Azure Synapse Analytics 是一种分析服务,它将企业数据仓库和大数据分析结合在一起。 它使你可以自由地根据你的条件查询数据。
Synapse SQL 体系结构组件
专用 SQL 池(以前称为 SQL DW)利用横向扩展体系结构将数据的计算处理分布在多个节点上。 规模单位是一种对计算能力(称为数据仓库单位)的抽象。 计算与存储是分离的,这使您能够在系统中的数据不受影响的情况下独立扩展计算资源。
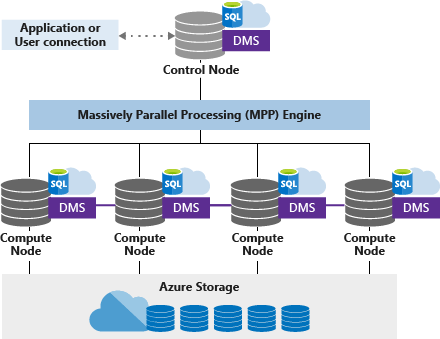
专用 SQL 池(以前称为 SQL DW)使用基于节点的体系结构。 应用程序连接到控制节点并将 T-SQL 命令发送到控制节点。 控制节点托管分布式查询引擎(用于优化并行处理查询),然后将操作传递给计算节点以完成并行工作。
计算节点将所有用户数据存储在 Azure 存储中并运行并行查询。 数据移动服务 (DMS) 是一项系统级内部服务,它根据需要在节点间移动数据以并行运行查询和返回准确的结果。
使用分离的存储和计算,用户可以在使用专用 SQL 池(以前称为 SQL DW)时执行以下操作:
- 无论存储需求如何,都可以独立调整计算能力的大小。
- 在专用 SQL 池(以前称为 SQL DW)中增加或减少计算能力,无需移动数据。
- 在保持数据不受影响的情况下暂停计算容量,因此只需为存储付费。
- 在工作时间恢复计算容量。
Azure 存储
专用 SQL 池 SQL(以前称为 SQL DW)利用 Azure 存储来保持用户数据安全。 由于数据通过 Azure 存储进行存储和管理,因此会对存储消耗单独收费。 将数据分片到“分布区”中来优化系统性能。 可选择在定义表时用于分布数据的分片模式。 支持以下分片模式:
- 哈希
- 轮循机制
- 复制
控制节点
控制节点是体系结构的核心。 它是与所有应用程序和连接进行交互的前端。 分布式查询引擎在控制节点上运行,可优化和协调并行查询。 提交 T-SQL 查询时,控制节点会将其转换为可针对每个分布区并行运行的查询。
计算节点
计算节点提供计算能力。 分布区映射到计算节点以进行处理。 当你为更多计算资源付费时,分布区将重新映射到可用的计算节点。 计算节点数的范围是 1 到 60,它由 Synapse SQL 的服务级别确定。
每个计算节点均有一个节点 ID,该 ID 会显示在系统视图中。 在名称以 sys.pdw_nodes 开头的系统视图中找到 node_id 列即可查看计算节点 ID。 有关这些系统视图的列表,请参阅 Synapse SQL 系统视图。
数据移动服务
数据移动服务 (DMS) 是一项数据传输技术,它可协调计算节点间的数据移动。 某些查询需要移动数据以确保并行查询返回准确的结果。 需要移动数据时,DMS 可确保正确的数据到达正确的位置。
分发
分布区是存储和处理针对分布式数据运行的并行查询的基本单位。 Synapse SQL 运行查询时,工作会被分割成 60 个并行运行的小型查询。
每个小型查询各在一个数据分布区上运行。 每个计算节点管理其中一个或多个分布区。 具有最多计算资源的专用 SQL 池(以前称为 SQL DW)的每个分布区占 1 个计算节点。 具有最小计算资源的专用 SQL 池(以前称为 SQL DW)的所有分布区都在 1 个计算节点上。
注释
有关基于工作负载使用的最佳表分发策略的建议,请参阅 Azure Synapse SQL 分发顾问。
哈希分布表
哈希分布表可为大型表上的联接和聚合提供最高查询性能。
为了将数据分片到哈希分布式表中,使用哈希函数明确将 1 个行分配到 1 个分布区。 在表定义中,可以将一个列指定为分布列。 哈希函数使用分布列中的值将 1 个行分配到 1 个分布区。
下图说明了如何将完整的非分布式表存储为哈希分布表。

- 一个行属于一个分布区。
- 通过确定性哈希算法将一个行分配到一个分布区。
- 不同大小的表格展示了每个分布区中表行数目的差异。
选择分布列时需考虑到性能,例如特异性、数据倾斜,以及在系统上运行的查询类型。
轮循分布表
轮循机制表是最简单的表,在被用作负载临时表时,它可创造和提供高速性能。
轮循机制分布表在表中均匀分布数据,但不会进行进一步优化。 首先随机选择一个分布区,然后将行的缓冲区按顺序分配给分布区。 将数据加载到循环表速度很快,但哈希分布式表的查询性能通常会更好。 联接循环表要求重新组织数据,因此这需要花费更多时间。
复制表
复制表为小型表提供最快查询性能。
复制表在每个计算节点上缓存表的完整副本。 因此复制表以后,无需在执行联接或聚合前在计算节点中间传输数据。 复制表尤为适用于小型表。 它需要额外存储并且在写入数据时会产生额外开销,因此不适用于大型表。
下图显示,副本表会缓存在每个计算节点的第一个分发区上。

相关内容
对 Azure Synapse 有了初步的认识后,请学习如何快速创建专用 SQL 池(以前称为 SQL DW)和加载示例数据。 如果不熟悉 Azure,遇到新术语时,Azure 词汇表 可以提供帮助。 或者,查看以下一些其他 Azure Synapse 资源。