Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article provides best practices for cluster reliability implemented both at a deployment and cluster level for your Azure Kubernetes Service (AKS) workloads. The article is intended for cluster operators and developers who are responsible for deploying and managing applications in AKS.
The best practices in this article are organized into the following categories:
Deployment level best practices
The following deployment level best practices help ensure high availability and reliability for your AKS workloads. These best practices are local configurations that you can implement in the YAML files for your pods and deployments.
Note
Make sure you implement these best practices every time you deploy an update to your application. If not, you might experience issues with your application's availability and reliability, such as unintentional application downtime.
Pod CPU and memory limits
Best practice guidance
Set pod CPU and memory limits for all pods to ensure that pods don't consume all resources on a node and to provide protection during service threats, such as DDoS attacks.
Pod CPU and memory limits define the maximum amount of CPU and memory a pod can use. When a pod exceeds its defined limits, it gets marked for removal. For more information, see CPU resource units in Kubernetes and Memory resource units in Kubernetes.
Setting CPU and memory limits helps you maintain node health and minimizes impact to other pods on the node. Avoid setting a pod limit higher than your nodes can support. Each AKS node reserves a set amount of CPU and memory for the core Kubernetes components. If you set a pod limit higher than the node can support, your application might try to consume too many resources and negatively impact other pods on the node. Cluster administrators need to set resource quotas on a namespace that requires setting resource requests and limits. For more information, see Enforce resource quotas in AKS.
In the following example pod definition file, the resources section sets the CPU and memory limits for the pod:
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: mypod
image: mcr.azk8s.cn/oss/nginx/nginx:1.15.5-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
Tip
You can use the kubectl describe node command to view the CPU and memory capacity of your nodes, as shown in the following example:
kubectl describe node <node-name>
# Example output
Capacity:
cpu: 8
ephemeral-storage: 129886128Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32863116Ki
pods: 110
Allocatable:
cpu: 7820m
ephemeral-storage: 119703055367
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28362636Ki
pods: 110
For more information, see Assign CPU Resources to Containers and Pods and Assign Memory Resources to Containers and Pods.
Vertical Pod Autoscaler (VPA)
Best practice guidance
Use Vertical Pod Autoscaler (VPA) to automatically adjust CPU and memory requests for your pods based on their actual usage.
While not directly implemented through the pod YAML, the Vertical Pod Autoscaler (VPA) helps optimize resource allocation by automatically adjusting the CPU and memory requests for your pods. This ensures that your applications have the resources they need to run efficiently without overprovisioning or underprovisioning.
VPA operates in three modes:
- Off: Only provides recommendations without applying changes.
- Auto: Automatically updates pod resource requests during pod restarts.
- Initial: Sets resource requests only during pod creation.
The following example shows how to configure a VPA resource in Kubernetes:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-deployment
updatePolicy:
updateMode: "Auto" # Options: Off, Auto, Initial
For more information, see Vertical Pod Autoscaler documentation.
Pod Disruption Budgets (PDBs)
Best practice guidance
Use Pod Disruption Budgets (PDBs) to ensure that a minimum number of pods remain available during voluntary disruptions, such as upgrade operations or accidental pod deletions.
Pod Disruption Budgets (PDBs) allow you to define how deployments or replica sets respond during voluntary disruptions, such as upgrade operations or accidental pod deletions. Using PDBs, you can define a minimum or maximum unavailable resource count. PDBs only affect the Eviction API for voluntary disruptions.
For example, let's say you need to perform a cluster upgrade and already have a PDB defined. Before performing the cluster upgrade, the Kubernetes scheduler ensures that the minimum number of pods defined in the PDB are available. If the upgrade would cause the number of available pods to fall below the minimum defined in the PDBs, the scheduler schedules extra pods on other nodes before allowing the upgrade to proceed. If you don't set a PDB, the scheduler doesn't have any constraints on the number of pods that can be unavailable during the upgrade, which can lead to a lack of resources and potential cluster outages.
In the following example PDB definition file, the minAvailable field sets the minimum number of pods that must remain available during voluntary disruptions. The value can be an absolute number (for example, 3) or a percentage of the desired number of pods (for example, 10%).
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: mypdb
spec:
minAvailable: 3 # Minimum number of pods that must remain available during voluntary disruptions
selector:
matchLabels:
app: myapp
For more information, see Plan for availability using PDBs and Specifying a Disruption Budget for your Application.
Graceful termination for pods
Best practice guidance
Utilize
PreStophooks and configure an appropriateterminationGracePeriodSecondsvalue to ensure pods are terminated gracefully.
Graceful termination ensures that pods are given enough time to clean up resources, complete ongoing tasks, or notify dependent services before being terminated. This is particularly important for stateful applications or services that require proper shutdown procedures.
Using PreStop hooks
A PreStop hook is called immediately before a container is terminated due to an API request or management event, such as preemption, resource contention, or a liveness/startup probe failure. The PreStop hook allows you to define custom commands or scripts to execute before the container is stopped. For example, you can use it to flush logs, close database connections, or notify other services of the shutdown.
The following example pod definition file shows how to use a PreStop hook to ensure graceful termination of a container:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "nginx -s quit; while killall -0 nginx; do sleep 1; done"]
Configuring terminationGracePeriodSeconds
The terminationGracePeriodSeconds field specifies the amount of time Kubernetes waits before forcefully terminating a pod. This period includes the time taken to execute the PreStop hook. If the PreStop hook doesn't complete within the grace period, the pod is forcefully terminated.
For example, the following pod definition sets a termination grace period of 30 seconds:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
terminationGracePeriodSeconds: 30
containers:
- name: example-container
image: nginx
For more information, see Container lifecycle hooks and Termination of Pods.
High availability during upgrades
Using maxSurge for faster updates
Best practice guidance
Configure the
maxSurgefield to allow additional pods to be created during rolling updates, enabling faster updates with minimal downtime.
The maxSurge field specifies the maximum number of additional pods that can be created beyond the desired number of pods during a rolling update. This allows new pods to be created and become ready before old pods are terminated, ensuring faster updates and reducing the risk of downtime.
The following example deployment manifest demonstrates how to configure maxSurge:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 33% # Maximum number of additional pods created during the update
By setting maxSurge to 3, this configuration ensures that up to three additional pods can be created during the rolling update, speeding up the deployment process while maintaining availability of your application.
For more information, see Rolling Updates in Kubernetes.
Using maxUnavailable for controlled updates
Best practice guidance
Configure the
maxUnavailablefield to limit the number of pods that can be unavailable during rolling updates, ensuring your application remains operational with minimal disruption.
The maxUnavailable field is particularly useful for applications that require are compute intensive or have specific infrastructure needs. It specifies the maximum number of pods that can be unavailable at any given time during a rolling update. This ensures that a portion of your application remains functional while new pods are being deployed and old ones are terminated.
You can set maxUnavailable as an absolute number (e.g., 1) or a percentage of the desired number of pods (e.g., 25%). For example, if your application has four replicas and you set maxUnavailable to 1, Kubernetes ensures that at least three pods remain available during the update process.
The following example deployment manifest demonstrates how to configure maxUnavailable:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 4
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # Maximum number of pods that can be unavailable during the update
In this example, setting maxUnavailable to 1 ensures that no more than one pod is unavailable at any given time during the rolling update. This configuration is ideal for applications which require specialized compute, where maintaining a minimum level of service availability is critical.
For more information, see Rolling Updates in Kubernetes.
Pod topology spread constraints
Best practice guidance
Use pod topology spread constraints to ensure that pods are spread across different nodes or zones to improve availability and reliability.
You can use pod topology spread constraints to control how pods are spread across your cluster based on the topology of the nodes and spread pods across different nodes or zones to improve availability and reliability.
The following example pod definition file shows how to use the topologySpreadConstraints field to spread pods across different nodes:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional
nodeAffinityPolicy: [Honor|Ignore] # optional
nodeTaintsPolicy: [Honor|Ignore] # optional
For more information, see Pod Topology Spread Constraints.
Readiness, liveness, and startup probes
Best practice guidance
Configure readiness, liveness, and startup probes when applicable to improve resiliency for high loads and lower container restarts.
Readiness probes
In Kubernetes, the kubelet uses readiness probes to know when a container is ready to start accepting traffic. A pod is considered ready when all of its containers are ready. When a pod is not ready, it's removed from service load balancers. For more information, see Readiness Probes in Kubernetes.
The following example pod definition file shows a readiness probe configuration:
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
For more information, see Configure readiness probes.
Liveness probes
In Kubernetes, the kubelet uses liveness probes to know when to restart a container. If a container fails its liveness probe, the container is restarted. For more information, see Liveness Probes in Kubernetes.
The following example pod definition file shows a liveness probe configuration:
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
Another kind of liveness probe uses an HTTP GET request. The following example pod definition file shows an HTTP GET request liveness probe configuration:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
For more information, see Configure liveness probes and Define a liveness HTTP request.
Startup probes
In Kubernetes, the kubelet uses startup probes to know when a container application has started. When you configure a startup probe, readiness and liveness probes don't start until the startup probe succeeds, ensuring the readiness and liveness probes don't interfere with application startup. For more information, see Startup Probes in Kubernetes.
The following example pod definition file shows a startup probe configuration:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
Multi-replica applications
Best practice guidance
Deploy at least two replicas of your application to ensure high availability and resiliency in node-down scenarios.
In Kubernetes, you can use the replicas field in your deployment to specify the number of pods you want to run. Running multiple instances of your application helps ensure high availability and resiliency in node-down scenarios. If you have availability zones enabled, you can use the replicas field to specify the number of pods you want to run across multiple availability zones.
The following example pod definition file shows how to use the replicas field to specify the number of pods you want to run:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
For more information, see Recommended active-active high availability solution overview for AKS and Replicas in Deployment Specs.
Cluster and node pool level best practices
The following cluster and node pool level best practices help ensure high availability and reliability for your AKS clusters. You can implement these best practices when creating or updating your AKS clusters.
Availability zones
Best practice guidance
Use multiple availability zones when creating an AKS cluster to ensure high availability in zone-down scenarios. Keep in mind that you can't change the availability zone configuration after creating the cluster.
Availability zones are separated groups of datacenters within a region. These zones are close enough to have low-latency connections to each other, but far enough apart to reduce the likelihood that more than one zone is affected by local outages or weather. Using availability zones helps your data stay synchronized and accessible in zone-down scenarios. For more information, see Running in multiple zones.
Cluster autoscaling
Best practice guidance
Use cluster autoscaling to ensure that your cluster can handle increased load and to reduce costs during low load.
To keep up with application demands in AKS, you might need to adjust the number of nodes that run your workloads. The cluster autoscaler component watches for pods in your cluster that can't be scheduled because of resource constraints. When the cluster autoscaler detects issues, it scales up the number of nodes in the node pool to meet the application demand. It also regularly checks nodes for a lack of running pods and scales down the number of nodes as needed. For more information, see Cluster autoscaling in AKS.
For AKS Standard, you can use the --enable-cluster-autoscaler parameter when creating a cluster:
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \
--vm-set-type VirtualMachineScaleSets \
--load-balancer-sku standard \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 3 \
--generate-ssh-keys
You can also enable the cluster autoscaler on an existing node pool and configure more granular details of the cluster autoscaler by changing the default values in the cluster-wide autoscaler profile.
For more information, see Use the cluster autoscaler in AKS.
Ingress and egress reliability
Best practice guidance
Use the cluster networking model that matches your AKS cluster mode and reliability requirements.
For AKS Standard, Standard Load Balancer remains a common and recommended reliability choice for inbound and outbound traffic scenarios.
If you're using AKS Standard, the following Standard Load Balancer guidance still applies:
Standard Load Balancer
Best practice guidance
Use the Standard Load Balancer to provide greater reliability and resources, support for multiple availability zones, HTTP probes, and functionality across multiple data centers.
In Azure, the Standard Load Balancer SKU is designed to be equipped for load balancing network layer traffic when high performance and low latency are needed. The Standard Load Balancer routes traffic within and across regions and to availability zones for high resiliency. The Standard SKU is the recommended and default SKU to use when creating an AKS cluster.
Important
Starting on September 30, 2025, Azure Kubernetes Service (AKS) no longer supports Basic Load Balancer. To avoid any potential service disruptions, we recommend using Standard Load Balancer for new deployments and upgrading any existing deployments to the Standard Load Balancer. For more information on this retirement, see the Retirement GitHub issue and the Azure Updates retirement announcement. To stay informed on announcements and updates, follow the AKS release notes.
The following example shows a LoadBalancer service manifest that uses the Standard Load Balancer:
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-ipv4 # Service annotation for an IPv4 address
name: azure-load-balancer
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: azure-load-balancer
For more information, see Use a standard load balancer in AKS.
Tip
You can also use an ingress controller or a service mesh to manage network traffic, with each option providing different features and capabilities.
System node pools
Use dedicated system node pools
Best practice guidance
Use system node pools to ensure no other user applications run on the same nodes, which can cause resource scarcity and impact system pods.
Use dedicated system node pools to ensure no other user application runs on the same nodes, which can cause scarcity of resources and potential cluster outages because of race conditions. To use a dedicated system node pool, you can use the CriticalAddonsOnly taint on the system node pool. For more information, see Use system node pools in AKS.
Autoscaling for system node pools
Best practice guidance
Configure the autoscaler for system node pools to set minimum and maximum scale limits for the node pool.
Use the autoscaler on node pools to configure the minimum and maximum scale limits for the node pool. The system node pool should always be able to scale to meet the demands of system pods. If the system node pool is unable to scale, the cluster runs out of resources to help manage scheduling, scaling, and load balancing, which can lead to an unresponsive cluster.
For more information, see Use the cluster autoscaler on node pools.
At least two nodes per system node pool
Best practice guidance
Ensure that system node pools have at least two nodes to ensure resiliency against freeze/upgrade scenarios, which can lead to nodes being restarted or shut down.
In AKS Standard, system node pools should have at least two nodes to improve resilience during restart or upgrade events.
System node pools are used to run system pods, such as the kube-proxy, coredns, and the Azure CNI plugin. We recommend that you ensure that system node pools have at least two nodes to ensure resiliency against freeze/upgrade scenarios, which can lead to nodes being restarted or shut down. For more information, see Manage system node pools in AKS.
Upgrade configurations for node pools
- AKS Standard: Operators explicitly configure upgrade channels and node pool settings such as maxSurge and maxUnavailable.
Using maxSurge for node pool upgrades
Best practice guidance
Configure the
maxSurgesetting for node pool upgrades to improve reliability and minimize downtime during upgrade operations.
The maxSurge setting specifies the maximum number of additional nodes that can be created during an upgrade. This ensures that new nodes are provisioned and ready before old nodes are drained and removed, reducing the risk of application downtime.
For example, the following Azure CLI command sets maxSurge to 1 for a node pool:
az aks nodepool update \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name myNodePool \
--max-surge 1
By configuring maxSurge, you can ensure that upgrades are performed faster while maintaining application availability.
For more information, see Upgrade node pools in AKS.
Using maxUnavailable for node pool upgrades
Best practice guidance
Configure the
maxUnavailablesetting for node pool upgrades to ensure application availability during upgrade operations.
The maxUnavailable setting specifies the maximum number of nodes that can be unavailable during an upgrade. This ensures that a portion of your node pool remains operational while nodes are being upgraded.
For example, the following Azure CLI command sets maxUnavailable to 1 for a node pool:
az aks nodepool update \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name myNodePool \
--max-unavailable 1
By configuring maxUnavailable, you can control the impact of upgrades on your workloads, ensuring that sufficient resources remain available during the process.
For more information, see Upgrade node pools in AKS.
Accelerated Networking
Best practice guidance
Use Accelerated Networking to provide lower latency, reduced jitter, and decreased CPU utilization on your VMs.
Accelerated Networking enables single root I/O virtualization (SR-IOV) on supported VM types, greatly improving networking performance.
The following diagram illustrates how two VMs communicate with and without Accelerated Networking:
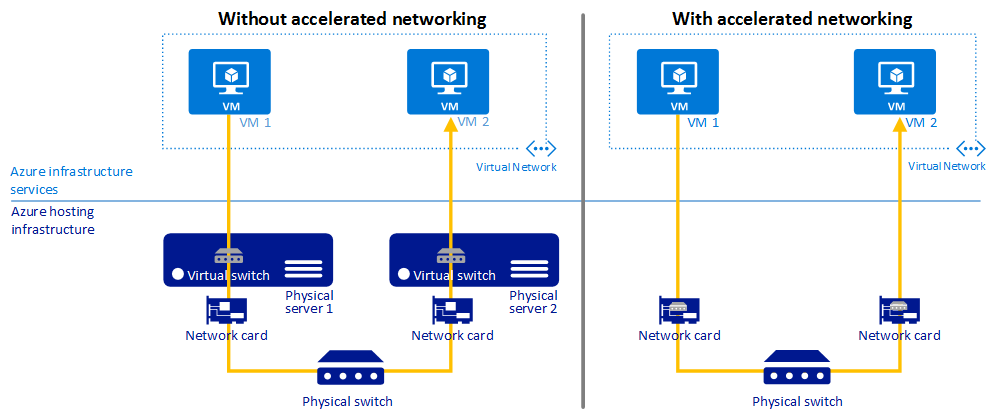
For more information, see Accelerated Networking overview.
Image versions
Best practice guidance
Images shouldn't use the
latesttag.
Container image tags
Using the latest tag for container images can lead to unpredictable behavior and makes it difficult to track which version of the image is running in your cluster. You can minimize these risks by integrating and running scan and remediation tools in your containers at build and runtime. For more information, see Best practices for container image management in AKS.
Node image upgrades
AKS provides multiple auto-upgrade channels for node OS image upgrades. You can use these channels to control the timing of upgrades. We recommend joining these auto-upgrade channels to ensure that your nodes are running the latest security patches and updates. For more information, see Auto-upgrade node OS images in AKS.
Standard pricing tier for production workloads
Best practice guidance
Use the Standard pricing tier for product workloads for greater cluster reliability and resources, support for up to 5,000 nodes in a cluster, and Uptime SLA enabled by default. If you need LTS, consider using the Premium tier.
The Standard tier for Azure Kubernetes Service (AKS) provides a financially backed 99.9% uptime service-level agreement (SLA) for your production workloads. The standard tier also provides greater cluster reliability and resources, support for up to 5,000 nodes in a cluster, and Uptime SLA enabled by default. For more information, see Pricing tiers for AKS cluster management.
LocalDNS for DNS reliability
Best practice guidance
Enable LocalDNS on your node pools to improve DNS resolution reliability and maintain service connectivity during transient DNS outages.
LocalDNS deploys a DNS proxy on each AKS node, providing low-latency, resilient DNS resolution. By resolving queries locally, LocalDNS reduces your dependence on centralized CoreDNS pods and avoids conntrack table exhaustion, which is a common cause of dropped DNS queries in high-throughput environments. LocalDNS also supports serving stale cached responses for a configurable duration when upstream DNS is unavailable, helping maintain pod connectivity during disruptions. For configuration instructions and best practices, see Configure LocalDNS in AKS.
Azure CNI for dynamic IP allocation
Best practice guidance
Configure Azure CNI for dynamic IP allocation for better IP utilization and to prevent IP exhaustion for AKS clusters.
For AKS Standard, Azure CNI dynamic IP allocation helps improve IP utilization and prevent IP exhaustion.
The dynamic IP allocation capability in Azure CNI allocates pod IPs from a subnet separate from the subnet hosting the AKS cluster and offers the following benefits:
- Better IP utilization: IPs are dynamically allocated to cluster Pods from the Pod subnet. This leads to better utilization of IPs in the cluster compared to the traditional CNI solution, which does static allocation of IPs for every node.
- Scalable and flexible: Node and pod subnets can be scaled independently. A single pod subnet can be shared across multiple node pools of a cluster or across multiple AKS clusters deployed in the same VNet. You can also configure a separate pod subnet for a node pool.
- High performance: Since pod are assigned virtual network IPs, they have direct connectivity to other cluster pod and resources in the VNet. The solution supports very large clusters without any degradation in performance.
- Separate VNet policies for pods: Since pods have a separate subnet, you can configure separate VNet policies for them that are different from node policies. This enables many useful scenarios such as allowing internet connectivity only for pods and not for nodes, fixing the source IP for pod in a node pool using an Azure NAT Gateway, and using NSGs to filter traffic between node pools.
- Kubernetes network policies: Both the Azure Network Policies and Calico work with this solution.
For more information, see Configure Azure CNI networking for dynamic allocation of IPs and enhanced subnet support.
v5 SKU VMs
Best practice guidance
Use v5 VM SKUs for improved performance during and after updates, less overall impact, and a more reliable connection for your applications.
For node pools in AKS, use v5 SKU VMs with ephemeral OS disks to provide sufficient compute resources for kube-system pods. For more information, see Best practices for performance and scaling large workloads in AKS.
Do not use B series VMs
Best practice guidance
Don't use B series VMs for AKS clusters because they're low performance and don't work well with AKS.
B series VMs are low performance and don't work well with AKS. Instead, we recommend using v5 SKU VMs.
Premium Disks
Best practice guidance
Use Premium Disks to achieve 99.9% availability in one virtual machine (VM).
Azure Premium Disks offer a consistent submillisecond disk latency and high IOPS and throughout. Premium Disks are designed to provide low-latency, high-performance, and consistent disk performance for VMs.
The following example YAML manifest shows a storage class definition for a premium disk:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: premium2-disk-sc
parameters:
cachingMode: None
skuName: PremiumV2_LRS
DiskIOPSReadWrite: "4000"
DiskMBpsReadWrite: "1000"
provisioner: disk.csi.azure.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
For more information, see Use Azure Premium SSD v2 disks on AKS.
Container Insights
Best practice guidance
Enable Container Insights to monitor and diagnose the performance of your containerized applications.
Container Insights is a feature of Azure Monitor that collects and analyzes container logs from AKS. You can analyze the collected data with a collection of views and prebuilt workbooks.
You can enable Container Insights monitoring on your AKS cluster using various methods. The following example shows how to enable Container Insights monitoring on an existing AKS Standard cluster using the Azure CLI:
az aks enable-addons -a monitoring --name myAKSCluster --resource-group myResourceGroup
For more information, see Enable monitoring for Kubernetes clusters.
Azure Policy
Best practice guidance
Apply and enforce security and compliance requirements for your AKS clusters using Azure Policy.
You can apply and enforce built-in security policies on your AKS clusters using Azure Policy. Azure Policy helps enforce organizational standards and assess compliance at-scale. After you install the Azure Policy add-on for AKS, you can apply individual policy definitions or groups of policy definitions called initiatives to your clusters.
For more information, see Secure your AKS clusters with Azure Policy.
Related content
This article focused on best practices for deployment and cluster reliability for Azure Kubernetes Service (AKS) clusters. For more information on related topics, see the following articles: