配置新的Azure AI 搜索服务涉及多个任务来优化安全性、访问和性能。 本文提供了一份第一天的检查清单,帮助你在 Azure 门户中配置服务。
创建搜索服务后,我们建议您:
配置基于角色的访问
门户访问基于 角色分配。 默认情况下,新的搜索服务至少有一个服务管理员或所有者。 服务管理员、共同管理员和所有者有权创建更多管理员并分配其他角色。 他们还可以访问所有默认搜索服务上的门户页面和操作。
提示
默认情况下,任何管理员或所有者都可以创建或删除服务。 若要防止意外删除,请考虑 锁定资源。
每个搜索服务附带 API 密钥 ,默认使用基于密钥的身份验证。 但是,我们建议使用Microsoft Entra ID和基于角色的访问控制(RBAC)来提高安全性。 RBAC 无需以纯文本形式存储和传递 API 密钥。
从基于密钥的身份验证切换到无密钥身份验证时,服务管理员必须分配自己的数据平面角色,以便完全访问对象和数据。 这些角色包括搜索服务参与者、搜索索引数据参与者和搜索索引数据读取者。
若要配置基于角色的访问权限,请执行以下操作:
在搜索服务上启用角色。 建议同时使用 API 密钥和角色。
分配数据平面角色 以替换禁用 API 密钥时丢失的功能。 所有者只需要搜索索引数据读取器,但开发人员需要 更多角色。
角色分配可能需要几分钟才能生效。 在此之前,用于数据平面操作的门户页面会显示以下消息:
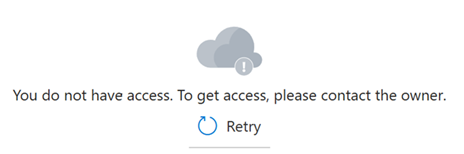
为解决方案开发人员和应用分配更多角色。
配置托管标识
如果计划使用索引器进行自动索引编制、应用 AI 或集成向量化,则应 将搜索服务配置为使用托管标识。 然后,可以在授权搜索服务访问数据和操作的其他Azure服务上分配角色。
对于集成向量化,搜索服务标识需要以下角色:
- Azure 存储上的存储 Blob 数据读取器
- Azure AI 服务资源上的认知服务数据用户
角色分配可能需要几分钟才能生效。
在转到网络安全之前,请考虑测试所有连接点以验证角色分配。 运行 导入向导 以测试权限。
配置网络安全
默认情况下,搜索服务通过公共 Internet 连接接受经过身份验证和授权的请求。 有两个选项可用于增强网络安全:
若要了解 Azure AI 搜索 中的入站和出站呼叫,请参阅 Understand 网络流量模式。
查看容量并了解账单
默认情况下,搜索服务使用一个副本和一个分区创建。 可以通过添加副本和分区来添加容量,但我们建议等到卷需要添加容量时再这样做。 许多客户在最低配置上运行生产工作负荷。
如果你选择加入标准计划,语义排名器可能会增加运行服务的成本。 如果不想使用此功能,可以在服务级别 禁用语义排名器 。
若要了解影响计费的其他功能,请参阅 如何为 Azure AI 搜索 计费。
启用诊断日志记录
启用诊断日志记录以跟踪用户活动。 如果跳过此步骤,仍会自动获取 活动日志 和 平台指标 。 但是,如果需要索引和查询使用情况的信息,则应启用诊断日志记录,并选择记录操作的目标。 建议Log Analytics工作区进行持久存储,以便在Azure门户中运行系统查询。
在内部,Azure收集有关服务和平台的遥测数据。 若要详细了解数据保留,请参阅指标的保留期。
若要详细了解数据位置和隐私,请参阅 数据驻留。
向开发人员提供连接信息
若要连接到Azure AI 搜索,开发人员需要:
- “概述”页上提供的终结点或 URL。
- “密钥”页中的 API 密钥,或者角色分配。 我们推荐搜索服务参与者、搜索索引数据参与者和搜索索引数据读取者。
建议通过门户访问导入数据向导和搜索资源管理器。 必须是参与者或更高版本才能运行向导。
相关内容
有关服务管理的编程支持,请参阅以下 API 和模块:
还可以将Azure SDK中的管理客户端库用于.NET、Python、Java和 JavaScript。
除预览管理功能外,所有模式和语言都具备功能一致性。 一般情况下,预览版管理功能首先通过管理 REST API 发布。