本文介绍如何优化 Durable Functions 应用的性能和缩放行为。 它涵盖你可以调整的主要杠杆:
- 工作程序扩展:Azure Functions 主机如何根据负载添加和删除工作程序。
- 并发限制:如何限制每个工作者节点上同时运行的函数数量。
- 实例缓存:如何在工作器内存中缓存编排状态来减少重放开销。
- 分区计数:如何配置分区以实现横向扩展和本地性。
Important
如果使用 Python 或 PowerShell,请在配置并发设置之前阅读 语言运行时注意事项 。 配置错误的并发可能导致活动在单个工作线程上停止。
工作负载缩放
任务中心概念的一个主要优点是处理任务中心工作项的工作者数量可以根据需要增加或减少。 应用程序添加工作节点(横向扩展)以更快地处理工作,并在没有足够的工作来保持它们忙碌时删除工作节点(缩容)。 甚至可以在任务中心空闲时 缩放为零 。 缩放到零时,没有工作进程运行。 只有缩放控制器和存储保持活动状态。
下图演示了此概念:
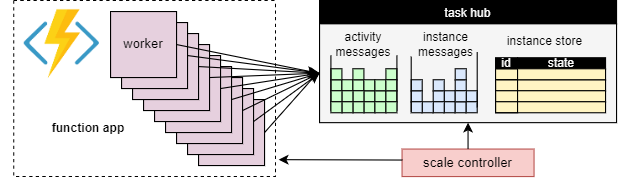
自动缩放
在消费计划和弹性高级计划中,Durable Functions 支持通过 Azure Functions 缩放控制器进行自动缩放。 缩放控制器监视消息和任务在处理前等待的时间。 根据这些延迟,添加或删除工作者。
注意
从 Durable Functions 2.0 开始,可以将函数应用配置为在 Elastic Premium 计划中运行于受虚拟网络保护的服务终结点上。 在此配置中,Durable Functions 触发器启动缩放请求而不是缩放控制器。 有关详细信息,请参阅 运行时缩放监视。
在高级套餐中,自动缩放使工作者数量(和运营成本)与应用程序的负载大致成正比。
并发限制机制
单个工作实例可以同时执行多个工作项。 这会提高并行性,更有效地使用工作者资源。 但是,如果一个工作线程同时处理过多的工作项,则可能会耗尽 CPU、网络连接和内存等资源。
为了防止单个工作线程过度承诺,您可能需要调节每个实例的并发度。 限制在每个工作线程上同时运行的函数数量有助于避免超过该工作线程的资源限制。
注意
并发限制仅适用于本地,并限制 每个工作器的处理。 因此,它们不会限制系统总吞吐量。
Tip
在某些情况下,限制每个工作线程的 并发实际上会增加 系统的总吞吐量。 每个工作节点的工作减少会导致缩放控制器添加更多工作节点来跟上队列需求,从而增加总的吞吐量。
配置并发限制
在 host.json 文件中配置活动、业务流程协调程序和实体函数并发限制。 请使用 durableTask/maxConcurrentActivityFunctions 表示活动函数和 durableTask/maxConcurrentOrchestratorFunctions 表示协调函数和实体函数。 这些设置限制工作者将协调器、实体和活动功能加载到内存中的数量。
注意
业务流程和实体仅在处理事件或操作时,或启用 实例缓存 时加载到内存中。 在运行逻辑并等待(例如,C# 中的 await 或 JavaScript 和 Python 中的 yield)后,他们可以从内存中卸载。 卸载的编排和实体不计入maxConcurrentOrchestratorFunctions限制。 即使数百万个实例处于“正在运行”状态,内存中的实例也仅计入限制限制。 等待某个活动完成的编排也不计入限制。
{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
语言运行时注意事项
你选择的语言运行时可以对函数施加严格的并发限制。 例如,Durable Functions用 Python 或 PowerShell 编写的应用一次只能在单个 VM 上运行一个函数。 如果不考虑这一点,可能会导致性能问题。 如果协调程序扩展为 10 个活动,但是语言运行时只允许运行一个函数,那么这 10 个活动函数中的 9 个将停滞等待运行机会。 此外,这些等待操作无法与其他工作线程进行负载均衡,因为Durable Functions运行时已将它们加载到内存中。 当活动函数长时间运行时,这尤其有问题。
如果语言运行时限制并发,请更新Durable Functions并发设置以匹配它。 这样可以防止 Durable Functions 运行时同时运行的函数数量超过语言运行时的允许范围,并让待处理的活动负载均衡到其他 VM。 例如,如果Python应用将并发限制为四个函数(例如,单个语言工作进程上的 4 个线程或 4 个语言工作进程上的 1 个线程),请同时配置 maxConcurrentOrchestratorFunctions 和 maxConcurrentActivityFunctions 到 4。
有关提高 Python 应用在 Azure Functions 中吞吐量性能的建议,请参阅 提高 Azure Functions 中 Python 应用的吞吐量性能。 这些技术可以显著提高Durable Functions性能和可伸缩性。
实例缓存
若要处理 业务流程工作项,工作人员执行以下两项:
- 获取编排历史记录。
- 使用历史记录重播协调器代码。
如果同一辅助角色处理同一业务流程的多个工作项,则存储提供程序可以在辅助角色的内存中缓存历史记录,以消除第一步。 它还可以缓存中间执行业务流程协调程序,以避免对后续工作项重播历史记录。
当业务流程包含许多剧集并且出现高重播开销时启用缓存。 缓存通常会减少基础存储服务的 I/O 并提高吞吐量和延迟,但也会增加辅助角色内存使用量。
Tip
缓存可以减少运行时重播历史记录的频率,但无法消除重播。 在开发过程中,关闭缓存的情况下测试协调器。 强制重播有助于检测 协调器函数代码约束的违规。
注意
Durable Task Scheduler 在内部管理缓存。 以下配置详细信息仅适用于 BYO 存储提供程序。
由存储提供程序执行的缓存
下表比较了跨提供程序的实例缓存支持,并总结了如何配置每个实例。
| Azure 存储提供程序 | Netherite 存储提供程序 | MSSQL 存储提供程序 | |
|---|---|---|---|
| 实例缓存 | 支持 (仅限于.NET进程内工作器) |
支持 | 不支持 |
| 默认设置 | 禁用 | 已启用 | 不适用 |
| 机制 | 扩展会话 | 实例缓存 | 不适用 |
扩展会话 (Azure 存储提供程序)将执行中的协调器保留在内存中,直到它们设定时间内处于空闲状态。 在extendedSessionsEnabled文件中启用此行为,并使用extendedSessionIdleTimeoutInSeconds和进行调整。
{
"extensions": {
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
}
注意
扩展会话仅在.NET进程内工作器中受支持。 有关详细信息,请参阅 Azure 存储 提供程序文档中的 扩展会话。
实例缓存 (Netherite 存储提供程序)在工作器的内存中存储实例状态和历史记录,并跟踪总内存使用情况。 如果缓存超出 InstanceCacheSizeMB 限制,则会逐出最近使用最少的实例数据。 如果将CacheOrchestrationCursors设置为true,缓存还会存储执行中的协调程序。
注意
实例缓存适用于所有语言 SDK,但CacheOrchestrationCursors选项仅适用于.NET 进程内工作器。 有关详细信息,请参阅 Netherite 存储提供程序文档中的 实例缓存 。
分区计数
某些存储提供程序支持 分区 ,并允许设置 partitionCount。
使用分区时,工作者不会争夺单个工作项。 将工作项分组到 partitionCount 分区中,运行时将分区分配给工作者。 此方法可减少存储访问总数。 此外还可以启用实例缓存,并通过创建相关性改进区域:同一辅助角色处理同一实例的所有工作项。
注意
Durable Task Scheduler 在内部管理分区。 以下配置详细信息仅适用于 BYO 存储提供程序。
对于大多数应用,默认分区计数就足够了。 如果你希望在默认编排工作线程数量之外进行拓展,请增加分区计数,因为它限制了能够处理来自分区队列的编排消息的工作线程数量。
下表显示了每个存储提供程序如何分区队列以及partitionCount的允许范围和默认值。
| Azure 存储提供程序 | Netherite 存储提供程序 | MSSQL 存储提供程序 | |
|---|---|---|---|
| 实例消息 | Partitioned | Partitioned | 未分区 |
| 活动消息 | 未分区 | Partitioned | 未分区 |
默认值 partitionCount |
4 | 12 | 不适用 |
最大值 partitionCount |
16 | 32 | 不适用 |
| 文档 | 请参阅 Orchestrator 横向扩展 | 请参阅 分区计数注意事项 | 不适用 |
Warning
创建任务中心后,无法更改分区计数。 将其设置为足够高,以满足任务中心实例的预期横向扩展要求。
设置分区数
在 partitionCount 文件中指定。 以下 host.json 片段将 durableTask/storageProvider/partitionCount 设置为 3。
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
函数执行行为
本部分介绍影响性能的执行详细信息:每个函数类型应处理的工作类型、超时的工作原理以及实体操作的批处理方式。
按职能类型工作安置
协调器函数 会因为重播而多次运行其逻辑。 因此,协调器函数线程不执行 CPU 密集型任务、进行 I/O 操作或产生阻塞是非常重要的。 将可能需要 I/O、阻塞或多个线程的工作移动到活动函数中。
活动函数 的行为类似于常规队列触发的函数。 它们支持 I/O、CPU 密集型作和多个线程。 由于活动触发器是无状态的,因此能够横向扩展到许多 VM。
实体函数 也在单个线程上运行,并一次处理一个操作。 实体函数对它们运行的代码类型没有限制。
函数超时
活动、协调器和实体函数与其他 Azure Functions 一样,受到相同的函数超时限制。 Durable Functions将函数超时视为代码中未经处理的异常。
例如,当操作超时时,Durable Functions将执行记录为失败并通知协调器。 协调器会像处理任何其他异常一样处理超时:如果调用指定重试,或运行异常处理程序,则运行时会进行重试。
实体操作批处理
为了提高性能和降低成本,单个工作项可以执行一批实体操作。 在消耗计划中,每个批处理都作为单个函数执行计费。
默认情况下,消费计划的最大批大小为 50,其他计划为 5,000。 还可以在 host.json 文件中配置最大批大小。 如果最大批大小为 1,则批处理被有效地禁用。
注意
如果单个实体操作需要很长时间来执行,则限制最大批大小以降低函数超时的风险可能有所帮助,尤其是在消耗计划中。
性能目标
规划具有Durable Functions的生产应用时,请尽早考虑性能要求。 这些基本使用方案可帮助你规划:
- 顺序活动执行:此方案描述按顺序运行一系列活动函数的业务流程协调程序函数。 它最类似于 函数链接 示例。
- 并行活动执行:此方案描述一个业务流程协调程序函数,该函数使用 扇出扇入 模式并行执行许多活动函数。
- 并行响应处理:此方案是 扇出扇入 模式的后半部分。 它注重于提升扇入性能。 与扇出不同,扇入在单个协调器函数实例中运行,因此在单个 VM 上运行。
- 外部事件处理:此方案指一个编排函数实例,该实例逐个等待外部事件。
- 实体操作处理:此方案测试 单个计数器实体 处理持续操作流的速度。
这些方案的吞吐量数字位于存储提供程序文档中。 具体而言:
Tip
与扇出不同,扇入操作限制为单个 VM。 如果您的应用程序使用扇出、扇入模式,并且您担心扇入的性能,请考虑将活动函数的扇出拆分为多个子编排流程。