适用于:![]() Azure SQL 数据库
Azure SQL 数据库
重要
SQL Data Sync 将于 2027 年 9 月 30 日停用。 请考虑迁移到备用数据复制/同步解决方案。
使用 SQL 数据同步这项基于 Azure SQL 数据库的服务,可以跨多个本地和云端数据库双向同步选定数据。
Azure SQL 数据同步不支持 Azure SQL 托管实例或 Azure Synapse Analytics。
概述
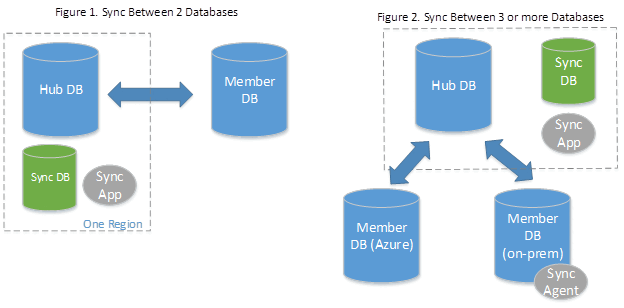
数据同步以同步组的概念为依据。 同步组是一组要同步的数据库。
数据同步使用中心辐射型拓扑来同步数据。 将同步组中的一个数据库定义为中心数据库。 其余数据库均为成员数据库。 仅在中心和各成员之间同步数据。
- 中心数据库必须是 Azure SQL 数据库。
- 成员数据库可以是 Azure SQL 数据库或 SQL Server 实例中的数据库。
- 同步元数据数据库包含用于数据同步的元数据和日志。同步元数据数据库必须是与中心数据库位于同一区域的 Azure SQL 数据库。 同步元数据数据库的创建者和所有者均为客户。 每个区域和订阅只能有一个同步元数据数据库。 存在同步组或同步代理时,无法删除或重命名同步元数据数据库。 Azure 建议新建空数据库,以将其用作同步元数据数据库。 数据同步在此数据库中创建表,并定期运行工作负载。
注意
如果使用本地数据库作为成员数据库,必须安装并配置本地同步代理。
同步组具有以下属性:
- “同步模式”描述了哪些数据被同步。
- “同步方向”可以是双向的,也可以仅为单向的。 也就是说,“同步方向”可以是“中心到成员”或“成员到中心”,或两者均可。
- “同步间隔”描述多久执行一次同步。
- “冲突解决策略”是组级别策略,可以是“中心胜出”,也可以是“成员胜出”。
何时使用
如果需要跨 Azure SQL 数据库或 SQL Server 中的多个数据库使数据保持最新,数据同步非常有用。 下面是 SQL 数据同步的主要用例:
- 混合数据同步:借助数据同步,可以在 SQL Server 和 Azure SQL 数据库中的数据库之间保持数据同步,以便启用混合应用程序。 此功能可能会吸引考虑迁移到云端并希望将某些应用程序部署到 Azure 的客户。
- 分布式应用程序: 在许多情况下,跨各个数据库分散不同的工作负载会大有裨益。 例如,如果有大型生产数据库,但还需要对此数据运行报表或分析工作负载,那么使用第二个数据库来处理此额外工作负载将会有所帮助。 这种方法可最大限度地减轻对生产工作负载造成的性能影响。 可以使用 SQL 数据同步来同步这两个数据库。
- 全球分布的应用程序: 许多企业的业务分布在多个区域。 为了最大限度地缩短网络延迟时间,最好将数据存储在靠近的区域中。 借助数据同步,可轻松让所有区域中的数据库保持同步。
数据同步不是以下场景的首选解决方案:
| 场景 | 一些建议的解决方案 |
|---|---|
| 灾难恢复 | Azure SQL 数据库中的自动备份 |
| 读取扩展 | 使用只读副本卸载只读的查询工作负荷 |
| ETL(OLTP 到 OLAP) | Azure 数据工厂或 SQL Server Integration Services |
| 从 SQL Server 迁移到 Azure SQL 数据库。 但是,可以在迁移完成后使用 SQL 数据同步,以确保源和目标保持同步。 | Azure 数据库迁移服务 |
工作原理
- 跟踪数据更改: SQL 数据同步使用插入、更新和删除触发器来跟踪更改。 更改记录在用户数据库中的端表内。 默认情况下 BULK INSERT 不会激发触发器。 如果未指定 FIRE_TRIGGERS,则不执行任何插入触发器。 添加 FIRE_TRIGGERS 选项,以便数据同步可以跟踪这些插入。
- 同步数据:数据同步旨在用于中心辐射型模型。 中心将分别与每个成员进行同步。 中心内的更改会先下载到成员,然后成员内的更改会上传到中心。
-
解决冲突: SQL 数据同步提供两个冲突解决选项,即“中心胜出”或“成员胜出” 。
- 如果选择“中心优先”,则中心内的更改将始终覆盖成员内的更改。
- 如果选择“成员优先”,则成员内的更改会覆盖中心内的更改。 如果有多个成员,最终值取决于哪个成员最先同步。
与事务复制比较
| 数据同步 | 事务复制 | |
|---|---|---|
| 优点 | - 主动-主动支持 - 在本地和 Azure SQL 数据库之间双向同步 |
- 更低的延迟 - 事务一致性 - 迁移后重用现有拓扑 \- Azure SQL 托管实例支持 |
| 缺点 | - 无事务一致性 - 更高的性能影响 |
- 无法从 Azure SQL 数据库发布 - 维护成本高 |
注意
SQL 数据同步需要 SQL 身份验证 才能连接到中心和成员数据库。 SQL 数据同步不支持Microsoft Entra (Azure AD) 身份验证。由于 SQL 身份验证依赖于静态密码,因此它不会受益于多重身份验证(MFA)、条件访问或托管标识等新式保护。 这会增加整个 SQL 实例遭受凭据盗窃、暴力破解攻击的风险,并增加密码轮换和策略执行的操作开销。 如果可能,首选支持Microsoft Entra 身份验证或托管标识的解决方案。 由于 SQL 数据同步计划停用,因此请迁移到符合组织安全标准的替代方法。
数据同步的专用链接
注意
SQL 数据同步专用链接与 Azure 专用链接不同。
使用新的专用链接功能,可以选择服务托管的专用终结点,以便在数据同步过程中在同步服务与成员/中心数据库之间建立安全连接。 服务托管的专用终结点是特定虚拟网络和子网中的专用 IP 地址。 在数据同步中,服务托管的专用终结点由 Microsoft 创建,并且由数据同步服务专门用于给定的同步操作。
在设置专用链接之前,请阅读功能的常规要求。

注意
你需要在同步组部署期间或通过 PowerShell,在 Azure 门户的“专用终结点连接”页中手动批准由服务管理的专用终结点。
开始
在 Azure 门户中设置数据同步
使用 PowerShell 设置数据同步
使用 REST API 设置数据同步
查看数据同步最佳做法
出了什么问题吗?
一致性和性能
最终一致性
由于 SQL 数据同步是基于触发器的服务,因此无法保证事务一致性。 Azure 保证最终执行所有更改,且数据同步不会导致数据丢失。
性能影响
SQL 数据同步使用插入、更新和删除触发器来跟踪更改。 它在用户数据库中创建用于跟踪的端表。 这些更改跟踪活动会对数据库工作负荷产生影响。 评估服务层级并根据需要升级。
在同步组创建、更新和删除期间预配和取消预配也可能会影响数据库性能。
要求和限制
一般要求
- 每个表都必须具有主键。 请勿更改任何一行中的主键值。 如果必须更改主键值,请先删除行,再使用新的主键值重新创建此行。
重要
更改现有主键的值会导致以下错误行为:
- 即使同步未报告任何问题,中心和成员之间的数据也会丢失。
- 由于主键更改,跟踪表的源行不存在,同步可能会失败。
必须同时为同步成员和中心启用快照隔离。 有关详细信息,请参阅 SQL Server 中的快照隔离。
若要使用数据同步专用链接,成员数据库和中心数据库都必须托管在 Azure 中(位于相同或不同的区域)。 此外,要使用专用链接,
Microsoft.Network资源提供程序必须向托管中心和成员服务器的订阅注册。 最后,在同步配置期间,必须在 Azure 门户的“专用终结点连接”部分(或通过 PowerShell)手动批准数据同步的专用链接。 有关如何批准专用链接的详细信息,请参阅教程:在 Azure SQL 数据库和 SQL Server 中的数据库之间设置 SQL 数据同步。 批准服务托管的专用终结点后,同步服务和成员/中心数据库之间的所有通信都通过专用链接进行。 可以更新现有同步组以启用此功能。
一般限制
- 表不能包含非主键的标识列。
- 主键不能具有以下数据类型:sql_variant、binary、varbinary、image、xml。
- 使用以下数据类型作为主键时请小心谨慎,因为支持的精度仅到秒:time、datetime、datetime2、datetimeoffset。
- 对象(数据库、表和列)的名称不能包含可打印字符句点 (
.)、左方括号 ([) 或右方括号 (])。 - 表名不能包含可打印字符:
! " # $ % ' ( ) * + -或空格。 - 不支持 Microsoft Entra(以前称为 Azure Active Directory)身份验证。
- 如果存在名称相同但架构不同的表(例如
dbo.customers和sales.customers),则只能将其中一个表添加到同步中。 - 不支持具有用户定义数据类型的列。
- 不支持在不同订阅之间移动服务器。
- 如果两个主键只是大小写不同(例如
Foo和foo),则数据同步将不支持此应用场景。 - 截断表不是数据同步支持的操作(不会跟踪更改)。
- 不支持将 Azure SQL 超大规模数据库用作中心或同步元数据数据库。 但是,超大规模数据库可以是数据同步拓扑中的成员数据库。
- 不支持内存优化表。
- 架构更改不会自动复制。
- 数据同步仅支持以下两个索引属性:Unique、Clustered/Non-Clustered。 索引的其他属性(如
IGNORE_DUP_KEY或WHERE筛选器谓词等)不受支持,并且即使源索引设置了这些属性,目标索引也会在未设置这些属性的情况下进行预配。 - Azure 弹性作业数据库不能用作 SQL 数据同步元数据数据库,反之亦然。
- 账本数据库不支持 SQL 数据同步。
- 数据同步不是灾难恢复或高可用性工具,也不会同步其自己的同步组信息。 数据同步没有自动灾难恢复。
- 数据同步不支持网络安全外围(NSP)。
不支持的数据类型
- FileStream
- SQL/CLR 用户定义数据类型 (UDT)
- XMLSchemaCollection(支持 XML)
- Cursor、RowVersion、Timestamp、Hierarchyid
不支持的列类型
数据同步无法同步只读列或系统生成的列。 例如:
- 计算列
- 临时表的系统生成的列
服务和数据库维度方面的限制
| 尺寸 | 限制 | 解决方法 |
|---|---|---|
| 任何数据库可属于的同步组的数量上限。 | 5 | |
| 一个同步组中包含的终结点的数量上限 | 30 | |
| 一个同步组中包含的本地终结点的数量上限。 | 5 | 创建多个同步组 |
| 数据库、表、架构和列名称 | 每个名称 50 个字符 | |
| 同步组中的表 | 500 | 创建多个同步组 |
| 同步组中表的列 | 1000 | |
| 表中的数据行大小 | 24MB |
注意
如果只有一个同步组,则单个同步组中最多可能有 30 个终结点。 如果有多个同步组,则所有同步组中的终结点总数不能超过 30。 如果数据库属于多个同步组,则该数据库计算为多个终结点,而不是一个。
网络要求
注意
如果使用数据同步专用链接,则这些网络要求不适用。
在建立同步组后,数据同步服务需要连接到中心数据库。 建立同步组时,Azure SQL Server 的 Firewalls and virtual networks 设置必须具有以下配置:
- “拒绝公用网络访问”必须设置为“关”。
- “允许 Azure 服务和资源访问此服务器”必须设置为“是”,否则必须为数据同步服务使用的 IP 地址创建 IP 规则 。
创建并预配同步组后,可以禁用这些设置。 同步代理将直接连接到中心数据库,你可以使用服务器的防火墙 IP 规则或专用终结点允许代理访问中心服务器。
注意
如果更改同步组架构设置,则将需要允许数据同步服务再次访问服务器,以便可以重新预配中心数据库。
区域数据驻留
如果在同一区域内同步数据,SQL 数据同步不会在部署服务实例的区域外存储/处理客户数据。 如果跨不同区域同步数据,SQL 数据同步将把客户数据复制到配对区域。
SQL 数据同步常见问题解答
SQL 数据同步服务的价格是多少?
对 SQL 数据同步服务本身不收取任何费用。 但是,对于传入和传出 SQL 数据库实例的数据移动,你仍然收取数据传输费用。 有关详细信息,请参阅数据传输费用。
哪些区域支持数据同步?
SQL 数据同步在所有区域中都可用。
是否需要 Azure SQL 数据库帐户?
是的。 必须具有 Azure SQL 数据库帐户才能托管中心数据库。
是否可以仅使用数据同步在 SQL Server 数据库之间进行同步?
无法直接配合使用。 但是,可以间接地在 SQL Server 数据库之间同步,方法是在 Azure 中创建一个中心数据库,然后将本地数据库添加到同步组。
是否可以使用数据同步在 Azure SQL 数据库中属于不同订阅的数据库之间进行同步?
是的。 你可以在属于不同订阅拥有的资源组的数据库之间配置同步,即使订阅属于不同的租户。
- 如果订阅属于同一租户,并且你有权访问所有订阅,则可以在 Azure 门户中配置同步组。
- 否则,必须使用 PowerShell 来添加同步成员。
- 跨租户方案中不支持专用链接。
是否可以设置数据同步以在 SQL 数据库中属于不同云(例如 Azure 公有云和由世纪互联运营的 Azure)的数据库之间进行同步?
数据同步不支持跨云同步。
是否可以使用数据同步将生产数据库中的数据种子植入到空数据库,然后将这两个数据库同步?
是的。 通过从原始数据库编写脚本,在新数据库中手动创建架构。 创建架构后,将表添加到同步组以复制数据并使其同步。
我应该使用 SQL 数据同步备份和还原数据库吗?
建议不要使用 SQL 数据同步创建数据备份。 由于 SQL 数据同步的同步不进行版本控制,因此无法备份并还原到特定时间点。 此外,SQL 数据同步不会备份其他 SQL 对象(如存储过程),并且不会快速执行还原操作的等效操作。
有关推荐的备份技术,请参阅在 Azure SQL 数据库中复制数据库的事务一致性副本。
数据同步是否可以同步加密的表或列?
- 如果数据库使用了 Always Encrypted,则只能同步未加密的表和列。 无法同步加密的列,因为数据同步无法对数据进行解密。
- 如果某个列使用了列级加密 (CLE),则可以对该列进行同步,只要行大小小于最大大小 24 MB。 数据同步将密钥 (CLE) 加密的列视为普通的二进制数据。 若要解密其他同步成员上的数据,则需要具有相同的证书。
SQL 数据同步是否支持排序规则?
是的。 SQL 数据同步在以下情况下支持配置排序规则设置:
- 如果所选同步架构表不在中心或成员数据库中,则部署同步组时,该服务会使用空目标数据库中选择的排序规则设置自动创建相应的表和列。
- 如果要同步的表已经存在于中心和成员数据库中,则 SQL 数据同步要求中心数据库和成员数据库之间的主键列具有相同的排序规则,以成功部署同步组。 主键列以外的列不存在排序规则限制。
SQL 数据同步是否支持联盟?
联合根数据库可用于 SQL 数据同步服务,没有任何限制。 不能将联合数据库终结点添加到当前版本的 SQL 数据同步。
是否可以使用数据同步来同步通过自带数据库 (BYOD) 功能从 Dynamics 365 导出的数据?
利用 Dynamics 365 自带数据库功能,管理员可以将数据实体从应用程序导出到其自己的 Azure SQL 数据库中。 如果使用“增量推送”(不支持完全推送)导出数据,并且“在目标数据库中启用触发器”设置为“是”,则可以使用数据同步来将这些数据同步到其他数据库中。
如何在故障转移组中创建数据同步以支持灾难恢复?
SQL 数据同步不提供自动故障转移或灾难恢复功能。 如果数据库故障转移到另一个区域,同步组将停止工作。 使用与主要区域相同的设置在故障转移区域中手动重新创建同步组。
相关内容
监视和故障排除
SQL 数据同步是否按预期执行? 若要监视活动和排查问题,请参阅以下文章:
了解有关 Azure SQL 数据库的详细信息
有关 Azure SQL 数据库的详细信息,请参阅以下文章: