Azure AI 搜索可以从 Azure Blob 存储中存储的 PDF 文档中提取和索引文本和图像。 本教程介绍如何在 Azure AI 搜索中构建多模式索引管道, 该管道使用内置文本拆分技能对数据进行分块 , 并使用多模式嵌入 来向量化同一文档中的文本和图像。 裁剪的图像存储在知识存储中,文本和视觉内容都经过矢量化并引入到可搜索索引中。
在本教程中,你使用:
一个包含 36 页的 PDF 文档,它将丰富的视觉内容(如图表、信息图和扫描的页面)与传统文本相结合。
用于创建索引流程的索引器和技能集,该流程包括通过技能进行 AI 增强。
文档提取技能用于提取规范化的图像和文本。
用于向量化文本和图像的 Azure 视觉多模式嵌入技能 。
配置为存储提取的文本和图像内容的搜索索引。 某些内容针对基于矢量的相似性搜索进行矢量化。
本教程演示了使用文档提取技能为多模式内容编制索引的低成本方法。 它支持从从 Azure Blob 存储提取的文档提取和搜索文本和图像。 但是,它不包括文本的位置元数据,例如页码或边界区域。 有关包含结构化文本布局和空间元数据的更全面的解决方案,请参阅 教程:从结构化文档布局向量化。
注释
文档提取技能的图像提取不是免费的。 将imageAction设置为generateNormalizedImages时,技能集会触发图像提取,这将产生额外费用。 有关计费信息,请参阅 Azure AI 搜索定价。
先决条件
Azure AI 服务资源。 此资源提供对本教程中使用的 Azure Vision 多模式嵌入模型的访问权限。 必须使用 AI 服务资源来访问此资源的技能集。
Azure AI 搜索。 为搜索服务配置 基于角色的访问控制,以及用于连接到 Azure 存储和 Azure 视觉的托管标识。 您的服务必须达到基本层级或更高。 免费层不支持本教程。
局限性
- Azure 视觉多模式嵌入技能具有有限的区域可用性。 创建 AI 服务资源时,请选择提供多模式嵌入的区域。 有关提供多模式嵌入的区域的更新列表,请参阅 Azure 视觉文档。
准备数据
以下说明适用于提供示例数据的 Azure 存储,并托管知识存储。 搜索服务标识需要对 Azure 存储进行读取访问权限才能检索示例数据,并且需要写入访问权限才能创建知识存储。 搜索服务使用在环境变量中提供的名称,在技能集处理过程中为裁剪的图像创建容器。
下载以下示例 PDF: sustainable-ai-pdf
在 Azure 存储中,创建名为 sustainable-ai-pdf 的新容器。
-
为索引器检索数据,分配 Storage Blob Data Reader。 分配 存储 Blob 数据参与者 和 存储表数据参与者 来创建和加载知识存储。 可以将系统分配的托管标识或用户分配的托管标识用于搜索服务角色分配。
对于使用系统分配的托管标识建立的连接,请获取包含 ResourceId 的连接字符串,不包含帐户密钥或密码。 ResourceId 必须包括存储帐户的订阅 ID、存储帐户的资源组和存储帐户名称。 连接字符串如以下示例所示:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }对于使用用户分配的托管标识建立的连接,请获取包含 ResourceId 的连接字符串,不包含帐户密钥或密码。 ResourceId 必须包括存储帐户的订阅 ID、存储帐户的资源组和存储帐户名称。 使用以下示例中所示的语法提供标识。 将 userAssignedIdentity 设置为用户分配的托管标识。 连接字符串如以下示例所示:
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }, "identity" : { "@odata.type": "#Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity" : "/subscriptions/00000000-0000-0000-0000-00000000/resourcegroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.ManagedIdentity/userAssignedIdentities/MY-DEMO-USER-MANAGED-IDENTITY" }
准备模型
本教程假设你已有一个 Azure AI 多服务帐户,通过该帐户,技能调用 Azure AI 视觉多模式 4.0 嵌入模型。 搜索服务使用其托管标识在技能集处理期间连接到模型。 本部分提供指导和链接,用于分配授权访问角色。
登录到 Azure 门户(而不是 AI 服务门户),并找到 Azure AI 多服务帐户。 请确保它位于提供 多模式 4.0 API 的区域。
选择“访问控制(IAM)”。
选择 “添加 ”,然后选择 “添加角色分配”。
搜索 认知服务用户 ,然后选择它。
选择 “托管标识 ”,然后分配 搜索服务托管标识。
配置您的 REST 文件
在本教程中,与 Azure AI 搜索的本地 REST 客户端连接需要终结点和 API 密钥。 可以从 Azure 门户获取这些值。 有关备用连接方法,请参阅 “连接到搜索服务”。
对于在索引器和技能组处理期间发生的经过身份验证的连接,搜索服务使用之前定义的角色分配。
启动 Visual Studio Code,并创建一个新文件。
为请求中使用的变量提供值。 对于
@storageConnection,请确保连接字符串没有尾随分号或引号。 对于@imageProjectionContainer,请提供 Blob 存储中唯一的容器名称。 Azure AI 搜索会在技能处理期间为你创建此容器。@searchUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @searchApiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @cognitiveServicesUrl = PUT-YOUR-AZURE-AI-MULTI-SERVICE-ENDPOINT-HERE @modelVersion = 2023-04-15 @imageProjectionContainer=sustainable-ai-pdf-images使用
.rest或.http文件扩展名保存文件。 有关 REST 客户端的帮助,请参阅 快速入门:使用 REST 进行全文搜索。
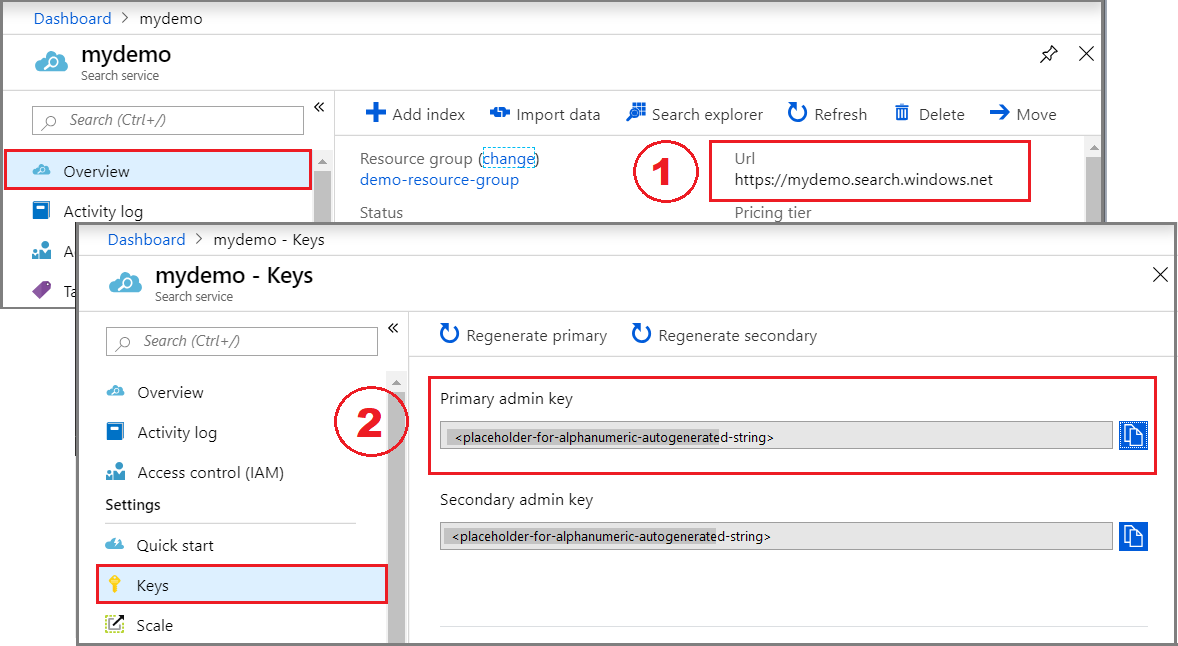
若要获取 Azure AI 搜索终结点和 API 密钥,请执行以下作:
登录到 Azure 门户,导航到搜索服务“概述”页,然后复制 URL。 示例终结点可能类似于
https://mydemo.search.azure.cn。在“设置”“密钥”下,复制管理密钥>。 管理密钥用于添加、修改和删除对象。 有两个可互换的管理密钥。 复制其中任意一个。
创建数据源
创建数据源 (REST) 会创建数据源连接,用于指定要编制索引的数据。
POST {{searchUrl}}/datasources?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name":"doc-extraction-multimodal-embedding-ds",
"description":null,
"type":"azureblob",
"subtype":null,
"credentials":{
"connectionString":"{{storageConnection}}"
},
"container":{
"name":"sustainable-ai-pdf",
"query":null
},
"dataChangeDetectionPolicy":null,
"dataDeletionDetectionPolicy":null,
"encryptionKey":null,
"identity":null
}
发送请求。 响应应如下所示:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows-int.net:443/datasources('doc-extraction-multimodal-embedding-ds')?api-version=2025-11-01-preview -Preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 4eb8bcc3-27b5-44af-834e-295ed078e8ed
elapsed-time: 346
Date: Sat, 26 Apr 2025 21:25:24 GMT
Connection: close
{
"name": "doc-extraction-multimodal-embedding-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"indexerPermissionOptions": [],
"credentials": {
"connectionString": null
},
"container": {
"name": "sustainable-ai-pdf",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
创建索引
创建索引 (REST) 会在搜索服务中创建搜索索引。 索引指定所有参数及其属性。
对于嵌套 JSON,索引字段必须与源字段相同。 目前,Azure AI 搜索不支持将字段映射到嵌套 JSON,因此字段名称和数据类型必须完全匹配。 以下索引与原始内容中的 JSON 元素保持一致。
### Create an index
POST {{searchUrl}}/indexes?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-extraction-multimodal-embedding-index",
"fields": [
{
"name": "content_id",
"type": "Edm.String",
"retrievable": true,
"key": true,
"analyzer": "keyword"
},
{
"name": "text_document_id",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false
},
{
"name": "document_title",
"type": "Edm.String",
"searchable": true
},
{
"name": "image_document_id",
"type": "Edm.String",
"filterable": true,
"retrievable": true
},
{
"name": "content_text",
"type": "Edm.String",
"searchable": true,
"retrievable": true
},
{
"name": "content_embedding",
"type": "Collection(Edm.Single)",
"dimensions": 1024,
"searchable": true,
"retrievable": true,
"vectorSearchProfile": "hnsw"
},
{
"name": "content_path",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "offset",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "location_metadata",
"type": "Edm.ComplexType",
"fields": [
{
"name": "page_number",
"type": "Edm.Int32",
"searchable": false,
"retrievable": true
},
{
"name": "bounding_polygons",
"type": "Edm.String",
"searchable": false,
"retrievable": true,
"filterable": false,
"sortable": false,
"facetable": false
}
]
}
],
"vectorSearch": {
"profiles": [
{
"name": "hnsw",
"algorithm": "defaulthnsw",
"vectorizer": "demo-vectorizer"
}
],
"algorithms": [
{
"name": "defaulthnsw",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"metric": "cosine"
}
}
],
"vectorizers": [
{
"name": "demo-vectorizer",
"kind": "aiServicesVision",
"aiServicesVisionParameters": {
"resourceUri": "{{cognitiveServicesUrl}}",
"authIdentity": null,
"modelVersion": "{{modelVersion}}"
}
}
]
},
"semantic": {
"defaultConfiguration": "semanticconfig",
"configurations": [
{
"name": "semanticconfig",
"prioritizedFields": {
"titleField": {
"fieldName": "document_title"
},
"prioritizedContentFields": [
],
"prioritizedKeywordsFields": []
}
}
]
}
}
要点:
文本和图像嵌入存储在
content_embedding字段中,并且必须配置适当的大小(例如 1024)和矢量搜索配置文件。location_metadata捕获每个规范化图像的边界多边形和页码元数据,从而实现精确的空间搜索或 UI 叠加。location_metadata仅存在于此应用场景中的图像中。 若要捕获文本的位置元数据,请考虑使用 文档布局技能。 深入教程在页面底部链接。有关矢量搜索的详细信息,请参阅 Azure AI 搜索中的矢量。
有关语义排名的详细信息,请参阅 Azure AI 搜索中的语义排名
创建技能集
创建技能集(REST) 会在搜索服务中创建技能集。 技能集定义了在编制索引之前对内容进行分块和嵌入的操作。 此技能集使用内置的文档提取技能提取文本和图像。 它使用文本拆分技能对大文本进行分块。 它使用 Azure 视觉多模式嵌入技能来向量化图像和文本内容。
### Create a skillset
POST {{searchUrl}}/skillsets?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-extraction-multimodal-embedding-skillset",
"description": "A test skillset",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentExtractionSkill",
"name": "document-extraction-skill",
"description": "Document extraction skill to extract text and images from documents",
"parsingMode": "default",
"dataToExtract": "contentAndMetadata",
"configuration": {
"imageAction": "generateNormalizedImages",
"normalizedImageMaxWidth": 2000,
"normalizedImageMaxHeight": 2000
},
"context": "/document",
"inputs": [
{
"name": "file_data",
"source": "/document/file_data"
}
],
"outputs": [
{
"name": "content",
"targetName": "extracted_content"
},
{
"name": "normalized_images",
"targetName": "normalized_images"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "split-skill",
"description": "Split skill to chunk documents",
"context": "/document",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 200,
"unit": "characters",
"inputs": [
{
"name": "text",
"source": "/document/extracted_content",
"inputs": []
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Vision.VectorizeSkill",
"name": "text-embedding-skill",
"description": "Vision Vectorization skill for text",
"context": "/document/pages/*",
"modelVersion": "{{modelVersion}}",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "vector",
"targetName": "text_vector"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Vision.VectorizeSkill",
"name": "image-embedding-skill",
"description": "Vision Vectorization skill for images",
"context": "/document/normalized_images/*",
"modelVersion": "{{modelVersion}}",
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "vector",
"targetName": "image_vector"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "shaper-skill",
"description": "Shaper skill to reshape the data to fit the index schema",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "normalized_images",
"source": "/document/normalized_images/*",
"inputs": []
},
{
"name": "imagePath",
"source": "='{{imageProjectionContainer}}/'+$(/document/normalized_images/*/imagePath)",
"inputs": []
},
{
"name": "dataUri",
"source": "='data:image/jpeg;base64,'+$(/document/normalized_images/*/data)",
"inputs": []
},
{
"name": "location_metadata",
"sourceContext": "/document/normalized_images/*",
"inputs": [
{
"name": "page_number",
"source": "/document/normalized_images/*/pageNumber"
},
{
"name": "bounding_polygons",
"source": "/document/normalized_images/*/boundingPolygon"
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "new_normalized_images"
}
]
}
],
"cognitiveServices": {
"@odata.type": "#Microsoft.Azure.Search.AIServicesByIdentity",
"subdomainUrl": "{{cognitiveServicesUrl}}",
"identity": null
},
"indexProjections": {
"selectors": [
{
"targetIndexName": "doc-extraction-multimodal-embedding-index",
"parentKeyFieldName": "text_document_id",
"sourceContext": "/document/pages/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/pages/*/text_vector"
},
{
"name": "content_text",
"source": "/document/pages/*"
},
{
"name": "document_title",
"source": "/document/document_title"
}
]
},
{
"targetIndexName": "doc-extraction-multimodal-embedding-index",
"parentKeyFieldName": "image_document_id",
"sourceContext": "/document/normalized_images/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/normalized_images/*/image_vector"
},
{
"name": "content_path",
"source": "/document/normalized_images/*/new_normalized_images/imagePath"
},
{
"name": "location_metadata",
"source": "/document/normalized_images/*/new_normalized_images/location_metadata"
},
{
"name": "document_title",
"source": "/document/document_title"
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
},
"knowledgeStore": {
"storageConnectionString": "{{storageConnection}}",
"identity": null,
"projections": [
{
"files": [
{
"storageContainer": "{{imageProjectionContainer}}",
"source": "/document/normalized_images/*"
}
]
}
]
}
}
此技能集提取文本和图像、向量化图像元数据,以便投影到索引中。
要点:
该
content_text字段填充了通过文档提取技能提取的文本,并通过拆分技能对其进行分块处理。content_path包含指定图像投影容器中图像文件的相对路径。 仅当imageAction设置为generateNormalizedImages时,才会为从 PDF 中提取的图像生成此字段,并且可以从源字段/document/normalized_images/*/imagePath的扩充文档中进行映射。Azure 视觉多模态嵌入技能支持通过输入的不同(文本或图像)来嵌入文本数据和视觉数据,使用的是相同的技能类型。 有关详细信息,请参阅 Azure Vision 多模式嵌入技能。
创建并运行索引器
创建索引器会在搜索服务上创建索引器。 索引器连接到数据源、加载数据、运行技能集和为扩充数据编制索引。
### Create and run an indexer
POST {{searchUrl}}/indexers?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-extraction-multimodal-embedding-indexer",
"dataSourceName": "doc-extraction-multimodal-embedding-ds",
"targetIndexName": "doc-extraction-multimodal-embedding-index",
"skillsetName": "doc-extraction-multimodal-embedding-skillset",
"parameters": {
"maxFailedItems": -1,
"maxFailedItemsPerBatch": 0,
"batchSize": 1,
"configuration": {
"allowSkillsetToReadFileData": true
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "document_title"
}
],
"outputFieldMappings": []
}
运行查询
加载第一个文档后,可立即开始搜索。
### Query the index
POST {{searchUrl}}/indexes/doc-extraction-multimodal-embedding-index/docs/search?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "*",
"count": true
}
发送请求。 这是一个未指定的全文搜索查询,它返回索引中标记为可检索的所有字段,以及文档计数。 响应应如下所示:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 712ca003-9493-40f8-a15e-cf719734a805
elapsed-time: 198
Date: Wed, 30 Apr 2025 23:20:53 GMT
Connection: close
{
"@odata.count": 100,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.azure.cn/indexes/doc-extraction-multimodal-embedding-index/docs/search?api-version=2025-11-01-preview "
}
响应中返回 100 个文档。
对于筛选器,还可以使用逻辑运算符(and、or、not)和比较运算符(eq、ne、gt、lt、ge、le)。 字符串比较区分大小写。 有关详细信息和示例,请参阅 简单搜索查询的示例。
注释
该 $filter 参数仅适用于在创建索引期间标记为可筛选的字段。
### Query for only images
POST {{searchUrl}}/indexes/doc-extraction-multimodal-embedding-index/docs/search?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "*",
"count": true,
"filter": "image_document_id ne null"
}
### Query for text or images with content related to energy, returning the id, parent document, and text (only populated for text chunks), and the content path where the image is saved in the knowledge store (only populated for images)
POST {{searchUrl}}/indexes/doc-extraction-multimodal-embedding-index/docs/search?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "energy",
"count": true,
"select": "content_id, document_title, content_text, content_path"
}
重置并重新运行
可以重置索引器以清除高水位标记,从而实现完全重新运行。 以下 POST 请求用于重置,然后重新运行。
### Reset the indexer
POST {{searchUrl}}/indexers/doc-extraction-multimodal-embedding-indexer/reset?api-version=2025-11-01-preview HTTP/1.1
api-key: {{searchApiKey}}
### Run the indexer
POST {{searchUrl}}/indexers/doc-extraction-multimodal-embedding-indexer/run?api-version=2025-11-01-preview HTTP/1.1
api-key: {{searchApiKey}}
### Check indexer status
GET {{searchUrl}}/indexers/doc-extraction-multimodal-embedding-indexer/status?api-version=2025-11-01-preview HTTP/1.1
api-key: {{searchApiKey}}
清理资源
在自己的订阅中操作时,最好在项目结束时移除不再需要的资源。 持续运行资源可能会产生费用。 可以逐个删除资源,也可以删除资源组以删除整个资源集。
你可以使用 Azure 门户来删除索引、索引器和数据源。
另请参阅
熟悉多模式索引方案的示例实现后,请查看: