此备忘单提供了有关生成专用 SQL 池(前 SQL DW)解决方案的有用提示和最佳做法。
下图显示了使用专用 SQL 池(以前为 SQL DW)设计数据仓库的过程:
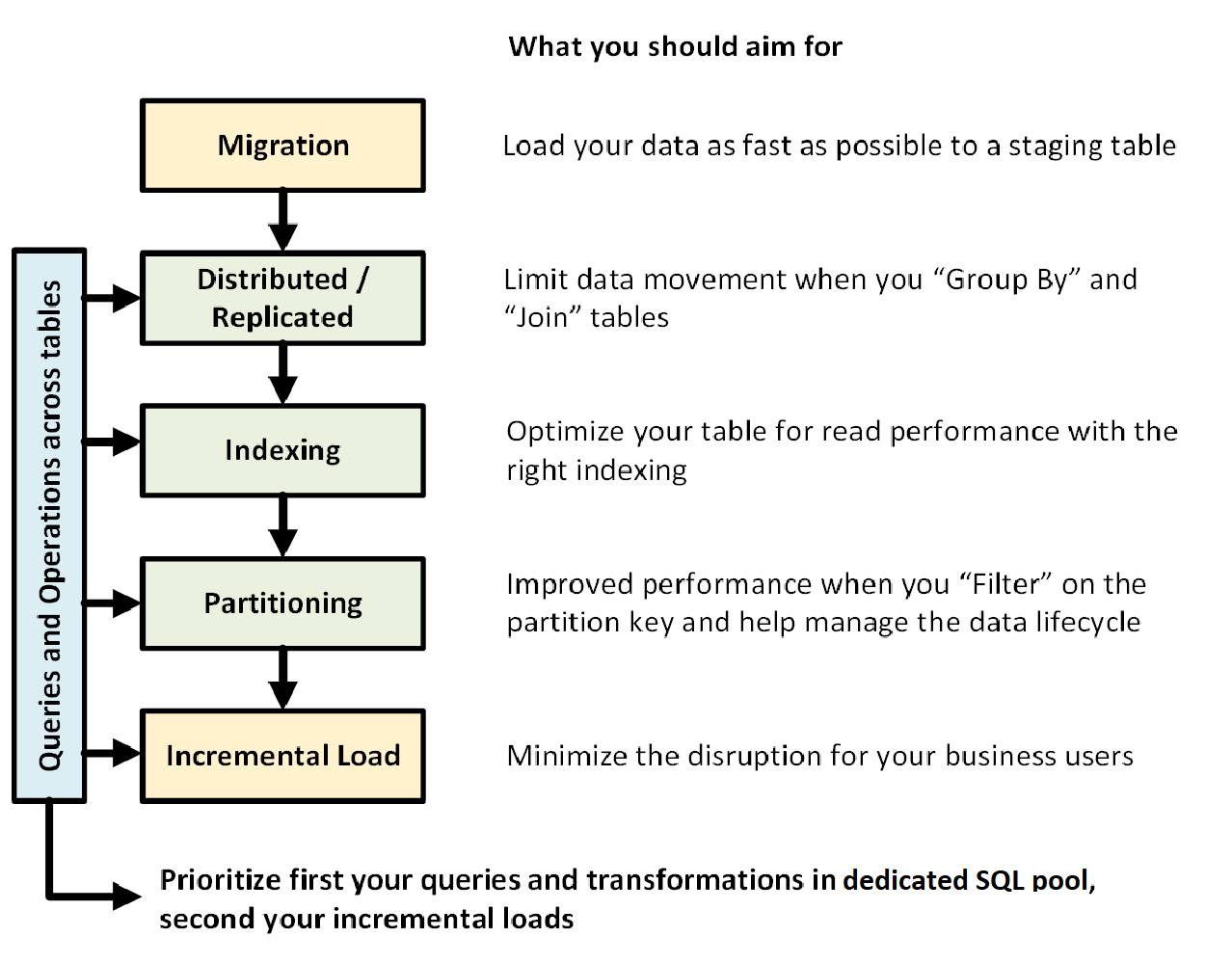
跨表的查询和操作
如果提前知道要在数据仓库中运行的主要操作和查询,可以优先考虑这些操作的数据仓库架构。 这些查询和操作可能包括(例如):
- 将一个或两个事实数据表与维度表相联接,筛选合并的表,然后将结果追加到数据市场。
- 对事实销售进行较大或较小的更新。
- 仅将数据追加到表。
提前了解操作类型有助于优化表格的设计。
数据迁移
首先,将数据加载到 Azure Blob 存储中。 接下来,使用 COPY 语句 将数据加载到临时表中。 使用以下配置:
| 设计 | 建议 |
|---|---|
| 配送 | 轮循机制 |
| 索引 | 堆 |
| 分区 | 没有 |
| 资源类 | largerc 或 xlargerc |
详细了解 数据迁移、 数据加载以及 提取、加载和转换(ELT)过程。
分布式表或复制表
根据表属性,使用以下策略:
| 类型 | 非常适合... | 谨慎使用 |
|---|---|---|
| 复制 | * 压缩后存储小于 2 GB 的星型架构中的小型维度表(约 5 倍压缩) | * 表上有大量写入事务(例如:插入、更新插入、删除、更新) * 您频繁调整数据仓库单元(DWU)的配置 * 仅使用 2-3 列,但表包含许多列 * 为复制的表编制索引 |
| 轮循机制(默认) | * 临时表 * 没有明显的联接键或合适的候选列 |
* 由于数据移动,性能缓慢 |
| 哈希 | * 事实数据表 * 大型维度表 |
* 无法更新分发密钥 |
提示:
- 先使用轮循机制,但以哈希分布策略为最终目标,以便充分利用大规模并行体系结构。
- 确保通用哈希键具有相同的数据格式。
- 不要在 varchar 格式上分发。
- 可以将具有常见哈希键的维度表哈希分布到具有频繁联接操作的事实数据表。
- 使用 sys.dm_pdw_nodes_db_partition_stats 分析数据中的任何偏差。
- 使用 sys.dm_pdw_request_steps 分析查询背后的数据移动、监视时间广播以及随机选择操作需要。 这有助于审查您的分销策略。
为表编制索引
索引有助于快速读取表。 可以根据需求使用一组独特的技术:
| 类型 | 非常适合... | 注意以下情况... |
|---|---|---|
| 堆 | * 临时表 * 包含小规模查找的小型表 |
* 任何查找扫描全表 |
| 聚集索引 | * 最多包含 1 亿行的表 * 大型表(超过1亿行),仅大量使用1-2列 |
* 用于复制表 * 涉及多个联接和 Group By 操作的复杂查询 * 对索引列进行更新:它占用内存 |
| 聚集列存储索引 (CCI) (默认值) | * 大型表(超过 1 亿行) | * 用于复制表 * 对表进行大规模更新操作 * 对表进行过度分区:行组不会跨越不同的分布节点和分区 |
提示:
- 在聚集索引之外,你可能想要为一个经常用于筛选的列添加非聚集索引。
- 注意如何使用 CCI 管理表上的内存。 加载数据时,希望用户(或查询)受益于大型资源类。 确保避免剪裁和创建许多经过压缩的小型行组。
- 在 Gen2 上,CCI 表在本地缓存在计算节点上,以最大程度地提高性能。
- 对于 CCI,可能因行组压缩不当而出现性能下降的情况。 如果发生这种情况,请重建或重新组织您的 CCI。 你希望每个压缩后的行组包含至少 10 万行。 理想状态为一个行组 100 万行。
- 根据增量加载的频率和大小,您需要自动决定何时重新组织或重建索引。 春天的清洁总是有帮助的。
- 想要剪裁行组时应更具战略性。 打开的行组有多大? 预计在未来几天内加载多少数据?
详细了解索引。
分区
如果拥有大型事实数据表(超过 10 亿行),则可以对表进行分区。 在 99% 的情况下,分区键应基于日期。
对于需要 ELT 的临时表,可从分区中受益。 它有助于进行数据生命周期管理。 注意不要对事实或临时表过度分区,尤其是对聚集列存储索引。
详细了解 分区。
增量加载
如果要以增量方式加载数据,请先确保分配更大的资源类来加载数据。 当加载到具有聚集列存储索引的表中时,这一点尤其重要。 有关更多详细信息 ,请参阅资源类 。
建议使用 PolyBase 和 ADF V2 将 ELT 管道自动化到数据仓库。
对于历史数据中的大量更新,请考虑使用 CTAS 写入要保留在表中的数据,而不是使用 INSERT、UPDATE 和 DELETE。
维护统计信息
更新统计信息非常重要,因为数据发生了 重大 更改。 请参阅 更新统计信息 以确定是否发生了 重大 更改。 更新的统计信息优化了查询计划。 如果发现维护所有统计信息需要很长时间,请更选择性地选择哪些列具有统计信息。
还可以定义更新的频率。 例如,你可能想要更新每天可能会添加新值的日期列。 通过收集联接中涉及的列、WHERE 子句中使用的列,以及 GROUP BY 中出现的列的统计信息,可以获得最大的好处。
详细了解 统计信息。
资源类
资源组用作将内存分配给查询的方法。 如果需要更多内存来提高查询或加载速度,则应分配更高的资源类。 另一方面,使用更大的资源类别会影响并发性。 在将所有用户移动到大型资源类之前,需要考虑到这一点。
如果发现查询耗时太长,请检查用户是否未在大型资源类中运行。 大型资源类会占用许多并发槽。 它们可能导致其他查询排队等待。
最后,通过使用 专用 SQL 池(以前为 SQL DW)的 Gen2,每个资源类的内存比 Gen1 多 2.5 倍。
详细了解如何使用 资源类和并发。
降低成本
Azure Synapse 的主要功能是 能够管理计算资源。 如果不使用它,则可以暂停专用 SQL 池(以前为 SQL DW),这会停止计算资源的计费。 可以缩放资源以满足性能需求。 若要暂停,请使用 Azure 门户 或 PowerShell。 若要进行缩放,请使用 Azure 门户、 PowerShell、 T-SQL 或 REST API。
优化您的体系结构以提高性能
建议考虑在中心辐射型体系结构中使用 SQL 数据库和 Azure Analysis Services。 此解决方案可以在不同的用户组之间提供工作负荷隔离,同时使用 SQL 数据库和 Azure Analysis Services 中的高级安全功能。 这也是向用户提供无限并发的一种方法。
详细了解 利用 Azure Synapse Analytics 中的专用 SQL 池(以前为 SQL DW)的典型体系结构。