Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In this article, you do the following steps.
Run a custom script to install Microsoft Cognitive Toolkit on an Azure HDInsight Spark cluster.
Upload a Jupyter Notebook to the Apache Spark cluster to see how to apply a trained Microsoft Cognitive Toolkit deep learning model to files in an Azure Blob Storage Account using the Spark Python API (PySpark)
Prerequisites
An Apache Spark cluster on HDInsight. See Create an Apache Spark cluster.
Familiarity with using Jupyter Notebooks with Spark on HDInsight. For more information, see Load data and run queries with Apache Spark on HDInsight.
How does this solution flow?
This solution is divided between this article and a Jupyter Notebook that you upload as part of this article. In this article, you complete the following steps:
- Run a script action on an HDInsight Spark cluster to install Azure Cognitive Toolkit and Python packages.
- Upload the Jupyter Notebook that runs the solution to the HDInsight Spark cluster.
The following remaining steps are covered in the Jupyter Notebook.
- Load sample images into a Spark Resilient Distributed Dataset or RDD.
- Load modules and define presets.
- Download the dataset locally on the Spark cluster.
- Convert the dataset into an RDD.
- Score the images using a trained Cognitive Toolkit model.
- Download the trained Cognitive Toolkit model to the Spark cluster.
- Define functions to be used by worker nodes.
- Score the images on worker nodes.
- Evaluate model accuracy.
Install Azure Cognitive Toolkit
You can install Azure Cognitive Toolkit on a Spark cluster using script action. Script action uses custom scripts to install components on the cluster that aren't available by default. You can use the custom script from the Azure portal, by using HDInsight .NET SDK, or by using Azure PowerShell. You can also use the script to install the toolkit either as part of cluster creation, or after the cluster is up and running.
In this article, we use the portal to install the toolkit, after the cluster has been created. For other ways to run the custom script, see Customize HDInsight clusters using Script Action.
Using the Azure portal
For instructions on how to use the Azure portal to run script action, see Customize HDInsight clusters using Script Action. Make sure you provide the following inputs to install Azure Cognitive Toolkit. Use the following values for your script action:
| Property | Value |
|---|---|
| Script type | - Custom |
| Name | Install MCT |
| Bash script URI | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| Node type(s): | Head, Worker |
| Parameters | None |
Upload the Jupyter Notebook to Azure HDInsight Spark cluster
To use the Azure Cognitive Toolkit with the Azure HDInsight Spark cluster, you must load the Jupyter Notebook CNTK_model_scoring_on_Spark_walkthrough.ipynb to the Azure HDInsight Spark cluster. This notebook is available on GitHub at https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
Download and unzip https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration.
From a web browser, navigate to
https://CLUSTERNAME.azurehdinsight.cn/jupyter, whereCLUSTERNAMEis the name of your cluster.From the Jupyter Notebook, select Upload in the top-right corner and then navigate to the download and select file
CNTK_model_scoring_on_Spark_walkthrough.ipynb.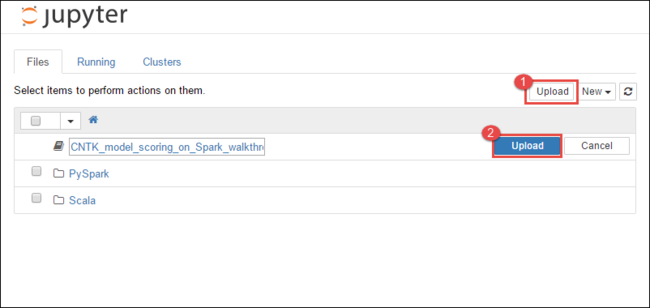
Select Upload again.
After the notebook is uploaded, click the name of the notebook and then follow the instructions in the notebook itself on how to load the data set and perform the article.
See also
Scenarios
- Apache Spark with BI: Perform interactive data analysis using Spark in HDInsight with BI tools
- Apache Spark with Machine Learning: Use Spark in HDInsight for analyzing building temperature using HVAC data
- Apache Spark with Machine Learning: Use Spark in HDInsight to predict food inspection results
- Website log analysis using Apache Spark in HDInsight
- Application Insight telemetry data analysis using Apache Spark in HDInsight
Create and run applications
- Create a standalone application using Scala
- Run jobs remotely on an Apache Spark cluster using Apache Livy
Tools and extensions
- Use HDInsight Tools Plugin for IntelliJ IDEA to create and submit Spark Scala applications
- Use HDInsight Tools Plugin for IntelliJ IDEA to debug Apache Spark applications remotely
- Use Apache Zeppelin notebooks with an Apache Spark cluster on HDInsight
- Kernels available for Jupyter Notebook in Apache Spark cluster for HDInsight
- Use external packages with Jupyter Notebooks
- Install Jupyter on your computer and connect to an HDInsight Spark cluster