适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
在处理 ETL 作业的数据时,你经常需要在写入结果之前更改列名。 有时,只有更改列名才能使列名与已知的目标架构相符。 此外,在运行时,你可能需要根据不断变化的架构设置列名。 本教程介绍如何使用数据流通过外部配置文件和参数动态设置目标文件与数据库表的列名。
如果对 Azure 数据工厂不熟悉,请参阅 Azure 数据工厂简介。
先决条件
- Azure 订阅。 如果没有 Azure 订阅,请在开始前创建一个试用 Azure 帐户。
- Azure 存储帐户。 将 ADLS 存储用作“源”和“接收器”数据存储。 如果没有存储帐户,请参阅创建 Azure 存储帐户以获取创建步骤。
创建数据工厂
在此步骤中,请先创建数据工厂,然后打开数据工厂 UX,在该数据工厂中创建一个管道。
- 打开 Microsoft Edge 或 Google Chrome。 目前,仅 Microsoft Edge 和 Google Chrome Web 浏览器支持数据工厂 UI。
- 在左侧菜单中,选择“创建资源>分析>数据工厂”
- 在“新建数据工厂”页面上,在“名称”下输入“ADFTutorialDataFactory”。
- 选择要在其中创建数据工厂的 Azure 订阅。
- 对于“资源组”,请执行以下步骤之一:
- 选择“使用现有资源组”,并从下拉列表选择现有的资源组。
- 选择“新建”,并输入资源组的名称。若要了解资源组,请参阅使用资源组管理 Azure 资源。
- 在“位置”下选择数据工厂所在的位置。 下拉列表中仅显示支持的位置。 数据工厂使用的数据存储(例如 Azure 存储和 SQL 数据库)和计算资源(例如 Azure HDInsight)可以位于其他区域。
- 选择“创建”。
- 创建完成后,通知中心内会显示通知。 选择“转到资源”导航到“数据工厂”页。
- 选择“创作和监视”,在单独的选项卡中启动数据工厂 UI。
创建包含数据流活动的管道
在此步骤中,你将创建一个包含数据流活动的管道。
在 ADF 主页中,选择“创建管道”。
在管道的“常规”选项卡中,输入“DeltaLake”作为管道的名称。
在工厂顶部栏中,将“数据流调试”滑块滑动到打开。 调试模式允许针对实时 Spark 群集进行转换逻辑的交互式测试。 数据流群集需要 5-7 分钟才能预热,如果用户计划进行数据流开发,建议先打开调试。 有关详细信息,请参阅调试模式。
在“活动”窗格中,展开“移动和转换”可折叠部分。 将“数据流”活动从该窗格拖放到管道画布上。
在“添加数据流”弹出窗口中选择“创建新数据流”,然后将数据流命名为“DynaCols”。 完成操作后,请选择“完成”。
在数据流中生成动态列映射
本教程将使用一个示例电影分级文件,并将源中的几个字段重命名为一组可随时更改的新目标列。 下面创建的数据集应指向你的 Blob 存储帐户或 ADLS Gen2 存储帐户中的此电影分级 CSV 文件。 在此处下载电影分级文件,并将其存储在你的 Azure 存储帐户中。
教程目标
你将了解如何使用数据流动态设置列名
- 为电影分级 CSV 文件创建源数据集。
- 为字段映射 JSON 配置文件创建查找数据集。
- 将源中的列转换为目标列名称。
从一个空白的数据流画布开始
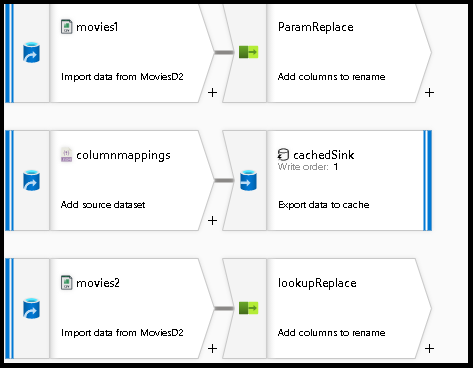
首先,让我们为下述每个机制设置数据流环境,使数据能够进入 ADLS Gen2。
选择源转换并将其命名为
movies1。选择底部面板中数据集旁的“新建”按钮。
选择“Blob”或“ADLS Gen2”,具体取决于前面你将 moviesDB.csv 文件存储到的位置。
添加第二个源,我们将借助它来寻找配置 JSON 文件,以查找字段映射。
将此源命名为
columnmappings。对于数据集,请指向用于存储列映射配置的新 JSON 文件。 对于此教程示例,可将以下代码粘贴到 JSON 文件中:
[ {"prevcolumn":"title","newcolumn":"movietitle"}, {"prevcolumn":"year","newcolumn":"releaseyear"} ]将此源设置设置为
array of documents。添加第三个源并将其命名为
movies2。 像配置movies1一样配置此源。
参数化列映射
在这第一个方案中,你将使用一个参数(列的字符串数组)基于匹配的传入字段设置列映射,以此在数据流中设置输出列名,然后使每个数组索引与传入列序号位置匹配。 从管道执行此数据流时,可以通过向数据流活动发送此字符串数组参数,在每个管道执行上设置不同的列名。
返回到数据流设计器,编辑前面创建的数据流。
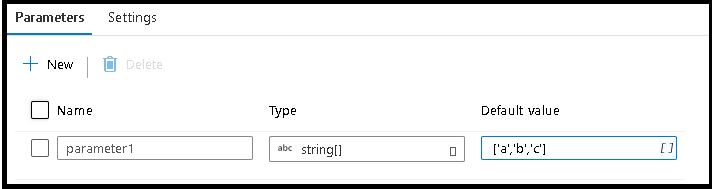
选择“参数”选项卡
创建新参数并选择字符串数组数据类型
输入
['a','b','c']作为默认值使用顶部的
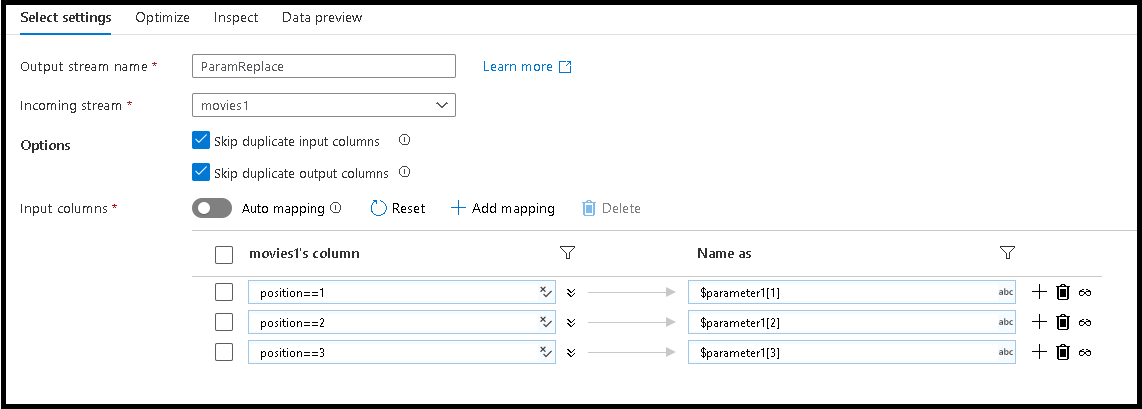
movies1源修改列名,以映射到这些数组值添加 Select 转换。 该 Select 转换用于将传入列映射到要输出的新列名。
我们要将前 3 个列名更改为参数中定义的新名称
为此,请在底部窗格中添加 3 个基于规则的映射条目
对于第一个列,匹配规则为
position==1,名称为$parameter1[1]对于第 2 和第 3 个列,请遵循相同的模式
选择 Select 转换的“检查”和“数据预览”选项卡,可以看到,新列名值
(a,b,c)替换了原始的 movie、title 和 genres 列名
创建外部列映射的缓存查找
接下来,我们将创建一个缓存接收器用于后续查找。 缓存将读取一个外部 JSON 配置文件,该文件可用于在数据流的每个管道执行上动态地重命名列。
- 返回到数据流设计器,编辑前面创建的数据流。 将 Sink 转换添加到
columnmappings源。 - 将接收器类型设置为
Cache。 - 在“设置”下,选择
prevcolumn作为键列。
查找缓存接收器中的列名
将配置文件内容存储到内存中后,可将传入列名动态映射到新的传出列名。
- 返回到数据流设计器并编辑上面的数据流创建。 选择
movies2源转换。 - 添加 Select 转换。 这一次,我们将使用 Select 转换来基于存储在缓存接收器中的 JSON 配置文件中的目标名称重命名列名。
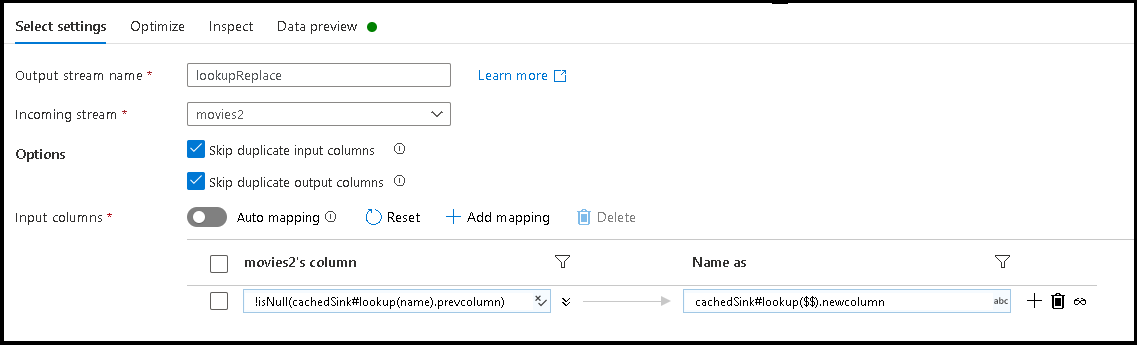
- 添加基于规则的映射。 对于“匹配条件”,请使用以下公式:
!isNull(cachedSink#lookup(name).prevcolumn)。 - 对于输出列名,请使用以下公式:
cachedSink#lookup($$).newcolumn。 - 我们要做的是在外部 JSON 配置文件中查找与
prevcolumn属性匹配的所有列名,并将每个匹配项重命名为新的newcolumn名称。 - 选择 Select 转换中的“数据预览”和“检查”选项卡,现在你应会看到外部映射文件中的新列名。