本文介绍用于计算全文搜索的搜索分数的 BM25 相关性评分算法。 BM25 相关性仅适用于全文搜索。 不会对筛选查询、自动完成和建议查询、通配符搜索和模糊搜索查询的相关性进行评分或排名。
全文搜索中使用的评分算法
Azure AI 搜索为全文搜索提供了以下评分算法:
| 算法 | 使用情况 | 范围 |
|---|---|---|
BM25Similarity |
修正了 2020 年 7 月之后创建的所有搜索服务中的算法。 可以配置此算法,但不能切换到较旧的算法(经典)。 | 无限制。 |
ClassicSimilarity |
以 2020 年 7 月之前的旧搜索服务作为默认设置。 在旧服务上,你可以选择启用 BM25,并基于每个索引来选择 BM25 算法。 | 0 < 1.00 |
BM25 和 Classic 都是类似于 TF-IDF 的检索函数,它们使用字词频率 (TF) 和逆向文档频率 (IDF) 作为变量来计算每个文档-查询对的相关性评分,然后使用这些评分来获得排名结果。 虽然在概念上与 Classic 类似,但 BM25 立足于概率信息检索来生成更直观的匹配项(通过用户研究进行度量)。
BM25 提供高级自定义选项,例如,允许用户确定如何根据匹配字词的字词频率调整相关性评分。
BM25 排名的工作原理
相关性评分是指搜索分数 (@search.score) 的计算,它作为一个项在当前查询上下文中的相关性的指示器。 范围是无界的。 不过,分数越高,项目就越相关。
根据字符串输入和查询本身的统计属性计算搜索分数。 Azure AI 搜索会查找与搜索词匹配的文档(与部分搜索词或全部搜索词匹配,具体取决于 searchMode),并优先列出包含该搜索词多个实例的文档。 如果搜索词在数据索引中很少见,但在文档中很常见,搜索分数仍升至更高。 这种计算相关性的方法的基本原理称为 TF-IDF(字词频率-逆向文档频率)。
搜索分数可以在整个结果集中重复。 当多个命中具有相同的搜索评分时,这些相同评分项的排序是不确定且不稳定的。 再次运行查询,你可能会看到项偏移位置,尤其是使用免费服务或包含多个副本的可计费服务时。 对于具有相同分数的两个项,无法保证先显示哪一个。
若要打破重复分数之间的平局,可添加一个 $orderby 子句,以便先按分数进行排序,然后按另一个可排序字段(例如 $orderby=search.score() desc,Rating desc)进行排序。
只有索引中标记为 searchable 或查询中标记为 searchFields 的字段才用于评分。 搜索结果中仅返回标记为 retrievable 的字段或在查询中的 select 中指定的字段,还会返回它们的搜索分数。
注意
@search.score = 1 指示未评分或未排名的结果集。 评分在所有结果中是统一的。 如果查询形式是模糊搜索、通配符或正则表达式查询,或者是空搜索(search=*,有时与筛选器配对,其中的筛选器是返回匹配项的主要方式),则会出现未评分的结果。
文本结果中的分数
每次对结果排名时,@search.score 属性都包含用于对结果进行排序的值。
下表列出了评分属性、算法以及范围。
| 搜索方法 | 参数 | 评分算法 | 范围 |
|---|---|---|---|
| 全文搜索 | @search.score |
BM25 算法,使用索引中指定的参数。 | 无限制。 |
分数变化
搜索评分表达了对相关性的总体认知,反映了相对于同一结果集中的其他文档的匹配强度。 但是,评分在不同的查询之间并非始终一致,因此,在处理查询时,你可能会注意到搜索文档的排序方式存在细微差别。 下面对发生这种情况的可能原因给出了几条解释。
| 原因 | 说明 |
|---|---|
| 相同的评分 | 如果多个文档具有相同的评分,其中的任何一个文档都可能会首先出现。 |
| 数据易变性 | 添加、修改或删除文档时,索引内容会发生变化。 在处理索引更新的过程中,字词频率会发生变化,从而影响了匹配文档的搜索评分。 |
| 多个副本 | 对于使用多个副本的服务,将并行针对每个副本发出查询。 用于计算搜索评分的索引统计信息是根据每个副本计算的,结果将在查询响应中合并和排序。 副本基本上是彼此的镜像,但由于状态存在细微差别,因此统计信息可能有所不同。 例如,一个副本可能删除了对统计信息有影响的文档,这些统计信息由其他副本合并而来。 通常,每个副本的统计信息的差异在较小的索引中更为明显。 以下部分提供有关此条件的详细信息。 |
分片对查询结果的影响
一个分片是一个索引的块。 Azure AI 搜索将索引划分为分片,以便更快地添加分区(通过将分片移动到新的搜索单位)。 在搜索服务中,分片管理是实现细节且不可配置,但知道索引是分片的有助于你了解排名和自动完成行为中的偶然异常:
排名异常:搜索得分首先在分片层面计算,然后汇总成一个结果集。 根据分片内容的特征,一个分片中的匹配项的排名可能高于另一个分片中的匹配项。 如果你在搜索结果中发现与预料相反的排名,则很可能是由于分片的影响,尤其是在索引较小的情况下。 你可以通过选择在整个索引中全局计算评分来避免这些排名异常,但这样做会导致性能下降。
自动完成异常:自动完成查询(根据仅输入了一部分内容的单词的前几个字符进行匹配)接受一个模糊参数,该参数允许有微小的拼写差异。 对于自动完成,模糊匹配被限制为当前分片中的字词。 例如,如果某个分片包含“Microsoft”,并且输入了部分字词“micro”,则搜索引擎将针对该分片中的“Microsoft”进行匹配,但不会在包含索引剩余部分的其他分片中进行匹配。
下图显示了副本、分区、分片与搜索单位之间的关系。 它显示了一个示例,该示例说明了在具有两个副本和两个分区的服务中,单个索引如何跨越四个搜索单位。 这四个搜索单位每个都只存储索引的一半分片。 左列中的搜索单位存储分片的第一半,构成第一个分区,而右列中的搜索单位存储分片的第二半,构成第二个分区。 由于有两个副本,因此每个索引分片有两个拷贝。 顶部行中的搜索单位存储着一个副本,构成第一个副本,而底部行中的搜索单位存储着另一个副本,构成第二个副本。
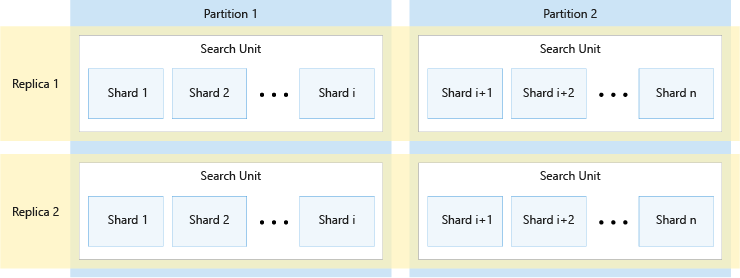
上图只是一个示例。 分区和副本可以有多种组合,总计最多可以有 36 个搜索单元。
注意
副本数和分区数必须能被 12 整除(具体而言,为 1、2、3、4、6、12)。 Azure AI 搜索将每个索引预先分割为 12 个分片,以便将其平均分散到所有分区。 例如,如果服务有三个分区,而你创建了新索引,则每个分区将包含该索引的四个分片。 Azure AI 搜索为索引分片的方法属于实现细节,在将来的版本中可能发生变化。 尽管目前的数字为 12,但请不要期望将来该数字永远都是 12。
评分统计数据和粘性会话
为了实现可伸缩性,Azure AI 搜索会通过分片过程横向分布每个索引,这意味着,索引的某些部分在物理上是独立的。
默认情况下,文档的评分是根据分片中数据的统计属性计算的。 此方法对于大型数据集而言通常不会造成问题,与基于所有分片中的信息计算评分相比,此方法可提供更好的性能。 也就是说,使用这种性能优化可能会导致两个非常相似的文档(甚至相同的文档)最终可能出现不同的相关性评分(如果这些文档出现在不同的分片中)。
如果你偏向于基于所有分片中的统计属性计算分数,可通过添加 scoringStatistics=global 作为查询参数(或者添加 "scoringStatistics": "global" 作为查询请求的正文参数)来执行此操作。
POST https://[service name].search.azure.cn/indexes/hotels/docs/search?api-version=2026-04-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
使用 scoringStatistics 可确保同一副本中的所有分片提供相同的结果。 也就是说,不同的副本可能相互之间略有不同,因为它们总是会随着索引的最新更改而更新。 在某些情况下,你可能希望用户在“查询会话”期间获得更一致的结果。 在这种情况下,可以提供 sessionId 作为查询的一部分。
sessionId 是你创建的用于引用唯一用户会话的唯一字符串。
POST https://[service name].search.azure.cn/indexes/hotels/docs/search?api-version=2026-04-01
{
"search": "<query string>",
"sessionId": "<string>"
}
只要使用相同的 sessionId,就会尽最大努力以同一副本为目标,从而提高用户将看到的结果的一致性。
注意
反复使用相同的 sessionId 值可能会干扰跨副本对请求进行负载均衡,并对搜索服务的性能产生负面影响。 用作 sessionId 的值不能以“_”字符开头。
相关性优化
在 Azure AI 搜索中,对于关键字搜索和混合查询的文本部分,可以通过以下机制配置 BM25 算法参数,并且调整搜索相关性和提升搜索分数。
| 方法 | 实现 | 说明 |
|---|---|---|
| BM25 算法配置 | 搜索索引 | 配置文档长度和词条频率如何影响相关性分数。 |
| 评分配置文件 | 搜索索引 | 提供根据内容特征提高匹配项的搜索分数的标准。 例如,你可以根据它们的创收潜力来提升匹配项,推广较新的项目,或者提升已经在库存中存放过久的项目。 计分概要文件属于索引定义的一部分,由加权字段、函数和参数组成。 可以通过修改计分概要文件来更新现有索引,而无需重建索引。 |
| 语义排名 | 查询请求 | 将计算机阅读理解应用于搜索结果,从而将语义上更加相关的结果提升到顶部。 |
| featuresMode 参数 | 查询请求 | 此参数主要用于解包 BM25 排名的分数,但可用于提供自定义评分解决方案的代码。 |
featuresMode 参数(预览版)
注意
该 featuresMode 参数在 REST API 文档中未被描述,但你可以在 REST API 的预览调用环境中使用它来执行 BM25 排名的文本(关键字)搜索。
搜索文档(预览版) 请求支持一个 featuresMode 参数,该参数提供有关字段级别的 BM25 相关性分数的更多详细信息。 虽然@searchScore是针对整个文档计算的(该文档在此查询的上下文中的相关性如何),但featuresMode通过@search.features结构显示各个字段的信息。 该结构包含查询中使用的所有字段(查询中通过 searchFields 指定的特定字段,或索引中属性为“可搜索”的所有字段)。
featuresMode 的有效值:
- “none”(默认值)。 不会返回功能级评分详细信息。
- “启用”。 返回每个字段的评分详细分解
对于每个字段,@search.features 可获得以下值:
- 在字段中找到的唯一标记数
- 相似性得分,即字段内容相对于查询项的相似程度的度量
- 字词频率,即在字段中找到查询项的次数
当你尝试了解某些文档在搜索结果中排名较高或更低的原因时,此参数特别有用。 它有助于说明不同字段对整体分数的贡献。
对于面向“说明”字段的查询,请求可能如下所示:
POST {{baseUrl}}/indexes/hotels-sample/docs/search?api-version=2026-05-01-preview HTTP/1.1
Content-Type: application/json
Authorization: Bearer {{accessToken}}
{
"search": "lake view",
"select": "HotelId, HotelName, Tags, Description",
"featuresMode": "enabled",
"searchFields": "Description, Tags",
"count": true
}
包含 @search.features 的响应可能如以下示例所示。
"value": [
{
"@search.score": 3.0860271,
"@search.features": {
"Description": {
"uniqueTokenMatches": 2.0,
"similarityScore": 3.0860272,
"termFrequency": 2.0
}
},
"HotelName": "Downtown Mix Hotel",
"Description": "Mix and mingle in the heart of the city. Shop and dine, mix and mingle in the heart of downtown, where fab lake views unite with a cheeky design.",
"Tags": [
"air conditioning",
"laundry service",
"free wifi"
]
},
{
"@search.score": 2.7294855,
"@search.features": {
"Description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 1.6023184,
"termFrequency": 1.0
},
"Tags": {
"uniqueTokenMatches": 1.0,
"similarityScore": 1.1271671,
"termFrequency": 1.0
}
},
"HotelName": "Ocean Water Resort & Spa",
"Description": "New Luxury Hotel for the vacation of a lifetime. Bay views from every room, location near the pier, rooftop pool, waterfront dining & more.",
"Tags": [
"view",
"pool",
"restaurant"
]
}
]
可以使用自定义评分解决方案中的这些数据点或使用相关信息来调试搜索相关性问题。
全文查询响应中的排名结果数
默认情况下,如果你不使用分页,搜索引擎会返回全文搜索的前 50 个最高排名匹配项。 可以使用 top 参数返回较少或较多的项(单个响应中最多 1,000 个)。 可以使用 skip 和 next 来对结果进行分页。 分页功能决定每个逻辑页面上的结果数量,并支持内容导航。 有关详细信息,请参阅形状搜索结果。
如果全文查询是混合查询的一部分,则可以设置 maxTextRecallSize 来增加或减少查询文本端的结果数。
全文搜索的最大限制为 1,000 个匹配项(请参阅 API 响应限制)。 找到 1,000 个匹配项后,搜索引擎便不再进行查找。