重要
本文提供有关使用 Azure 机器学习 SDK v1 的信息。 SDK v1 自 2025 年 3 月 31 日起弃用。 对它的支持将于 2026 年 6 月 30 日结束。 可以在该日期之前安装和使用 SDK v1。 使用 SDK v1 的现有工作流将在支持结束日期后继续运行。 但是,在产品发生体系结构更改时,可能会面临安全风险或中断性变更。
建议在 2026 年 6 月 30 日之前过渡到 SDK v2。 有关 SDK v2 的详细信息,请参阅 什么是 Azure 机器学习 CLI 和 Python SDK v2? 以及 SDK v2 参考。
在本文中,你将了解使用 Azure 数据工厂生成数据引入管道时的可用选项。 此 Azure 数据工厂管道用于引入要在 Azure 机器学习中使用的数据。 使用数据工厂可以轻松提取、转换和加载 (ETL) 数据。 转换数据并将其载入存储后,可以使用这些数据在 Azure 机器学习中训练机器学习模型。
可以使用原生数据工厂活动和数据流等检测工具来处理简单的数据转换。 涉及到较复杂的方案时,可以使用一些自定义代码来处理数据。 例如 Python 或 R 代码。
比较 Azure 数据工厂数据引入管道
在引入期间,可以通过多种常用方法使用数据工厂来转换数据。 每种方法各有优缺点,这也决定了它是否适合特定的用例:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 数据工厂 + Azure Functions | 仅适用于短时间运行的处理 | |
| 数据工厂 + 自定义组件 | ||
| 数据工厂 + Azure Databricks 笔记本 |
包含 Azure 函数的 Azure 数据工厂
Azure Functions 允许运行小段代码(函数),且不需要担心应用程序基础结构。 使用此选项时,数据将通过包装在 Azure 函数中的自定义 Python 代码进行处理。
该函数是使用 Azure 数据工厂 Azure 函数活动调用的。 此方法非常适合轻型数据转换。
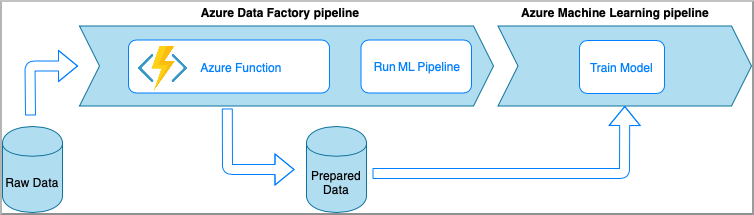
- 优点:
- 以相对较低的延迟在无服务器计算资源中处理数据
- 数据工厂管道可以调用一个持久性 Azure 函数,该函数可实现复杂的数据转换流
- 可重复使用且可从其他位置调用的 Azure 函数会抽象掉数据转换的详细信息
- 缺点:
- 在与 ADF 结合使用之前,必须先创建 Azure Functions
- Azure Functions 仅适用于短时间运行的数据处理
包含自定义组件活动的 Azure 数据工厂
使用此选项时,数据将通过包装在可执行文件中的自定义 Python 代码进行处理。 该可执行文件是使用 Azure 数据工厂自定义组件活动调用的。 与前面的方法相比,此方法更适合较大的数据。
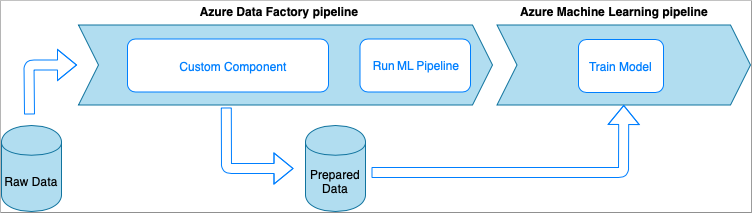
- 优点:
- 数据将在 Azure Batch 池中进行处理,该池提供大规模并行和高性能计算
- 可用于运行繁重的算法并处理大量数据
- 缺点:
- 在与数据工厂结合使用之前,必须先创建 Azure Batch 池
- 将 Python 代码包装到可执行文件会产生过多的工程工作量。 处理依赖项和输入/输出参数时存在的复杂性
包含 Azure Databricks Python 笔记本的 Azure 数据工厂
Azure Databricks 是 Azure 云中基于 Apache Spark 的分析平台。
使用此方法时,数据转换将由 Azure Databricks 群集上运行的某个 Python 笔记本执行。 这也许是全面使用 Azure Databricks 服务的强大之处的最常见方法。 它旨在用于大规模的分布式数据处理。
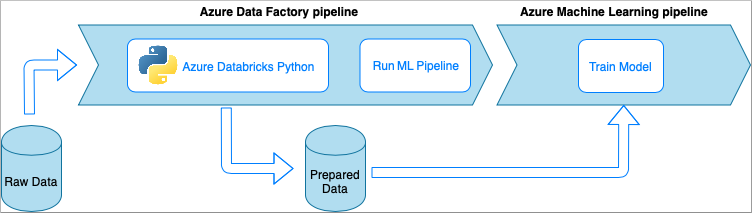
- 优点:
- 在以 Apache Spark 环境为后盾的最强大数据处理 Azure 服务中转换数据
- 原生支持 Python 以及数据科学框架和库(包括 TensorFlow、PyTorch 和 scikit-learn)
- 无需将 Python 代码包装到函数或可执行模块中。 代码按原样运行。
- 缺点:
- 在与数据工厂结合使用之前,必须先创建 Azure Databricks 基础结构
- 开销可能很高,具体取决于 Azure Databricks 配置
- 从“冷”模式运转计算群集需要一段时间,使解决方案遇到较高的延迟
使用 Azure 机器学习中的数据
数据工厂管道会将准备好的数据保存到你的云存储(例如 Azure Blob 或 Azure Data Lake)。
可以通过以下方式使用 Azure 机器学习中已准备好的数据:
- 从数据工厂管道调用 Azure 机器学习管道。
或 - 创建 Azure 机器学习数据存储。
从数据工厂调用 Azure 机器学习管道
对于机器学习操作 (MLOps) 工作流,建议使用此方法。 如果不想设置 Azure 机器学习管道,请参阅直接从存储读取数据。
数据工厂管道每次运行时:
- 数据将保存到存储中的不同位置。
- 若要将位置传递给 Azure 机器学习,数据工厂管道需要调用 Azure 机器学习管道。 当数据工厂管道调用 Azure 机器学习管道时,数据位置和作业 ID 将作为参数发送。
- 然后,ML 管道可以使用数据位置创建 Azure 机器学习数据存储和数据集。 可以从在数据工厂中执行 Azure 机器学习管道中了解详细信息。
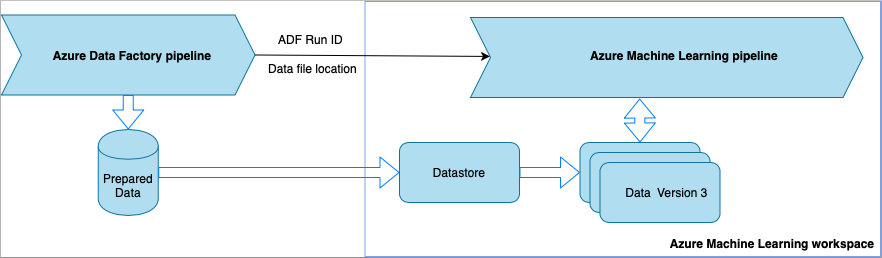
提示
数据集支持版本控制,因此 ML 管道可以注册指向 ADF 管道中最新数据的新数据集版本。
可通过数据存储或数据集访问数据后,可以使用这些数据来训练 ML 模型。 训练过程可能是从 ADF 中调用的同一 ML 管道的一部分。 或者,它可能是一个单独的过程,例如 Jupyter 笔记本中的试验。
由于数据集支持版本控制,并且每个管道中的作业都会创建一个新版本,因此,很容易就知道使用了哪个数据版本来训练模型。
直接从存储读取数据
如果不想创建 ML 管道,则可以直接从存储帐户访问数据,该存储帐户使用 Azure 机器学习数据存储和数据集保存准备好的数据。
以下 Python 代码演示了如何创建连接到 Azure DataLake Generation 2 存储的数据存储。 详细了解数据存储以及在何处查找服务主体权限。
适用于: 适用于 Python 的 Azure 机器学习 SDK v1
适用于 Python 的 Azure 机器学习 SDK v1
ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
接下来,创建一个数据集,以引用要在机器学习任务中使用的文件。
下面的代码基于 csv 文件 prepared-data.csv 创建一个 TabularDataset。 详细了解数据集类型和接受的文件格式。
适用于:适用于 Python 的 Azure 机器学习 SDK v1
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
在这里,请使用 prepared_dataset 来引用已准备好的数据,就像在训练脚本中一样。 了解如何在 Azure 机器学习中使用数据集训练模型。