适用于:Azure Synapse Analytics 专用 SQL 池
当用户查询专用 SQL 池中的列存储表时,优化器会检查每个段中存储的最小值和最大值。 超出查询谓词边界的段不会从磁盘读取到内存。 如果要读取的段的数目及其总大小较小,查询就可以更快地完成。
注意
本文适用于 Azure Synapse Analytics 专用 SQL 池。 有关 SQL Server 和其他 SQL 平台中有序列存储索引的信息,请参阅使用有序聚集列存储索引优化性能。
有序与无序聚集列存储索引
默认情况下,对于不是使用索引选项创建的每个表,某个内部组件(索引生成器)将在该表中创建无序的聚集列存储索引 (CCI)。 每个列中的数据压缩成单独的 CCI 行组段。 每个段的值范围都有元数据,因此,在执行查询期间,不会从磁盘中读取超出查询谓词边界的段。 CCI 提供最高级别的数据压缩,可减少要读取的段大小,因此查询可以更快地运行。 但是,由于索引生成器在将数据压缩成段之前不会将数据排序,因此可能会出现值范围重叠的段,从而导致查询从磁盘中读取更多的段,需要更长的时间才能完成。
通过启用高效的段消除,有序聚集列存储索引能够跳过大量与查询谓词不匹配的有序数据,从而显著提高性能。 创建有序 CCI 时,专用 SQL 池引擎会先按顺序键将内存中的现有数据排序,然后,索引生成器会将这些数据压缩成索引段。 使用有序数据可以减少段重叠的情况,使查询更有效地消除段,因而可提高性能,因为要从磁盘读取的段数更少。 如果可以一次性在内存中为所有数据排序,则可以避免段重叠的情况。 由于数据仓库中的表较大,因此这种情况不经常发生。
若要检查列的段范围,请使用表名称和列名称在命令行中运行以下命令:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
注意
在有序 CCI 表中,同一批 DML 或数据加载操作生成的新数据将在该批中排序,而表中的所有数据不会经过全局排序。 用户可以重建有序的 CCI,以对表中的所有数据进行排序。 在专用 SQL 池中,列存储索引重新生成是一项脱机操作。 对于已分区表,每次将对一个分区执行 REBUILD。 重新生成的分区中的数据是“脱机”的,在对该分区完成重新生成之前,这些数据不可用。
查询性能
有序 CCI 带来的查询性能提升程度取决于查询模式、数据大小、数据排序的合理性、段的物理结构,以及为查询执行选择的 DWU 和资源类。 在设计有序 CCI 表时,用户应在选择排序列之前考虑所有这些因素。
具有所有这些模式的查询在使用有序 CCI 时运行速度往往更快。
- 查询具有相等性、不相等性或范围谓词
- 谓词列和有序 CCI 列相同。
在此示例中,表 T1 具有一个已按 Col_C、Col_B 和 Col_A 顺序排序的聚集列存储索引。
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
由于查询 1 和查询 2 引用所有有序 CCI 列,因此相比其他查询,这两种查询的性能更适用于有序 CCI。
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
数据加载性能
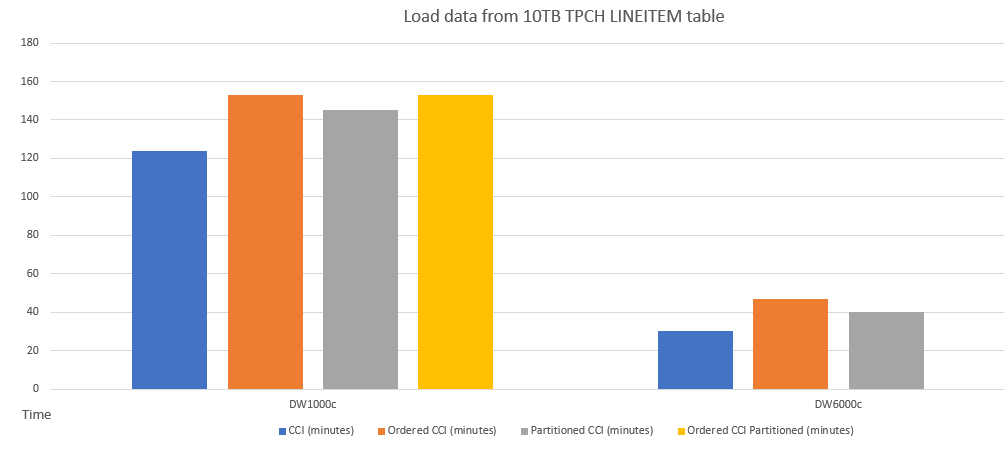
将数据载入有序 CCI 表中的性能类似于将数据载入已分区的表。 由于需要执行数据排序操作,将数据载入有序 CCI 表所需的时间可能比载入无序 CCI 表更长,但之后,查询可以使用有序 CCI 更快地运行。
以下示例将数据载入采用不同架构的表的性能做了比较。
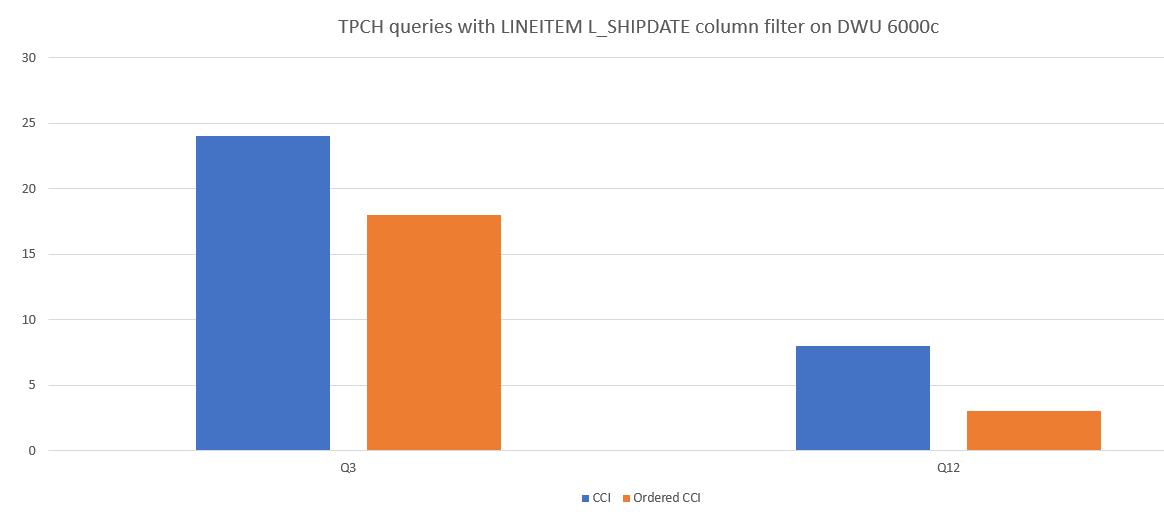
以下示例对使用 CCI 和有序 CCI 的查询性能进行了比较。
减少段重叠
重叠段的数目取决于要排序的数据的大小、可用内存,以及创建有序 CCI 期间的最大并行度 (MAXDOP) 设置。 在创建有序 CCI 时,以下策略可以减少段重叠。
在更高的 DWU 上使用
xlargerc资源类,以便在索引生成器将数据压缩成段之前,有更多的内存可用于数据排序。 进入索引段后,数据的物理位置不可更改。 段内部或者段之间不会发生数据排序。使用
OPTION (MAXDOP = 1)创建有序 CCI。 用于创建有序 CCI 的每个线程针对一部分数据运行,并在本地为数据排序。 已由不同线程排序的数据不会经过全局排序。 使用并行线程可以减少创建有序 CCI 所需的时间,但生成的重叠段比使用单个线程时更多。 使用单线程操作可以提供最高的压缩质量。 例如:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
注意
目前,在 Azure Synapse Analytics 的专用 SQL 池中,MAXDOP 选项仅在使用 CREATE TABLE AS SELECT 命令创建有序 CCI 表时受支持。 通过 CREATE INDEX 或 CREATE TABLE 命令创建有序 CCI 时不支持 MAXDOP 选项。 此限制不适用于 SQL Server 2022 和更高版本,在其中可为 CREATE INDEX 或 CREATE TABLE 命令指定 MAXDOP。
- 将数据载入表之前,预先按排序键将数据排序。
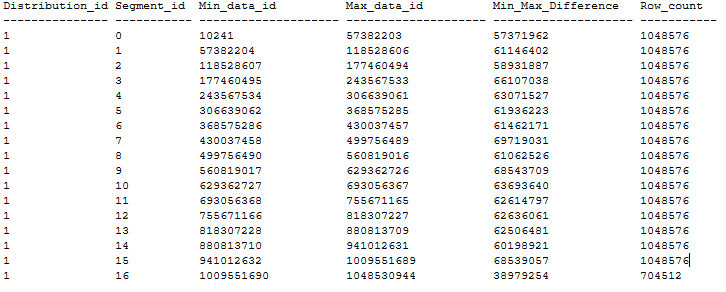
下面是有序 CCI 表分布示例,该表根据上述建议清除了段重叠情况。 该有序 CCI 表是使用 MAXDOP 1 和 ,基于 20-GB 的堆表通过 xlargerc 在 DWU1000c 数据库中创建的。 CCI 已按照不包含重复项的 BIGINT 列进行排序。
在大型表中创建有序 CCI
创建有序 CCI 是一项脱机操作。 对于不包含分区的表,在有序 CCI 创建过程完成之前,用户无法访问数据。 对于已分区的表,由于引擎将按分区创建有序的 CCI 分区,因此,在尚未进行有序 CCI 创建操作的情况下,用户仍可以访问分区中的数据。 在大型表中创建有序 CCI 的过程中,可以使用此选项来尽量减少故障时间:
- 在目标大型表(名为
Table_A)中创建分区。 - 使用与
Table_B相同的表架构和分区架构创建空的有序 CCI 表(名为Table_A)。 - 将一个分区从
Table_A切换到Table_B。 - 运行
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>,在Table_B上重新生成已换入的分区。 - 对
Table_A中的每个分区重复步骤 3 和 4。 - 将所有分区都从
Table_A切换到Table_B并重新生成之后,删除Table_A,并将Table_B重命名为Table_A。
提示
对于具有有序 CCI 的专用 SQL 池表,ALTER INDEX REBUILD 将使用 tempdb 对数据进行重新排序。 在重新生成操作期间监视 tempdb。 如果需要更多 tempdb 空间,请纵向扩展该池。 完成索引重新生成之后,缩小为原空间大小。
对于具有有序 CCI 的专用 SQL 池表,ALTER INDEX REORGANIZE 不对数据进行重新排序。 若要重新排序数据,请使用 ALTER INDEX REBUILD。
有关有序 CCI 维护的详细信息,请参阅优化聚集列存储索引。
SQL Server 2022 功能差异
SQL Server 2022 (16.x) 引入了与 Azure Synapse 专用 SQL 池中的功能类似的有序聚集列存储索引。
- 目前,只有 SQL Server 2022 (16.x) 及更高版本针对字符串、二进制和 GUID 数据类型以及刻度大于 2 的 datetimeoffset 数据类型支持聚集列存储增强段消除功能。 以前,这种段消除适用于数值、日期和时间数据类型,以及精度小于或等于 2 的 datetimeoffset 数据类型。
- 目前,只有 SQL Server 2022 (16.x) 及更高版本针对
LIKE谓词的前缀(例如column LIKE 'string%')支持聚集列存储行组消除。 对于 LIKE 操作符的非前缀用法(例如column LIKE '%string'),不支持分段消除。
有关详细信息,请参阅列存储索引中的新增功能。
示例
A. 检查有序列和序号:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. 若要更改列序号,请在顺序列表中添加或删除列,或者从 CCI 更改为有序 CCI:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
后续步骤
- 有关更多开发技巧,请参阅 开发概述。
- 列存储索引:概述
- 列存储索引的新增功能
- 列存储索引 - 设计指南
- 列存储索引 - 查询性能