适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Azure Data Lake Storage Gen2是一组专用于大数据分析的功能,内置于 Azure Blob 存储中。 它可使用文件系统和对象存储范例与数据进行交互。
Azure Data Factory(ADF)是一项完全托管的基于云的数据集成服务。 通过该服务,可使用丰富的本地数据存储和基于云的数据存储中的数据填充数据湖,并更快速地生成分析解决方案。 若要查看受支持的连接器的详细列表,请参阅支持的数据存储表。
Azure Data Factory提供托管的横向扩展数据移动解决方案。 得益于 ADF 的横向扩展体系结构,它能以较高的吞吐量引入数据。 有关详细信息,请参阅 复制活动性能。
本文介绍如何使用数据工厂复制数据工具将数据从 Amazon Web Services S3 服务加载到 Azure Data Lake Storage Gen2。 可以遵循类似步骤,从其他类型的数据存储中复制数据。
先决条件
- Azure订阅:如果没有Azure订阅,请在开始前创建试用帐户。
- Azure Storage 帐户已启用 Data Lake Storage Gen2。如果你没有存储帐户,请创建一个帐户。
- AWS 帐户与一个包含数据的 S3 存储桶:本文介绍如何从 Amazon S3 复制数据。 可以按类似步骤使用其他数据存储。
创建数据工厂
如果尚未创建数据工厂,请按照 Quickstart:使用 Azure 门户和 Azure Data Factory Studio 创建数据工厂创建一个数据工厂。 创建后,导航到 Azure 门户中的数据工厂。
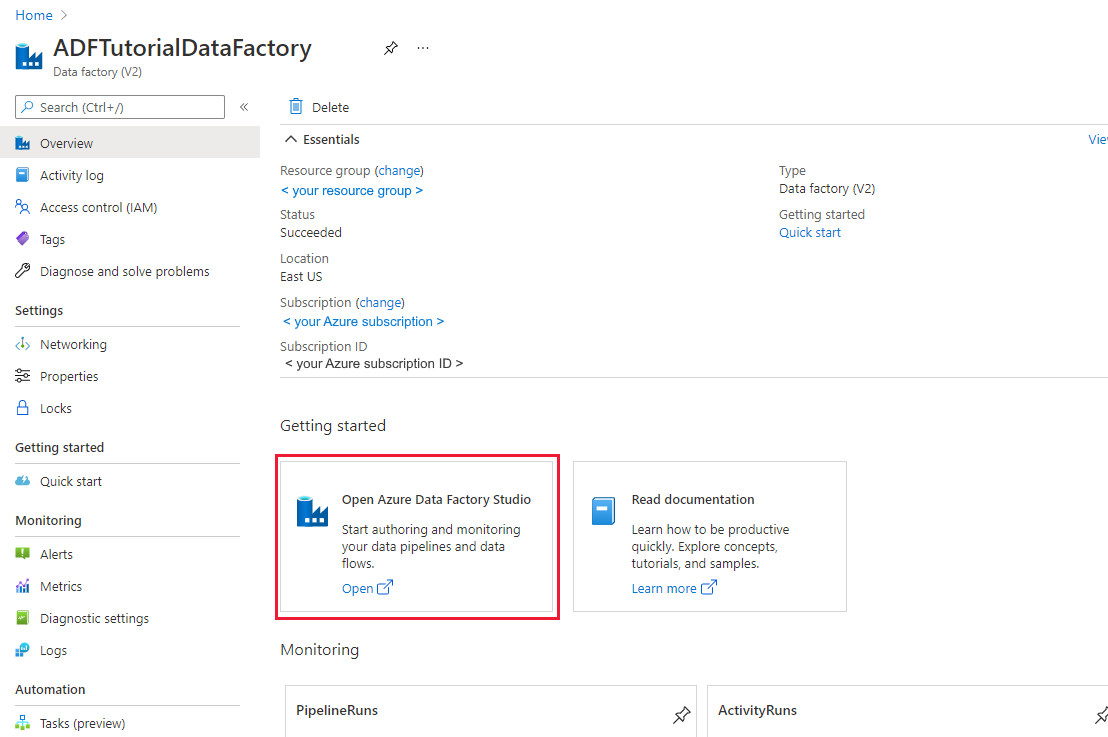
在 Open Azure Data Factory Studio 磁贴上选择 Open,以在单独的选项卡中启动数据集成应用程序。
将数据加载到Azure Data Lake Storage Gen2
在Azure Data Factory主页中,选择引入磁贴以启动复制数据工具。
在“属性”页中,在“任务类型”下选择“内置复制任务”,在“任务节奏或任务计划”下选择“现在运行一次”,然后选择“下一页”。
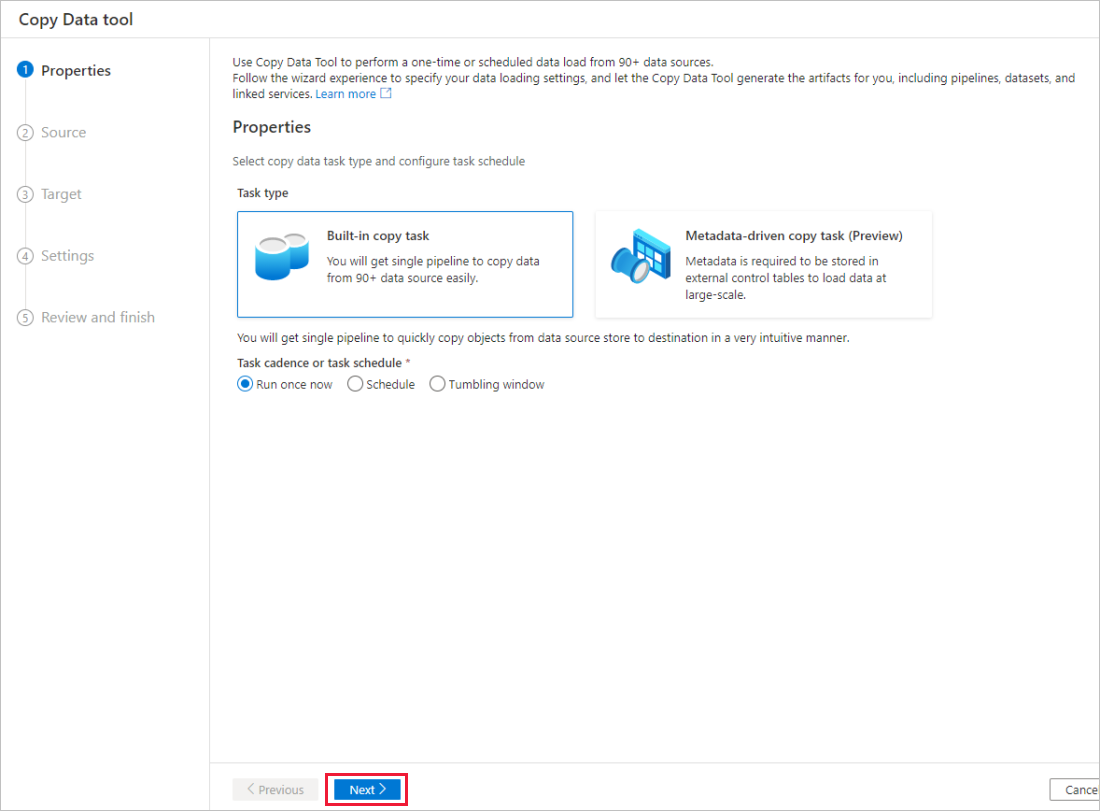
在“源数据存储”页上,完成以下步骤:
选择“+ 新建连接”。 从连接器库中选择“Amazon S3”,然后选择“继续” 。

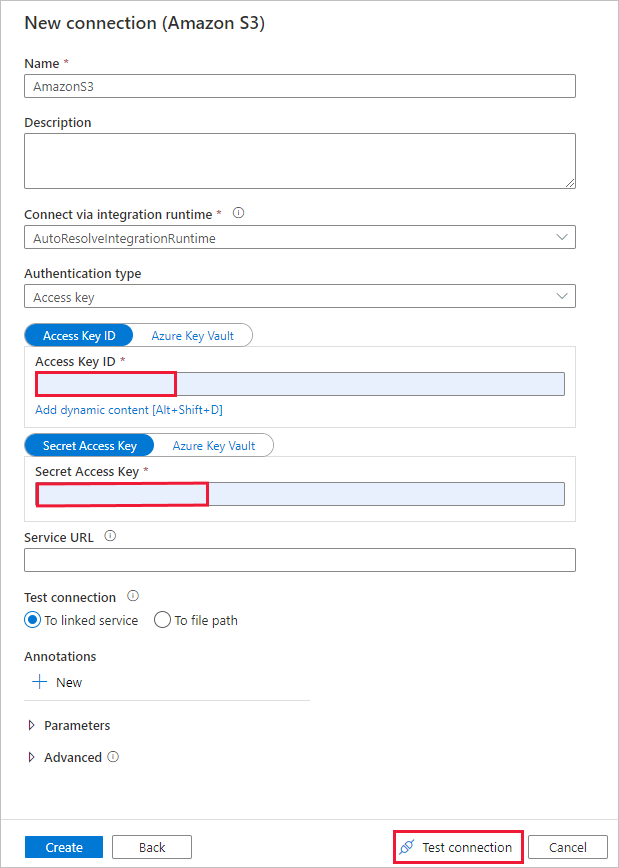
在“新建连接 (Amazon S3)”页中,执行以下步骤:
- 指定“访问密钥 ID”值。
- 指定“机密访问密钥”值。
- 选择“测试连接”以验证设置,然后选择“创建” 。
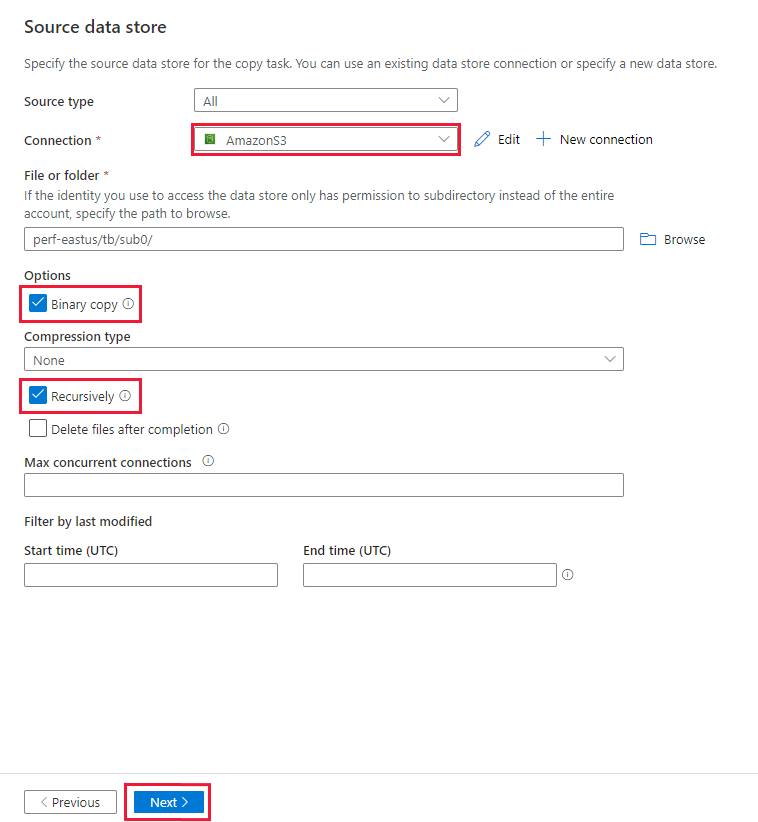
在“源数据存储”页上,确保新创建的 Amazon S3 连接在“连接”块中处于选中状态。
在“文件或文件夹”部分中,浏览到要复制的文件夹和文件。 选中文件夹/文件,然后选择“确定”。
通过选中“以递归方式”和“以二进制方式复制”选项,指定复制行为 。 选择“下一步”。
在“目标数据存储”页上,完成以下步骤。
选择 + 新建连接,然后选择 Azure Data Lake Storage Gen2,然后选择 Continue。
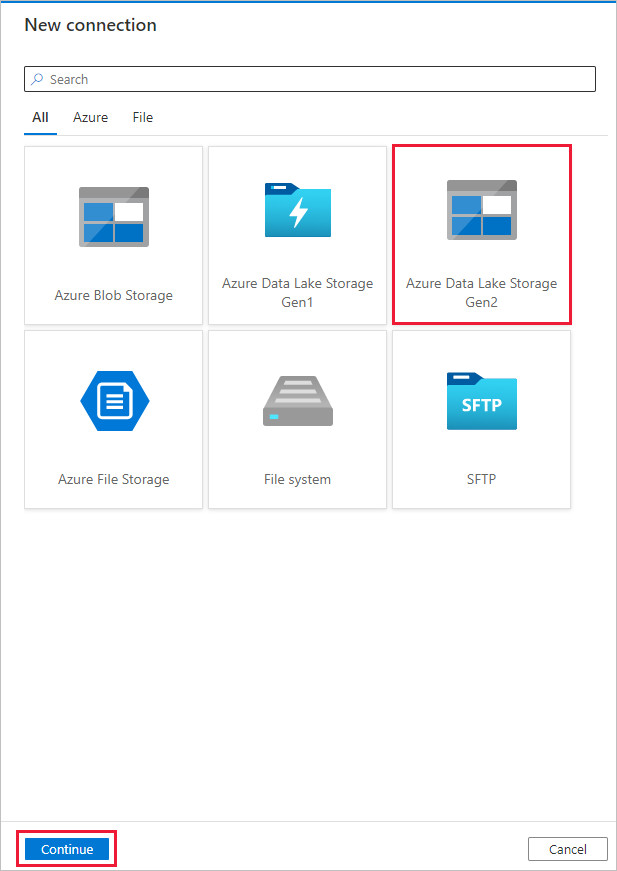
在“新建连接(Azure Data Lake Storage Gen2)页中,从”存储帐户名称“下拉列表中选择支持Data Lake Storage Gen2的帐户,然后选择Create来创建连接。
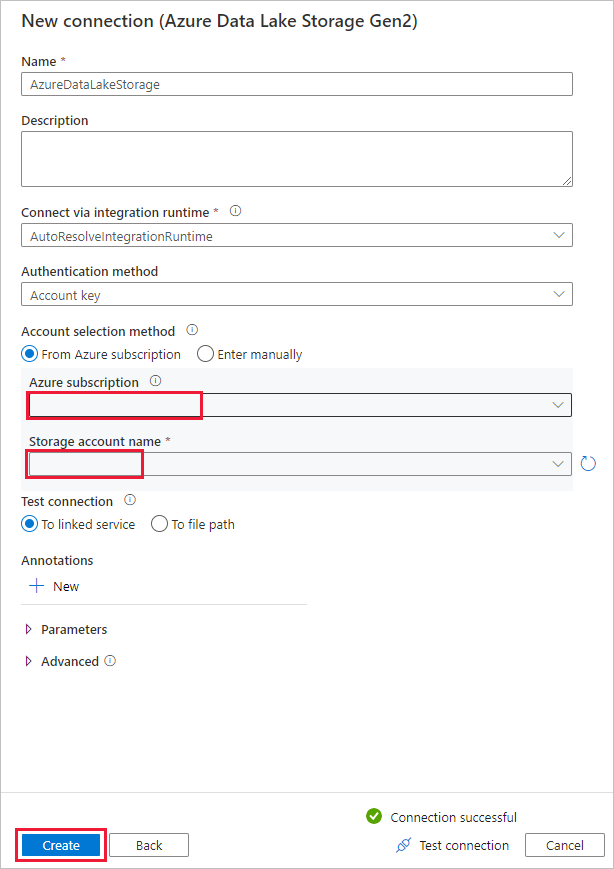
在“目标数据存储”上的“连接”块中选择新创建的连接 。 然后在“文件夹路径”下,输入“copyfroms3”作为输出文件夹名称,然后选择“下一步”。 ADF 将在复制过程中创建相应的 ADLS Gen2 文件系统和子文件夹(如果不存在)。
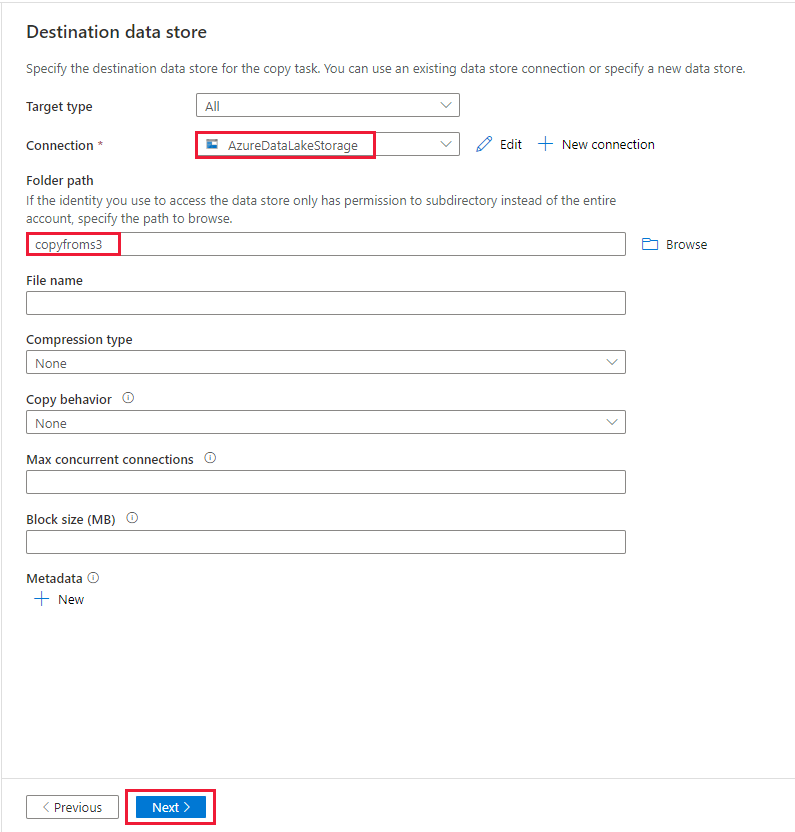
在“设置”页中,为“任务名称”字段指定“CopyFromAmazonS3ToADLS”,然后选择“下一步”,以使用默认设置。
在“摘要”页中检查设置,然后选择“下一步”。
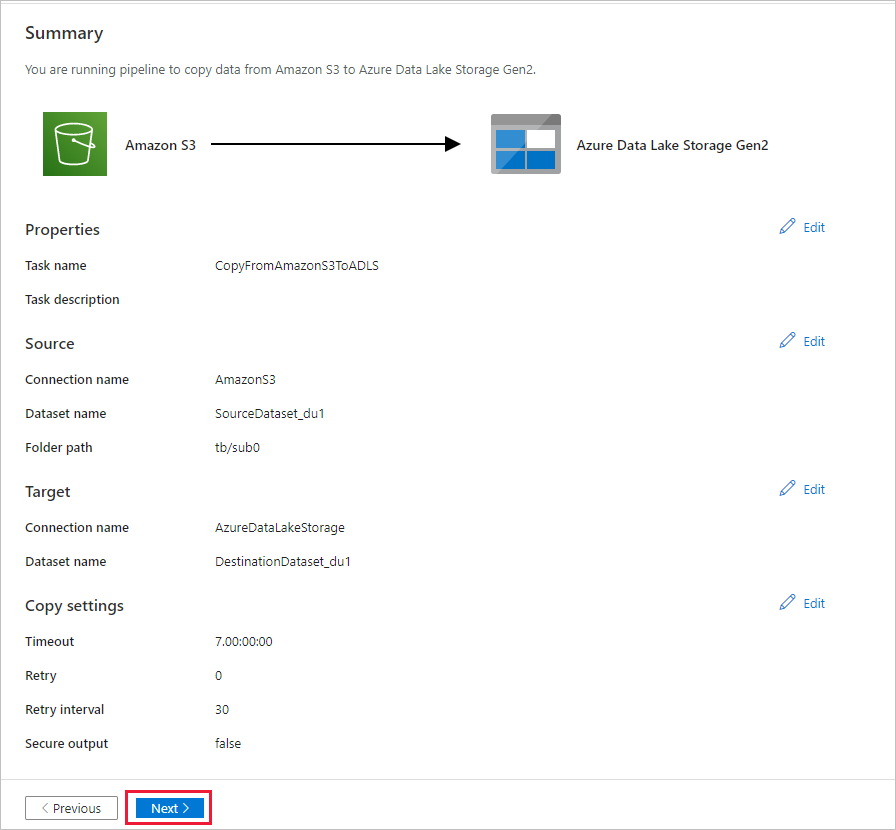
在“部署”页中,选择“监视”可以监视管道(任务)。
管道运行成功完成后,你会看到由手动触发器触发的管道运行。 可以使用“管道名称”列下的链接来查看活动详细信息以及重新运行该管道。
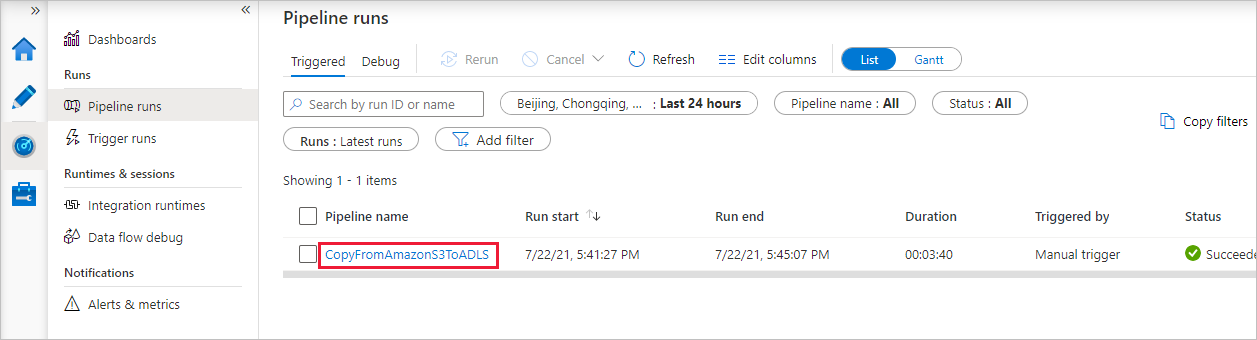
若要查看与管道运行关联的活动运行,请选择“管道名称”列下的“CopyFromAmazonS3ToADLS”链接。 有关复制操作的详细信息,请选择“活动名称”列下的“详细信息”链接(眼镜图标) 。 可以监视详细信息,例如,从源复制到接收器的数据量、数据吞吐量、执行步骤以及相应的持续时间和使用的配置。
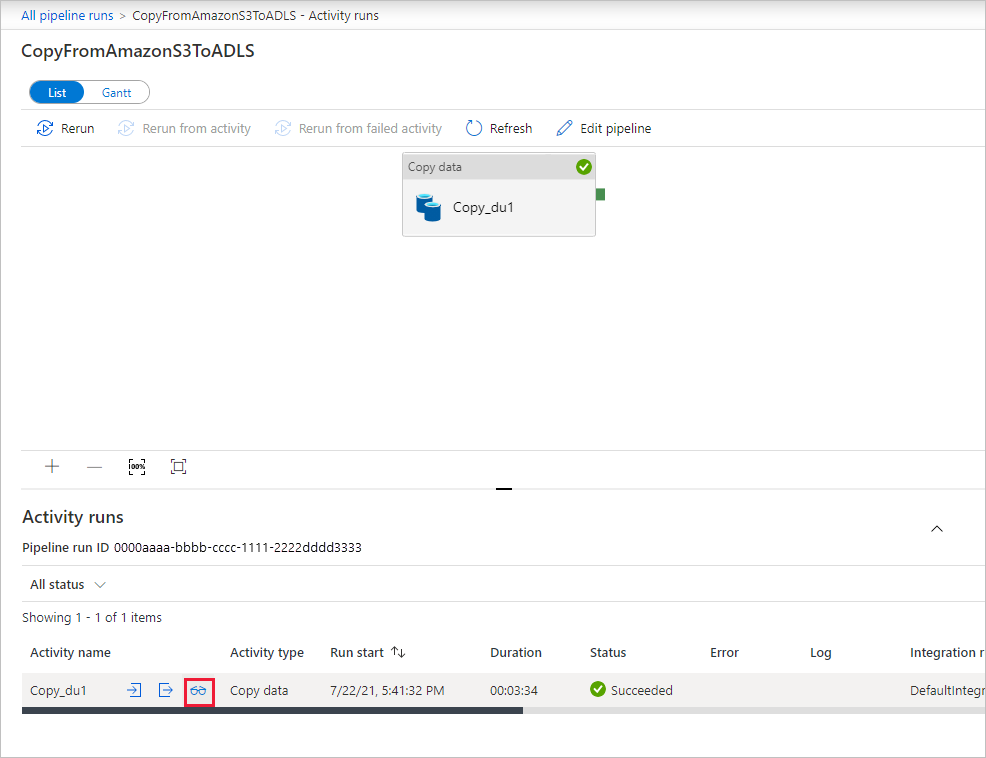
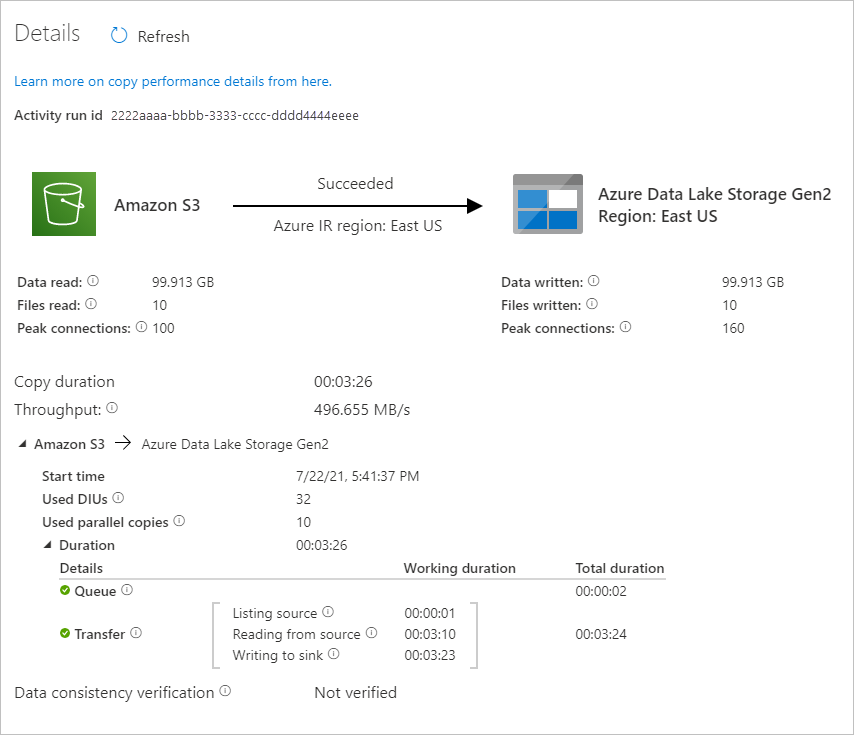
若要刷新视图,请选择“刷新”。 选择顶部的“所有管道运行”,回到“管道运行”视图。
验证数据是否已复制到Data Lake Storage Gen2帐户中。