Microsoft 致力于确保 Azure 服务一直可用。 但是,可能会发生计划外服务中断。 当应用程序需要复原能力时,应为应用配置异地冗余。
还应制定灾难恢复计划来处理区域性服务中断。 灾难恢复计划的一个重要部分是准备在主要副本不可用时切换到应用程序和存储账户的次要副本。
本文介绍使用 Azure Functions Durable Functions 功能配置灾难恢复和异地分发的示例方案。
场景概述
本文介绍三种主动/被动灾难恢复配置。 选择与容错和成本要求匹配的方案:
| 情景 | 防止 | 故障转移时数据丢失 | 跨区域延迟 | 相对成本 |
|---|---|---|---|---|
| 方案 1:共享存储 | 计算中断 | 没有 | 是(在主要区域内的存储) | 低 |
| 方案 2:区域存储 | 计算 和 存储/调度器中断 | 在主机恢复之前暂停正在进行中的编排任务 | 没有 | Medium |
| 方案 3:共享 GRS 存储 | 计算能力和存储故障(含复制) | 最近事务可能丢失(异步复制延迟) | 是(直到 DNS 故障转移完成) | 高 |
注意
如果使用 持久任务计划程序而不是默认的 Azure 存储 提供程序,建议使用方案 2 作为灾难恢复方法。
Background
在Durable Functions中,所有状态都保留在存储后端中。 默认情况下,此后端是Azure 存储,但也可以使用 可任务计划程序或 SQL Server 数据库。 任务中心是用于业务流程和实体的存储资源的逻辑容器。 业务流程协调程序、活动和实体函数只能在它们属于同一任务中心时相互交互。 本文在描述保持这些存储资源高度可用的场景时提到了任务中心枢纽。
协调器和实体可以由 客户端函数 触发,这些函数本身是通过 HTTP 或其他受支持的 Azure Functions 触发器类型触发的。 业务流程和实体也可以通过内置 HTTP API 触发。 为简单起见,本文重点介绍涉及Azure 存储和基于 HTTP 的函数触发器的方案,以及用于提高可用性并在灾难恢复期间最大限度地减少停机时间的选项。 本文未显式涵盖其他触发器类型,例如Azure 服务总线或Azure Cosmos DB触发器。
本文中的方案基于主动/被动配置,最适合使用Azure 存储。 此模式包括将备份(被动)函数应用部署到其他区域。 Azure 流量管理器监视主要(活动)函数 App 以确保 HTTP 的可用性。 当主应用程序失败时,它会切换到备用函数应用程序。 有关详细信息,请参阅 优先级流量路由方法。
一般注意事项
为Durable Functions配置主动/被动故障转移配置时,请记住以下注意事项:
- 本文中的指南假定你使用的是用于存储Durable Functions运行时状态的默认 Azure 存储 提供程序。 还可以配置备用存储提供程序,这些提供程序将状态存储在其他位置,例如在 SQL Server 数据库中。 备用存储提供程序可能需要不同的灾难恢复和异地分发策略。 有关详细信息,请参阅 Durable Functions 存储提供程序。
- 建议的主动/被动配置可确保客户端始终可以通过 HTTP 触发新业务流程。 但是,当两个函数应用在存储中共享相同的任务中心时,某些后台存储事务可以在应用之间分布。 由于此分布,此配置可能会导致次要函数应用的出口成本增加。
- 基础存储帐户和任务中心都在主要区域中创建。 函数应用共享此存储帐户和任务中心。
- 冗余部署的所有函数应用在通过 HTTP 激活时必须共享相同的函数访问密钥。 Azure Functions运行时公开管理 API,可用于以编程方式添加、删除和更新函数密钥。 还可以使用 Azure 资源管理器 API 管理密钥。
方案 1:使用共享存储进行负载均衡计算
为了减轻当函数应用资源不可用时发生停机时间的可能性,此方案使用部署到不同区域的两个函数应用。 建议将此方案作为故障转移的解决方案。
流量管理器配置为检测主函数应用中的问题,并自动将流量重定向到次要区域中的函数应用。 此函数应用共享相同的Azure 存储帐户和任务中心。 函数应用的状态不会丢失,工作可以正常恢复。 将运行状况还原到主要区域后,Azure 流量管理器会自动将请求路由到该函数应用。
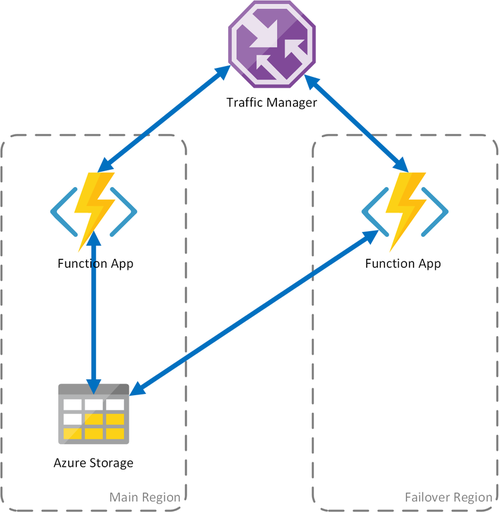
使用此部署方案有几个好处:
- 如果计算基础结构失败,可以在故障转移区域中恢复工作,而不会丢失数据。
- 流量管理器负责自动故障转移到正常的函数应用。
- 服务中断结束后,Traffic Manager 会自动恢复对主要功能应用的流量。
方案特定注意事项
如果使用专用Azure 应用服务计划部署函数应用,则复制故障转移数据中心中的计算基础结构会增加成本。
此方案涵盖计算基础结构中断,但存储帐户仍然是函数应用的单一故障点。 如果发生Azure 存储中断,应用程序将停机。
如果功能应用程序发生故障转移,延迟会增加,因为应用程序跨地区访问其存储帐户。
当函数应用处于故障转移中时,它会访问原始区域中的存储服务。 网络出口流量可能会导致更高的成本。
此方案取决于流量管理器。 客户端应用程序可能需要一些时间才能再次从流量管理器请求函数应用地址。 有关详细信息,请参阅 流量管理器的工作原理。
从 Durable Functions 扩展版本 2.3.0 开始,可以使用同一存储帐户和任务中心配置安全地运行两个函数应用。 第一个启动的应用程序会获取一个应用程序级别的 Blob 租约,从而阻止其他应用程序处理任务中心队列中的消息。 如果第一个应用停止运行,则其租约将过期。 第二个应用可以获取租约并开始处理任务中心消息。
对于 2.3.0 之前的扩展版本,配置为使用相同存储帐户的函数应用会同时处理消息并更新存储元素。 此并发活动会导致总体延迟和出口成本更高。 如果主要应用和副本应用部署了不同的代码,即使是暂时的,业务流程也可能无法正常运行,因为两个应用中的业务流程协调程序函数不一致。
所有需要异地分发进行灾难恢复的应用都应使用 2.3.0 或更高版本的 Durable Functions 扩展。
方案 2:使用区域存储进行负载均衡计算
上述方案仅涵盖仅限于计算基础结构的故障。 当存储服务或持久任务计划程序失败时,函数应用也会中断。
为了确保Durable Functions的持续操作,第二种方案会在托管函数应用的每个区域中部署专用存储帐户或 Durable Task Scheduler。 使用 Durable Task Scheduler 时,我们目前建议采用此灾难恢复方法。
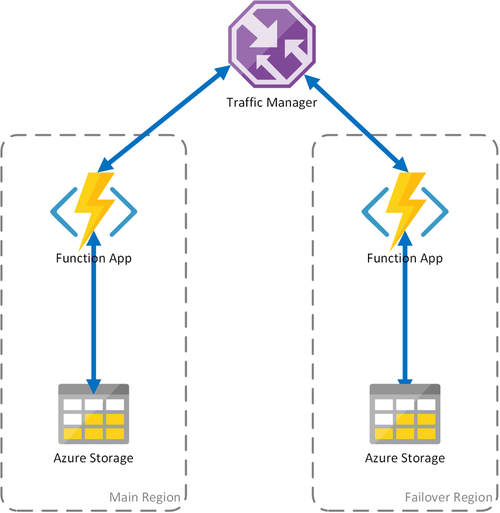
此方法对前面的方案进行了改进:
- 区域状态隔离:每个函数应用都链接到其自己的区域存储帐户或 Durable Task Scheduler。 如果函数应用失败,流量管理器会将流量重定向到次要区域。 由于每个区域中的函数应用使用其本地存储或持久任务计划程序,因此Durable Functions可以使用本地状态继续处理。
- 故障转移时没有附加延迟:在故障转移期间,函数应用程序和状态提供者(存储帐户或持久任务调度程序)是并置的,因此在故障转移区域中不会产生额外的延迟。
- 对状态支持故障的弹性:如果某个区域中的存储帐户或持久任务调度程序出现故障,持久函数会在该区域失败。 Durable Functions 的失败会触发重定向到次要区域。 由于每个区域都隔离计算和应用状态,因此故障转移区域中Durable Functions仍可正常运行。
方案特定注意事项
- 如果使用专用应用服务计划部署函数应用,则复制故障转移数据中心中的计算基础结构会增加成本。
- 当前状态没有发生故障转移。 在主要区域恢复之前,现有业务流程和实体会有效地暂停和不可用。 保留延迟和尽量减少出口成本的权衡是否可接受取决于应用程序的要求。
- 如果使用持久任务计划程序,请考虑为函数应用和区域计划程序之间的网络隔离配置 专用终结点 。
方案 3:使用共享 GRS 进行负载均衡计算
此方案是对第一个方案(实现共享存储帐户)的修改。 主要区别在于存储帐户是在启用异地复制的情况下创建的。
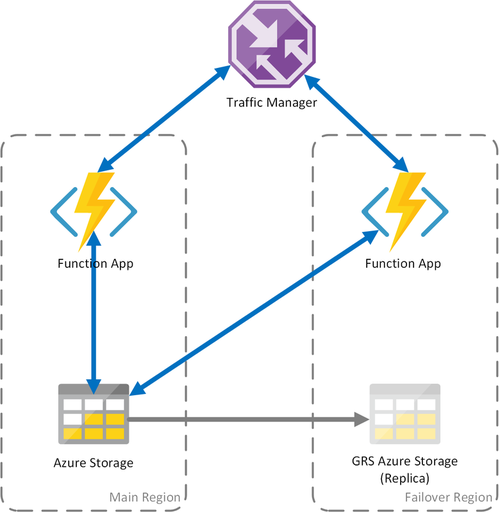
此方案提供与第一种方案相同的功能优势,但也可实现其他数据恢复优势:
- 对于存储账户,异地冗余存储(GRS)和只读访问异地冗余存储(RA-GRS)可以最大化其可用性。
- 如果Azure 存储服务发生区域性中断,可以手动启动到次要副本的故障转移。 在发生灾难导致区域丢失的极端情况下,微软可能会启动区域故障转移。 在这种情况下,无需采取任何行动。
- 发生故障转移时,Durable Functions 的状态将保留到存储帐户的最后一次复制。 复制通常每隔几分钟进行一次。
有关详细信息,请参阅 Azure 存储灾难恢复计划和故障转移。
方案特定注意事项
- 故障转移到副本可能需要一些时间。 在故障转移完成并Azure 存储 DNS 记录更新之前,函数应用将继续不可访问。
- 使用异地复制的存储帐户会增加成本。
- GRS 复制以异步方式复制数据。 由于复制过程的延迟,某些最新事务可能会丢失。
- 如第一个方案所述,建议在此策略中部署的函数应用使用 Durable Functions 扩展版本 2.3.0 或更高版本。