Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
This article provides guidance for upgrading connectors in Azure Data Factory.
How to receive notifications in Azure Service Health portal
Regular notifications are sent to you to help you upgrade related connectors or notify you the key dates for EOS and removal. You can find the notification under Service Health portal - Health advisories tab.
Here's the steps to help you find the notification:
Navigate to Service Health portal or you can select Service Health icon on your Azure portal dashboard.
Go to Health advisories tab and you can see the notification related to your connectors in the list. You can also go to Health history tab to check historical notifications.
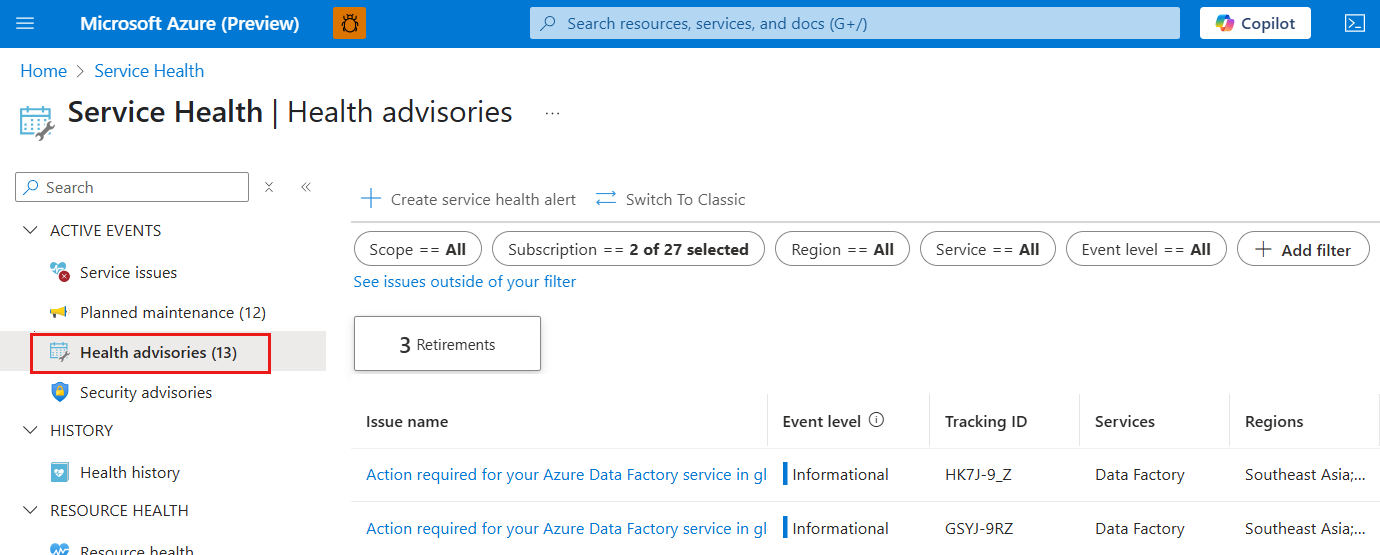
To learn more about the Service Health portal, see this the Azure Service Health overview.
How to find your impacted objects from data factory portal
Here's the steps to get your objects which still rely on the deprecated connectors or connectors that have a precise end of support date. It is recommended to take action to upgrade those objects to the new connector version before the end of the support date.
- Open your Azure Data Factory.
- Go to Manage - Linked services page.
- You should see the Linked Service that is still on V1 with an alert behind it.
- Click on the number under the 'Related' column will show you the related objects that utilize this Linked service.
- To learn more about the upgrade guidance and the comparison between V1 and V2, you can navigate to the connector upgrade section within each connector page.

How to find your impacted objects programmatically
Users can run a PowerShell script to programmatically extract a list of Azure Data Factory or Synapse linked services that are using integration runtimes running on versions that are either out of support or nearing end-of-support. The script can be customized to query each data factory under a specified tenant or subscription, enumerate a list of specified linked services, and inspect configuration properties such as connection types, connector versions. It can then cross-reference these details against known version EOS timelines, flagging any linked services using unsupported or soon-to-be unsupported connector versions. This automated approach enables users to proactively identify and remediate outdated components to ensure continued support, security compliance, and service availability.
You can find examples of the script and customize it as needed:
- Script to list all linked services within the specified subscription ID
- Script to list all linked services within the specified tenant ID