本文介绍如何从 Azure Databricks 连接 Azure Cosmos DB MongoDB vCore。 它演示了使用 Python 代码进行读取、筛选、SQL 查询、聚合管道操作和写入表等基本数据操作语言(DML)操作。
先决条件
- 配置 Azure Cosmos DB for MongoDB vCore 群集。
- 预配所选的 Spark 环境 Azure Databricks。
为连接配置依赖项
以下是从 Azure Databricks 连接到 Azure Cosmos DB for MongoDB vCore 所需的依赖项:
-
用于 MongoDB 的 Spark 连接器 Spark 连接器用于连接到 Azure Cosmos DB for MongoDB vCore。 请识别并使用 Maven 中心内与 Spark 环境的 Spark 和 Scala 版本兼容的连接器版本。 建议使用支持 Spark 3.2.1 或更高版本的环境,并且 Spark 连接器在 maven 坐标
org.mongodb.spark:mongo-spark-connector_2.12:3.0.1上可用。 - 用于 MongoDB 的 Azure Cosmos DB 连接字符串: 用于 MongoDB vCore 的 Azure Cosmos DB 连接字符串、用户名和密码。
预配 Azure Databricks 工作区
您可以按照说明来预配 Azure Databricks 工作区。 可以使用可用的默认 计算或创建新的计算资源 来运行笔记本。 请务必选择至少支持 Spark 3.0 的 Databricks 运行时。
添加依赖项
将 MongoDB Connector for Spark 库添加到计算资源中,以便连接至本机 MongoDB 和 Azure Cosmos DB for MongoDB 终结点。 在计算中,选择“ 库>安装新>Maven”,然后添加 org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 Maven 坐标。
选择 “安装”,然后在安装完成后重启计算。
注释
请确保在安装了用于 Spark 的 MongoDB 连接器库后重启 Databricks 计算。
之后,可以创建 Scala 或 Python 笔记本进行迁移。
创建 Python 笔记本以连接到 Azure Cosmos DB for MongoDB vCore
在 Databricks 中创建 Python 笔记本。 在运行以下代码之前,请确保输入变量的正确值。
使用 Azure Cosmos DB for MongoDB 连接字符串更新 Spark 配置
- 请注意 Azure 门户中 Azure Cosmos DB MongoDB vCore 资源中的“设置 ->连接字符串”下的连接字符串。 其形式为“mongodb+srv://<user>:<password>@<database_name>.mongocluster.cosmos.azure.com”
- 返回到 Databricks 的计算配置中,在页面底部的 高级选项 下,粘贴适用于
spark.mongodb.output.uri和spark.mongodb.input.uri变量的连接字符串。 填充相应的用户名和密码字段。 这样,所有在计算上运行的工作簿都使用此配置。 - 或者,在调用 API 时,可以显式设置
option,例如:spark.read.format("mongo").option("spark.mongodb.input.uri", connectionString).load()。 如果在群集中配置变量,则无需设置该选项。
connectionString_vcore="mongodb+srv://<user>:<password>@<database_name>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
database="<database_name>"
collection="<collection_name>"
数据样本集
在本实验室中,我们将使用 CSV“Citibike2019”数据集。 可以导入:CitiBike 行程历史记录 2019。 我们已将其加载到名为“CitiBikeDB”的数据库和集合“CitiBike2019”。 我们将变量数据库和集合设置为指向加载的数据,并在示例中使用变量。
database="CitiBikeDB"
collection="CitiBike2019"
从 Azure Cosmos DB for MongoDB vCore 读取数据
常规语法看起来像这样:
df_vcore = spark.read.format("mongo").option("database", database).option("spark.mongodb.input.uri", connectionString_vcore).option("collection",collection).load()
可以验证加载的数据帧,如下所示:
df_vcore.printSchema()
display(df_vcore)
请看以下示例:
df_vcore = spark.read.format("mongo").option("database", database).option("spark.mongodb.input.uri", connectionString_vcore).option("collection",collection).load()
df_vcore.printSchema()
display(df_vcore)
输出:

DataFrame
从 Azure Cosmos DB for MongoDB vCore 筛选数据
常规语法看起来像这样:
df_v = df_vcore.filter(df_vcore[column number/column name] == [filter condition])
display(df_v)
请看以下示例:
df_v = df_vcore.filter(df_vcore[2] == 1970)
display(df_v)
输出: 
创建视图或临时表并对其运行 SQL 查询
常规语法看起来像这样:
df_[dataframename].createOrReplaceTempView("[View Name]")
spark.sql("SELECT * FROM [View Name]")
请看以下示例:
df_vcore.createOrReplaceTempView("T_VCORE")
df_v = spark.sql(" SELECT * FROM T_VCORE WHERE birth_year == 1970 and gender == 2 ")
display(df_v)
输出: 
将数据写入 Azure Cosmos DB for MongoDB vCore
常规语法看起来像这样:
df.write.format("mongo").option("spark.mongodb.output.uri", connectionString).option("database",database).option("collection","<collection_name>").mode("append").save()
请看以下示例:
df_vcore.write.format("mongo").option("spark.mongodb.output.uri", connectionString_vcore).option("database",database).option("collection","CitiBike2019").mode("append").save()
此命令没有输出,因为它直接写入集合。 可以使用读取命令交叉检查记录是否已更新。
从运行聚合管道的 Azure Cosmos DB for MongoDB vCore 集合中读取数据
[!注意] 聚合管道 是一项功能强大的功能,可用于预处理和转换 Azure Cosmos DB for MongoDB 中的数据。 它非常适合实时分析、仪表板、报表生成和汇总,进行求和和平均值计算,并对服务器端数据进行后处理。 (注意:有一本 关于它的书)。
Azure Cosmos DB for MongoDB 甚至支持 丰富的辅助/复合索引 来提取、筛选和处理它所需的数据。
例如,分析数据库中位于特定地理位置中的所有客户,而无需首先加载完整的数据集,尽量减少数据移动和降低延迟。
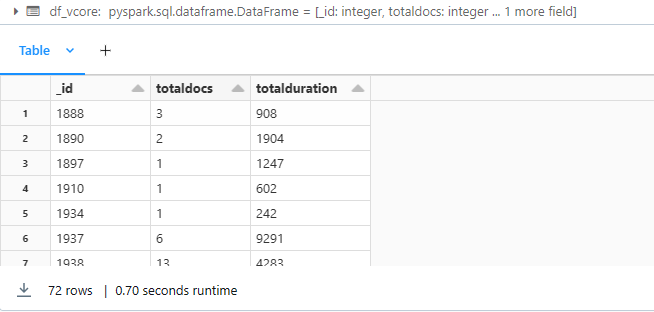
下面是使用聚合函数的示例:
pipeline = "[{ $group : { _id : '$birth_year', totaldocs : { $count : 1 }, totalduration: {$sum: '$tripduration'}} }]"
df_vcore = spark.read.format("mongo").option("database", database).option("spark.mongodb.input.uri", connectionString_vcore).option("collection",collection).option("pipeline", pipeline).load()
display(df_vcore)
输出:
相关内容
以下文章演示如何在 Azure Cosmos DB for MongoDB vCore 中使用聚合管道: