重要
这是 不是适用于 Azure Cosmos DB 的最新 Java SDK! 应将project升级到 Azure Cosmos DB Java SDK v4,然后阅读 Azure Cosmos DB Java SDK v4 性能提示指南。 按照 "迁移到 Azure Cosmos DB Java SDK v4" 指南 中的说明和 "Reactor 与 RxJava" 指南 进行升级。
这些性能提示仅适用于 Azure Cosmos DB Sync Java SDK v2。 有关详细信息,请查看 Maven 存储库。
重要
2024 年 2 月 29 日,Azure Cosmos DB Sync Java SDK v2.x 将停用;SDK 和所有使用 SDK
Azure Cosmos DB 是一个快速灵活的分布式数据库,可无缝缩放,并保证延迟和吞吐量。 无需进行重大体系结构更改或编写复杂的代码,才能使用 Azure Cosmos DB 缩放数据库。 扩展和缩减操作就像执行单个 API 调用一样简单。 若要了解详细信息,请参阅 如何预配容器吞吐量 或 如何预配数据库吞吐量。 但是,由于Azure Cosmos DB 是通过网络调用访问的,因此可以通过客户端优化在使用 Azure Cosmos DB Sync Java SDK v2 时实现最佳性能。
因此,如果询问“如何提高数据库性能?”,请考虑以下选项:
网络
连接模式:使用 DirectHttps
客户端如何连接到 Azure Cosmos DB 对性能有重要影响,尤其是在观察到的客户端延迟方面。 有一个关键配置设置可用于配置客户端 ConnectionPolicy — ConnectionMode。 两种可用的 ConnectionModes 为:
-
所有 SDK 平台上都支持网关模式,并且是配置的默认值。 如果应用程序在具有严格防火墙限制的企业网络中运行,则网关是最佳选择,因为它使用标准 HTTPS 端口和单个终结点。 但是,性能权衡在于,每次读取或写入到 Azure Cosmos DB 的数据时,网关模式都会涉及额外的网络跃点。 因此,DirectHttps 模式提供更好的性能,因为网络跃点较少。
Azure Cosmos DB 同步 Java SDK v2 使用 HTTPS 作为传输协议。 HTTPS 使用 TLS 进行初始身份验证和加密流量。 使用 Azure Cosmos DB Sync Java SDK v2 时,只需打开 HTTPS 端口 443。
在构造 DocumentClient 实例期间,通过 ConnectionPolicy 参数配置 ConnectionMode。
同步 Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
public ConnectionPolicy getConnectionPolicy() { ConnectionPolicy policy = new ConnectionPolicy(); policy.setConnectionMode(ConnectionMode.DirectHttps); policy.setMaxPoolSize(1000); return policy; } ConnectionPolicy connectionPolicy = new ConnectionPolicy(); DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);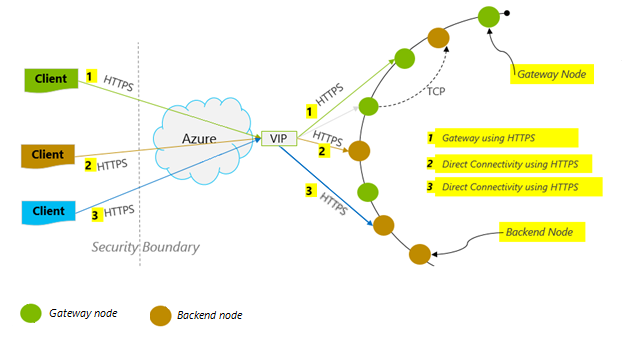
在同一Azure区域中部署客户端以提升性能
如果可能,请将调用 Azure Cosmos DB 的任何应用程序放置在与 Azure Cosmos DB 数据库相同的区域中。 此延迟可能会因请求而异,具体取决于请求在从客户端传递到Azure数据中心边界时所采用的路由。 通过确保调用应用程序位于与已配置的 Azure Cosmos DB 端点在同一 Azure 区域中,实现最低的延迟。 有关可用区域的列表,请参阅 Azure Regions。
图表显示两个区域中的请求和响应,计算机通过中间层服务连接到 Azure Cosmos DB 帐户。
SDK 用法
安装最新的 SDK
Azure Cosmos DB SDK 不断改进,以提供最佳性能。 若要确定最新的 SDK 改进,请访问 Azure Cosmos DB SDK。
在应用程序的生命周期内使用单例 Azure Cosmos DB 客户端
每个 DocumentClient 实例都是线程安全的,在直接模式下运行时执行高效的连接管理和地址缓存。 若要通过 DocumentClient 实现高效的连接管理和更好的性能,建议在应用程序的生存期内使用 DocumentClient per AppDomain 的单个实例。
使用网关模式时增加每个主机的 MaxPoolSize
使用网关模式时,Azure Cosmos DB 请求是通过 HTTPS/REST 发出的,并且受每个主机名或 IP 地址的默认连接限制的约束。 可能需要将 MaxPoolSize 设置为更高的值(200-1000),以便客户端库可以利用多个同时连接到 Azure Cosmos DB。 在 Azure Cosmos DB Sync Java SDK v2 中,ConnectionPolicy.getMaxPoolSize的默认值为 100。 使用 setMaxPoolSize 更改值。
优化已分区集合的并行查询
Azure Cosmos DB Sync Java SDK 版本 1.9.0 及更高版本支持并行查询,这使你可以并行查询分区集合。 有关详细信息,请参阅与使用 SDK 相关的代码示例。 并行查询旨在与串行查询相比,改善查询的延迟和吞吐量。
(a) 优化 setMaxDegreeOfParallelism: 并行查询的工作原理是并行查询多个分区。 但是,对于查询,会按顺序提取单个分区集合中的数据。 因此,使用 setMaxDegreeOfParallelism 设置具有最高性能查询机会的分区数,前提是所有其他系统条件保持不变。 如果不知道分区数,则可以使用 setMaxDegreeOfParallelism 设置高数字,并且系统选择最小(分区数、用户提供的输入)作为最大并行度。
请务必注意,如果数据在查询的所有分区之间均匀分布,并行查询将产生最佳优势。 如果分区集合的方式导致查询返回的所有或大部分数据集中在少数几个分区(最坏情况下为单个分区),那么查询的性能将受到这些分区的制约。
(b) 优化 setMaxBufferedItemCount: 并行查询旨在预提取结果,同时客户端正在处理当前批结果。 预提取有助于降低查询的总体延迟。 setMaxBufferedItemCount 限制预提取的结果数。 通过将 setMaxBufferedItemCount 设置为返回的结果的预期数量(或更高的数字),这使查询能够从预提取中获得最大好处。
预提取的工作方式与 MaxDegreeOfParallelism 无关,并且所有分区的数据共用一个缓冲区。
在 getRetryAfterInMilliseconds 的间隔时间内实现退避
在性能测试期间,应增加负载,直到小部分请求被限制。 如果遭遇节流,客户端应用程序应在服务器指定的重试间隔内退避。 恪守退避策略可确保在重试之间将等待时间最小化。 重试策略支持包含在 Azure Cosmos DB Sync Java SDK 的版本 1.8.0 及更高版本中。 有关详细信息,请参阅 getRetryAfterInMilliseconds。
横向扩展您的客户端工作负载
如果要在高吞吐量级别(>50,000 RU/秒)进行测试,客户端应用程序可能会成为瓶颈,因为计算机在 CPU 或网络利用率上达到上限。 如果达到此目标,可以通过将客户端应用程序分布到多个服务器上,进一步提升和优化 Azure Cosmos DB 帐户的性能。
使用基于名称的寻址
使用基于名称的寻址,其中链接格式为
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId,而不是采用格式dbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>的自链接(_self),这样可以避免检索构建链接所需的所有资源的 ResourceId。 此外,由于这些资源重新创建(可能使用相同的名称),因此缓存这些资源可能无济于事。优化查询/读取源的页面大小以提高性能
使用批量读取功能(例如,readDocuments)或发出 SQL 查询时,如果结果集过大,则以分段方式返回结果。 默认情况下,结果以 100 个项目或 1 MB 为一组返回,具体取决于先达到哪个限制。
若要减少检索所有适用结果所需的网络往返次数,可以使用 x-ms-max-item-count 请求标头将页面大小增加到最多 1000。 如果需要仅显示几个结果,例如,如果用户界面或应用程序 API 一次只返回 10 个结果,则还可以将页面大小减少到 10,以减少读取和查询使用的吞吐量。
还可以使用 setPageSize 方法设置页面大小。
索引策略
从索引中排除未使用的路径以加快写入速度
Azure Cosmos DB 的索引策略允许你通过使用索引路径(setIncludedPaths 和 setExcludedPaths)指定要包含或排除索引的文档路径。 使用索引路径可以为事先已知查询模式的场景提供提升的写入性能和较低的索引存储,因为索引成本与索引的唯一路径数直接相关。 例如,下面的代码演示如何使用“*”通配符从索引中排除文档的整个节(子树)。
同步 Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);有关详细信息,请参阅 Azure Cosmos DB 索引策略。
吞吐量
测量和调整以减少每秒请求单位的使用量
Azure Cosmos DB 提供了一组丰富的数据库操作,包括使用 UDF、存储过程和触发器的关系查询和分层查询 - 所有操作都在数据库集合中的文档上运行。 与这些操作关联的成本取决于完成操作所需的 CPU、IO 和内存。 与考虑和管理硬件资源不同的是,可以考虑将请求单位 (RU) 作为所需资源的单个措施,以执行各种数据库操作和服务应用程序请求。
吞吐量是基于为每个容器设置的请求单位数量预配的。 请求单位消耗以每秒速率评估。 如果应用程序的速率超过了为其容器预配的请求单位速率,则会受到限制,直到该速率降到容器的预配级别以下。 如果应用程序需要较高级别的吞吐量,可以通过预配更多请求单位来增加吞吐量。
查询的复杂性会影响操作使用的请求单位数量。 谓词数、谓词性质、UDF 数目和源数据集的大小都会影响查询操作的成本。
测量任何操作的开销(创建、更新或删除),可以通过检查 x-ms-request-charge 标头,或 ResourceResponse<T> 中的 RequestCharge 属性、FeedResponse<T> 来评估这些操作消耗的请求单位数。
同步 Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
ResourceResponse<Document> response = client.createDocument(collectionLink, documentDefinition, null, false); response.getRequestCharge();在此标头中返回的请求费用是您预设吞吐量的一小部分。 例如,如果预配了 2000 RU/秒,并且上述查询返回 1,000 1KB 文档,则作成本为 1000。 因此在一秒内,服务器在对后续请求进行速率限制之前,只接受两个此类请求。 有关详细信息,请参阅 请求单位 和 请求单位计算器。
处理速率限制/请求速率太大
客户端尝试超过帐户保留的吞吐量时,服务器的性能不会降低,并且不会使用超过保留级别的吞吐量容量。 服务器将抢先结束 RequestRateTooLarge(HTTP 状态代码 429)的请求并返回 x-ms-retry-after-ms 标头,该标头指示重新尝试请求前用户必须等待的时间量(以毫秒为单位)。
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100SDK 全部都会隐式捕获此响应,并遵循服务器指定的 retry-after 标头,并重试请求。 除非多个客户端同时访问帐户,否则下次重试就会成功。
如果有多个客户端累积运行一致高于请求速率,则客户端当前在内部设置为 9 的默认重试计数可能不足以满足以下要求:在这种情况下,客户端会向应用程序引发状态代码为 429 的 DocumentClientException。 在 ConnectionPolicy 实例上使用 setRetryOptions 可以更改默认重试计数。 默认情况下,如果请求继续运行高于请求速率,则状态代码为 429 的 DocumentClientException 在累积等待时间 30 秒后返回。 即使当前的重试计数小于最大重试计数(默认值 9 或用户定义的值),也会发生这种情况。
尽管自动重试行为有助于改善大多数应用程序的复原能力和可用性,但是在执行性能基准测试时可能会造成冲突(尤其是在测量延迟时)。 如果实验触发服务器节流并导致客户端 SDK 自动重试,则客户端观测到的延迟会剧增。 为了避免性能实验期间出现延迟高峰,应评估每个操作返回的费用,并确保请求在低于预定请求速率的水平下运行。 有关详细信息,请参阅请求单位。
针对小型文档进行设计以提高吞吐量
给定操作的请求费用(请求处理成本)与文档大小直接相关。 大型文档的操作成本高于小型文档的操作成本。
后续步骤
若要详细了解如何设计应用程序以进行缩放和达到高性能,请参阅 Azure Cosmos DB 中的分区和缩放。