
警告
在 2022 年 6 月之后,将不再支持通过 azureml.contrib.train.rl 包进行 Azure 机器学习强化学习。 我们建议客户使用 Azure 机器学习库上的 Ray 来进行 Azure 机器学习的强化学习实验。 有关示例,请参阅 Azure 机器学习中的强化学习 - Pong 问题笔记本。
本文介绍如何训练一个强化学习 (RL) 代理,以便能够畅玩视频游戏 Pong。 将开放源代码 Python 库 Ray RLlib 与 Azure 机器学习配合使用来管理分布式 RL 的复杂性。
本文介绍如何执行以下操作:
- 设置试验
- 定义头节点和工作器节点
- 创建 RL 估算器
- 提交试验以开始作业
- 查看结果
本文基于可在 Azure 机器学习笔记本 GitHub 存储库中找到的 RLlib Pong 示例。
在以下任一环境中运行此代码。 建议尝试使用 Azure 机器学习计算实例,以获得最快的启动体验。 可以在 Azure 机器学习计算实例上快速克隆和运行强化示例笔记本。
Azure 机器学习计算实例
- 在教程:训练和部署模型中了解如何克隆示例笔记本。
- 请克隆 how-to-use-azureml 文件夹而不是 tutorials
- 运行
/how-to-use-azureml/reinforcement-learning/setup/devenv_setup.ipynb中的虚拟网络设置笔记本,打开用于分布式强化学习的网络端口。 - 运行示例笔记本
/how-to-use-azureml/reinforcement-learning/atari-on-distributed-compute/pong_rllib.ipynb
- 在教程:训练和部署模型中了解如何克隆示例笔记本。
你自己的 Jupyter 笔记本服务器
- 安装 Azure 机器学习 SDK。
- 安装 Azure 机器学习 RL SDK:
pip install --upgrade azureml-contrib-reinforcementlearning - 创建工作区配置文件。
- 运行虚拟网络,打开用于分布式强化学习的网络端口。
强化学习 (RL) 是通过工作来学习知识的一种机器学习方法。 其他机器学习技术是通过被动地接收输入数据并在其中查找模式来学习知识,而 RL 则是使用训练代理主动做出决策,并从结果中学习知识。
你的训练代理将会学习如何在模拟环境中玩 Pong 游戏。 训练代理会在每个游戏帧处,决定是要将球拍上移、下移还是保留原位。 它会查看游戏状态(屏幕的 RGB 图像)来做出决策。
RL 使用奖励来告知代理其决策是否成功。 在此示例中,代理获得一分时则获得正奖励,代理被扣掉一分时则获得负奖励。 经过多次迭代后,训练代理会根据其当前状态学习选择动作,并进行优化以提高将来的预期总奖励。 在 RL 中,通常使用深度神经网络 (DNN) 执行这种优化。
当代理在一个训练时期达到平均奖励评分 18 时,训练即告结束。 这意味着,代理在比赛中,凭借最低 18 分的平均比分(总分 21 分)击败了其对手。
这种迭代模拟和重新训练 DNN 的过程会消耗大量计算资源,且需要大量数据。 提高 RL 作业性能的一种方法是将工作并行化,使多个训练代理能够同时做出动作并学习知识。 但是,管理分布式 RL 环境可能是一项复杂的任务。
Azure 机器学习提供了一个框架,用于处理这种复杂性,以便能够横向扩展 RL 工作负荷。
通过以下方式设置本地 RL 环境:
- 加载所需的 Python 包
- 初始化工作区
- 创建试验
- 指定配置的虚拟网络。
导入所需的 Python 包以运行本示例的其余部分。
# Azure ML Core imports
import azureml.core
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core.compute import AmlCompute
from azureml.core.compute import ComputeTarget
from azureml.core.runconfig import EnvironmentDefinition
from azureml.widgets import RunDetails
from azureml.tensorboard import Tensorboard
# Azure ML Reinforcement Learning imports
from azureml.contrib.train.rl import ReinforcementLearningEstimator, Ray
from azureml.contrib.train.rl import WorkerConfiguration
根据在先决条件部分中创建的 config.json 文件初始化工作区对象。 如果在 Azure 机器学习计算实例中执行此代码,则系统已经为你创建了配置文件。
ws = Workspace.from_config()
创建一个试验,用于跟踪强化学习作业。 在 Azure 机器学习中,试验是相关试运行的逻辑集合,用于组织作业日志、历史记录、输出等信息。
experiment_name='rllib-pong-multi-node'
exp = Experiment(workspace=ws, name=experiment_name)
对于使用多个计算目标的 RL 作业,必须指定一个虚拟网络,其中带有开放端口,这些端口使工作器节点和头节点可以相互通信。
虚拟网络可以位于任意资源组中,但应该与工作区位于同一区域。 有关设置虚拟网络的详细信息,请参阅“先决条件”部分中的工作区设置笔记本。 在这里,请指定资源组中的虚拟网络的名称。
vnet = 'your_vnet'
此示例对 Ray 头节点和工作器节点使用不同的计算目标。 使用这些设置,可以根据工作负载纵向扩展和缩减计算资源。 根据需要设置节点数目和每个节点的大小。
可以使用配备了 GPU 的头节点群集来提高深度学习性能。 头节点将训练供代理用来做出决策的神经网络。 头节点还从工作器节点收集数据点,以训练神经网络。
头节点计算使用单个 STANDARD_NC6s_v3 虚拟机 (VM)。 它有 6 个可以分配工作的虚拟 CPU。
from azureml.core.compute import AmlCompute, ComputeTarget
# choose a name for the Ray head cluster
head_compute_name = 'head-gpu'
head_compute_min_nodes = 0
head_compute_max_nodes = 2
# This example uses GPU VM. For using CPU VM, set SKU to STANDARD_D2_V2
head_vm_size = 'STANDARD_NC6s_v3'
if head_compute_name in ws.compute_targets:
head_compute_target = ws.compute_targets[head_compute_name]
if head_compute_target and type(head_compute_target) is AmlCompute:
print(f'found head compute target. just use it {head_compute_name}')
else:
print('creating a new head compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size = head_vm_size,
min_nodes = head_compute_min_nodes,
max_nodes = head_compute_max_nodes,
vnet_resourcegroup_name = ws.resource_group,
vnet_name = vnet_name,
subnet_name = 'default')
# create the cluster
head_compute_target = ComputeTarget.create(ws, head_compute_name, provisioning_config)
# can poll for a minimum number of nodes and for a specific timeout.
# if no min node count is provided it will use the scale settings for the cluster
head_compute_target.wait_for_completion(show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current AmlCompute status, use get_status()
print(head_compute_target.get_status().serialize())
此示例对工作器节点计算目标使用 4 个 STANDARD_D2_V2 VM。 每个工作器节点有 2 个可用 CPU,因此总共有 8 个可用 CPU。
没有必要在工作器节点上配备 GPU,因为 GPU 不执行深度学习。 工作器运行游戏模拟并收集数据。
# choose a name for your Ray worker cluster
worker_compute_name = 'worker-cpu'
worker_compute_min_nodes = 0
worker_compute_max_nodes = 4
# This example uses CPU VM. For using GPU VM, set SKU to STANDARD_NC6
worker_vm_size = 'STANDARD_D2_V2'
# Create the compute target if it hasn't been created already
if worker_compute_name in ws.compute_targets:
worker_compute_target = ws.compute_targets[worker_compute_name]
if worker_compute_target and type(worker_compute_target) is AmlCompute:
print(f'found worker compute target. just use it {worker_compute_name}')
else:
print('creating a new worker compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size = worker_vm_size,
min_nodes = worker_compute_min_nodes,
max_nodes = worker_compute_max_nodes,
vnet_resourcegroup_name = ws.resource_group,
vnet_name = vnet_name,
subnet_name = 'default')
# create the cluster
worker_compute_target = ComputeTarget.create(ws, worker_compute_name, provisioning_config)
# can poll for a minimum number of nodes and for a specific timeout.
# if no min node count is provided it will use the scale settings for the cluster
worker_compute_target.wait_for_completion(show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current AmlCompute status, use get_status()
print(worker_compute_target.get_status().serialize())
使用 ReinforcementLearningEstimator 将训练的作业提交到 Azure 机器学习。
Azure 机器学习使用估算器类来封装作业配置信息。 这样,你便可以指定脚本执行的配置方式。
WorkerConfiguration 对象告知 Azure 机器学习如何初始化运行入口脚本的工作器节点群集。
# Pip packages we will use for both head and worker
pip_packages=["ray[rllib]==0.8.3"] # Latest version of Ray has fixes for isses related to object transfers
# Specify the Ray worker configuration
worker_conf = WorkerConfiguration(
# Azure ML compute cluster to run Ray workers
compute_target=worker_compute_target,
# Number of worker nodes
node_count=4,
# GPU
use_gpu=False,
# PIP packages to use
pip_packages=pip_packages
)
入口脚本 pong_rllib.py 接受一个参数列表,这些参数定义如何执行训练作业。 通过用作封装层的估算器传递这些参数可以轻松更改脚本参数以及独立运行每项配置。
指定正确的 num_workers 可以最大程度地发挥并行化的作用。 将工作器数量设置为与可用 CPU 数量相同。 在此示例中,可以使用以下计算:
头节点是有 6 个 vCPU 的 Standard_NC6s_v3。 工作器节点群集是 4 个 Standard_D2_V2 VM,每个 VM 有 2 个 CPU,因此总共有 8 个 CPU。 但是,必须从工作器计数中减去 1 个 CPU,因为必须有 1 个 CPU 专用于头节点角色。
6个 CPU + 8 个 CPU - 1 个头节点 CPU = 13 个同步工作器。 Azure 机器学习使用头节点和工作器节点群集来区分计算资源。 但是,Ray 并不区分头节点和工作器节点,所有 CPU 都可用作工作线程。
training_algorithm = "IMPALA"
rl_environment = "PongNoFrameskip-v4"
# Training script parameters
script_params = {
# Training algorithm, IMPALA in this case
"--run": training_algorithm,
# Environment, Pong in this case
"--env": rl_environment,
# Add additional single quotes at the both ends of string values as we have spaces in the
# string parameters, outermost quotes are not passed to scripts as they are not actually part of string
# Number of GPUs
# Number of ray workers
"--config": '\'{"num_gpus": 1, "num_workers": 13}\'',
# Target episode reward mean to stop the training
# Total training time in seconds
"--stop": '\'{"episode_reward_mean": 18, "time_total_s": 3600}\'',
}
使用参数列表和工作器节点配置对象来构造估算器。
# RL estimator
rl_estimator = ReinforcementLearningEstimator(
# Location of source files
source_directory='files',
# Python script file
entry_script="pong_rllib.py",
# Parameters to pass to the script file
# Defined above.
script_params=script_params,
# The Azure ML compute target set up for Ray head nodes
compute_target=head_compute_target,
# Pip packages
pip_packages=pip_packages,
# GPU usage
use_gpu=True,
# RL framework. Currently must be Ray.
rl_framework=Ray(),
# Ray worker configuration defined above.
worker_configuration=worker_conf,
# How long to wait for whole cluster to start
cluster_coordination_timeout_seconds=3600,
# Maximum time for the whole Ray job to run
# This will cut off the job after an hour
max_run_duration_seconds=3600,
# Allow the docker container Ray runs in to make full use
# of the shared memory available from the host OS.
shm_size=24*1024*1024*1024
)
入口脚本 pong_rllib.py 使用 OpenAI Gym 环境 PongNoFrameSkip-v4 来训练神经网络。 OpenAI Gym 是用于在经典 Atari 游戏中测试强化学习算法的标准化接口。
此示例使用名为 IMPALA(重要性加权操作器-学习器体系结构)的训练算法。 IMPALA 并行化每个学习操作器,以跨多个计算节点进行缩放,且不降低速度或稳定性。
Ray 优化协调 IMPALA 工作器任务。
import ray
import ray.tune as tune
from ray.rllib import train
import os
import sys
from azureml.core import Run
from utils import callbacks
DEFAULT_RAY_ADDRESS = 'localhost:6379'
if __name__ == "__main__":
# Parse arguments
train_parser = train.create_parser()
args = train_parser.parse_args()
print("Algorithm config:", args.config)
if args.ray_address is None:
args.ray_address = DEFAULT_RAY_ADDRESS
ray.init(address=args.ray_address)
tune.run(run_or_experiment=args.run,
config={
"env": args.env,
"num_gpus": args.config["num_gpus"],
"num_workers": args.config["num_workers"],
"callbacks": {"on_train_result": callbacks.on_train_result},
"sample_batch_size": 50,
"train_batch_size": 1000,
"num_sgd_iter": 2,
"num_data_loader_buffers": 2,
"model": {
"dim": 42
},
},
stop=args.stop,
local_dir='./logs')
入口脚本使用某个实用工具函数定义一个自定义 RLlib 回调函数,以将指标记录到 Azure 机器学习工作区。 请在监视和查看结果部分了解如何查看这些指标。
'''RLlib callbacks module:
Common callback methods to be passed to RLlib trainer.
'''
from azureml.core import Run
def on_train_result(info):
'''Callback on train result to record metrics returned by trainer.
'''
run = Run.get_context()
run.log(
name='episode_reward_mean',
value=info["result"]["episode_reward_mean"])
run.log(
name='episodes_total',
value=info["result"]["episodes_total"])
运行处理正在进行的或已完成的作业的运行历史记录。
run = exp.submit(config=rl_estimator)
备注
完成运行最多可能需要 30 到 45 分钟。
使用 Azure 机器学习 Jupyter 小组件可实时查看作业状态。 该小组件显示两个子作业:一个是头节点的作业,另一个是工作器节点的作业。
from azureml.widgets import RunDetails
RunDetails(run).show()
run.wait_for_completion()
- 等待加载小组件。
- 在作业列表中选择头节点作业。
选择“单击此处在 Azure 机器学习工作室中查看作业”可在工作室中查看更多作业信息。 可以在作业正在进行时访问此信息,也可以在完成运行后访问。
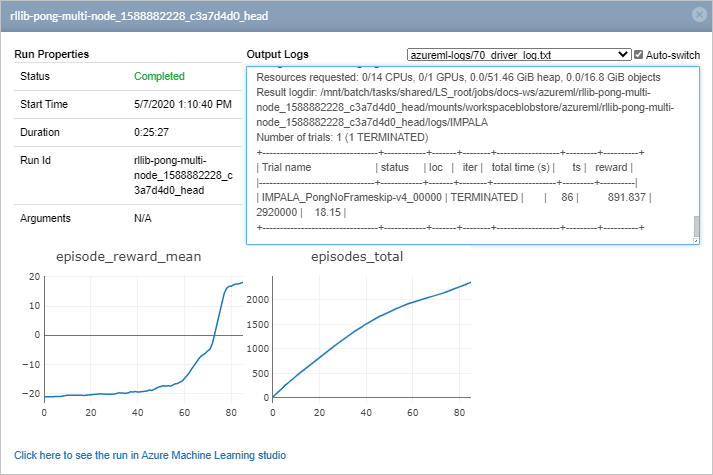
episode_reward_mean 绘图显示每个训练时期的平均评分。 可以看到,训练代理最初的表现很差,输掉了比赛且一分未得(reward_mean 为 -21)。 在 100 次迭代内,训练代理已学会了如何击败计算机对手,平均分数为 18 分。
如果浏览子作业的日志,可以看到 driver_log.txt 文件中记录的评估结果。 可能需要等待几分钟,这些指标才会出现在“作业”页上。
简而言之,你已了解如何配置多个计算资源来训练强化学习代理,使其能够很好地与计算机对手玩“乓”游戏。
在本文中,你已了解如何使用 IMPALA 学习代理来训练强化学习代理。 若要查看更多示例,请转到 Azure 机器学习强化学习 GitHub 存储库。