Azure Cosmos DB 是一个可缩放的、多区域分布式、完全托管的数据库。 它提供了保证的低延迟数据访问。 若要详细了解 Azure Cosmos DB,请参阅 overview 一文。 本文指导如何将数据从 HBase 迁移到 Azure Cosmos DB NoSQL 帐户。
Azure Cosmos DB 与 HBase 之间的差异
在迁移之前,必须了解 Azure Cosmos DB 和 HBase 之间的差异。
资源模型
Azure Cosmos DB 具有以下资源模型: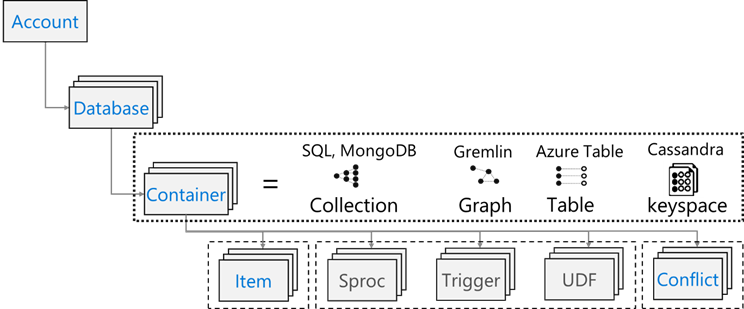 ,包括帐户、数据库、容器和项目。
,包括帐户、数据库、容器和项目。
HBase 具有以下资源模型: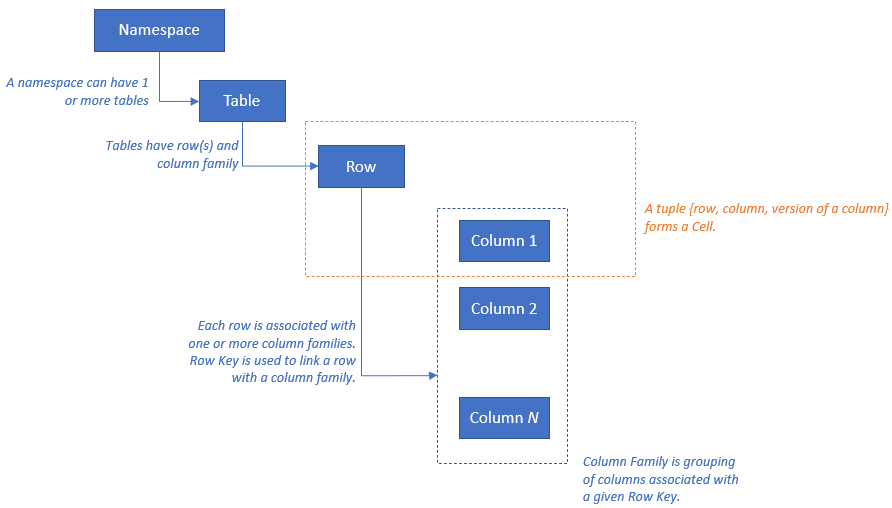
资源映射
下表显示了 Apache HBase、Apache Phoenix 和 Azure Cosmos DB 之间的概念映射。
| HBase | Phoenix | Azure Cosmos DB |
|---|---|---|
| 集群 | 集群 | 帐户 |
| Namespace | 架构(如果启用) | 数据库 |
| Table | Table | 容器/集合 |
| 列系列 | 列系列 | 不适用 |
| 行 | 行 | 单项/文件 |
| 版本(时间戳) | 版本(时间戳) | 不适用 |
| 不适用 | 主键 | 分区键 |
| 不适用 | Index | Index |
| 不适用 | 辅助索引 | 辅助索引 |
| 不适用 | 查看 | 不适用 |
| 不适用 | 序列 | 不适用 |
数据结构比较和差异
Azure Cosmos DB 和 HBase 的数据结构之间的主要区别如下:
RowKey
在 HBase 中,数据通过 RowKey 进行存储,并按表创建期间指定的 RowKey 范围水平分区为各个区域。
Azure Cosmos DB 利用指定的 分区键的哈希值将数据分发到不同的分区中。
列系列
在 HBase 中,列按列系列 (CF) 进行分组。
Azure Cosmos DB (Api for NoSQL) 将数据存储为 JSON 文档。 因此,与 JSON 数据结构关联的所有属性都适用。
时间戳
HBase 使用时间戳为给定单元的多个实例确定版本。 可以使用时间戳查询单元的不同版本。
Azure Cosmos DB 附带 更改源功能,以发生的顺序跟踪容器的更改的持久记录。 然后,它会按照所更改文档的修改顺序输出这些文档的排序列表。
数据格式
HBase 数据格式由 RowKey、列系列:列名、时间戳和值组成。 下面是 HBase 表行的示例:
ROW COLUMN+CELL 1000 column=Office:Address, timestamp=1611408732448, value=1111 San Gabriel Dr. 1000 column=Office:Phone, timestamp=1611408732418, value=1-425-000-0002 1000 column=Personal:Name, timestamp=1611408732340, value=John Dole 1000 column=Personal:Phone, timestamp=1611408732385, value=1-425-000-0001在 Azure Cosmos DB for NoSQL 中,JSON 对象表示数据格式。 分区键驻留在文档的字段中,并设置哪个字段是集合的分区键。 Azure Cosmos DB 没有用于列系列或版本的时间戳的概念。 如前面强调的那样,它具有更改记录支持,可以通过该功能跟踪/记录对容器的更改。 下面是文档的示例。
{ "RowId": "1000", "OfficeAddress": "1111 San Gabriel Dr.", "OfficePhone": "1-425-000-0002", "PersonalName": "John Dole", "PersonalPhone": "1-425-000-0001", }
小窍门
HBase 将数据存储在字节数组中,因此,如果要将包含双字节字符的数据迁移到 Azure Cosmos DB,数据必须经过 UTF-8 编码。
一致性模型
HBase 提供严格一致的读取和写入。
Azure Cosmos DB 提供五个定义完善的一致性级别。 每个级别在可用性与性能方面各有利弊。 支持的一致性级别如下(从最强到最弱):
- 非常
- 有限过期性
- Session
- 一致前缀
- 最终
调整大小
HBase
对于 HBase 的企业规模部署,Master、区域服务器和 ZooKeeper 推动了大量的调整大小操作。 与任何分布式应用程序一样,HBase 旨在实现水平扩展。HBase 的性能主要受 HBase 区域服务器大小的影响。 大小调整主要取决于两个关键要求 - 必须存储在 HBase 上的数据集的吞吐量和大小。
Azure Cosmos DB
Azure Cosmos DB 是来自Azure的 PaaS 产品/服务,底层基础结构部署详细信息从最终用户抽象化。 预配 Azure Cosmos DB 容器时,Azure平台会自动预配底层基础结构(计算、storage、内存、网络堆栈),以支持给定工作负荷的性能要求。 所有数据库操作的成本均由 Azure Cosmos DB 规范化,并以 请求单元(或简称为 RU)表示。
若要估计工作负载消耗的 RU 数量,请考虑以下因素:
有一个容量计算器可用于帮助进行 RU 的大小调整练习。
还可以在 Azure Cosmos DB 中使用 自动缩放预配吞吐量自动缩放数据库或容器吞吐量(RU/秒)。 吞吐量会根据使用情况进行缩放,而不会影响工作负载可用性、延迟、吞吐量或性能。
数据分布
HBase HBase 根据 RowKey 对数据进行排序。 数据随后会分区到区域中并存储在区域服务器中。 自动分区会根据分区策略水平划分区域。 这由分配给 HBase 参数 hbase.hregion.max.filesize 的值(默认值为 10 GB)进行控制。 HBase 中具有给定 RowKey 的行始终属于一个区域。 此外,每个列系列的数据会在磁盘上分隔。 这样便可以在读取时进行筛选,并对 HFile 上的 I/O 进行隔离。
Azure Cosmos DB Azure Cosmos DB 使用 分区来缩放单个容器。 有关逻辑分区、物理分区和分区键选择的综合详细信息,请参阅 分区概述。
迁移的主要差异:
- 数据分布机制:HBase 的 RowKey 对数据和存储连续数据进行排序,同时Azure Cosmos DB 的分区键哈希分布数据。 使用相同的 RowKey 作为分区键通常无法达到最佳性能。
- 排序查询的Composite 索引:鉴于数据在 HBase 上排序,Azure Cosmos DB 复合索引可能很有用。 如果要对多个字段使用 ORDER BY 子句,则需要用到该子句。 还可以通过定义复合索引来提高许多相等查询和范围查询的性能。
可用性
HBase HBase 由 Master、区域服务器和 ZooKeeper 组成。 通过使每个组件冗余,可以实现单个群集的高可用性。 配置异地冗余时,可以在不同物理数据中心间部署 HBase 群集,并使用复制使多个群集保持同步。
Azure Cosmos DB Azure Cosmos DB 不需要任何配置(例如群集组件冗余)。 它可为高可用性、一致性和延迟提供综合性 SLA。 有关更多详细信息,请参阅 SLA for Azure Cosmos DB。
数据可靠性
HBase HBase 基于 Hadoop 分布式文件系统 (HDFS) 进行构建,HDFS 上存储的数据会复制三次。
Azure Cosmos DB Azure Cosmos DB 主要以两种方式提供高可用性。 首先,Azure Cosmos DB 在 Azure Cosmos DB 帐户中配置的区域之间复制数据。 其次,Azure Cosmos DB 保留区域中数据的四个副本。
迁移前的注意事项
系统依赖项
规划的这一方面侧重于了解 HBase 实例的上游和下游依赖项,该依赖项正在迁移到 Azure Cosmos DB。
下游依赖项的示例可能是从 HBase 读取数据的应用程序。 必须对这些进行重构以从 Azure Cosmos DB 读取。 在迁移过程中必须考虑以下几点:
用于评估依赖项的问题 - 当前 HBase 系统是否为独立组件? 或者,它是否调用了另一个系统上的进程,或它是否由另一个系统上的进程进行调用,或它是否使用目录服务进行访问? 是否有其他重要进程在 HBase 群集中工作? 需要阐明这些系统依赖项,以确定迁移的影响。
本地 HBase 部署的 RPO 和 RTO。
脱机与联机迁移
对于成功的数据迁移,重要的是了解使用数据库的业务特征,并确定如何进行。 如果可以完全关闭系统,执行数据迁移,然后在目标位置重新启动系统,请选择脱机迁移。 此外,如果数据库始终繁忙,并且你不能承受较长中断时间,请考虑联机迁移。
注释
本文档仅涵盖脱机迁移。
执行脱机数据迁移时,这取决于当前运行的 HBase 版本和可用的工具。 请参阅数据迁移部分以了解更多详细信息。
性能注意事项
规划的这一方面是了解 HBase 的性能目标,然后将其转换为 Azure Cosmos DB 语义。 例如, 若要在 HBase 上命中 “X” IOPS,Azure Cosmos DB 中需要多少个请求单位(RU/s)。 HBase 和 Azure Cosmos DB 之间存在差异,本练习重点介绍如何将 HBase 中的性能目标转换为 Azure Cosmos DB。 这会推动扩展活动。
需要问的问题:
- HBase 部署是读取密集型还是写入密集型?
- 读取与写入之间的比例是什么?
- 目标 IOPS 表示为多少百分位?
- 使用哪些/如何使用应用程序将数据加载到 HBase?
- 如何使用哪些应用程序从 HBase 读取数据?
执行请求排序数据的查询时,HBase 会快速返回结果,因为数据是按 RowKey 进行排序。 但是,Azure Cosmos DB 没有这样的概念。 若要优化性能,可以根据需要使用组合索引。
部署注意事项
可以使用 Azure portal 或 Azure CLI 部署 Azure Cosmos DB for NoSQL。 由于迁移目标Azure Cosmos DB for NoSQL,因此在部署时选择 API 的“NoSQL”作为参数。 此外,请根据可用性要求设置地理冗余、多区域写入和可用区。
网络注意事项
Azure Cosmos DB 有三个主要网络选项。 第一个配置使用公共 IP 地址,并通过 IP 防火墙控制访问(默认值)。 第二种配置使用公共 IP 地址,仅允许从特定虚拟网络(服务端点)的特定子网访问。 第三种是使用专用 IP 地址加入专用网络的配置(专用终结点)。
有关三种网络选项的详细信息,请参阅以下文档:
评估现有数据
数据发现
从现有 HBase 群集提前收集信息,以确定要迁移的数据。 这些信息可帮助确定如何迁移、决定要迁移的表、了解这些表中的结构以及决定如何生成数据模型。 例如,收集如下所示的详细信息:
- HBase 版本
- 迁移目标表
- 列系列信息
- 表状态
以下命令演示如何使用 hbase shell 脚本收集以上详细信息,并将其存储在操作系统的本地文件系统中。
获取 HBase 版本
hbase version -n > hbase-version.txt
输出:
cat hbase-version.txt
HBase 2.1.8.4.1.2.5
获取表的列表
可以获取 HBase 中存储的表的列表。 如果创建了非默认命名空间,则它会以“命名空间: 表”格式输出。
echo "list" | hbase shell -n > table-list.txt
HBase 2.1.8.4.1.2.5
输出:
echo "list" | hbase shell -n > table-list.txt
cat table-list.txt
TABLE
COMPANY
Contacts
ns1:t1
3 row(s)
Took 0.4261 seconds
COMPANY
Contacts
ns1:t1
确定要迁移的表
通过指定要迁移的表名,获取表中列系列的详细信息。
echo "describe '({Namespace}:){Table name}'" | hbase shell -n > {Table name} -schema.txt
输出:
cat {Table name} -schema.txt
Table {Table name} is ENABLED
{Table name}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'cf2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.5775 seconds
获取表中的列系列及其设置
echo "status 'detailed'" | hbase shell -n > hbase-status.txt
输出:
{HBase version}
0 regionsInTransition
active master: {Server:Port number}
2 backup masters
{Server:Port number}
{Server:Port number}
master coprocessors: []
# live servers
{Server:Port number}
requestsPerSecond=0.0, numberOfOnlineRegions=44, usedHeapMB=1420, maxHeapMB=15680, numberOfStores=49, numberOfStorefiles=14, storefileUncompressedSizeMB=7, storefileSizeMB=7, compressionRatio=1.0000, memstoreSizeMB=0, storefileIndexSizeKB=15, readRequestsCount=36210, filteredReadRequestsCount=415729, writeRequestsCount=439, rootIndexSizeKB=15, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=464, currentCompactedKVs=464, compactionProgressPct=1.0, coprocessors=[GroupedAggregateRegionObserver, Indexer, MetaDataEndpointImpl, MetaDataRegionObserver, MultiRowMutationEndpoint, ScanRegionObserver, SecureBulkLoadEndpoint, SequenceRegionObserver, ServerCachingEndpointImpl, UngroupedAggregateRegionObserver]
[...]
"Contacts,,1611126188216.14a597a0964383a3d923b2613524e0bd."
numberOfStores=2, numberOfStorefiles=2, storefileUncompressedSizeMB=7168, lastMajorCompactionTimestamp=0, storefileSizeMB=7, compressionRatio=0.0010, memstoreSizeMB=0, readRequestsCount=4393, writeRequestsCount=0, rootIndexSizeKB=14, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=0, currentCompactedKVs=0, compactionProgressPct=NaN, completeSequenceId=-1, dataLocality=0.0
[...]
可以获取有用的调整大小信息,例如堆内存的大小、区域数、作为群集状态的请求数以及以表状态形式进行压缩/解压缩的数据大小。
如果要在 HBase 群集上使用 Apache Phoenix,则还需要从 Phoenix 收集数据。
- 迁移目标表
- 表架构
- 索引
- 主密钥
在群集上连接到 Apache Phoenix
sqlline.py ZOOKEEPER/hbase-unsecure
获取表列表
!tables
获取表详细信息
!describe <Table Name>
获取索引详细信息
!indexes <Table Name>
获取主键详细信息
!primarykeys <Table Name>
迁移您的数据
迁移选项
有多种方法可以脱机迁移数据,但此处我们将介绍如何使用Azure Data Factory。
| 解决方案 | 源版本 | 注意事项 |
|---|---|---|
| Azure Data Factory | HBase < 2 | 易于设置。 适合用于大型数据集。 不支持 HBase 2 或更高版本。 |
| Apache Spark | 所有版本 | 支持 HBase 的所有版本。 适合用于大型数据集。 需要 Spark 设置。 |
| 使用 Azure Cosmos DB 批量执行程序库的自定义工具 | 所有版本 | 最灵活,可使用库创建自定义数据迁移工具。 需要进行更多设置工作。 |
以下流程图使用某些条件访问可用的数据迁移方法。
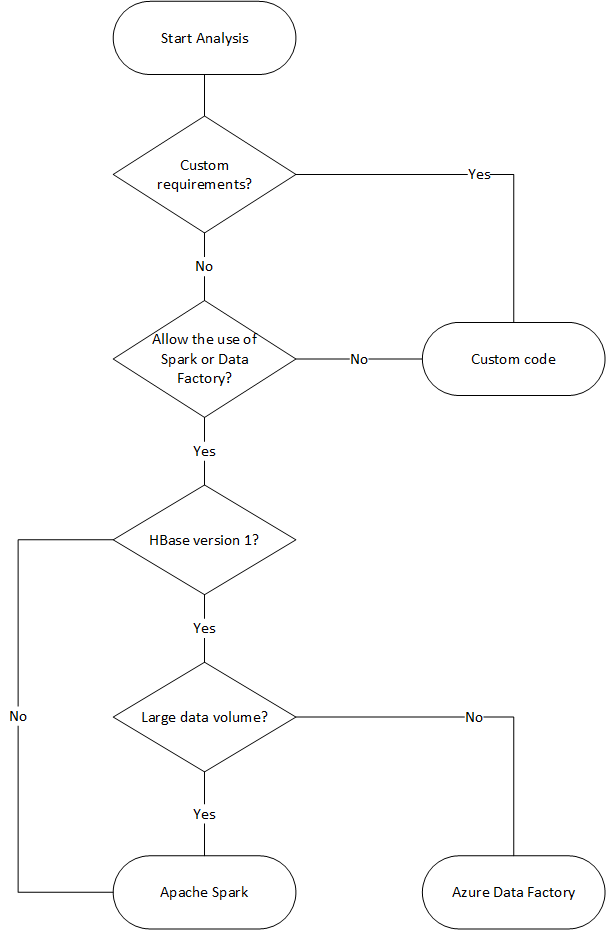
使用数据工厂进行迁移
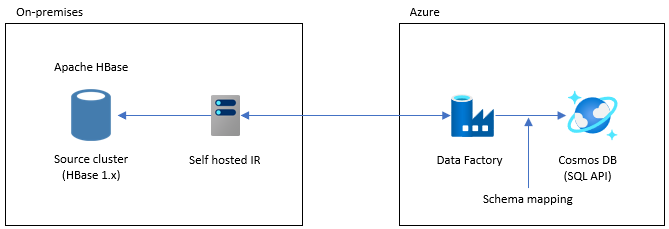
此选项适用于大型数据集。 使用 Azure Cosmos DB 批量执行程序库。 没有检查点,因此如果在迁移过程中遇到任何问题,则必须从头开始重启迁移过程。 还可以使用数据工厂的自托管集成运行时连接到您的内部 HBase,或者将数据工厂部署到托管虚拟网络,并通过 VPN 或 ExpressRoute 连接到您的内部网络。
数据工厂的复制活动支持 HBase 作为一种数据源。 有关更多详细信息,请参阅文章《使用 Azure Data Factory 从 HBase 复制数据》。
可以将 Azure Cosmos DB (API for NoSQL)指定为数据的目标。 有关详细信息,请参阅 使用 Azure Data Factory 复制和转换 Azure Cosmos DB(NoSQL 接口)中的数据的文章。
使用 Apache Spark 迁移 - Apache HBase 连接器 &Azure Cosmos DB Spark 连接器
下面是将数据迁移到 Azure Cosmos DB 的示例。 它假定 HBase 2.1.0 和 Spark 2.4.0 在同一群集中运行。
可以在
有关 Azure Cosmos DB Spark 连接器,请参阅 Quick Start Guide 并下载适用于 Spark 版本的相应库。
将 hbase-site.xml 复制到 Spark 配置目录。
cp /etc/hbase/conf/hbase-site.xml /etc/spark2/conf/使用 Spark HBase 连接器和 Azure Cosmos DB Spark 连接器运行 spark -shell。
spark-shell --packages com.hortonworks.shc:shc-core:1.1.0.3.1.2.2-1 --repositories http://repo.hortonworcontent/groups/public/ --jars azure-cosmosdb-spark_2.4.0_2.11-3.6.8-uber.jarSpark shell 启动后,按如下所示执行 Scala 代码。 导入从 HBase 加载数据所需的库。
// Import libraries import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.execution.datasources.hbase._ import org.apache.spark.{SparkConf, SparkContext} import spark.sqlContext.implicits._为 HBase 表定义 Spark 目录架构。 此处的命名空间为“default”,表名为“Contacts”。 行键被指定为主键。 列、列系列和列会映射到 Spark 的目录。
// define a catalog for the Contacts table you created in HBase def catalog = s"""{ |"table":{"namespace":"default", "name":"Contacts"}, |"rowkey":"key", |"columns":{ |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} |} |}""".stripMargin接下来,定义一个方法,以将 HBase Contacts 表中的数据获取为 DataFrame。
def withCatalog(cat: String): DataFrame = { spark.sqlContext .read .options(Map(HBaseTableCatalog.tableCatalog->cat)) .format("org.apache.spark.sql.execution.datasources.hbase") .load() }使用定义的方法创建 DataFrame。
val df = withCatalog(catalog)然后导入使用 Azure Cosmos DB Spark 连接器所需的库。
import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark._ import com.microsoft.azure.cosmosdb.spark.config.Config配置设置以将数据写入 Azure Cosmos DB。
val writeConfig = Config(Map( "Endpoint" -> "https://<cosmos-db-account-name>.documents.azure.cn:443/", "Masterkey" -> "<comsmos-db-master-key>", "Database" -> "<database-name>", "Collection" -> "<collection-name>", "Upsert" -> "true" ))将数据帧数据写入 Azure Cosmos DB。
import org.apache.spark.sql.SaveMode df.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
它以高速方式并行写入,其性能较高。 另一方面,请注意,它可能会消耗 Azure Cosmos DB 端的 RU/秒。
Phoenix
支持将 Phoenix 作为数据工厂数据源。 有关详细步骤,请参阅以下文档。
迁移您的代码
本部分介绍在用于 NoSQL 和 HBase 的 Azure Cosmos DB 中创建应用程序之间的差异。 此处的示例使用 Apache HBase 2.x API 和 Azure Cosmos DB Java SDK v4。
这些 HBase 的示例代码基于 HBase 的官方文档中所述的内容。
此处显示了代码迁移的映射,但这些示例中使用的 HBase RowKeys 和 Azure Cosmos DB 分区键并非总是设计得很好。 根据迁移源的实际数据模型进行设计。
建立连接
HBase
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","zookeepernode0,zookeepernode1,zookeepernode2");
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.cluster.distributed", "true");
Connection connection = ConnectionFactory.createConnection(config)
Phoenix
//Use JDBC to get a connection to an HBase cluster
Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333",props);
Azure Cosmos DB
// Create sync client
client = new CosmosClientBuilder()
.endpoint(AccountSettings.HOST)
.key(AccountSettings.MASTER_KEY)
.consistencyLevel(ConsistencyLevel.{ConsistencyLevel})
.contentResponseOnWriteEnabled(true)
.buildClient();
创建数据库/表/集合
HBase
// create an admin object using the config
HBaseAdmin admin = new HBaseAdmin(config);
// create the table...
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("FamilyTable"));
// ... with single column families
tableDescriptor.addFamily(new HColumnDescriptor("ColFam"));
admin.createTable(tableDescriptor);
Phoenix
CREATE IF NOT EXISTS FamilyTable ("id" BIGINT not null primary key, "ColFam"."lastName" VARCHAR(50));
Azure Cosmos DB
// Create database if not exists
CosmosDatabaseResponse databaseResponse = client.createDatabaseIfNotExists(databaseName);
database = client.getDatabase(databaseResponse.getProperties().getId());
// Create container if not exists
CosmosContainerProperties containerProperties = new CosmosContainerProperties("FamilyContainer", "/lastName");
// Provision throughput
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
// Create container with 400 RU/s
CosmosContainerResponse databaseResponse = database.createContainerIfNotExists(containerProperties, throughputProperties);
container = database.getContainer(databaseResponse.getProperties().getId());
创建行/文档
HBase
HTable table = new HTable(config, "FamilyTable");
Put put = new Put(Bytes.toBytes(RowKey));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes("1"));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Witherspoon"));
table.put(put)
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Witherspoon’);
Azure Cosmos DB
Azure Cosmos DB 通过数据模型提供类型安全性。 我们使用名为“Family”的数据模型。
public class Family {
public Family() {
}
public void setId(String id) {
this.id = id;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String id="";
private String lastName="";
}
上面是代码的一部分。 请参阅 full 代码示例。
使用 Family 类定义文档并插入项。
Family family = new Family();
family.setLastName("Witherspoon");
family.setId("1");
// Insert this item as a document
// Explicitly specifying the /pk value improves performance.
container.createItem(family,new PartitionKey(family.getLastName()),new CosmosItemRequestOptions());
读取行/文档
HBase
HTable table = new HTable(config, "FamilyTable");
Get get = new Get(Bytes.toBytes(RowKey));
get.addColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Result result = table.get(get);
byte[] col = result.getValue(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Phoenix
SELECT lastName FROM FamilyTable;
Azure Cosmos DB
// Read document by ID
Family family = container.readItem(documentId,new PartitionKey(documentLastName),Family.class).getItem();
String sql = "SELECT lastName FROM c";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
更新数据
HBase
对于 HBase,使用 append 方法和 checkAndPut 方法来更新值。 “追加”是一个以原子方式将值追加到当前值末尾的过程,而 checkAndPut 以原子方式将当前值与预期值进行比较,并仅在它们匹配时进行更新。
// append
HTable table = new HTable(config, "FamilyTable");
Append append = new Append(Bytes.toBytes(RowKey));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes(2));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Harris"));
Result result = table.append(append)
// checkAndPut
byte[] row = Bytes.toBytes(RowKey);
byte[] colfam = Bytes.toBytes("ColFam");
byte[] col = Bytes.toBytes("lastName");
Put put = new Put(row);
put.add(colfam, col, Bytes.toBytes("Patrick"));
boolearn result = table.checkAndPut(row, colfam, col, Bytes.toBytes("Witherspoon"), put);
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Brown’)
ON DUPLICATE KEY UPDATE id = "1", lastName = "Whiterspoon";
Azure Cosmos DB
在 Azure Cosmos DB 中,更新被视为 Upsert 操作。 也就是说,如果文档不存在,将插入该文档。
// Replace existing document with new modified document (contingent on modification).
Family family = new Family();
family.setLastName("Brown");
family.setId("1");
CosmosItemResponse<Family> famResp = container.upsertItem(family, new CosmosItemRequestOptions());
删除行/文档
HBase
在 Hbase 中,没有按值选择行的直接删除方法。 你可能已与 ValueFilter 等一起实现了删除过程。在此示例中,要删除的行通过 RowKey 指定。
HTable table = new HTable(config, "FamilyTable");
Delete delete = new Delete(Bytes.toBytes(RowKey));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("id"));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
table.dalate(delete)
Phoenix
DELETE FROM TableName WHERE id = "xxx";
Azure Cosmos DB
下面显示了按文档 ID 进行的删除方法。
container.deleteItem(documentId, new PartitionKey(documentLastName), new CosmosItemRequestOptions());
查询行/文档
HBase HBase 允许使用扫描检索多个行。 可以使用筛选器指定详细扫描条件。 请参阅客户端请求筛选器以了解 HBase 内置筛选器类型。
HTable table = new HTable(config, "FamilyTable");
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("ColFam"),
Bytes.toBytes("lastName"), CompareOp.EQUAL, New BinaryComparator(Bytes.toBytes("Witherspoon")));
filter.setFilterIfMissing(true);
filter.setLatestVersionOnly(true);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
Phoenix
SELECT * FROM FamilyTable WHERE lastName = "Witherspoon"
Azure Cosmos DB
筛选器操作
String sql = "SELECT * FROM c WHERE c.lastName = 'Witherspoon'";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
删除表/集合
HBase
HBaseAdmin admin = new HBaseAdmin(config);
admin.deleteTable("FamilyTable")
Phoenix
DROP TABLE IF EXISTS FamilyTable;
Azure Cosmos DB
CosmosContainerResponse containerResp = database.getContainer("FamilyContainer").delete(new CosmosContainerRequestOptions());
其他注意事项
HBase 群集可以与 HBase 工作负载以及 MapReduce、Hive、Spark 等一起使用。 如果具有使用当前 HBase 的其他工作负载,则也需要迁移它们。 有关详细信息,请参阅每个迁移指南。
- MapReduce
- HBase
- Spark
服务器端编程
HBase 提供多种服务器端编程功能。 如果使用这些功能,则还需要迁移其处理。
HBase
-
各种筛选器在 HBase 中作为默认设置提供,但你也可以实现自己的自定义筛选器。 如果 HBase 上作为默认设置提供的筛选器不符合要求,则可以实现自定义筛选器。
-
协处理器是一种框架,可用于在区域服务器上运行自己的代码。 通过使用协处理器,可以在服务器端执行在客户端上执行的处理,并且根据处理情况,可以提高效率。 有两种类型的协处理器:观察者和终结点。
观察者
- 观察者挂钩特定操作和事件。 这是用于添加任意处理的函数。 这是类似于 RDBMS 触发器的功能。
端点
- 终结点是用于扩展 HBase RPC 的一种功能。 此功能类似于 RDBMS 存储过程。
Azure Cosmos DB
-
- Azure Cosmos DB 存储过程是用 JavaScript 编写的,可以执行创建、更新、读取、查询和删除Azure Cosmos DB 容器中的项等作。
-
- 可以为针对数据库执行的操作指定触发器。 提供了两种方法:在数据库项更改之前运行的前触发器,以及在数据库项更改之后运行的后触发器。
-
- Azure Cosmos DB 允许定义用户定义函数(UDF)。 也可以用 JavaScript 编写 UDF。
存储过程和触发器根据所执行的操作的复杂性来消耗 RU。 开发服务器端处理时,请检查所需使用情况,以更好地了解每个操作消耗的 RU 量。 有关详细信息,请参阅 Azure Cosmos DB 中的 Request Units 和 优化请求成本。
服务器端编程映射
| HBase | Azure Cosmos DB | Description |
|---|---|---|
| 自定义筛选器 | WHERE 子句 | 如果自定义筛选器实现的处理不能由 Azure Cosmos DB 中的 WHERE 子句实现,请结合使用 UDF。 |
| 协处理器(观察者) | Trigger | 观察者是在特定事件之前和之后执行的触发器。 正如 Observer 支持预调用和后调用一样,Azure Cosmos DB 的触发器也支持预触发和后触发。 |
| 协处理器(终结点) | 存储过程 | 终结点是对每个区域执行的服务器端数据处理机制。 这类似于 RDBMS 存储过程。 Azure Cosmos DB 存储过程是使用 JavaScript 编写的。 它提供通过存储过程访问 Azure Cosmos DB 的所有操作。 |
注释
根据 HBase 上实现的处理,Azure Cosmos DB 可能需要不同的映射和实现。
安全性
数据安全性的责任由客户和数据库提供程序共同分担。 对于本地解决方案,客户必须提供从终结点保护到物理硬件安全性的所有工作,这不是一个轻松的任务。 如果选择 PaaS 云数据库提供程序(如 Azure Cosmos DB),客户参与将减少。 Azure Cosmos DB 在 Azure 平台上运行,因此它可以以不同于 HBase 的方式进行增强。 Azure Cosmos DB 不需要安装任何额外的组件,以确保安全性。 建议考虑使用以下清单迁移数据库系统安全实现:
| 安全控制 | HBase | Azure Cosmos DB |
|---|---|---|
| 网络安全和防火墙设置 | 使用网络设备等安全功能控制流量。 | 支持入站防火墙上基于策略和IP的访问控制。 |
| 用户身份验证和精细用户控制 | 通过将 LDAP 与 Apache Ranger 等安全组件组合使用,实现精细访问控制。 | 可使用帐户主密钥为每个数据库创建用户和权限资源。 还可以使用Microsoft Entra ID对数据请求进行身份验证。 这使你可以使用精细 RBAC 模型向数据请求授权。 |
| 能够在多个区域复制数据来应对区域性故障 | 使用 HBase 的复制在远程数据中心创建数据库副本。 | Azure Cosmos DB 执行无配置的多区域分发,并允许通过单击按钮将数据复制到 Azure 中的中国各地的数据中心。 在安全性方面,多区域复制可确保数据免受本地故障影响。 |
| 能够从一个数据中心故障转移到另一个数据中心 | 你需要自己实现故障转移。 | 如果将数据复制到多个数据中心,而某一地区的数据中心离线,Azure Cosmos DB 会自动接管操作。 |
| 在数据中心内进行本地数据复制 | HDFS 机制允许在单个文件系统中跨节点创建多个副本。 | Azure Cosmos DB 会自动复制数据以保持高可用性,即使在单个数据中心内也是如此。 可以自己选择一致性级别。 |
| 自动数据备份 | 没有自动备份功能。 你需要自己实现数据备份。 | Azure Cosmos DB 会定期备份并存储在异地冗余storage中。 |
| 保护和隔离敏感数据 | 例如,如果使用 Apache Ranger,则可使用 Ranger 策略将策略应用到表。 | 可以将个人和其他敏感数据分开到特定的容器中,以及读取/写入,或将只读access限制为特定用户。 |
| 监控潜在攻击 | 此行为需使用第三方产品来实现。 | 使用审核日志和活动日志,可以监视帐户中的正常和异常活动。 |
| 响应攻击 | 此行为需使用第三方产品来实现。 | 联系Azure support并报告潜在攻击时,将开始执行五步事件响应过程。 |
| 能够为数据设定虚拟地理围栏,以遵守数据治理限制 | 你需要检查每个国家或地区的限制,并亲自实施这些限制。 | 保证对德国、中国、美国政府等主权区域的数据治理。 |
| 对受保护数据中心内的服务器实施物理保护 | 这取决于系统所在的数据中心。 | 有关最新认证的列表,请参阅多区域Azure合规性站点。 |
| 认证 | 取决于 Hadoop 发行版。 | 请参阅 Azure 合规性文档 |
监测
HBase 通常使用群集指标 Web UI 或是使用 Ambari、Cloudera Manager 或其他监视工具监视群集。 Azure Cosmos DB 允许使用内置于 Azure 平台中的监视机制。 有关 Azure Cosmos DB 监视的详细信息,请参阅 Monitor Azure Cosmos DB。
如果环境实现 HBase 系统监视来发送警报,例如通过电子邮件发送警报,则可以将其替换为 Azure Monitor 警报。 可以根据Azure Cosmos DB 帐户的指标或活动日志事件接收警报。
有关 Azure Monitor 中的警报的详细信息,请参阅 使用 Azure Monitor 为 Azure Cosmos DB 创建警报
另请参阅 Azure Cosmos DB 指标和日志类型,这些指标可由 Azure Monitor 收集。
备份和灾难恢复
备份
可通过多种方法获取 HBase 的备份。 例如,快照、导出、CopyTable、HDFS 数据的脱机备份和其他自定义备份。
Azure Cosmos DB 定期自动备份数据,这不会影响数据库作的性能或可用性。 备份存储在Azure storage中,并可用于根据需要恢复数据。 Azure Cosmos DB 备份有两种类型:
灾难恢复
HBase 是容错分布式系统,但是如果在数据中心级别发生故障时,备份位置需要故障转移,则必须使用快照、复制等实现灾难恢复。 可以采用三种复制模式设置 HBase 复制:“领导者-追随者”、“领导者-领导者”和“循环”。 如果源 HBase 实现了灾难恢复,则需要了解如何在 Azure Cosmos DB 中配置灾难恢复并满足系统要求。
Azure Cosmos DB 是具有内置灾难恢复功能的多区域分布式数据库。 可以将 DB 数据复制到任何Azure区域。 Azure Cosmos DB 使数据库在某些区域发生故障的可能性不大的情况下保持高度可用。
Azure仅使用单个区域的 Cosmos DB 帐户可能会在发生区域故障时失去可用性。 建议至少配置两个区域,以始终确保高可用性。 还可以通过配置 Azure Cosmos DB 帐户来确保写入和读取的高可用性,以跨越具有多个写入区域的至少两个区域,以确保写入和读取的高可用性。 对于由多个写入区域组成的多区域帐户,Azure Cosmos DB 客户端检测和处理区域之间的故障转移。 这些是暂时的,不需要对应用程序进行任何更改。 这样,便可以实现可用性配置,其中包括用于 Azure Cosmos DB 的灾难恢复。 如前所述,可以使用三个模型设置 HBase 复制,但可以通过配置单写入和多写入区域,来设置基于 SLA 的可用性的 Azure Cosmos DB。
有关高可用性的详细信息,请参阅 Azure Cosmos DB 如何提供高可用性
常见问题
为什么迁移到 Azure Cosmos DB 中的 NOSQL API 而不是其他 API?
API for NoSQL 在接口和服务 SDK 客户端库方面提供最佳的端到端体验。 推出到 Azure Cosmos DB 的新功能将首先在 API for NoSQL 帐户中使用。 此外,API for NoSQL 支持分析,并在生产和分析工作负载之间提供性能隔离。 如果要使用现代化技术来生成应用,API for NoSQL 则是建议选项。
是否可以将 HBase RowKey 分配到 Azure Cosmos DB 分区键?
它现在可能还没有得到优化。 在 HBase 中,数据按指定 RowKey 进行排序,存储在区域中,并划分为固定大小。 这与 Azure Cosmos DB 中的分区不同。 因此,需要重新设计密钥,以根据工作负载的特征更好地分布数据。 请参阅分布部分以了解更多详细信息。
数据按 HBase 中的 RowKey 排序,但按 Azure Cosmos DB 中的键进行分区。 Azure Cosmos DB 如何实现排序和并置?
在 Azure Cosmos DB 中,可以添加复合索引以升序或降序对数据进行排序,以提高相等查询和范围查询的性能。 请参阅产品文档中的分布部分和组合索引。
用户如何在 HBase 和 Azure Cosmos DB 中使用时间戳查询?
Azure Cosmos DB 没有与 HBase 完全相同的时间戳版本控制功能。 但是,Azure Cosmos DB 提供了访问更改馈送的功能,并且可以利用它进行版本控制。
将每个版本/更改存储为单独项。
读取更改日志,合并和整合更改,然后通过“_ts”字段筛选以在下游触发相应操作。 此外,对于旧版本的数据,可以使用 TTL 使旧版本过期。
后续步骤
若要优化代码,请参阅 Cosmos DB Azure性能提示一文。
浏览 Java Async V3 SDK,SDK 参考 GitHub 仓库。