本教程介绍如何处理使用分层命名空间的存储帐户中的事件。
你将生成一个小型解决方案,它可以让用户通过上传描述销售订单的逗号分隔值 (csv) 文件,来填充 Databricks Delta 表。 为了生成此解决方案,你要将事件网格订阅、Azure 函数和 Azure Databricks 中的作业连接到一起。
在本教程中,将:
- 创建一个事件网格订阅用于调用 Azure 函数。
- 创建一个 Azure 函数,用于接收事件中的通知,然后运行 Azure Databricks 中的作业。
- 创建一个 Databricks 作业,用于将客户订单插入到存储帐户中的 Databricks Delta 表。
我们将从 Azure Databricks 工作区开始,按相反的顺序生成此解决方案。
先决条件
创建一个存储帐户,该帐户必须有一个分层命名空间 (Azure Data Lake Storage)。 本教程使用名为
contosoorders的存储帐户。请确保你的用户帐户分配有存储 Blob 数据参与者角色。
创建服务主体,创建客户端密码,然后向服务主体授予对存储帐户的访问权限。
请参阅教程:连接到 Azure Data Lake Storage(步骤 1 到 3)。 完成这些步骤后,请确保将租户 ID、应用 ID 和客户端密码值粘贴到文本文件中。 很快就会需要这些值。
如果没有 Azure 订阅,可在开始前创建一个试用帐户。
创建销售订单
首先创建一个描述销售订单的 csv 文件,然后将该文件上传到存储帐户。 稍后将使用此文件中的数据来填充 Databricks Delta 表中的第一行。
导航到 Azure 门户中的新存储帐户。
选择“存储浏览器”->“Blob 容器”->“添加容器”,并创建名为 data 的新容器。
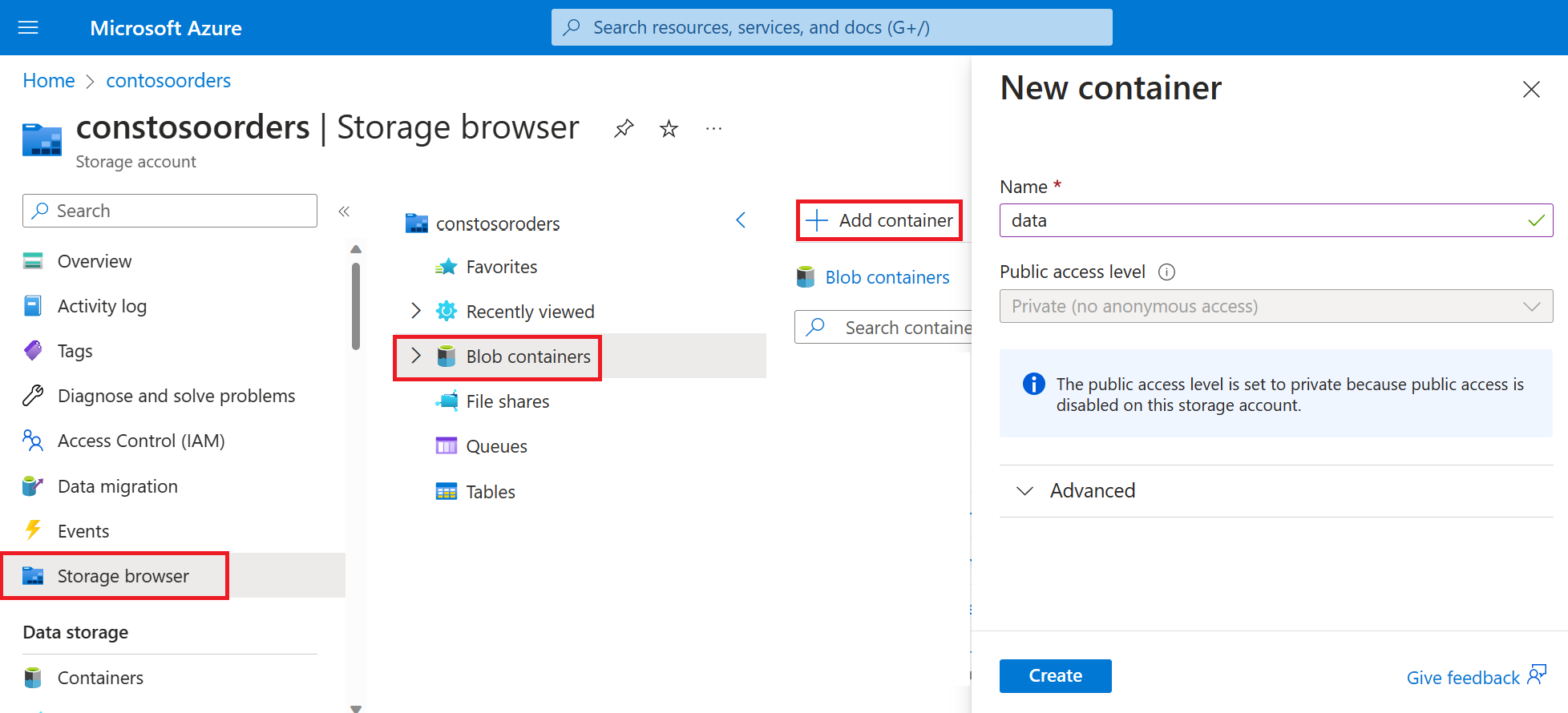
在 data 容器中,创建名为 input 的目录。
在文本编辑器中粘贴以下文本:
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United Kingdom将此文件保存到本地计算机,并将其命名为 data.csv。
在存储浏览器中,将此文件上传到 input 文件夹。
在 Azure Databricks 中创建作业
在本部分,你将执行以下任务:
- 创建 Azure Databricks 工作区。
- 创建笔记本。
- 创建并填充 Databricks Delta 表。
- 添加用于将行插入 Databricks Delta 表的代码。
- 创建一个作业。
创建 Azure Databricks 工作区
在本部分,使用 Azure 门户创建 Azure Databricks 工作区。
创建 Azure Databricks 工作区。 将该工作区命名为
contoso-orders。 请参阅创建 Azure Databricks 工作区。创建群集。 将群集命名为
customer-order-cluster。 参阅创建群集。创建笔记本。 将笔记本命名为
configure-customer-table,并选择“Python”作为笔记本的默认语言。 请参阅创建笔记本。
创建并填充 Databricks Delta 表
在创建的笔记本中,将以下代码块复制并粘贴到第一个单元中,但暂时不要运行此代码。
请将此代码块中的
appId、password和tenant占位符值替换为在完成本教程的先决条件时收集的值。dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.partner.microsoftonline.cn/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.chinacloudapi.cn/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'此代码将创建名为 source_file 的小组件。 稍后你将创建一个 Azure 函数,用于调用此代码并将文件路径传递到该小组件。 此代码还使用存储帐户对你的服务主体进行身份验证,并创建要在其他单元中使用的一些变量。
注意
在生产设置中,请考虑将身份验证密钥存储在 Azure Databricks 中。 然后,将查找密钥(而不是身份验证密钥)添加到代码块。
例如,不使用这行代码:spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>"),而是使用以下代码行:spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>"))。按 SHIFT + ENTER 键,运行此块中的代码。
将以下代码块复制并粘贴到另一个单元中,然后按 SHIFT + ENTER 键运行此代码块中的代码。
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))此代码将在存储帐户中创建 Databricks Delta 表,然后从前面上传的 csv 文件中加载一些初始数据。
成功运行此代码块后,请从笔记本中删除此代码块。
添加用于将行插入 Databricks Delta 表的代码
将以下代码块复制并粘贴到另一个单元中,但不要运行此单元。
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")此代码使用 csv 文件中的数据将数据插入到临时表视图。 该 csv 文件的路径源自在前一步骤中创建的输入小组件。
将以下代码块复制并粘贴到另一个单元格中。 此代码将临时表视图的内容与 Databricks Delta 表合并。
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
创建作业
创建一个作业来运行前面所创建的笔记本。 稍后你将创建一个 Azure 函数,用于在引发事件时运行此作业。
选择“新建”->“作业”。
为作业命名,并选择创建的笔记本和群集。 然后选择“创建”以创建作业。
创建 Azure 函数
创建用于运行作业的 Azure 函数。
在 Azure Databricks 工作区中,单击顶部栏中 Azure Databricks 用户名,然后从下拉列表中选择“用户设置”。
在“访问令牌”选项卡上,选择“生成新令牌”。
复制显示的令牌,然后单击“完成”。
在 Databricks 工作区的上角选择人像图标,然后选择“用户设置”。

依次选择“生成新令牌”按钮、“生成”按钮。
确保将令牌复制到安全位置。 Azure 函数需要使用此令牌对 Databricks 进行身份验证,以便能够运行该作业。
在 Azure 门户菜单上或在门户主页中,选择“创建资源”。
在 “新建” 页面,选择 “计算”>“函数应用” 。
在“创建函数应用”页的“基本信息”选项卡中选择一个资源组,然后更改或验证以下设置:
设置 值 Function App 名称 contosoorder 运行时堆栈 .NET 发布 代码 操作系统 Windows 计划类型 消耗(无服务器) 选择“查看 + 创建”,然后选择“创建”。
部署完成后,选择“转到资源”打开函数应用的概述页。
在“设置”组中,选择“配置”。
在“应用程序设置”页中,选择“新建应用程序设置”按钮以添加每个设置。

添加以下设置:
设置名称 值 DBX_INSTANCE Databricks 工作区的区域。 例如: chinaeast2.databricks.azure.cnDBX_PAT 前面生成的个人访问令牌。 DBX_JOB_ID 正在运行的作业的标识符。 选择“保存”以提交这些设置。
在“函数”组中选择“函数”,然后选择“创建”。
选择“Azure 事件网格触发器”。
根据提示安装 Microsoft.Azure.WebJobs.Extensions.EventGrid 扩展。 如果必须安装该扩展,则必须再次选择“Azure 事件网格触发器”来创建函数。
此时将显示“新建函数”窗格。
在“新建函数”窗格中,将函数命名为 UpsertOrder,然后选择“创建”按钮。
将代码文件的内容替换为此代码,然后选择“保存”按钮:
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
此代码将分析有关引发的存储事件的信息,然后创建一条请求消息,其中包含触发了该事件的文件的 URL。 在该消息中,该函数会将一个值传递给前面创建的 source_file 小组件。 函数代码将该消息发送到 Databricks 作业,并使用前面获取的用于身份验证的令牌。
创建事件网格订阅
在本部分,你将创建一个事件网格订阅,用于在将文件上传到存储帐户时调用 Azure 函数。
选择“集成”,然后在“集成”页中选择“事件网格触发器”。
在“编辑触发器”窗格中,将事件命名为
eventGridEvent,然后选择“创建事件订阅”。注意
名称
eventGridEvent与传递到 Azure 函数中的参数名称匹配。在“创建事件订阅”页的“基本信息”选项卡中,更改或验证以下设置:
设置 值 名称 contoso-order-event-subscription 主题类型 存储帐户 源资源 contosoorders 系统主题名称 <create any name>筛选事件类型 已创建 Blob、已删除 Blob 选择“创建”按钮。
测试事件网格订阅
创建名为
customer-order.csv的文件,将以下信息粘贴到该文件中,并将其保存到本地计算机。InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra Leone在存储资源管理器中,将此文件上传到存储帐户的 input 文件夹。
上传文件会引发 Microsoft.Storage.BlobCreated 事件。 事件网格会通知所有订阅者已发生该事件。 在本例中,Azure 函数是唯一的订阅者。 Azure 函数将分析事件参数以确定发生了哪个事件。 然后,它将该文件的 URL 传递给 Databricks 作业。 Databricks 作业将读取该文件,并将某个行添加到存储帐户中的 Databricks Delta 表。
若要检查作业是否成功,请查看作业的运行。 你将看到完成状态。 有关如何查看作业的运行的详细信息,请参阅查看作业的运行
在新的工作簿单元中运行此查询,以查看更新的 Delta 表。
%sql select * from customer_data返回的表将显示最新记录。

若要更新此记录,请创建名为
customer-order-update.csv的文件,将以下信息粘贴到该文件中,然后将其保存到本地计算机。InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra Leone除了订单数量从
228更改为22外,此 CSV 文件几乎与前一文件相同。在存储资源管理器中,将此文件上传到存储帐户的 input 文件夹。
再次运行
select查询以查看更新后的增量表。%sql select * from customer_data返回的表将显示更新后的记录。

清理资源
如果不再需要本文中创建的资源,可以删除资源组和所有相关资源。 为此,请选择存储帐户所在的资源组,然后选择“删除”。