验证机器学习算法或训练组件的要求。
重新访问输入数据集。 验证希望被视作标签的列是否具有要创建的模型的正确数据类型。
检查输入中是否包含缺少的值,如有必要,请删除或替换它们。
如有必要,请添加“编辑元数据”组件,并确保将标签列标记为标签。
| 异常消息 |
|---|
| 不可比较标签列值和已评分的标签列值。 |
| “{dataset_name}”中的标签列不符合预期。 |
| “{dataset_name}”中的标签列不符合预期,{reason}。 |
| “{dataset_name}”中的标签列“{column_name}”不符合预期。 |
| “{dataset_name}”中的标签列“{column_name}”不符合预期,{reason}。 |
错误 0059
如果无法分析列选取器中指定的列索引,将出现异常。
如果无法分析使用列选择器时指定的列索引,Azure 机器学习中会出现此错误。 如果列索引的格式无效且无法进行分析,则会收到此错误。
解决方法: 修改列索引,以使用有效的索引值。
| 异常消息 |
|---|
| 无法分析一个或多个指定的列索引或索引范围。 |
| 无法分析列索引或范围“{column_index_or_range}”。 |
错误 0060
在列选取器中指定的列范围在范围之外时,会出现异常。
在列选取器中指定的范围在列范围之外时,Azure 机器学习中会出现此错误。 如果列选取器中的列范围与数据集中的列不对应,你将收到此错误。
解决方法: 修改列选取器中的列范围,以对应数据集中的列。
| 异常消息 |
|---|
| 指定了无效或超出范围的列索引范围。 |
| 列范围“{column_range}”无效或超出范围。 |
错误 0061
尝试向数据表中添加行,而该行的列数与表不同时,会出现异常。
尝试向数据集中添加行,而该行的列数与数据集不同时,Azure 机器学习中会出现此错误。 如果向数据集中添加行,而该行的列数与输入数据集不同,你将收到此错误。 如果列数不同,则无法将该行追加到数据集。
解决方法: 修改输入数据集,使其与添加的行具有相同的列数;或修改添加的行,使其与数据集具有相同的列数。
| 异常消息 |
|---|
| 所有表必须拥有相同的列数。 |
| 区块“{chunk_id_1}”中的列数与区块大小为 {chunk_size} 的“{chunk_id_2}”不同。 |
| 文件“{filename_1}”中的列数 (count={column_count_1}) 与文件“{filename_2}”不同 (count={column_count_2})。 |
错误 0062
尝试将两个具有不同学习器类型的模型进行比较时,会出现异常。
无法比较两个评分方式不同的数据集的指标时,Azure 机器学习中会产生此错误。 在这种情况下,无法比较用于生成两个评分数据集的模型的有效性。
解决方法: 验证评分结果是否由同一类型的机器学习模型(二元分类、回归、多类分类、建议、聚类分析、异常情况检测等)生成用于比较的所有模型必须具有相同的学习器类型。
| 异常消息 |
|---|
| 所有模型都必须具有相同的学习器类型。 |
| 具有不兼容的学习器类型:“{actual_learner_type}”。 预期的学习器类型为:“{expected_learner_type_list}”。 |
错误 0064
如果指定的 Azure 存储帐户名称或存储密钥不正确,将出现异常。
如果指定的 Azure 存储帐户名称或存储密钥不正确,则 Azure 机器学习中会出现此错误。 如果为存储帐户输入的帐户名称或密码不正确,将收到此错误。 如果手动输入帐户名称或密码,也可能出现此错误。 如果帐户已被删除,也可能出现此错误。
解决方法: 验证是否已输入正确的帐户名称和密码以及容器是否存在。
| 异常消息 |
|---|
| Azure 存储帐户名称或存储密钥不正确。 |
| Azure 存储帐户名称“{account_name}”或该帐户名称的存储密钥不正确。 |
错误 0065
如果指定的 Azure blob 名称不正确,将出现异常。
如果指定的 Azure blob 名称不正确,则 Azure 机器学习中会出现此错误。 如果出现以下情况,你将收到错误:
- 在指定的容器中找不到 blob。
格式为带编码的 Excel 或 CSV 时,导入数据请求中仅将该容器指定为源;不允许使用这些格式串联容器中所有 blob 的内容。
SAS URI 不包含有效的 blob 名称。
解决方法:重新访问引发异常的组件。 验证指定的 blob 是否存在于存储帐户中的容器内,并验证你是否有权查看该 blob。 如果具有带编码格式的 Excel 或 CSV,请验证输入的格式是否为 containername/filename。 验证 SAS URI 是否包含有效的 blob 名称。
| 异常消息 |
|---|
| Azure 存储 blob 名称不正确。 |
| Azure 存储 blob 名称“{blob_name}”不正确。 |
| 不存在带前缀“{blob_name_prefix}”的 Azure 存储 blob 名称。 |
| 无法在容器“{container_name}”下找到任何 Azure 存储 blob。 |
| 无法找到任何通配符路径为“{blob_wildcard_path}”的 Azure 存储 blob。 |
错误 0066
如果无法将资源上传到 Azure Blob,将出现异常。
如果无法将资源上传到 Azure Blob,则 Azure 机器学习中会出现此错误。 两者都保存在与包含输入文件的帐户相同的 Azure 存储帐户中。
解决方法:重新访问组件。 验证 Azure 帐户名称、存储密钥和容器是否正确,以及该帐户是否具有写入该容器的权限。
| 异常消息 |
|---|
| 无法将资源上载到 Azure 存储。 |
| 无法将文件“{source_path}”作为“{dest_path}”上载到 Azure 存储。 |
错误 0067
如果数据集的列数不同于预期列数,将出现异常。
如果数据集的列数不同于预期列数,Azure 机器学习中会出现此错误。 如果数据集的列数与组件在执行期间所需的列数不同,你将收到此错误。
解决方法: 修改输入数据集或参数。
| 异常消息 |
|---|
| 数据表中出现非预期的列数。 |
| 数据集“{dataset_name}”中出现非预期的列数。 |
| 应有“{expected_column_count}”列,但实际找到“{actual_column_count}”列。 |
| 在输入数据集“{dataset_name}”中,应有“{expected_column_count}”列,但实际找到“{actual_column_count}”列。 |
错误 0068
如果指定的 Hive 脚本不正确,将出现异常。
如果 Hive QL 脚本中存在语法错误,或者 Hive 解释器在执行查询或脚本时遇到错误,则 Azure 机器学习中会出现此错误。
解决方法:
系统通常会将来自 Hive 的错误消息报告传回错误日志,以便你可以根据具体错误采取操作。
- 打开组件并检查查询是否有错误。
- 通过登录到 Hadoop 群集的 Hive 控制台并运行查询,验证该查询在 Azure 机器学习之外是否正常运行。
- 尝试将 Hive 脚本中的注释放在单独行中,而不将可执行语句和注释混合到一行。
资源
请参阅以下文章,获取有关针对机器学习的 Hive 查询的帮助:
- 从 Azure Blob 存储创建 Hive 表并加载数据
- 使用 Hive 查询浏览表中的数据
- 使用 Hive 查询创建用于 Hadoop 群集中数据的功能
- 适用于 SQL 的 Hive 用户速查表 (PDF)
| 异常消息 |
|---|
| Hive 脚本不正确。 |
错误 0069
如果指定的 SQL 脚本不正确,将出现异常。
如果指定的 SQL 脚本具有语法问题,或者如果脚本中指定的列或表无效,则 Azure 机器学习中会出现此错误。
如果 SQL 引擎在执行查询或脚本时遇到任何错误,你将收到此错误。 系统通常会将 SQL 错误消息报告传回错误日志,以便你可以根据具体错误采取操作。
解决方法:重新访问该组件并检查 SQL 查询是否有错误。
直接登录到数据库服务器并运行查询,以验证查询在 Azure 机器学习外部能否正常工作。
如果组件异常报告了由 SQL 生成的消息,请根据报告的错误采取操作。 例如,错误消息有时包含关于可能出现的错误的特定指导:
- 没有此列或缺少数据库,表示键入的列名可能有误。 如果你确定列名正确,请尝试使用括号或引号将列标识符括起来。
- <SQL keyword> 附近有 SQL 逻辑错误,表示在指定关键字前面可能有语法错误
| 异常消息 |
|---|
| SQL 脚本不正确。 |
| SQL 查询“{sql_query}”不正确。 |
| SQL 查询“{sql_query}”不正确。 异常消息: {exception}。 |
错误 0070
尝试访问不存在的 Azure 表时将发生异常。
当你尝试访问不存在的 Azure 表时,Azure 机器学习中会出现此错误。 如果指定了 Azure 存储中的表,而它在读取或写入 Azure 表存储时不存在,你将收到此错误。 如果你错误键入了所需表的名称,或目标名称和存储类型不匹配,则可能会出现此错误。 例如,你打算从表中读取,但输入的是 blob 的名称。
解决方法:重新访问该组件,以验证表的名称是否正确。
| 异常消息 |
|---|
| Azure 表不存在。 |
| Azure 表“{table_name}”不存在。 |
错误 0072
如果连接超时,将出现异常。
如果连接超时,Azure 机器学习中会出现此错误。如果数据源或目标当前存在连接问题(如 Internet 连接),或者数据集较大并且/或者要在数据中读取的 SQL 查询会执行复杂处理,那么你将收到此错误。
解决方法: 确定当前是否存在与 Azure 存储或 Internet 连接缓慢的问题。
| 异常消息 |
|---|
| 出现连接超时。 |
错误 0073
如果在将列转换为另一种类型时发生错误,则会出现异常。
无法将列转换为另一种类型时,Azure 机器学习中会出现此错误。 如果组件需要特定类型,而无法将列转换为新类型,那么你将收到此错误。
解决方法: 修改输入数据集,以便可以根据内部异常来转换列。
| 异常消息 |
|---|
| 无法转换列。 |
| 无法将列转换为 {target_type}。 |
错误 0075
如果在量化数据集时使用无效的分箱函数,将出现异常。
当你尝试使用不受支持的方法对数据进行分箱,或参数组合无效时,Azure 机器学习中会出现此错误。
解决方法:
在早期版本的 Azure 机器学习中引入了此事件的错误处理,该版本允许对分箱方法进行更多自定义操作。 当前所有分箱方法都可从下拉列表中进行选择,因此从技术上讲,应该不可能再收到此错误。
| 异常消息 |
|---|
| 使用的分箱函数无效。 |
错误 0077
如果传递了未知的 blob 文件写入模式,则会出现异常。
如果在 blob 文件目标或源的规范下传递了无效参数,则 Azure 机器学习中会出现此错误。
解决方法:在将数据导入或导出 Azure blob 存储的几乎所有组件中,控制写入模式的参数值都是通过使用下拉列表分配的;因此,不可能传递无效值,因而应不会出现此错误。 此错误在后续版本中删除。
| 异常消息 |
|---|
| blob 写入模式不受支持。 |
| blob 写入模式 {blob_write_mode} 不受支持。 |
错误 0078
当导入数据的 HTTP 选项收到指示重定向的 3xx 状态代码时,会出现异常。
当导入数据的 HTTP 选项收到指示重定向的 3xx(301、302、304 等)状态代码时,Azure 机器学习中会出现此错误。 如果尝试连接到将浏览器重定向到其他页面的 HTTP 源,你将收到此错误。 出于安全原因,不允许将重定向网站作为 Azure 机器学习的数据源。
解决方法: 如果网站是受信任的网站,请直接输入重定向 URL。
| 异常消息 |
|---|
| 不允许 HTTP 重定向。 |
错误 0079
如果指定的 Azure 存储容器不正确,将出现异常。
如果指定的 Azure 存储容器名称不正确,则 Azure 机器学习中会出现此错误。 如果在写入 Azure Blob 存储时,尚未使用“以 container 开头的 blob 路径”选项指定容器和 blob(文件)名称,你将收到此错误。
解决方法:重新访问“导出数据”组件,并确保 blob 的指定路径同时包含容器和文件名,格式为 container/filename。
| 异常消息 |
|---|
| Azure 存储容器名称不正确。 |
| Azure 存储容器名称“{container_name}”不正确;应提供 container/blob 格式的容器名称。 |
错误 0080
当组件不允许使用缺失所有值的列时,将出现异常。
如果组件使用的一个或多个列包含所有缺失值,则会在 Azure 机器学习中生成此错误。 例如,如果某个组件正在计算每个列的聚合统计信息,那么它无法对不包含任何数据的列进行运算。 在这种情况下,组件执行会因该异常而停止。
解决方法: 重新访问输入数据集并删除任何包含的值全部缺失的列。
| 异常消息 |
|---|
| 不允许使用包含所有缺失值的列。 |
| 列 {col_index_or_name} 包含所有缺失值。 |
错误 0081
如果要减少的维数等于输入数据集中的特征列数,而且该数据集中至少包含一个稀疏特征列,则会在 PCA 组件中发生异常。
如果满足以下条件,则 Azure 机器学习中会产生此错误:(a) 输入数据集至少有一个稀疏列,(b) 请求的最终维数与输入维数相同。
解决方法: 考虑降低输出的维数,使其小于输入的维数。 这在 PCA 应用程序中很典型。
| 异常消息 |
|---|
| 对于包含稀疏特征列的数据集,降至的维数应小于特征列数。 |
错误 0082
无法成功反序列化模型时,会出现异常。
当较新版本的 Azure 机器学习运行时因重大更改而无法加载已保存的机器学习模型或转换时,Azure 机器学习中会出现此错误。
解决方法: 必须重新运行生成模型或转换的训练管道,并且必须重新保存模型或转换。
| 异常消息 |
|---|
| 无法反序列化模型,因为可能使用的是较旧的序列化格式对其进行序列化。 请重新训练并重新保存该模型。 |
错误 0083
如果用于训练的数据集不能用于具体类型的学习器,则会出现异常。
当数据集与正在接受训练的学习器不兼容时,Azure 机器学习中会产生此错误。 例如,数据集的每一行可能包含至少一个缺少的值,因此在训练期间将跳过整个数据集。 在其他情况下,某些机器学习算法(如异常情况检测)不需要显示标签,并且如果标签显示在数据集中,可能会引发此异常。
解决方法: 请参阅用于检查输入数据集要求的学习器的文档。 检查列以查看是否存在所有必需的列。
| 异常消息 |
|---|
| 用于训练的数据集无效。 |
| {data_name} 包含无法用于训练的数据。 |
| {data_name} 包含无法用于训练的数据。 学习器类型: {learner_type}。 |
| {data_name} 包含无法用于训练的数据。 学习器类型: {learner_type}。 原因: {reason}。 |
| 无法对训练数据 {data_name} 应用“{action_name}”操作。 原因: {reason}。 |
错误 0084
评估从 R 脚本生成的分数时,会出现异常。 目前不支持此操作。
如果尝试使用某个组件来计算具有 R 脚本输出(包含分数)的模型,则会在 Azure 机器学习中出现此错误。
解决方法:
| 异常消息 |
|---|
| 当前不支持评估自定义模型生成的分数。 |
错误 0085
当脚本评估失败并出现错误时,会出现异常。
运行的自定义脚本包含语法错误时,Azure 机器学习中会出现此错误。
解决方法: 在外部编辑器中查看代码,检查是否存在错误。
| 异常消息 |
|---|
| 计算脚本期间出错。 |
| 计算脚本期间发生以下错误,请查看输出日志以了解详细信息: ---------- 来自 {script_language} 解释器的错误消息开头 ---------- {message} ---------- 来自 {script_language} 解释器的错误消息结尾 ---------- |
错误 0090
Hive 表创建失败时,会出现异常。
如果你使用导出数据或其他选项将数据保存到 HDInsight 群集,并且无法创建指定的 Hive 表,则 Azure 机器学习中会出现此错误。
解决方法:检查与群集相关联的 Azure 存储帐户名称,并在组件属性中验证是否使用同一帐户。
| 异常消息 |
|---|
| 无法创建 Hive 表。 对于 HDInsight 群集,请确保与群集关联的 Azure 存储帐户名称与通过组件参数传入的名称相同。 |
| 无法创建 Hive 表“{table_name}”。 对于 HDInsight 群集,请确保与群集关联的 Azure 存储帐户名称与通过组件参数传入的名称相同。 |
| 无法创建 Hive 表“{table_name}”。 对于 HDInsight 群集,请确保与该群集关联的 Azure 存储帐户名称为“{cluster_name}”。 |
错误 0102
无法提取 ZIP 文件时引发此错误。
如果要导入具有 .zip 扩展名的压缩包,但此包不是 zip 文件,或者该文件未使用受支持的 zip 格式,则 Azure 机器学习中会出现此错误。
解决方法: 请确保所选文件是有效的 .zip 文件,并且是使用其中一种受支持的压缩算法压缩的。
如果在以压缩格式导入数据集时遇到此错误,请验证所有包含的文件是否都使用受支持的文件格式之一,并且是否都为 Unicode 格式。
尝试将所需文件读取到新压缩的压缩文件夹中,然后尝试再次添加自定义组件。
| 异常消息 |
|---|
| 给定的 ZIP 文件的格式不正确。 |
错误 0105
组件定义文件包含不受支持的参数类型时,会显示此错误。
当你创建自定义组件 xml 定义,并且定义中的形参或实参的类型与受支持的类型不匹配时,Azure 机器学习中会产生此错误。
解决方法:确保自定义组件 xml 定义文件中任何 Arg 元素的 type 属性都是受支持的类型。
| 异常消息 |
|---|
| 参数类型不受支持。 |
| 指定了不支持的参数类型“{0}”。 |
错误 0107
当组件定义文件定义了不支持的输出类型时引发。
当自定义组件 xml 定义中输出端口的类型与支持的类型不匹配时,将在 Azure 机器学习中生成此错误。
解决方法: 确保自定义组件 xml 定义文件中 Output 元素的 type 属性是受支持的类型。
| 异常消息 |
|---|
| 输出类型不受支持。 |
| 指定了不支持的输出类型“{output_type}”。 |
错误 0125
多个数据集的架构不匹配时会引发此错误。
解决方法:
| 异常消息 |
|---|
| 数据集架构不匹配。 |
错误 0127
图像像素大小超出了允许的限制。
如果要从图像数据集读取图像以进行分类,但图像大于模型可以处理的大小,则会出现此错误。
| 异常消息 |
|---|
| 图像像素大小超出了允许的限制。 |
| 文件“{file_path}”中的图像像素大小超出了允许的限制:“{size_limit}”。 |
错误 0128
分类列的条件概率数超出了限制。
解决方法:
| 异常消息 |
|---|
| 分类列的条件概率数超出了限制。 |
| 分类列的条件概率数超出了限制。 “{column_name_or_index_1}”和“{column_name_or_index_2}”列是有问题的配对。 |
错误 0129
数据集中的列数超出了允许的限制。
解决方法:
| 异常消息 |
|---|
| 数据集中的列数超出了允许的限制。 |
| “{dataset_name}”中数据集的列数超出允许的限制。 |
| “{dataset_name}”中数据集的列数超出“{component_name}”允许的限制。 |
| “{dataset_name}”中数据集的列数超出“{component_name}”允许的限制“{limit_columns_count}”。 |
错误 0134
缺少标签列或标签列中带标签的行数不足时,会出现异常。
当组件需要标签列,但列选择中没有标签列,或者标签列缺失过多的值时,会出现此错误。
如果之前的操作更改了数据集,从而没有足够的行可供下游操作使用,也会出现此错误。 例如,假设使用“分区和采样”组件中的表达式按值划分数据集。 如果没有找到表达式的匹配项,则由该分区生成的其中一个数据集将为空。
解决方法:
如果在列选择中包含标签列,但无法识别该列,请使用编辑元数据组件将其标记为标签列。
然后,可以使用清理缺失数据组件来删除标签列中包含缺失值的行。
检查输入数据集以确保它们包含有效数据和足够的行来满足操作要求。 如果算法具有最少数据行数要求,但数据只包含几行或一个标头,很多算法会生成错误消息。
| 异常消息 |
|---|
| 缺少标签列或标签列中带标签的行数不足时,会出现异常。 |
| 缺少标签列或标签列所具有的带标签的行数小于 {required_rows_count} 时,会出现异常。 |
| 数据集 {dataset_name} 缺少标签列,或标签列所具有的带标签的行数小于 {required_rows_count} 时,会出现异常。 |
错误 0138
内存已耗尽,无法完成组件运行。 缩小数据集可能有助于解决问题。
当正在运行的组件所需的内存超过 Azure 容器中的可用内存时,会发生此错误。 如果使用的是大型数据集,而内存无法容纳当前操作,则可能会出现此错误。
解决方法:如果尝试读取大型数据集,并且无法完成操作,那么缩小数据集可能有所帮助。
| 异常消息 |
|---|
| 内存已耗尽,无法完成组件运行。 |
| 内存已耗尽,无法完成组件运行。 详细信息:{details} |
错误 0141
如果分类列和字符串列中选定的数值列数和唯一值数量过少,会出现异常。
当所选列中的唯一值不足而无法执行操作时,Azure 机器学习中会出现此错误。
解决方法:某些操作对特征列和分类列执行统计运算,如果没有足够的值,操作可能失败或返回无效结果。 检查数据集以查看特征列和标签列中有多少个值,并确定尝试执行的操作在统计意义上是否有效。
如果源数据集有效,还可以检查是否有上游数据操作或元数据操作更改了数据并删除了某些值。
如果上游操作包括拆分、采样或重新采样,请验证输出是否包含预期的行数和值数量。
| 异常消息 |
|---|
| 所选数值列的数量以及分类列和字符串列中唯一值的数量太少。 |
| 所选数值列以及分类列和字符串列中唯一值的总数(当前为 {actual_num} 个)应至少为 {lower_boundary}。 |
错误 0154
当用户尝试联接具有不兼容的列类型的键列上的数据时,会出现异常。
| 异常消息 |
|---|
| 键列元素类型不兼容。 |
| 键列元素类型不兼容。(左:{keys_left};右:{keys_right}) |
错误 0155
当数据集的列名不是字符串时,会出现异常。
| 异常消息 |
|---|
| 数据帧列名称必须是字符串类型。 列名称不是字符串。 |
| 数据帧列名称必须是字符串类型。 列名称 {column_names} 不是字符串。 |
错误 0156
从 Azure SQL 数据库读取数据失败时,会出现异常。
| 异常消息 |
|---|
| 未能从 Azure SQL 数据库读取数据。 |
| 未能从 Azure SQL 数据库读取数据:{detailed_message} DB: {database_server_name}:{database_name} Query: {sql_statement} |
错误 0157
未找到数据存储。
| 异常消息 |
|---|
| 数据存储信息无效。 |
| 数据存储信息无效。 未能获取工作区“{workspace_name}”中的 Azure 机器学习数据存储“{datastore_name}”。 |
错误 0158
转换目录无效时引发。
| 异常消息 |
|---|
| 给定的 TransformationDirectory 无效。 |
| TransformationDirectory“{arg_name}”无效。 原因: {reason}。 请重新运行训练实验,以生成转换文件。 如果训练实验被删除,请重新创建并保存转换文件。 |
| TransformationDirectory“{arg_name}”无效。 原因: {reason}。 {troubleshoot_hint} |
错误 0159
如果组件模型目录无效,则会发生异常。
| 异常消息 |
|---|
| 给定的 ModelDirectory 无效。 |
| ModelDirectory“{arg_name}”无效。 |
| ModelDirectory“{arg_name}”无效。 原因: {reason}。 |
| ModelDirectory“{arg_name}”无效。 原因: {reason}。 {troubleshoot_hint} |
错误 1000
内部库异常。
提供此错误是为了捕获未通过其他方式处理的内部引擎错误。 因此,导致此错误的原因可能会因生成此错误的组件而异。
若要获得更多帮助,建议将错误附带的详细消息发布到 Azure 机器学习论坛,同时提供情况说明(包括用作输入的数据)。 此反馈将帮助我们确定错误的优先级,并确定接下来要处理的最重要的问题。
| 异常消息 |
|---|
| 库异常。 |
| 库异常: {exception}。 |
| 未知库异常: {exception}。 {customer_support_guidance}。 |
故障排除指南
执行 Python 脚本组件错误
在“执行 Python 脚本”组件的 70_driver_logs 中搜索“in azureml_main”,便可以找到发生错误的行。 例如,“File "/tmp/tmp01_ID/user_script.py", line 17, in azureml_main”表示错误发生在 Python 脚本的第 17 行。
分布式训练
当前设计器支持对训练 PyTorch 模型组件进行分布式训练。
如果启用分布式训练的组件发生故障,但未生成任何 70_driver 日志,则可查看 70_mpi_log 以了解错误详情。
以下示例显示运行设置的节点计数大于计算群集的可用节点计数。

下方示例显示每个节点的进程计数大于计算的处理单位。

否则,可以检查每个进程的 70_driver_log。 70_driver_log_0 适用于主进程。

未能在管道中装载示例数据

如果遇到以上错误,请遵循以下步骤来解决此问题:
双击数据节点,转到数据存储的详细信息页。
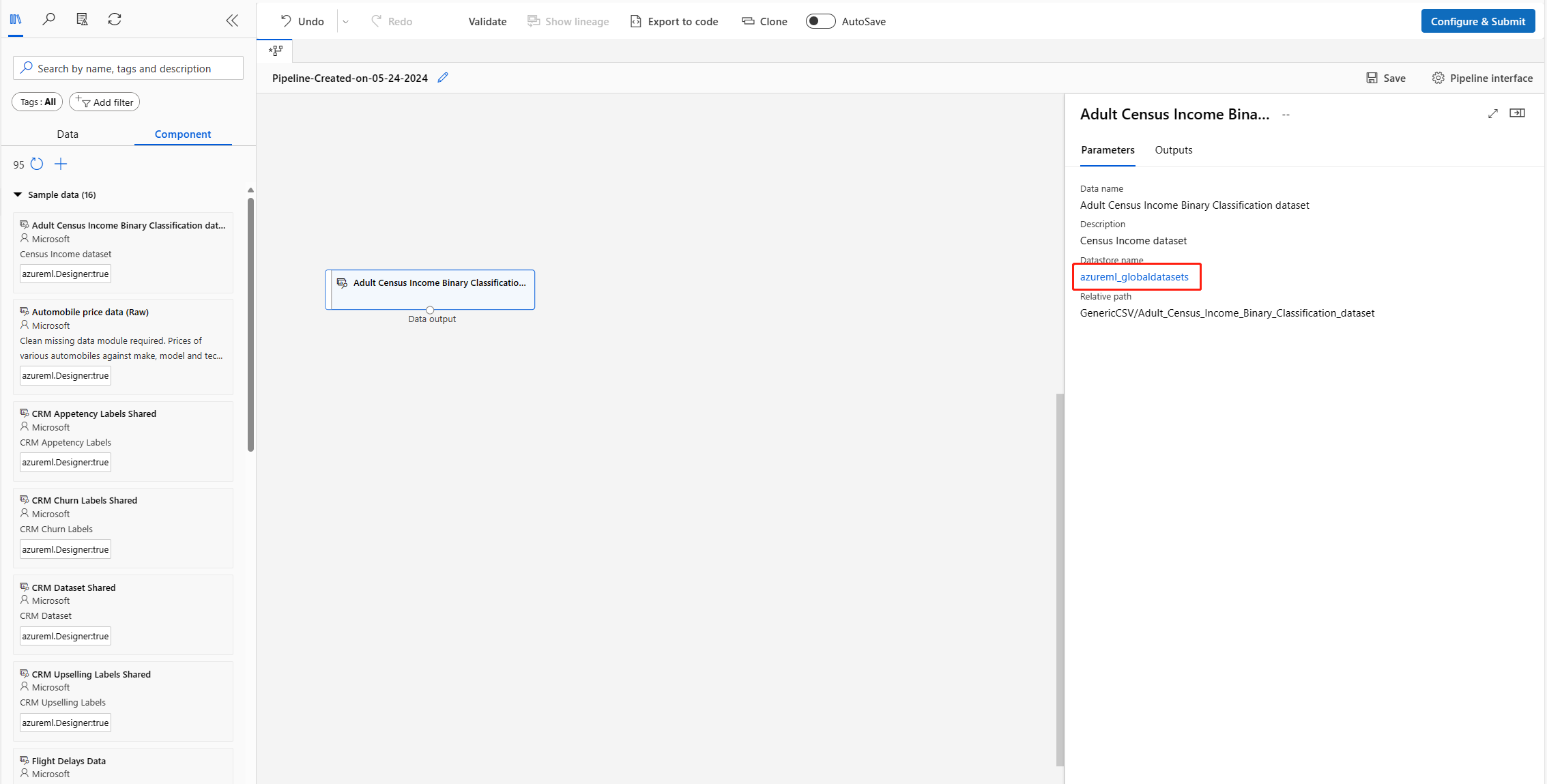
Unregister此azureml_globaldatasets数据存储。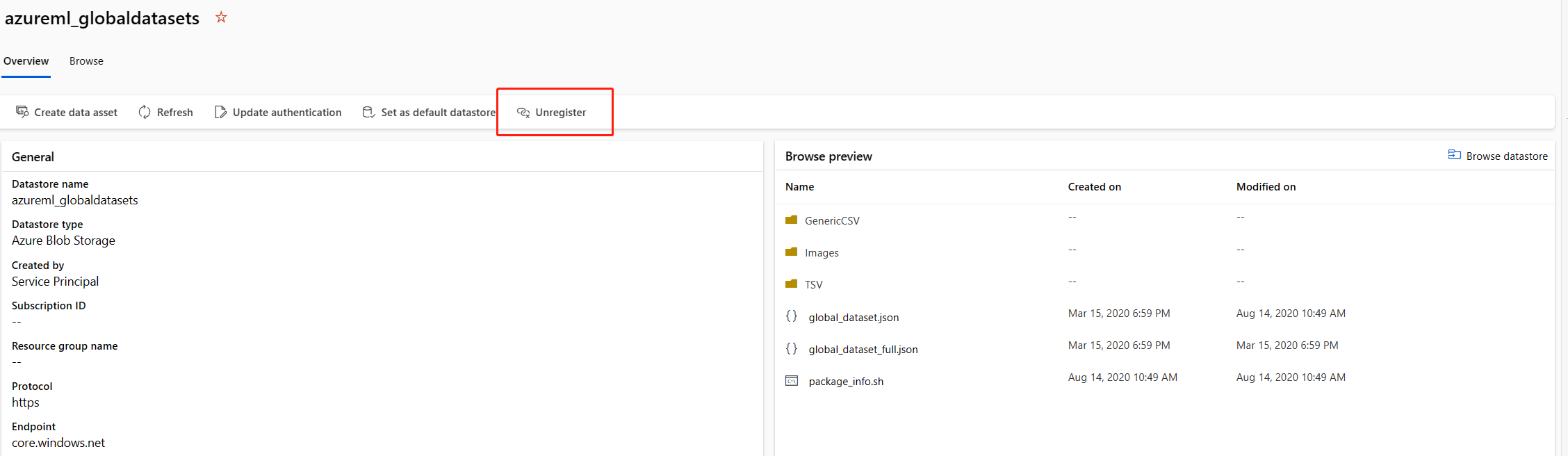
将新的
Sample Data节点拖放到管道,以便再试一次。

